第 9 章 作者归属问题
文本挖掘任务作者分析(authorship analysis)的目标是只根据作品内容找出作者独有的特点,比如年龄、性别或背景。作者归属(authorship attribution)是作者分析的一个细分领域,研究目标是从一组可能的作者中找到文档真正的主人。这是一种典型的分类任务。作者分析任务一般采用标准的数据挖掘方法,比如交叉检验、特征抽取和分类算法等。
本章将把前几章学到的数据挖掘方法整合起来,解决作者归属问题,从而掌握数据挖掘整个过程。我们界定问题,讨论相关背景和知识,抽取特征,创建流水线实现分类。我们将比较两类特征的效果:功能词和N元语法。最后,深入分析结果。数据集会用到两种,一开始使用图书,然后增加难度,使用噪音较多的真实电子邮件语料。
本章主要介绍如下内容。
特征工程和如何根据应用选择特征
带着新问题,重新回顾词袋模型
特征类型和字符N元语法模型
支持向量机
数据集清洗
9.1 为作品找作者
作者分析可以从文体学(stylometry)中找到它的一席之地,文体学分析研究的是作者的写作风格,所依据的理念是每个人在语言掌握上有微小差异,这会反映到写作中,通过分析作品之间的细微差别,就可以把作者区分开来。
过去一直靠人工统计、分析来解决作者分析问题,而这些工作恰好是计算机所擅长的,这表明可以借助数据挖掘技术来实现自动化。如今作者分析的研究工作几乎都是用数据挖掘方法来解决,但仍有不少研究偏重于人工分析作品语言风格。
作者分析问题衍生出很多更细的问题,主要有以下几个。
作者画像:根据作品界定作者的年龄、性别或其他特性。例如,通过观察一个人讲英语的方式,判断英语是否为他的母语。
作者验证:根据作者已有作品,推断其他作品是否也是他写的。拿法庭断案场景来讲更好理解,例如,分析嫌犯的写作风格(内容方面),以确定勒索信是不是他写的。
作者聚类:作者验证问题的延伸,用聚类分析方法把作品按照作者进行分类。
然而,作者分析研究领域最常见的还是作者归属问题,即如何从一群作者中找到作品的真正主人。
9.1.1 相关应用和使用场景
作者分析有很多应用场景,比如证实作者是谁,证实几本书有相同的作者,或者寻找社会媒体账号的主人。
从历史意义上来说,作者分析可用来核实某些文档是否真由公认的作者所写。有些作品的作者就存在争议,比如莎士比亚的几部戏剧,美国建国时期的联邦党人文集等。
单凭作者分析无法确定作者到底是谁,但是能够提供支持或反驳某一观点的依据。例如,在检验一首十四行诗是否是莎士比亚所写前,我们可以先分析他的若干部剧作,弄清楚他的写作风格。
作者分析问题最近几年也被用来确定社会媒体账号到底是谁在使用。例如,一个恶意用户可能在不同社交平台创建多个账号。把它们关联起来后,便于监管部门跟踪幕后的黑手——例如,当扰乱其他用户时。
举个陈旧点的例子,法庭上视作者分析为核心技术,主要靠它来提供文档是否出自嫌犯之手的证据。例如,嫌疑犯可能因为发骚扰邮件而被起诉。作者分析就能确定邮件是否是嫌犯所写。另一个在法庭中的使用场景是,解决作品归属纠纷。比如,遇到两个人就一本书到底是谁写的而纠缠不已的情况,法庭就可以借助作者分析技术找到作者可能是谁的证据。
作者分析也并不是绝对可靠的。最近研究发现,即使没有经过专业训练的人,让他们隐藏自己的写作风格,也会让作者归属问题变得困难无比。研究人员还探讨了模仿别人写作风格的问题,结果发现人们模仿得很像,作者分析的结果是这些伪作出自被模仿人之手。
尽管存在很多问题,作者分析在越来越多的领域被证实十分有用,它是一个非常有意思的、值得研究的数据挖掘问题。
9.1.2 作者归属
作者归属可以看作是一种分类问题,已知一部分作者,数据集为多个作者的作品(训练集),目标是确定一组作者不详的作品(测试集)是谁写的。如果作者恰好是已知的作者里面的,这种问题叫作封闭问题。

如果作者可能不在里面,这种问题就叫作开放问题。不只是作者归属问题可以这样区分——任何数据挖掘应用,只要实际的类别可能不在训练集中的都叫作开放问题,对于这类问题进行挖掘,最终目标分两种情况,如果在训练集中,就返回找到的类别,如果不在,要给出不属于任何现有类别的提示。
在进行作者归属研究时,一般会受到两个限制。一是只能使用作品的内容,而不能使用写作时间、印刷形式、笔迹等信息。当然也有这样的做法,把这些信息整合到模型中,但一般来说这就不是作者归属而更像是数据融合问题。
第二个限制是不考虑作品的主题;相反,关注单词用法、标点和其他文本特征。原因在于,一个人如果是多面手,可以写多个主题的内容,作品的主题就不能反映作者的实际写作风格。关注主题关键字可能会导致过度拟合训练集——模型可能只是用同一个作者的同一个主题的作品进行训练。例如,根据我写的这本书为我的写作风格建模,可能会得出“数据挖掘”这个词能代表我的风格这样的结论,而事实上,我还写一些其他主题的内容。
接下来,用于作者归属问题的流水线跟第6章所用的很相似。首先,从文本中抽取特征;然后,对抽到的特征做进一步甄选;最后,训练算法分类器,预测文档的类别(作者)。
当然有些步骤跟第6章还是存在一些差别,主要集中在特征选取方面,后面会详细讲。我们还是先来划定待解决问题的范围。
9.1.3 获取数据
本章所用的图书数据集来自于古腾堡计划网站(www.gutenberg.org),该网站收集了大量版权失效的公版文学作品。实验用到以下作家的若干作品。
塔金顿(Booth Tarkington,22篇)
