附录 C Python 的科学
在她统治期间,
蒸汽无所不能的力量被用于海陆之间,
这些都强烈地依赖于
科学上的突破。
——1887 年维多利亚女王执政 50 周年纪念颂歌,麦金泰尔 1
1詹姆斯 · 麦金泰尔,加拿大诗人。
最近几年,由于大量实用软件包的出现(本章中会见到这些软件包),Python 在科学研究者中愈加流行。如果你是科学工作者或者学生,可能用过像 MATLAB 或者 R 这样的工具,也可能使用过像 Java、C、C++ 这样的传统编程语言。而本章,你将会见识 Python 为了科学研究和出版而搭建的完美平台。
C.1 标准库中的数学和统计
首先重温一下标准库,看看那些我们之前不曾提到过的模块和功能。
C.1.1 数学函数
Python 的标准 math(https://docs.python.org/3/library/math.html)库中汇集了大量的数学函数。通过 import math 即可将它们引入到你的程序中进行使用。
math 库会引入一些常量,例如 pi 和 e:
>>> import math>>> math.pi>>> 3.141592653589793>>> math.e2.718281828459045
组成 math 库的大部分内容都是函数,我们不妨先来看一些最常用的。
fabs() 用于获得绝对值:
>>> math.fabs(98.6)98.6>>> math.fabs(-271.1)271.1
你还可以获得向下取整的整数(floor())和向上取整的整数(ceil()):
>>> math.floor(98.6)98>>> math.floor(-271.1)-272>>> math.ceil(98.6)99>>> math.ceil(-271.1)-271
使用 factorial() 计算阶乘(在数学中以 n! 表示):
>>> math.factorial(0)1>>> math.factorial(1)1>>> math.factorial(2)2>>> math.factorial(3)6>>> math.factorial(10)3628800
使用 log() 计算自然对数(以 e 为底):
>>> math.log(1.0)0.0>>> math.log(math.e)1.0
如果你想使用别的数字作为 log 的底,可以把它当作第二个参数传入函数:
>>> math.log(8, 2)3.0
pow() 做的工作与上面正好相反,它用于计算一个数的指数:
>>> math.pow(2, 3)8.0
Python 内置的指数运算符 ** 也可以进行同样的计算,只不过当底数和指数都是整数时,用 ** 计算得到的结果也是整数,不会被自动转化为浮点数:
>>> 2**38>>> 2.0**38.0
使用 sqrt() 得到平方根:
>>> math.sqrt(100.0)10.0
别想着调戏 sqrt() 函数,你的小把戏它都见过:
>>> math.sqrt(-100.0)Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: math domain error
常见的三角函数都可以使用,这里我只列出它们的名字:sin()、cos()、tan()、asin()、acos()、atan()、atan2()。如果你还记得勾股定理,math 库还包含 hypot()2 函数帮你计算给定两直角边对应的斜边长度:
2函数名 hypot 是 hypotenuse 的缩写,意思是斜边。——译者注
>>> x = 3.0>>> y = 4.0>>> math.hypot(x, y)5.0
如果你不放心这些神奇的函数,可以自己验证一下,看看它们是否能正常工作:
>>> math.sqrt(x*x + y*y)5.0>>> math.sqrt(x**2 + y**2)5.0
最后一组函数用于进行角坐标转换:
>>> math.radians(180.0)3.141592653589793>>> math.degrees(math.pi)180.0
C.1.2 使用复数
基本 Python 语言(即不引入任何第三方库的 Python)就支持复数运算。所谓复数,就是由实部(real)和虚部(imaginary)两部分组成的数:
>>> # 一个实数... 55>>> # 一个虚数... 8j8j>>> # 一个虚数... 3 + 2j(3+2j)
