第 11 章 环境搭建与部署的自动化
应用的运行离不开执行环境。
搭建环境要做的事非常多,比如安装依赖包、设置中间件、设置应用本身等。这些工作稍有差错就会导致应用无法运行,而我们很难分辨问题究竟出在应用身上还是环境身上,因此解决问题常常要费一番力气。
另外,许多项目的环境不止一个,除正式环境外还需要开发环境、演示环境等。现今还要考虑到向外扩展,有时一个环境甚至是由几十台服务器共同构成的。要手动搭建这么多环境还要保证不出错,实在有些强人所难。
为保证良好的服务运营,需要有能让应用稳定运行且便于维护的环境。本章将就搭建稳定环境的方法理论以及通过 Ansible 实现环境搭建、部署自动化的方法进行说明。
本章的目的是搭建环境的自动化,但是如果过于随意地搭建内容和流程,则很难形成一个稳定的环境。另外,在这种状态下也不可能顺利实现自动化。因此本章内容将分为两部分,第一部分探讨搭建环境的流程和内容,第二部分讲解如何将第一部分的内容自动化。
11.1 确定所需环境的内容
首先要从所需环境的内容入手。环境一旦开始使用就很难再进行大的改动,所以动手搭建前搞清所需环境的内容是十分重要的。
在熟悉搭建环境的流程之前,建议先摸索着尝试手动搭建。等到熟悉之后,再考虑结构选择和搭建过程自动化的问题。
利用 VirtualBox 和快照功能可以帮助我们快速确定所需环境的内容。感兴趣的读者请同时参考附录 A。
11.1.1 网络结构
许多服务是由多台服务器组合实现的,所以在探讨服务器内部的环境搭建之前,先要确定服务器的组成结构。
可用服务器数、预算、应用性能不同,所需的服务器结构也是千差万别。这里我们以图 11.1 所示的结构为例进行学习。
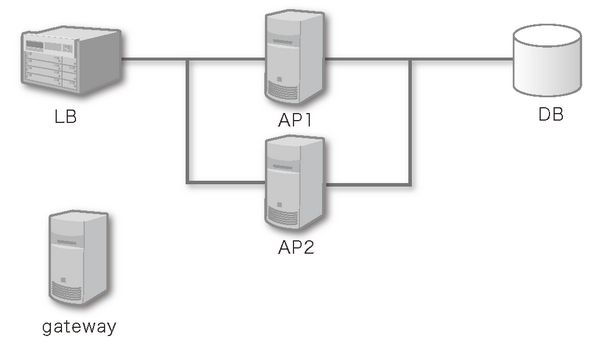
图 11.1 服务器结构
LB:负载平衡器(nginx)
AP1、2:应用服务器(django/gunicorn)
DB:数据库(mysql)
gateway:跳板服务器
◉ 服务器编组
确定服务器结构时,要给职责相同的服务器起一个统一的名字。
这里我们将分担各个职责的服务器群称为组。在图 11.1 所示的结构中,有 LB、AP、DB、gateway 这 4 个组。
即便某个职责只由一台服务器完成,我们也认为其是一个组。这样一来能更灵活地应对多服务器结构。
NOTE
按职责划分的服务器群也被称为“角色”(Role)。但这会与我们即将讲到的 Ansible 的 Role 重复,所以这里改用“组”(Group)。
◉ 跳板服务器
允许从外部网络直接 ssh 登录各个服务器会带来很多安全隐患,所以一般我们会阻止外部通过 ssh 访问各服务器。
可是,一旦阻止了对所有服务器的 ssh,我们便无法通过外网登录,这会造成很多不便。所以这里要准备一台用作登录跳板的服务器,形成通过跳板登录各服务器的结构。
11.1.2 服务器搭建内容的结构化
将服务器搭建内容按照图 11.2 所示的结构进行结构化。
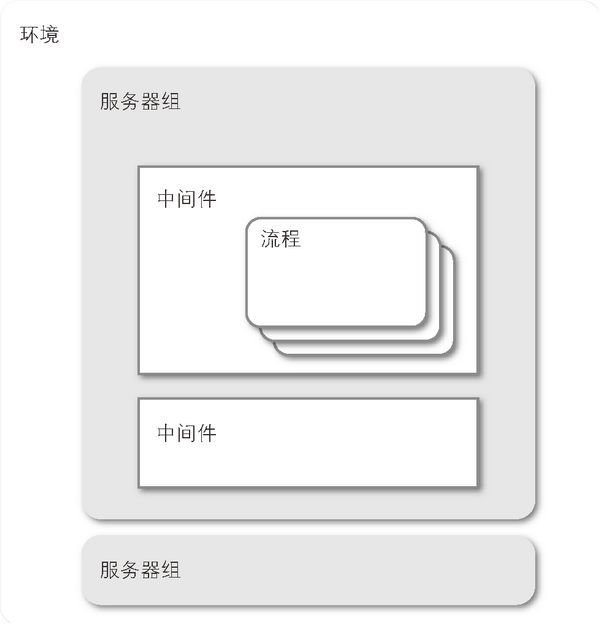
图 11.2 服务器搭建内容的结构化
这个结构很好理解。在中间件里定义安装和设置等流程,然后将各个中间件组合起来搭建服务器组。最后把搭建好的多个服务器组整合起来,就形成了一个环境。
这里需要特别注意的是,将搭建流程整合到各个中间件里时,如果只简单地把要做的处理按顺序一件一件写下来,很容易让人搞不清究竟哪个步骤属于哪个中间件的设置。加强对这个结构的理解和注意,有助于提高自动化的效率。关于自动化的知识我们将在 11.2 节进行学习。
根据图 11.2 所示的结构,本章中的服务器可划分为如下图 11.3 所示的结构。

图 11.3 本章中的服务器的搭建内容
这里出现了“环境设置”,它不是中间件,而是我们为了便于理解,将 OS 的设置、用户的创建等不针对特定中间件进行的操作汇总在了一起,并统一称为“环境设置”。
下面我们开始学习具体的搭建流程。
11.1.3 用户的设置
我们已经确定好了服务器的结构,接下来要探讨搭建流程。首先是用户的设置。
初始状态下的 Ubuntu 以 ubuntu 用户为登录用户。但是,如果让默认的管理员用户来做维护或启动应用,会带来一些安全隐患。所以,我们新建 mainte 用户用于搭建和维护,新建一个不能直接登录的普通用户 www 用于执行应用。
# useradd -m mainte# useradd -m www
搭建工作会经常用到 sudo,因此要给 mainte 用户设置 sudo 权限。另外,考虑到自动化的问题,最好让 mainte 不需要密码就可以执行 sudo。
可以通过编辑 etcsudoers 或者在 etcsudoers.d/ 中添加设置文件修改 sudo 权限。这次我们用后一种方法,创建 etcsudoers.d/mainte。
%mainte ALL=(ALL) NOPASSWD:ALL
%mainte 表示给 mainte 组的所有用户设置 sudo 权限。今后如果有其他用户需要用到 sudo,只要将其加入 mainte 组即可。
至于 www 用户,要让它只保有启动应用所需的最小权限,因此不设置 sudo 权限。
最后是登录设置。mainte 用户今后要用来做维护工作,所以需要能从外部登录。
首先用 ssh-keygen 生成密钥文件。
$ sudo su - mainte$ ssh-keygen -b 2048
如果在初始设置状态下执行 ssh-keygen,会在 homemainte.ssh 下生成 id_rsa 和 id_rsa.pub 两个文件。我们将这两个文件下载到本地 PC 保管。
将 id_rsa.pub 的内容设置到 authorized_keys 中,登录设置就完成了。
$ cat ~.sshid_rsa.pub >> .sshauthorized_keys$ chmod 600 .sshauthorized_keys
经过上面的设置,我们在 mainte 用户的“.ssh”目录下生成了密钥文件,同时完成了对应的 authorized_key 的设置。