狄更斯(Charles Dickens,44篇)
伊迪斯·内斯比特(Edith Nesbit,10篇)
阿瑟·柯南·道尔(Arthur Conan Doyle,51篇)
马克·吐温(Mark Twain,29篇)
理查德·弗朗西斯·伯顿爵士(Sir Richard Francis Burton,11篇)
埃米尔·加博里奥(Emile Gaboriau,10篇)
以上总共是7位作家的177篇作品,文本数量还是相当可观的。作品名称列表、下载链接以及自动下载图书的代码请见本书配套的代码包。
用requests库下载作品文件到数据文件夹所在的目录。首先,在Data目录下创建文件夹存放这些作品。注意,下面代码指定的文件目录跟你实际创建的文件夹目录保持一致。
import osimport sysdata_folder = os.path.join(os.path.expanduser("~"), "Data", "books")
接着,就可以使用代码包中我写好的代码,从古腾堡计划的网站下载图书。下载完后将其保存到我们上面创建的目录中。
从代码包Chapter 9文件夹中找到getdata.py,保存到笔记本文件所在目录下,在新格子中输入以下代码。
!load getdata.py
在笔记本中,按下Shift+Enter运行该格子的代码。代码将会加载到格子中。然后再次点击代码,按下Shift+Enter运行加载的代码。代码要运行一段时间,运行完毕后会提示你。
大体翻看一下下载的作品,你会发现大部分都包含很多噪音——从数据分析的角度看至少是这样的。每篇作品前都有大段的声明文字,开始数据分析之前,得先把它们删掉。
我们可以直接从文件里将这些免责声明删除,但是丢失数据怎么办?我们可能会丢失先前做过的改动,从而导致实验结果无法重现,因此,不如在加载文件时跳过这部分——这样再次用这些文件做实验时,也能得到同样的结果(只要原文件没变)。代码如下:
def clean_book(document):
每篇作品前后各有一行文字,标识作品的开头和结尾,作品前后为古腾堡项目的说明。既然我们能根据这两行找到作品内容,因此,就按行来切分。
lines = document.split("\n")
遍历文档的每一行,寻找作品的开头和结尾,中间部分就是作品内容。代码如下:
start = 0end = len(lines)for i in range(len(lines)):line = lines[i]if line.startswith("*** START OF THIS PROJECT GUTENBERG"):start = i + 1elif line.startswith("*** END OF THIS PROJECT GUTENBERG"):end = i - 1
函数最后,用换行符把所有行再连接起来,得到作品内容。
return "\n".join(lines[start:end])
现在,我们可以创建一个函数,加载所有图书,进行上述预处理操作,返回书的内容以及作家序号1。先来导入numpy。
1用索引来表示,详见下文。——译者注
import numpy as np
声明加载图书的函数,参数为图书所在目录books,该目录下是一系列以作者名字命名的子文件夹,图书文件就在这些子文件夹中。代码如下:
def load_books_data(folder=data_folder):
创建两个列表,分别用来存储文档和作者。
documents = []authors = []
获取到books目录下所有的子文件夹。代码如下:
subfolders = [subfolder for subfolder in os.listdir(folder)if os.path.isdir(os.path.join(folder,subfolder))]
遍历这些子文件夹,使用enumerate函数为这些子文件夹指定索引。
for author_number, subfolder in enumerate(subfolders):
获取到子文件夹的绝对路径,查找里面的所有图书文件。
full_subfolder_path = os.path.join(folder, subfolder)for document_name in os.listdir(full_subfolder_path):
对于找到的每一个图书文件,打开后读取里面的内容,对内容进行预处理后,将其添加到documents列表中。代码如下:
with open(os.path.join(full_subfolder_path,document_name)) as inf:documents.append(clean_book(inf.read()))
把分配给作家的索引号添加到authors列表中,其实authors就是类别列表。
authors.append(author_number)
函数最后返回文档和类别(把类别列表转换为numpy数组)。
return documents, np.array(authors, dtype='int')
调用上面定义的加载图书函数,就能获得图书文档及其它们的类别。
documents, classes = load_books_data(data_folder)