由于虚数 i(在 Python 中用 1j 表示)被定义为 -1 的平方根,因此我们可以执行下列 运算:
>>> 1j 1j(-1+0j)>>> (7 + 1j) 1j(-1+7j)
一些与复数计算相关的函数都被纳入了 cmath(https://docs.python.org/3/library/cmath.html)模块。
C.1.3 使用小数对浮点数进行精确计算
计算机中的浮点数和我们在学校学的实数有些差别。由于计算机的 CPU 是针对二进制运算设计的,因此它无法准确表示那些不是 2 的幂次方的数:
>>> x = 10.0 / 3.0>>> x3.3333333333333335
天呐,最后的那个 5 是怎么回事?应该一直是 3 才对啊。使用 Python 的 decimal(https://docs.python.org/3/library/decimal.html)模块,你可以把数字按任意你所需的精度表示。这种对于涉及钱的计算非常重要。美元的最小精度是 1 美分(1 美元的百分之一),因此当我们需要用美元和美分计算钱的数目时,我们期望最终的结果精确到美分。如果我们使用像 19.99 和 0.06 这样的浮点数来表示美元和美分的话,在开始实际计算前,我们的数据精度就会有所损失(浮点数的最后几位数字会像上面的例子一样产生误差)。那么如何解决这个问题呢?很简单,使用 decimal 模块代替即可:
>>> from decimal import Decimal>>> price = Decimal('19.99')>>> tax = Decimal('0.06')>>> total = price + (price * tax)>>> totalDecimal('21.1894')
我们使用字符串值初始化了价格(price)和税收(tax)变量,以此隐性指明数据的有效数字。total 的计算过程保留了所有有效数字,但是我们只需要精确到最近的美分:
>>> penny = Decimal('0.01')>>> total.quantize(penny)Decimal('21.19')
上例中,也许你使用浮点数和取整运算能获得一样的结果,但这并不总能成功。你也可以把所有数都乘以 100,然后使用整数进行运算,但小心,这早晚也会产生问题。在 www.itmabyahack.com(http://www.itmaybeahack.com/homepage/books/nonprog/html/p13_modules/p13_c03_decimal.html)上,有许多关于上述计算精度损失问题的讨论。
C.1.4 使用分数进行有理数运算
你可以使用标准 Python 中的 fractions(https://docs.python.org/3/library/fractions.html)模块将有理数表示为分子除以分母的形式。下面是一个简单的例子,计算三分之一乘以三分之二:
>>> from fractions import Fraction>>> Fraction(1, 3) * Fraction(2, 3)Fraction(2, 9)
使用浮点数作为参数会造成结果不准确,你可以在 Fraction 中使用 Decimal 作为替代传入:
>>> Fraction(1.0/3.0)Fraction(6004799503160661, 18014398509481984)>>> Fraction(Decimal('1.0')/Decimal('3.0'))Fraction(3333333333333333333333333333, 10000000000000000000000000000)
使用 gcd 函数可以获得两个数的最大公约数:
>>> import fractions>>> fractions.gcd(24, 16)8
C.1.5 使用array创建压缩序列
Python 中的列表类型更像是一个链表而不是数组。如果你需要一个元素类型全都相同的一维序列,可以使用数组(array,https://docs.python.org/3/library/array.html)类型。与列表相比,数组占用空间更小,却支持许多列表方法。使用 array(typecode, initializer)可以创建一个新的数组。其中 typecode 定义了数据类型(例如 int 或 float),另一个可选的参数 initializer 包含了初始化的值,它可以是一个列表、字符串或者其他可迭代类型。