这样设置下来之后,就能很轻松地在多个服务器之间切换登录了。
最后查看设置是否正确。
mainte 用户能用下载到本地 PC 的密钥文件登录服务器
mainte 用户能通过 sudo 切换为 www 用户
可以对 localhost 执行 ssh
$ ssh localhost
11.1.4 选定程序包
接下来安装应用运行所需的程序包。
在 Ubuntu 上运行 Python 应用时,主要通过 apt-get 和 pip 安装程序包。
选择要安装的程序包时请注意以下几点。
① 安装的程序包要尽量少
尽量不要导入与运行应用无关的程序包。
盲目导入程序包会使我们无法准确掌握应用的运行条件,出问题时很难分辨问题出在环境上还是应用本身上。
要导入与运行应用没有直接关系的程序包时,必须先仔细考虑其用途和安装范围,再确定是否要将其加入搭建流程。
下面是一些做判断的例子。
- 应用的目录结构很复杂,排查 Bug 时需要
tree命令的辅助
任何环境都难免需要排查 Bug,因此需要将 tree 命令加入构建流程。
- 想用自己常用的编辑器 emacs
基本只会在开发环境中用到,所以仅在开发环境中导入。
② 掌握并管理程序包的版本
对开发力度较大的应用 / 库而言,常有从某个版本起发生大幅度规格变更,或是不兼容旧版本设置文件的情况发生。
这种时候如果盲目升级了版本,很容易导致应用无法运行。
要防止这类因版本导致的事故,重点在于把握安装的程序包的版本以及确定更新原则。
原则主要有下面几种,各位可以为每个程序包分别选择合适的原则。
- 完全固定
不考虑版本升级,仅使用指定版本的程序包。
- 固定至次版本号
固定主版本号和次版本号,允许加入安全更新和 Bug 修复。
◉ 通过 apt-get 安装程序包
用 apt-get 或 yum 从各个 Linux 发行版的程序包版本库安装程序包时,首先要确认各个发行版的更新原则。
本书所用的 Ubuntu 原则上只加入安全更新和 Bug 修复,不进行其他版本升级。
也就是说,环境本身就处于上述“固定至次版本号”原则的状态,我们不必多作修改。程序包升级时只会加入重大的 Bug 修复,不会更新主版本号和次版本号。
上述原则只要能满足我们的需求即可,没有什么特别需要注意的地方。现在我们可以通过简单的命令安装程序包,具体如下。
$ sudo apt-get install packagename
如果需要固定版本,则需要在程序包名称后面添加等号以及版本号。具体如下所示。
$ sudo apt-get install packagename=1.2.3-4ubuntu3
包名和版本号都可以用正则表达式。比如,如果只想固定到次版本号,则上述命令可以写成“1.2..*”的形式。
◉ 通过 pip 安装程序包
用 pip 安装程序包的流程在第 9 章中有详细介绍,不清楚的读者请参考该部分。
根据 11.1.4 节得出的结果编写 requirements.txt,修正版本指定,依照自身情况选择是否分离一部分到 dev-requires.txt 和 tests-require.txt。
完成 requirements.txt 之后,只需用 pip install -r requirements.txt 进行安装即可。
◉ 封闭环境中的安装
为没有网络连接的服务器搭建环境时,apt-get 和 pip 这种通过外部连接安装程序包的方法就不好用了。另外,程序包提供方(apt 版本库、PyPI、GitHub 等)故障或维护时也是同样道理。
为应对这种情况,我们可以将所需的程序包事先保存在版本库中,然后进行离线安装。我们把这些打包在一起的程序包叫作 bundle。
bundle 不但可以让我们离线安装程序包,还能有效固定版本以及削减搭建时间。
○ 通过 apt-get 安装 bundle
apt-get 安装的程序包都是以“.deb”格式发布的。用 apt-get download 命令可以获取我们需要的 deb 程序包。
$ mkdir aptcache && cd aptcache$ sudo apt-get download python3.4$ lspython3.4_3.4.0-2ubuntu1_amd64.deb
deb 程序包用 dpkg -i 命令安装。
$ sudo dpkg -i python3.4_3.4.0-2ubuntu1_amd64.deb
但是有一个问题,apt-get download 命令只能获取目标程序包,无法同时获取该程序包的依赖包。因此要用 aptcache depends 命令查看依赖包,然后在通过上述方法获取它们的 deb 程序包。
$ aptcache depends python3.4python3.4Depends: python3.4-minimalDepends: libpython3.4-stdlibDepends: mime-supportSuggests: python3.4-docSuggests: binutils
有时这些依赖包本身又依赖于其他程序包,如此循环下去不知何时是个头,所以我们需要一个方法来一次性获取所有相关的程序包。
实际上,用 apt-get install 命令安装程序包时,目标程序包及其所有依赖包的 deb 文件全都会被下载到缓存目录下。只要通过 -o 选项临时变更缓存目录,就能将目标程序包和其所有依赖包保存到任意目录下了。
$ sudo apt-get install python3.4 -o Dir::Cache::Archives=homemainte/aptcache
然而有一点需要注意,那就是这个方法无法获取已经安装的程序包,因此需要在初始状态的环境下(比如刚用 VM 搭建完毕的环境)进行操作。
○ 通过 pip 安装 bundle
旧版本的 pip 可以用 pip bundle 命令进行安装,但这个命令在 pip 1.5 被删除。1.5 之后开始使用 wheel。9.1.4 节详细介绍了 wheel 的相关内容,有需要的读者请参考该部分。