把这些数据加载到内存没有问题,因此,我们可以立即加载。如果数据集太大,内存装不下,较好的方法是每次只从一篇(或几篇)文档中抽取特征,把这些特征保存到文件或位于内存的矩阵中。
9.2 功能词
功能词是作者分析问题最早使用的一类特征,到现在来看,在词袋模型中使用功能词做特征效果依然不错。功能词指的是本身具有很少含义,却是组成(英语)句子必不可少的成分。例如,单词this和which的意思不是由它们本身的含义所决定,而是由它们在句子中充当的角色来决定。与功能词相对的是实词,比如tiger就有明确的含义,当人们在句子中看到这个单词时,脑海中就会浮现出大型猫科动物老虎的样子。
有些功能词的用法并不总是清晰、明确的。因此,从经验来看,选用使用频率较高的功能词做特征比较好(在所有文档中使用频率高,而不仅是在单个作者的作品中)。通常而言,使用越频繁的单词,对于作者分析能提供更多有价值的信息。相反,使用频率较低的单词,更适合用来做基于内容的文本挖掘,例如下章要讲的文档主题划分。
功能词的使用通常不是由文档内容而是由作者的使用习惯所决定,因此可以用它们来区分不同的作者。例如,很多美国人比较在意区分that和which在句子中的用法,澳大利亚等国家的人就不太在意。在使用这两个词的地方,有些澳大利亚人要么几乎无一例外地都用that,要么是which用得多一点。这样的不同点,再加上成千上万个其他的微小差别,就形成了用于作者分析的模型。
9.2.1 统计功能词
我们可以使用第6章所用到的CountVectorizer统计功能词。我们把包含所有要查找的单词的词汇表(vocabulary)传递进去,如果没有传词汇表(第6章就没有),它会从数据集中学习。所有单词都在训练集中(取决于其他参数)。
首先,创建功能词词汇表,用列表存储。至于确切来说哪些是功能词,哪些不是,有待商榷。我从已发表的研究成果中找到下面这些功能词,它们还是比较可靠的。
function_words = ["a", "able", "aboard", "about", "above", "absent","according" , "accordingly", "across", "after", "against","ahead", "albeit", "all", "along", "alongside", "although","am", "amid", "amidst", "among", "amongst", "amount", "an","and", "another", "anti", "any", "anybody", "anyone","anything", "are", "around", "as", "aside", "astraddle","astride", "at", "away", "bar", "barring", "be", "because","been", "before", "behind", "being", "below", "beneath","beside", "besides", "better", "between", "beyond", "bit","both", "but", "by", "can", "certain", "circa", "close","concerning", "consequently", "considering", "could","couple", "dare", "deal", "despite", "down", "due", "during","each", "eight", "eighth", "either", "enough", "every","everybody", "everyone", "everything", "except", "excepting","excluding", "failing", "few", "fewer", "fifth", "first","five", "following", "for", "four", "fourth", "from", "front","given", "good", "great", "had", "half", "have", "he","heaps", "hence", "her", "hers", "herself", "him", "himself","his", "however", "i", "if", "in", "including", "inside","instead", "into", "is", "it", "its", "itself", "keeping","lack", "less", "like", "little", "loads", "lots", "majority","many", "masses", "may", "me", "might", "mine", "minority","minus", "more", "most", "much", "must", "my", "myself","near", "need", "neither", "nevertheless", "next", "nine","ninth", "no", "nobody", "none", "nor", "nothing","notwithstanding", "number", "numbers", "of", "off", "on","once", "one", "onto", "opposite", "or", "other", "ought","our", "ours", "ourselves", "out", "outside", "over", "part","past", "pending", "per", "pertaining", "place", "plenty","plethora", "plus", "quantities", "quantity", "quarter","regarding", "remainder", "respecting", "rest", "round","save", "saving", "second", "seven", "seventh", "several","shall", "she", "should", "similar", "since", "six", "sixth","so", "some", "somebody", "someone", "something", "spite","such", "ten", "tenth", "than", "thanks", "that", "the","their", "theirs", "them", "themselves", "then", "thence","therefore", "these", "they", "third", "this", "those","though", "three", "through", "throughout", "thru", "thus","till", "time", "to", "tons", "top", "toward", "towards","two", "under", "underneath", "unless", "unlike", "until","unto", "up", "upon", "us", "used", "various", "versus","via", "view", "wanting", "was", "we", "were", "what","whatever", "when", "whenever", "where", "whereas","wherever", "whether", "which", "whichever", "while","whilst", "who", "whoever", "whole", "whom", "whomever","whose", "will", "with", "within", "without", "would", "yet","you", "your", "yours", "yourself", "yourselves"]
既然有了功能词列表,我们就来创建功能词统计工具。后面,会把它加到流水线中。
from sklearn.feature_extraction.text import CountVectorizerextractor = CountVectorizer(vocabulary=function_words)
9.2.2 用功能词进行分类
接下来,导入所需的几个类,唯一的新内容支持向量机在下节会讲(现在把它看作是标准的分类算法即可)。导入用支持向量机算法进行分类的SVC类,以及其他一些我们用过的标准工作流工具。
from sklearn.svm import SVCfrom sklearn.cross_validation import cross_val_scorefrom sklearn.pipeline import Pipelinefrom sklearn import grid_search
支持向量机接收一系列参数。现阶段照我设置的参数来就行,下节再深入探讨参数值选择。我们用字典结构来组织参数。参数kernel使用linear和rbf。C的值取1或10(参数说明请见下节)。接着用网络搜索法寻找最优参数值。
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}svr = SVC()grid = grid_search.GridSearchCV(svr, parameters)
rbf)只适用于数据集相对较小的情况,比如特征数少于10 000。
接着,创建流水线,把特征抽取和参数搜索两个步骤加入到流水线中,特征(仅功能词)抽取使用CountVectorizer类,参数搜索使用SVM。代码如下:
pipeline1 = Pipeline([('feature_extraction', extractor),('clf', grid)])
然后,使用cross_val_score对该流水线的结果进行交叉检验,正确率为0.811,大约80%的预测结果正确。对于只有7个作者来说,这个结果很好!
9.3 支持向量机
支持向量机(SVM)分类算法背后的思想很简单,它是一种二类分类器(扩展后可用来对多个类别进行分类)。假如我们有两个类别的数据,而这两个类别恰好能被一条线分开,线上所有点为一类,线下所有点属于另一类。SVM要做的就是找到这条线,用它来做预测,跟线性回归原理很像。只是SVM要找出最佳的分割线。下图中有三条线,分别为蓝色、黑色和绿色线,都能把两类数据区分开来。你说哪条分类效果更好呢?
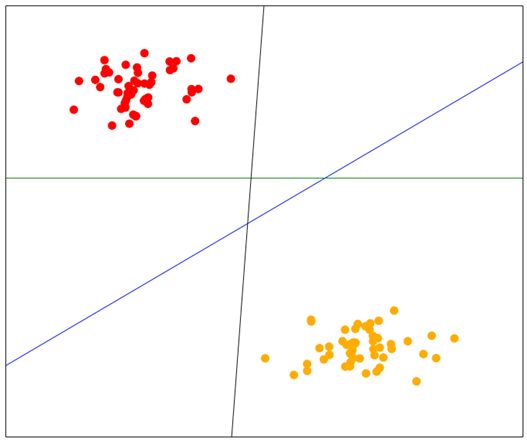