在实际工作中,我从未使用过这个包。数组是一个相对低层次的数据结构,在表示图像数据时比较有用。如果你使用数组——尤其是多维数组——仅仅是为了进行数值计算的话(例如矩阵运算),最好还是使用 NumPy 代替,随后就会讲到这个包。
C.1.6 使用statistics进行简单数据统计
从 Python 3.4 开始,statistics(https://docs.python.org/3.4/library/statistics.html)被纳入了标准模块。它包含许多实用函数:平均值、中数、求模、标准差、方差,等等。输入的数据可以是序列型的(列表或元组)也可以是不同类型的数值(整数、浮点数、小数、分数)组成的迭代型。其中,mode 函数还可以接受字符串类型的输入。SciPy 和 Pandas 包含更多的统计函数,随后会介绍。
C.1.7 矩阵乘法
据说从 Python 3.5 开始,@ 字符将不再仅限于处理字符时使用了。它仍然还会具有修饰符的作用,但同时还将可以用于矩阵乘法(http://legacy.python.org/dev/peps/pep-0465/)。但在它真正到来之前,NumPy 仍然是你进行矩阵运算的最佳选择。
C.2 科学Python
本附录剩下的内容会涵盖一些与科学、数学相关的第三方 Python 包。你可以选择分开安装它们,但我建议通过安装某个科学计算版本的 Python 从而一口气把它们全都安装了。下面是几种主流的科学版 Python。
这个包是免费的、可扩展的、不断更新的科学计算版 Python。它同时支持 Python 2 和 Python 3,而且不会对你系统中已经安装的 Python 产生任何副作用。
- Enthought Canopy(https://www.enthought.com/products/canopy/)
这个包既有免费版本也有商业版本。
- Python(x,y)(https://code.google.com/p/pythonxy/)
这个包仅可在 Windows 下使用。
- Pyzo(http://www.pyzo.org/)
这个包是建立在 Anaconda 的一些工具上的,同时添加了一些其他的实用工具。
- ALGORETE Loopy(http://algorete.org/)
这也是一个建立在 Anaconda 上的包,同样添加了一些其他内容。
我建议安装 Anaconda。虽然它的体积比较庞大,但包含了本附录中会使用到的所有工具,一劳永逸。你可以参考附录 D,学习如何安装 Python 3 版本的 Anaconda。本附录的后半部分内容会假定你已经安装好了所有所需的包,不管你是分开安装还是通过 Anaconda 安装。
C.3 Numpy
NumPy(http://www.numpy.org/)是 Python 在科学工作者中流行起来的主要原因之一。你可能听到过类似这样的说法:像 Python 这样的动态语言要比像 C 语言一样的编译型语言效率低,甚至比像 Java 这样的解释型语言的效率也要低。NumPy 是为了进行快速多维矩阵运算而设计的,和 FORTRAN 这样的科学性语言有些类似。你可以同时获得接近 C 语言的运算速度和 Python 的友好(便于编写使用)接口。
如果你已经下载安装了 Python 的某一个科学计算版本,应该已经拥有 NumPy 了。如果没有的话可以前往 NumPy 的下载页(http://www.scipy.org/scipylib/download.html)按教程下载安装。
在开始使用 NumPy 之前,你需要理解它的核心数据结构:多维数组,用 ndarray(N-dimensional array)或仅仅 array 表示。和 Python 的列表、元组不同,多维数组中的元素必须是同一类型的。NumPy 把数组的维数称为它的秩(rank)。一维数组就像是一行数据,二维数组就像是一张包含行列的表格,三维数组就像是一个魔方。每一维的长度不要求相同。
NumPy 中的
array和标准 Python 中的array并不是一回事。本附录的后面部分,当我说数组时,我指的都是 NumPy 里面的数组。
为什么需要数组类型呢?