将所需程序包全部转换为 wheel。此时也通过 requirements.txt 指定程序包。
$ pip wheel -r requirments.txt
这个操作会在当前目录的 wheelhouse 目录下生成 wheel。我们将整个 wheelhouse 目录都添加到应用的版本库中。
在各环境下都可以通过下述命令从 wheelhouse 安装程序包。
$ pip install --no-index -f pathto/my/repository/wheelhouse -r requirements.txt
○ bundle 的维护
更新或添加新的程序包时,需要将程序包重新打包成 bundle。一旦漏掉这个步骤,应用可能出现在某些环境下能运行,在某些环境下却不能运行的情况,问题很难排查。
重新打包 bundle 是一件非常繁琐的工作,对于 deb 程序包来说尤其如此。开发时会频繁出现程序包的添加和更新,因此过早地 bundle 化会带来许多麻烦。毕竟开发环境很少遇到无法连接外部网络的情况,所以开发中建议使用 apt-get 和 pip install 来安装程序包。等到正式环境就绪再考虑 bundle 化也不迟。
程序包管理进入 bundle 阶段后,程序包的 bundle 化也可以交给构建服务器实现自动化。
11.1.5 中间件的设置
mysql、nginx 等中间件要根据使用环境进行设置。
我们往往需要在大量服务器上实施或更新中间件的设置,如果这些全都手动去完成,很容易出现疏漏,导致发生问题。因此,实现中间件设置的自动化才是上上之选。首先搞清需要自动化的内容,选出对象文件以及要修改的项目。本章用作例子的服务器结构中包含了 mysql、nginx 和 gunicorn,这里我们就来探讨一下这 3 个中间件的设置。
◉ 让中间件设置生效的方法
自动化更新中间件的设置文件需要以下步骤。
① 在版本库中管理对象文件
② 用模板语言重新描述可变部分
③ 将模板化的文件翻译过来直接覆盖原设置文件
步骤②和③提到的模板功能是 Ansible 标配的功能,关于 Ansible 的知识会在后面讲到。探讨设置内容的过程中需要我们手动改写设置文件,但最终所有设置都要通过上述步骤反映出来。 Ansible 采用 Jinja2 为模板编辑器,因此本节的模板文件都是以 Jinja2 格式描述的。
下面我们来看看用 Jinja2 格式描述设置文件可变部分的例子。
◉ mysql
MySQL 的设置描述在“etcmysql/conf.d/*”中。本例的设置文件为 etcmysql/conf.d/myproject.cnf。
讨论所需项目并编写文件。
[mysqld]bind_address = {{ MY_LOCAL_IP }}innodb_file_per_table = yesinnodb_buffer_pool_size = {{ MYSQL_INNODB_BUFFER_POOL_SIZE }}
在 mysql 的设置中,有些值会根据环境变化,比如根据服务器 IP 变化的 bind_address,根据服务器内存容量变更最优值的 innodb_buffer_pool_size 等。如果事先将这些值设置为变量,可以在中间件变更所在服务器时轻松完成设置更新。
◉ nginx
nginx 的设置描述在 etcnginx/conf.d/ap.conf 中。
nginx 的 conf.d 目录下设置有 default.conf 和 example_ssl.conf 两个文件,它们是用来显示 nginx 默认页的,与我们要搭建环境的服务器无关。因此要在探讨设置之前把这两个文件删除。
LIST 11.1 etcnginx/conf.d/ap.conf
upstream app {{% for server in NGINX_UPSTREAMS %}server {{ server }}:8000;{% endfor %}}server {listen {% if SSL %}443{% else %}80{% endif %};server_name {{ DOMAIN }};{% if SSL %}ssl on;ssl_certificate {{ SSL.CERTIFICATE }};ssl_certificate_key {{ SSL.KEY }};{% endif %}...}
需要在 upstream 指令中指定多个反向代理对象的服务器地址。这里我们是用变量 NGINX_UPSTREAMS 来存储服务器地址清单,并通过 for 语句来指定服务器地址的。
另外,我们还对 server 指令内是否存在 SSL 的设置进行了判断,并根据情况进行了 listen 端口的切换以及 ssl_certificate 的设置。出于预算原因,我们的项目并不是每个环境都使用 SSL,所以在这里保证了两种设定之间的简单切换。
可见,利用 Jinja2 模板的 if 和 for 能做出复杂的情况分类(LIST 11.1)。但有一点需要注意,过度使用控制语句会降低程序的可读性,增加修改的难度。
◉ gunicorn
让 gunicorn 通过 upstart 启动。创建 ectinit/myapp.conf 文件用作启动脚本,脚本内容如下。
upstart 的文档
description "myapp"start on (filesystem)stop on runlevel [016]respawnconsole logsetuid wwwsetgid wwwchdir {{ SOURCE_DIR }}/srcexec DJANGO_SETTINGS_MODULE={{ DJANGO_SETTINGS }} {{ SOURCE_DIR }}.venv/bin/gunicorn myapp.wsgi:application --bind={{ MY_LOCAL_IP }}:8000 --workers={{GUNICORN_WORKERS }}