凭直觉,人们往往会选择从左下到右上的这条线2,它把两类数据更好地分开了。也就是说,数据集中的每个点到这条线的距离都是最远的。
2如果你查看原书PDF文件的话,这条线指的是图中的蓝线。PDF文件获取方法请见前言部分。建议读者下载查看。彩色图毕竟比黑白图形象。——译者注
找到这样的一条线其实是最优化问题,也就是要让各点到分割线之间的距离最大化。
虽然最优化问题的公式推导不在本书讲述范围之列,我还是建议感兴趣的读者自行查看http://en.wikibooks.org/wiki/Support_Vector_Machines,了解详细步骤。此外,你还可以访问http://docs.opencv.org/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html,了解支持向量机相关内容。
9.3.1 用SVM分类
模型训练完毕,就能找到使得两类之间间隔最大的一条线。新数据点分类问题就简化为:数据点在线上还是线下?如果在线上,就被分到线上那一类;如果位于线下,自然属于线下那一类。
对于多种类别的分类问题,我们创建多个SVM分类器——每个还是二类分类器。连接多个分类器有不少方法,从中任选一种即可。最简单的方法是为每个类别创建一对多(one-versus-all)分类器,把训练数据分为两个类别——属于特定类别的数据和其他所有类别数据。对新数据进行分类时,从这些类别中找出最匹配的。大多数SVM多类分类器都能自动完成上述过程。
前面代码中有两个参数:C和kernel。kernel参数下节讲,C参数对于训练SVM来说很重要,我们现在来讲下。C参数与分类器正确分类比例相关,但可能带来过拟合的风险。C值越高,间隔越小,表示要尽可能把所有数据正确分类。C值越小,间隔越大——有些数据将无法正确分类。C值低,过拟合训练数据的可能性就低,但是分类效果可能会相对较差。
SVM(基础形式)局限性之一就是只能用来对线性可分的数据进行分类。如果线性不可分呢?这时我们就要用到内核函数。
9.3.2 内核
如果数据线性不可分,就需要将其置入更高维的空间中,加入更多伪特征直到数据线性可分(如果你加入足够多恰当的特征,总能把数据分开)。
寻找最佳分隔线时往往需要计算个体之间的内积3。对于使用点积(dot product)的函数,我们可以创建新特征而无需实际定义这些特征。因为我们不知道这些特征到底是什么样子,所以用点积很方便。我们把内核函数定义为数据集中两个个体函数的点积,而不是使用个体自身(及构造的特征)。
3inner product,也称作点积。——译者注
接下来就可以计算点积(或近似值),然后就能使用它。
常用的内核函数有几种。线性内核最简单,它无外乎两个个体的特征向量的点积、带权重的特征和偏置项。多项式内核提高点积的阶数(比如2)。此外,还有高斯内核(rbf)、Sigmoind内核。前面例子中,我们比较了线性内核和rbf内核的效果。
这些内核能够有效地确定两类数据之间的距离,SVM可以据此对新数据进行分类。理论上讲,任何距离度量方法都可以用,但是在训练SVM时,最优化问题的复杂程度会有所不同。
scikitlearn实现的SVM,可以通过kernel参数指定内核函数,正如我们在前面例子中见过的。
9.4 字符N元语法
我们前面研究的是如何用功能词做特征预测文档的作者。接下来看下字符N元语法特征。N元语法由一系列的N个为一组的对象组成。N为每组对象的个数(对于文本来说,N通常取2到6之间的值)。基于单词的N元语法被广泛用在通常与文档主题相关的各项研究中。然而,基于字符的N元语法被证明在作者归属问题上效果很好。
我们可以把文档看成是由一系列字符组成的,从里面抽取N元语法,训练得到模型。常用模型有几个,其中标准模型跟我们之前用到的词袋模型很相似。
分别为训练语料中各个不同的N元语法创建一个特征。例如,由字母e、空格和字母t组成的N元语法
关于基于字符的N元语法为什么效果比较好,广为接受的理论是,人们在写作时,往往选取那些他们讲起来很容易的单词,而字符N元模型(至少N取 2到6之间时)跟这些音素具有很好的相似关系——音素指的是我们讲话时,组成单词发音的那些声音。从这种意义上讲,用字符N元模型可以很好地模拟讲话时经常用到的单词,而这些单词形成了写作风格。这是创建新特征的通用模式:先找到哪些概念影响最终结果(写作风格)的理论依据,然后创建跟这些概念相近或是能够量化这些概念的特征。
字符N元语法矩阵的一个主要特点是数据稀疏,随着N值的增加,稀疏程度逐渐加大,且速度很快。N取2时,我们的特征矩阵中大约75%的项都是0,N取5时,93%以上的项为0。比起基于词语的N元语法矩阵来说,稀疏程度要低一些,因此,适用于单词分类的分类器处理数据,不会有太大问题。
抽取字符N元语法
我们接下来用CountVectorizer类来抽取N元语法,需要设置analyzer参数,指定N的值。
scikitlearn的N元语法抽取工具提供了range参数,允许用户同时抽取不同长度的N元语法。我们这里用不到,只抽取相同长度即可,range参数的两个值使用相同值即可。要抽取长度为3的N元语法,range的值需要设置为(3, 3)。
我们可以重用前面网格搜索代码,但是需要在新流水线中指定新的特征抽取器。