上述例子将许多值替换为了变量。等到自动化的时候,这些地方就会发挥出其效果了。
- SOURCE_DIR
放置源码目录。虽然这个值很少因为环境而变,但换成变量能防止键入错误。
- DJANGO_SETTINGS
Django的settings文件需要根据环境而变。将它设置为变量之后,我们就可以在所有环境中应用同一个模板了。
- MY_LOCAL_IP
自身服务器的本地IP。直接拿mysql设置文件中定义的变量来用。
- GUNICORN_WORKERS
gunicorn的worker进程数。
将中间件的设置文件模板化时,需要考虑以下几个问题。
- 哪个设置值需要用变量替换
因环境而变的值,以及容易输入错的值(比如较长的文件路径)。
- 有多个中间件共用的变量吗
所有环境共享的值要设计成共用一个变量。
11.1.6 部署
部署就是将应用安置到环境中,使其进入可运行状态。
应用源码的安置、中间件设置的反映、中间件的重启等都属于部署工作。
本节将对上述 3 个工作进行说明。
◉ 源码的安置与更新
源码的安置用 Mercurial 的 clone 和 pull 即可轻松完成。利用标签和分支的功能,还能灵活应对回滚等操作。
如果有从各环境均可连接的公共密钥认证的中央版本库,那么最好从该版本库进行 clone 操作。这里我们假设中央版本库放在 myrepository.com。
clone 时用 11.1.3 节创建的 www 用户。访问版本库时用到的公共密钥和私有密钥要事先设置好。
本例中,我们把版本库设置在 varwww/myproject。
$ cd varwww/$ hg clone ssh://myrepository.com/myproject
执行 clone 操作之后就完成了应用源码的安置工作。更新工作只需要在各个服务器上对版本库进行 pull/update 即可。
$ cd varwww/myproject$ hg pull; hg update default
根据用途和环境不同可以将 update 位置替换为其他分支名或标签名,以灵活应对各种需求。实现自动化时只需将其改为变量,让其能够被替换即可。
专栏 没有可通过公共密钥认证的中央版本库时该怎么办
源码在 Mercurial 上管理时,只要我们能使用 clone 操作,就能将源码部署到环境中。但是如果中央版本库要求密码认证,那么每次 clone 都要输入密码,不利于自动化。
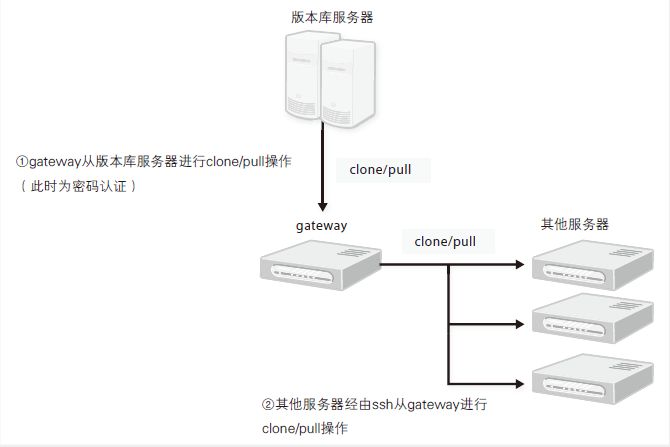
这种时候可以先将主版本库 clone 到 gateway 服务器上,然后各环境服务器再从 gateway服务器上的版本库进行clone,这样就能将输入密码的次数降到最少(图11.4)。
图 11.4 密码认证环境中的源码部署
◉ 中间件设置的反映
如 11.1.5 节所述,现阶段需要手动改写模板部分并上传至各环境,从而反映设置。
改写过程中要时刻注意设置文件有没有放错地方,有没有不小心改写了未加入管理的文件。
◉ 重启中间件
守护进程的启动和停止要使用 service 命令。
$ sudo service myapp restart
11.2 用 Ansible 实现自动化作业
上面我们大致总结了搭建环境的流程,现在来看看如何用 Ansible 实现自动化搭建环境。
11.2.1 Ansible 简介
Ansible 是基于 Python 研发的结构管理工具。不过它除了能进行结构管理之外,还能将许多针对服务器的操作自动化。
Ansible 本身由 Python 实现,但运行所需的设置文件均以 INI 格式或 YAML 格式描述,因此没有 Python 知识也能使用它。
另外,Ansible 不像 Chef 和 Puppet,它不需要在被操作的服务器上安装代理程序。只要服务器允许 ssh 登录,Ansible 就能执行相关操作。
Ansible 的主要概念有以下 5 个,我们随后将依次进行了解。
inventory
module
role
playbook
vars
NOTE
本书只介绍了 Ansible 的一部分功能,想了解其基本使用方法以及其他功能的读者可以参考 Ansible 的官方文档。
◉ inventory
inventory 是保存有执行对象(即主机)清单的 INI 格式的设置文件。主机通过 IP 地址或主机名指定。
192.168.0.1192.168.0.2192.168.0.3192.168.0.4192.168.0.5
Ansible 只能访问这里指定的主机,因此我们需要为不同的执行环境准备不同的 inventory 文件。
另外,主机可以用段进行分组。后面讲到的 playbook 和 vars 会用到这里定义的组。
[load-balancers]192.168.0.2[appservers]192.168.0.3192.168.0.4[db-servers]192.168.0.5
同一个主机可以同时出现在多个组里。比如在所有功能全由一台主机实现的开发环境中,inventory 就是下面这个样子。
[load-balancers]192.168.0.6[appservers]192.168.0.6[db-servers]192.168.0.6
Inventory - Ansible Documentation
专栏 Dynamic Inventory
inventory 文件除了可以指定 INI 格式的文件外,还可以指定可执行的脚本文件。我们将这类文件称为 Dynamic Inventory,适用于 Amazon EC2、Google Compute Engine、Docker 等需要频繁变更对象主机信息的情况。
Ansible 的版本库中有以上述 EC2 等为对象的示例 Dynamic Inventory,各位不妨加以参考。
Ansible plugins/inventory
https://github.com/ansible/ansible/tree/devel/contrib/inventory