pipeline = Pipeline([('feature_extraction', CountVectorizer(analyzer='char', ngram_range=(3, 3))),('classifier', grid)])scores = cross_val_score(pipeline, documents, classes, scoring='f1')print("Score: {:.3f}".format(np.mean(scores)))
9.5 使用安然公司数据集
安然公司(Enron)是20世纪90年代末期世界上最大的能源公司之一,年收入高达1000亿美元。2000年时,拥有20 000余名员工,看不出公司有什么严重问题。
2001年,安然丑闻发生,调查人员发现安然为谋取暴利,在全公司范围内账务存在系统性造假现象。丑闻被揭发后,安然公司的股价从2000年的90多美元一下子跌到了2001年的1美元。安然随即申请破产保护,留下的残局,五年多以后才收拾干净。
作为对安然公司调查的一部分,美国联邦能源署公开了60多万封电子邮件。从那时起,这些数据就被广泛应用于社会媒体分析、欺诈分析等众多问题的研究。这些数据用于作者归属问题研究也不错,因为我们能获得发件人及他们写的邮件,语料规模比之前见过的很多数据集都要大得多。
9.5.1 获取安然数据集
安然公司的邮件可以从卡内基梅隆大学的网站下载:https://www.cs.cmu.edu/~./enron/。
下载电子邮件语料,将其解压到Data目录下。解压后的目录默认为enron_mail_20110402。
因为要做作者归属分析,我们只需要那些明确知道发件人是谁的邮件。因此,查看每位用户的发件夹——那里面存放的是他们所发的邮件。
在笔记本中,指定安然数据集所在的位置。
enron_data_folder = os.path.join(os.path.expanduser("~"), "Data","enron_mail_20110402", "maildir")
9.5.2 创建数据集加载工具
我们现在就来创建一个函数,它接收几个发件人作为参数,返回他们所发送的邮件。我们需要的有效信息是邮件内容而不是邮件本身。因此,还需要邮件解析器。代码如下:
from email.parser import Parserp = Parser()
我们后面会用到该解析器从邮件中抽取邮件内容。
因为是随机选取收件人,为了重现实验结果,我们设置随机状态。
from sklearn.utils import check_random_state
数据加载函数提供几个参数,大部分是为了确保得到的数据集类别分布相对比较均衡。有些用户发了成千上万封邮件,而有的用户只发了几十封。我们用min_docs_author参数指定每个发件人至少发过10封邮件,用max_docs_author参数指定最多从一个用户那里抽取100封邮件。我们还用num_authors限定了收件人数量——默认为10。代码如下:
def get_enron_corpus(num_authors=10, data_folder=data_folder,min_docs_author=10, max_docs_author=100,random_state=None):random_state = check_random_state(random_state)
接下来,获取到安然公司员工的邮箱,邮箱其实就是data_folder文件夹中各子文件夹的名称。随机对得到的邮箱列表进行排序。只要随机状态相同,实验结果就可以重现。
email_addresses = sorted(os.listdir(data_folder))random_state.shuffle(email_addresses)
os.listdir函数每次返回结果不一定相同,在使用该函数前先排序,从而保持返回结果的一致性。然后我们用随机状态的shuffle函数随机选取一组收件人。如果需要的话,随机状态函数可以返回跟之前相同的结果。
然后,我们创建文档列表、类别列表,author_num指的是每个新发件人的类别编号。这次我们不用enumerate函数,因为有些发件人我们用不到。例如,发过不够10封邮件的,就不会用。代码如下:
documents = []classes = []author_num = 0
我们还需要记录我们所用到的收件人及他们的编号。数据挖掘过程用不到,但是在可视化时能用到,便于我们确定收件人。authors字典用于将用户名和类别关联起来。代码如下:
authors = {}
接下来,遍历邮箱文件夹,查找它下面名字中含有“sent”的表示发件箱的子文件夹。代码如下:
for user in email_addresses:users_email_folder = os.path.join(data_folder, user)mail_folders = [os.path.join(users_email_folder,subfolder) for subfolder in os.listdir(users_email_folder)if "sent" in subfolder]
获得子文件夹中的每一封邮件。我们用到了try-except语句,因为有些用户的发件箱目录还有子目录。要获取目录层次更深的邮件,我们的代码还需要做些改进,现在我们先跳过这些用户。代码如下:
try:authored_emails = [open(os.path.join(mail_folder,email_filename), encoding='cp1252').read()for mail_folder in mail_foldersfor email_filename in os.listdir(mail_folder)]except IsADirectoryError:continue
接下来,检测是否获取到了至少10封邮件(或min_docs_author指定的其他值)。
if len(authored_emails) < min_docs_author:continue
下一步,如果发件人发了大量邮件,只取前100封(具体数量由max_docs_author指定)。
if len(authored_emails) > max_docs_author:authored_emails = authored_emails[:max_docs_author]
解析邮件,获取邮件内容。我们对邮件头部不感兴趣——发件人所能改动的内容比较少,因此对作者分析没有多大用处。然后把邮件内容添加到数据集中。
contents = [p.parsestr(email)._payload for email inauthored_emails]documents.extend(contents)
把该发件人添加到类别列表中,每一封邮件添加一次。
classes.extend([author_num] * len(authored_emails))
记录该收件人的编号,再把编号加1,以便下一个收件人使用。
authors[user] = author_numauthor_num += 1
检测收件人数量是否达到我们设置的值,如果是,跳出循环,返回数据集。
if author_num >= num_authors or author_num >=len(email_addresses):break
返回邮件数据集和类别以及收件人字典。
return documents, np.array(classes), authors
在上述函数的外面,调用这个函数,我们就能得到数据集。我们使用随机状态14(全书都是),但是你可以尝试其他值或者将其设置为none,这样每次调用这个函数时将随机获取一组数据。
documents, classes, authors = get_enron_corpus(data_folder=enron_data_folder, random_state=14)
如果你看下现有的数据集,你就会发现还需要做进一步的预处理。数据集有不少噪音,但最致命的问题(从数据分析角度看)是,它还包含其他用户所写的内容,回复邮件时会带上别人之前写的邮件。我们来看下邮件documents[100]:

在这篇文档中,上面的邮件是对下面邮件的回复,这种情况很常见。第一部分是来自Mark Haedicke,而下面的邮件是Mark Greenberg写给Mark Haedicke。只有前面的内容(第一处“——-Original Message——-”之前)是发件人所写,这才是我们所关注的。
抽取这些信息不容易。邮件没有统一的格式。不同的邮件服务提供商使用不同的头部,对于回复内容有不同的定义形式,简直就是“为所欲为”4。就是在这样的环境中,电子邮件还被广泛使用,简直就是一个奇迹。
4读到此处,不禁想起各种浏览器的纷争。——译者注
当然还是有些共用的模式可以用。我们可以用quotequail包来查找邮件中的新内容,抛弃被回复的邮件及其他不相干信息。
pip安装quotequail:pip3 install quotequail。
我们编写一个简单的函数封装quotequail的功能,方便调用它处理所有的文档。首先导入quotequail,声明函数。
import quotequaildef remove_replies(email_contents):
接着用quotequail把邮件解析为几个部分,返回字典结构。代码如下:
r = quotequail.unwrap(email_contents)
有时候,r可能为none,比如邮件出于这样那样的原因解析失败。遇到这种情况,邮件原样返回。在处理真实数据集时,经常需要检测变量值是否为空。代码如下:
if r is None:return email_contents
quotequail的返回结果中,我们真正需要的是text_top这部分。如果字典r中存在text_top,返回它的值。
if 'text_top' in r:return r['text_top']
如果不存在,也就是quotequail没能找到该键。它也可能找到了text键,那返回text的值。代码如下:
elif 'text' in r:return r['text']
最后,如果这两个键都没有找到,返回邮件全部内容,希望多少会对数据分析有点用处。
return email_contents
对数据集中的每一封邮件,运行上述函数,做一遍预处理。
documents = [remove_replies(document) for document in documents]
我们之前看过的那封含有被回复邮件的文档,经过处理后,只包含Mark Greenberg所发的内容。
I am disappointed on the timing but I understand. Thanks. Mark