Dynamic Inventory
◉ module
Ansible 以 module 为单位定义对服务器的操作。
Ansible 本身自带了许多 module,可以将它们组合起来,实现多种操作。
Module Index - Ansible Documentation
只要遵循一定的规则,module 可用任何语言来实现。当标准模块无法满足需求时,可以直接将现有脚本封装成 module 来使用。
Developing Modules - Ansible Documentation
执行 module 时以 task 形式描述自身的传值参数及其他参数。
- name: install nginxsudo: yesapt: name=nginx- name: install mysqlsudo: yesapt:name: mysql-serverstate: latestupdate_cache: yes
module 的传值参数以 key=value 的形式描述,各传值参数之间用空格区分。或者也可以用字典形式描述。传值参数较多时建议使用字典形式。
◉ role
role 可以批量重复利用 task。
role 的结构如 LIST 11.2 所示。
LIST 11.2 role 的目录结构
roles/+-- nginx/+-- tasks/+-- main.yml+-- handlers/+-- main.yml+-- vars/+-- main.yml+-- defaults/+-- main.yml+-- files/+-- nginx.repo+-- templates/+-- conf.d/+-- ap.conf+-- meta/+-- main.yml
- tasks
task定义。定义描述在该目录的main.yml中。
- handlers
handler的定义。由task定义的notify指定并调用。同上,在main.yml中描述。
- vars
该role使用的变量。同上,在main.yml中描述。
- defaults
上述变量的默认值。同上,在main.yml中描述。
- files
该role的task中,文件关联模块用到的文件。
- templates
该role的task中,template模块用到的Jinja2模板文件。
- meta
元信息。可定义role之间的依赖关系等。
专栏 role 的共享
role 也能像 PyPI 一样在 Web 上公开及共享。Ansible Galaxy1 是 Ansible 公司运营的网站,任何人都可以在这里免费上传和下载 role。
从 Ansible Galaxy 上下载 role 时,需要用 ansible-galaxy install 命令。这个命令只需安装 Ansible 就可以使用了。下载的 role 默认安装到 etcansible/roles 目录下,我们可以通过 -p 选项指定安装位置。
$ ansible-galaxy install username.rolename -p ROLES_PATH使用 ansible-galaxy init 命令可以生成包含 meta/main.yml 和tasks 目录等内容的样板文件。这个命令原本是为方便用户向 Ansible Galaxy 上传role 而设计的,但对于不想公开的 role 同样好用。因此各位在制作 role 的时候不妨试试这个命令。
$ ansible-galaxy init rolename
◉ playbook
playbook 是 YAML 格式的文件,用来定义要执行的处理。
- hosts: load-balancerssudo_user: mainteroles:- django
在 hosts 处指定对象服务器。这里指定 inventory 中定义的群名,可以对该群中的主机执行 task。指定为 all 则以所有主机为对象。
定义 sudo: yes 之后,该 playbook 将全部由 sudo 用户执行。sudo 用户默认为 root。想使用 root 以外的用户时需要在 sudo_user 处指定。
roles 处以 YAML 的列表形式指定要执行的 role。虽然可以在 tasks 处直接描述 task,但除了没有现成脚本的情况以外,还是建议使用 role。
Playbooks - Ansible Documentation
◉ vars
playbook、task、role 的模板中都可以使用变量。vars 的设置方法有很多种,这里只介绍比较有代表性的。
○ role 的 defaults
定义该 role 使用的变量的默认值。这里设置的值一般都是无法直接运行的临时值或空值,实际的值在 group_vars 中描述,等到运行时再进行覆盖。这样一来只需看 defaults 就能掌握 role 所需的全部变量,使 role 的重复利用成为可能。
○ group_vars
针对 inventory 中定义的组进行设置。Ansible 会读取 group_vars 目录下的 YAML 格式文件。文件名对应组名。另外,文件名为 all,会对所有组套用变量。
○ host_vars
针对 inventory 中定义的主机进行设置。Ansible 会读取 host_vars 目录下的 YAML 格式文件。文件名对应组名。
11.2.2 文件结构
与 Ansible 关联的文件全都要在一个目录下统一管理。本章示例的目录结构如 LIST 11.3 所示。
LIST 11.3 ansible 脚本群的文件结构
+-- deployment/+-- group_vars/+-- all...+-- host_vars/+-- roles/+-- environ+-- nginx+-- mysql...+-- inventory/+-- production+-- dev...+-- site.yml+-- ap.yml+-- lb.yml...