9.5.3 组装起来
我们可以使用前面实验所用到的参数空间和分类器——在新数据集上进行训练。默认情况下,scikitlearn会重新进行训练——后续调用fit()函数将会丢掉之前的信息。
跟前面一样,我们使用cross_val_score计算正确率并输出结果。代码如下:
scores = cross_val_score(pipeline, documents, classes, scoring='f1')print("Score: {:.3f}".format(np.mean(scores)))
F1值为0.523,对于包含这么多噪音的数据集来说,结果还算可以。添加更多数据(比如增加max_docs_author的值)应该会提升效果。
9.5.4 评估
一般来说,只凭借一个数字来评估效果不是个好主意,可能会忽略很多东西。拿F值来说,它考察的点就比较全面,那些分类结果好,却没有实际用处的雕虫小技也就不能蒙混过关。前面多次使用的正确率就有破绽,比如邮件过滤器把所有邮件归为垃圾邮件,也能达到80%的正确率,但是这种方法却没有实际用处。出于这个原因,我们还要对评估结果进行深入探讨。
我们先来看下混淆矩阵,第8章用神经网络破解验证码曾经用过。首先,对测试集数据进行预测。前面代码使用cross_val_score,并没有给出可用的训练模型,因此我们需要重新训练一个模型。我们先来把语料切分为训练集和测试集。
from sklearn.cross_validation import train_test_splittraining_documents, testing_documents, y_train, y_test =train_test_split(documents, classes, random_state=14)
接着,把训练集传入流水线,进行训练,接着对测试集进行预测。
pipeline.fit(training_documents, y_train)y_pred = pipeline.predict(testing_documents)
你可能想知道最好的参数组合是什么。我们可以方便地从网格搜索对象(流水线classifier这一步)中获取到这些参数组合。
print(pipeline.named_steps['classifier'].best_params_)
上述代码输出分类器的所有参数。然而大部分参数都使用默认值。只有C和kernel两个参数,我们使用网格搜索寻找合适的值,它们分别被设置为1和linear。
创建混淆矩阵:
from sklearn.metrics import confusion_matrixcm = confusion_matrix(y_pred, y_test)cm = cm / cm.astype(np.float).sum(axis=1)
我们接下来作图要用到刻度,因此需要取到发件人。还好,加载数据集时,我们用字典来保存了发件人及其编号。代码如下:
sorted_authors = sorted(authors.keys(), key=lambda x:authors[x])
最后,使用matplotlib绘制混淆矩阵。代码跟上章大同小异,不同的地方用粗体表示,只是把坐标轴刻度改为发件人。
%matplotlib inlinefrom matplotlib import pyplot as pltplt.figure(figsize=(10,10))plt.imshow(cm, cmap='Blues')tick_marks = np.arange(len(sorted_authors))plt.xticks(tick_marks, sorted_authors)plt.yticks(tick_marks, sorted_authors)plt.ylabel('Actual')plt.xlabel('Predicted')plt.show()
图像如下。
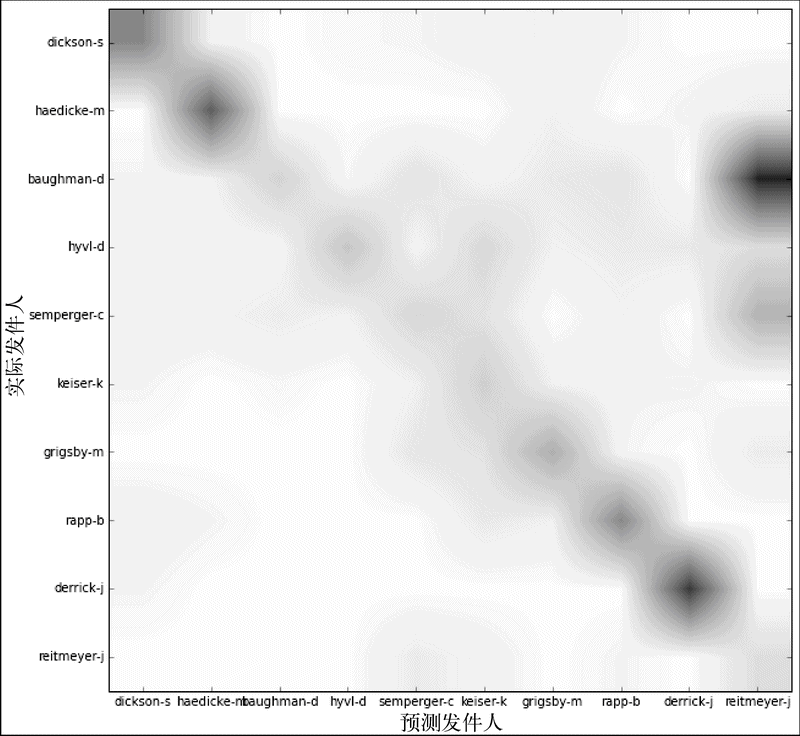
我们可以看到哪些发件人在大多数情况下都能正确预测——正确率高的形成了一条清晰的对角线。我们还能看出哪些发件人的邮件经常被弄混(颜色越深,弄混的次数越多):例如,baughman-d的邮件经常被当作是reitmeyer-j发的。
9.6 小结
本章研究的是文本挖掘领域中的作者归属问题,我们分析了两类特征的效果:功能词和字符N元语法。我们在词袋模型中使用功能词——提前选好的一组词,计算出这些词的词频。字符N元语法的处理流程跟基于单词的N元语法很相似,但是分析器转而关注字符而不是单词。此外,N元语法由一系列字符组成。单词N元语法由于可以提供单词的语境而没有增加多少计算量,在某些应用中也值得一试。
我们用SVM来进行分类,它通过找出使得两个类别之间间隔最大的线进行分类。线上的属于一类,线下的属于另外一类。跟其他分类任务一样,我们也需要有数据集(邮件)。
我们使用安然公司的邮件作为数据集,它包含很多噪音,比如包含被回复的邮件等。所以分类效果比起图书数据集要差不少。然而,在有10个发件人的情况下,半数以上邮件的发件人都能预测正确。
下一章,我们要研究的问题是没有目标类别的情况下,怎么对数据进行分类。这种叫作无监督学习,比起预测更像是探索性问题。我们要使用的依然是充满噪音的文本数据集。准备好接受挑战了吗?