这些文件也都要放在版本库中进行管理。管理方法可以有以下 2 种。
创建专用的版本库进行管理
与应用的源码放在同一个版本库中进行管理
◉ 在专用的版本库中管理
如果没必要或者不希望应用的开发与环境搭建同步,可以把源码与 Ansible 的文件群放在不同版本库中进行管理。
Ansible 关联文件的数量通常很大,如果不想让源码的版本库太复杂,同样可以用这个方法。
◉ 与应用的源码放在同一个版本库中进行管理
在应用的版本库中专门创建一个用于管理这些文件的目录。这样做的好处是能在开发过程中让应用开发与环境搭建内容的变更对应起来。
我们大部分项目都采用了这种方法。没有特殊要求的情况下文件路径以 myproject/deployment/ 为基准。
11.2.3 执行 Ansible
创建好的脚本用 ansible-playbook 命令执行。对象环境的选择是通过切换 inventory 来实现的,因此要用 -i 选项明确指定 inventory。
$ ansible-playbook -i inventory/production.ini site.yml
在本章的结构中,会频繁用到指定了 tag 的执行操作。-t 选项可以在执行时指定任意标签。
$ ansible-playbook -i inventory/production -t deploy site.yml
11.2.4 与最初确定的结构相对应
11.1 节确定的搭建内容可以与 Ansible 的各概念对应起来。图 11.5 与图 11.2 相对应。
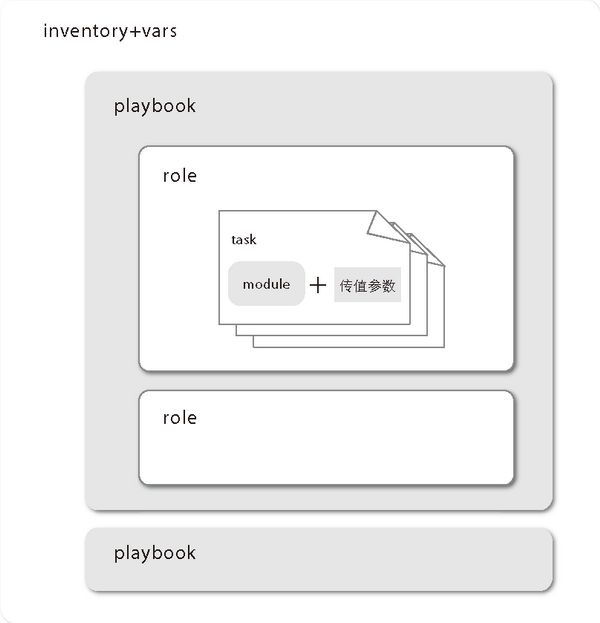
图 11.5 Ansible 的概念与服务器搭建内容的对应
- 环境 = inventory + vars
针对各个环境(正式环境、开发环境、过渡环境等)编写inventory文件。另外,Ansible 会自动读取与inventory的描述内容相对应的vars。
- 服务器组 = inventory 的段
前面定义的服务器组在inventory中是以段形式定义的,各段中列举了主机。
- 各服务器组的搭建流程 = playbook
给各个组分别创建lb.yml、ap.yml、db.yml、gateway.yml文件,将组设置成hosts。另外,创建一个include所有playbook的playbook,方便一次性搭建所有环境。这个playbook一般命名为site.yml。
- 针对各个中间件的搭建流程 = role
以中间件为单位创建role,各服务器组用对应其所需role的playbook统一管理。
- 其他环境设置 = role
不依赖于特定中间件的环境设置(创建用户等)也以role形式描述。
11.2.5 将各步骤 Ansible 化
◉ playbook/role 的设计
着手细节步骤之前,要先探讨搭建流程的各个步骤应该整合到怎样的 role/playbook 之中。
我们对前面学习的搭建操作流程进行如下分类,然后分割到各个 role 中。
① 应该套用到所有服务器中的操作
除了本章讲到的创建用户之外,比较常见的还有 ntp 和时区设置。
我们将这些处理整合到名为 environ 的 role 中,对所有服务器组进行套用。
② 特定服务器组使用的中间件的设置
为每个中间件编写一个 role,以达到分割的目的。
③ 部署
包含到对象中间件的 role 里。设置 tag 以保证能单独执行部署操作。然后将分割好的 role 组合成 playbook。以下是正式环境的例子。
- hosts: appserversroles:- environ- python- repository- django- appserver- hosts: db-serversroles:- environ- mysql- hosts: load-balancersroles:- environ- nginx
大致的设计完成后就可以开始实际编写所需操作,边测试边调整了。
◉ 用户设置
用户的创建和设置可以用 user 模块完成。
tasks:- user: name=mainte- user: name=www
借助 file 模块向 sudoers.d 目录下放置文件。本例的文件内容比较简单,因此可以通过 content 传值参数直接描述脚本内容来进行设置。
tasks:- file:dest: etcsudoers.d/maintecontent: "%mainte ALL=(ALL) NOPASSWD:ALL"
公开密钥的设置用 authorized_keys 模块。传值参数处需要些公开密钥的字符串,由于字符串太长,我们用 group_vars/all 文件的变量代替。
mainte_pubkey: AAAA1234512345...
tasks:- authorized_keys:user: maintekey: "{{mainte_pubkey}}"
密钥文件在版本库中管理,通过 file 模块放置。这里不要忘记修改权限。
tasks:- file:src: mainte_seckeydest: homemainte.sshid_rsamode: 0600
本例的 src 只指定了文件名,它在这里其实是相对路径,该相对路径是基于下面两个中的一个。
playbook 的目录
包含该 task 的 role 的 files 目录
◉ deb 程序包的安装
安装 deb 程序包时使用 apt 模块。指定版本的方式与 apt-get 相同。
- apt:name: mysql-server-5.5=5.5.40-0ubuntu0.14.04.1
用 with_items 可以将多个程序包的安装流程描述在一个 task 中。
- apt:name: "{{ item }}"with_items:- mysql-server-5.5=5.5.40-0ubuntu0.14.04.1- nginx
◉ 通过 pip 安装程序包
Ansible 有兼容 pip 的 pip 模块,使用前需要先安装 pip。
- name: install pipshell: curl -L https://bootstrap.pypa.io/get-pip.py | python creates=usrlocal/bin/pip
使用 shell 模块时,如果传值参数 creates 处指定的文件已经存在,该步骤将被强制跳过。本例是通过检查是否存在 userlocal/bin/pip 来判断是否需要执行该步骤的。
由于这些模块都可以自由执行命令,因此幂等性需要我们自己来验证。只要给传值参数 creates 指定了文件,当被指定的文件存在时,当前步骤就会被强制跳过。本例是通过检查 userlocal/bin/pip 是否存在来判断是否需要执行该步骤。
安装完成后 pip 模块就能用了。
- name install packagespip: name={{item}}with_items:- virtualenv
我们在第 1 章中也了解到,应用所需的程序包要安装在 virtualenv 环境中。因此我们把搭建 virtualenv 环境的步骤也写了进来。
- name: create virtualenvsudo_user: wwwcommand: virtualenv venv chdir=varwww/ creates=venv/bin/activate- name: installsudo_user: wwwpip: requirements=varwww/myproject/requirements.txt virtualenv=varwww/venv
pip 模块会向 virtualenv 参数处指定的环境安装程序包,所以我们在这里指定虚拟环境的路径。另外,只把 name 参数替换为 requirements 参数并指定 requirements.txt 的路径,就可以使用 requirements.txt 了。
◉ 中间件设置的反映
放置、更新设置文件要用 template 模块。
之前我们在设置文件中使用了一些尚未定义的变量,现在在 group_vars 和 role 的 defaults/main.yml 中定义它们。比如对 nginx.conf 中使用的变量要作如下定义(LIST 11.4)。
LIST 11.4 group_vars/all
DOMAIN: myproject.example.comNGINX_UPSTREAMS:- 192.168.0.3- 192.168.0.4SSL:CERTIFICATE: myproject.crtKEY: myproject.key
变量准备完毕后开始写放置配置文件的 task。涉及多个文件时推荐使用 with_items。
tasks:- template:src: "{{ item }}"dest: etcnginx/"{{ item }}"with_items:- conf.d/gunicorn.conf
template 模块的文件路径引用的是包含该 task 的 role 的 templates 目录。保持 templates 目录的相对路径与文件放置目标目录的相对路径一致能够简化描述。
◉ 部署
部署的 task 也写在各个 role 的 tasks 中。描述时要给该 task 设置 tag。设置 tag 能让我们单独拿出与部署相关的 task 来执行。
按照本章的结构,我们定义下述 tag。
- configure
设置文件的更新
- update
源码的更新
- reload
重新加载中间件设置
- deploy
执行update、configure、reload
◉ 设置的更新
给在“中间件设置的反映”部分编写的 template 模块的 task 添加 configure 和 deploy 标签。
- template:src: "{{ item }}"dest: etcnginx/"{{ item }}"with_items:- conf.d/gunicorn.conftags:- configure- deploy
◉ 中间件的重启
经由 sysvinit 或 upstart 启动的中间件可以用 service 模块重启或重新加载。
- service:name: nginxstate: reloadedtags:- reload- deploy
如果使其与 Ansible 的 Notify 机制相结合,则可以规定仅在设置文件被修改时自动重新加载中间件。
通过 Notify 调用的 task 在 role 的 handlers/main.yml 中描述。name 会被视为标识符,所以要指定一个在整个项目中独一无二的名字。
LIST 11.5 roles/nginx/handlers/main.yml
- name: reload nginxservice:name: nginxstate: reloaded
接下来在调用方的 notify 参数处指定通过 LIST 11.5 设置的 name。这个 task 的返回值 changed 为 True 时(对 template 模块而言是文件内容被更新时)将执行 notify 指定的 task(LIST 11.6)。
LIST 11.6 roles/nginx/tasks/main.yml
...- name: configure nginxtemplate:src: "{{ item }}"dest: etcnginx/"{{ item }}"with_items:- conf.d/gunicorn.conftags:- configure- deploynotify:- reload nginx
使用 Notify 可以让我们不必分神去注意重新加载设置的问题,但会使单独执行重新加载或重启,以及只修改设置不重启等类似操作变得难以实现。因此需要根据项目的实际情况选择合适的方法。
◉ 源码的更新
通过 Mercurial 放置源码的操作可以用 hg 模块来完成,但需要事前完成安装 Mercurial、创建目录、设置权限等准备工作。
把这一系列工作整合到名为 repository 的 role 中,让需要放置源码的服务器组能够使用该 role。
- pip:name: mercurial- file:state: directorydest: varwww/owner: wwwmode: 755- hg:repo: ssh://user@myrepository.com/myprojectdest: varwww/myprojectrevision: "{{ revision }}"tags:- update- deploy
为了能够更新成任意版本而不仅限于 default,这里将 hg 模块的传值参数 revision 设为变量。
根据需要还可以将放置源码的目标项目名、版本库 URL 也设为变量,方便替换和引用,从而灵活应对多种需求。
11.2.6 整理Ansible 的执行环境
本例中的环境如 11.1.1 节所述,除 gateway 服务器以外全都无法从外部进行 ssh,因此我们无法从本地环境操作所有服务器。另外,如果给所有相关人员的本地环境中都搭建 Ansible 的执行环境,那么每次调换或新增负责人时都要搭建一次环境。
这种时候,最好的解决办法就是在一个项目全体成员共享的、可连接环境中所有服务器并且与应用运行没有直接关系的 gateway 服务器上搭建 Ansible 的执行环境。
虽然我们也希望通过 Ansible 完成 gateway 服务器的整理,但这又涉及到用 Ansible 整理 Ansible 执行环境的自举问题。
这里我们从手头环境执行 Ansilbe,以解决这一问题。但有一点要注意,执行这部分操作时 gateway 服务器上还不存在 mainte 用户。虽然我们设想用 mainte 进行维护工作,但构建环境时无法使用该用户。所以要为 root 或 ubuntu 用户创建一份临时的 inventory 文件(LIST 11.7 ~ LIST 11.9)。
LIST 11.7 gateway 搭建时所需的 ini
[gateway]gateway.example.com ansible_ssh_user=ubuntu
LIST 11.8 gateway.yml
- hosts: gatewaysudo: yesroles:- environ- python- ansible
LIST 11.9 roles/ansible/tasks/main.yml
- name: install Ansiblepip: name=ansible
11.3 小结
本章讲解了探讨环境搭建流程的思路以及自动化搭建环境的方法。
我们往往觉得环境的运行没有什么技术含量,而且很难看到付诸其中的努力。但是,应用能持续平稳地运行,毫无疑问是高效环境搭建以及维护的功劳。
从长远角度看,搭建环境的自动化对提高搭建环境及维护的效率有十分明显的效果。另外,搭建流程自动化使得项目成员能够自由地搭建个人开发环境,能大幅提高整个项目的生产能力。
因此推荐各位搭建环境时多注意稳定和高效两个方面。另外,为了让项目稳定高效运转,建议导入环境搭建的自动化。
专栏 自动化的“度”在哪里
当我们为实现自动化而写搭建流程的详细列表时,会发现搭建所需的步骤比我们想象中要多得多。其中有些内容自动化起来很麻烦,有些内容又很难自动化。于是这些步骤要自动化到一个什么“程度”便成了重要的研究课题。
刚开始导入自动化时,看到服务器自己搭建环境,人们往往会得意忘形,希望把所有步骤全都自动化。然而我们认为这样做是错的。Ansible 的 Playbook 虽然能极简洁地描述搭建步骤,但量堆积到一定数量同样会使可读性变差。shell 模块确实可以强行自动化一些繁杂的步骤,不过日后读和改的时候肯定会遇到麻烦。
我们认为,简化流程是流程自动化工作的一部分。大部分自动化工具都把构建时经常遇到的操作进行了简化,使得我们能轻松执行这些操作,Ansible 更是将这些机制以标准模块的形式提供给了我们。难以用这些标准模块实现的操作可以认为是冗余的或者是错的,应该考虑删除或者改良。有些时候,如果能简化流程或结构,考虑改变架构也是值得的。
通过自动化实现繁琐的搭建流程远不如找一个能简单完成环境搭建的方法来得有价值。因此不要想着用自动化去掩盖复杂的操作,而是要以自动化为契机着手改善流程。
专栏 巧用备份
搭建环境实现自动化后,每次向组中添加服务器都要整体从零搭建环境。但是,一遍遍重新搭建相同结构的服务器是一件非常浪费时间的事。如果我们采用的基础设备可以使用备份或服务器镜像,那么直接复制现有的服务器备份要远比重新搭建环境轻松且安全。
另外,添加新的服务器组时,由于全新服务器中不存在维护用户,所以每次都要面对自举问题。如果能从已有维护用户的状态开始搭建,那么整个过程将轻松不少。
出于以上原因,我们在搭建时会按照下述方针进行备份,缩短搭建时间。
在执行了environ role 的状态下做一次备份
基于上述备份给每组里的每一台服务器搭建环境并备份,有多台服务器组成的服务器组基于该备份搭建环境。
虽然看服务器自动搭建环境是一种享受,但多余操作还是应该尽量减少。