科学数据总是包含大量序列数据;
对这种数据进行的科学计算经常包括矩阵数学、回归运算、模拟以及其他需要同时对许多数据点进行运算的操作;
NumPy 对数组的处理速度要远远超过它处理标准 Python 里列表或元组的速度。
NumPy 数组有多种创建方式。
C.3.1 使用array()创建数组
你可以利用普通的列表或元组生成数组:
>>> b = np.array( [2, 4, 6, 8] )>>> barray([2, 4, 6, 8])
ndim 属性会返回数组的秩:
>>> b.ndim1
数组中所有元素的个数由 size 记录:
>>> b.size4
每一秩(维)的元素数量由 shape 返回:
>>> b.shape(4,)
C.3.2 使用arange()创建数组
NumPy 中的 arange() 与 Python 中的标准 range() 类似。如果你在调用 arange() 时只传入了一个整形参数 num,它会返回一个包含了从 0 到 num-1 的整数的 ndarray:
>>> import numpy as np>>> a = np.arange(10)>>> aarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>>> a.ndim1>>> a.shape(10,)>>> a.size10
如果传入两个参数,则 arange() 方法会返回从第一个参数到最后一个参数减一的全部整数的数组:
>>> a = np.arange(7, 11)>>> aarray([ 7, 8, 9, 10])
除此之外,你还可以把自己指定的步长(默认是 1)作为第三个参数:
>>> a = np.arange(7, 11, 2)>>> aarray([7, 9])
目前为止,我们的例子中出现的都是整数,但事实上,使用浮点数也能完美运行:
>>> f = np.arange(2.0, 9.8, 0.3)>>> farray([ 2. , 2.3, 2.6, 2.9, 3.2, 3.5, 3.8, 4.1, 4.4, 4.7, 5. ,5.3, 5.6, 5.9, 6.2, 6.5, 6.8, 7.1, 7.4, 7.7, 8. , 8.3,8.6, 8.9, 9.2, 9.5, 9.8])
最后一个小技巧,dtype 参数可以指定 arange 产生的值的类型:
>>> g = np.arange(10, 4, -1.5, dtype=np.float)>>> garray([ 10. , 8.5, 7. , 5.5])
C.3.3 使用zeros()、ones()和random()创建数组
zeros() 会返回一个全都是 0 的矩阵。zeros 接收的参数是元组,用于指定你想要创建的矩阵的形状。下面是一个一维数组的例子:
>>> a = np.zeros((3,))>>> aarray([ 0., 0., 0.])>>> a.ndim1>>> a.shape(3,)>>> a.size3
下面创建的矩阵的秩为二:
>>> b = np.zeros((2, 4))>>> barray([[ 0., 0., 0., 0.],[ 0., 0., 0., 0.]])>>> b.ndim2>>> b.shape(2, 4)>>> b.size8
另一个特殊的函的矩阵中所有值都相等: 数 ones(),它创建
>>> import numpy as np>>> k = np.ones((3, 5))>>> karray([[ 1., 1., 1., 1., 1.],[ 1., 1., 1., 1., 1.],[ 1., 1., 1., 1., 1.]])
最后一个初始化函数可以创建由 0.0 到 1.0 之间的随机数组成的矩阵:
>>> m = np.random.random((3, 5))>>> marray([[ 1.92415699e-01, 4.43131404e-01, 7.99226773e-01,1.14301942e-01, 2.85383430e-04],[ 6.53705749e-01, 7.48034559e-01, 4.49463241e-01,4.87906915e-01, 9.34341118e-01],[ 9.47575562e-01, 2.21152583e-01, 2.49031209e-01,3.46190961e-01, 8.94842676e-01]])
C.3.4 使用reshape()改变矩阵的形状
目前为止,你可能还是觉得数组能做的事情和列表、元组没有什么区别。其实,数组能做许多列表和元组做不到的事情,例如你可以使用 reshape() 函数对数组的形状进行修改:
>>> a = np.arange(10)>>> aarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])>>> a = a.reshape(2, 5)>>> aarray([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])>>> a.ndim2>>> a.shape(2, 5)>>> a.size10
你可以将刚才的数组转化为其他形状:
>>> a = a.reshape(5, 2)>>> aarray([[0, 1],[2, 3],[4, 5],[6, 7],[8, 9]])>>> a.ndim2>>> a.shape(5, 2)>>> a.size10
将表示形状的元组赋值给 shape 属性也可以达到相同的效果:
>>> a.shape = (2, 5)>>> aarray([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
形状的唯一限制是秩的乘积需要等于数组中元素的个数(上例中是 10):
>>> a = a.reshape(3, 4)Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: total size of new array must be unchanged
C.3.5 使用[]访问元素
一维数组的使用和列表类似:
>>> a = np.arange(10)>>> a[7]7>>> a[-1]9
然而,如果数组的形状不是一维的,就需要用逗号分开指定每一维的索引了:
>>> a.shape = (2, 5)>>> aarray([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])>>> a[1,2]7
这和二维的 Python 列表的访问方法有所不同:
>>> l = [ [0, 1, 2, 3, 4], [5, 6, 7, 8, 9] ]>>> l[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]>>> l[1,2]Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: list indices must be integers, not tuple>>> l[1][2]7
还有一件事情。分片操作仍然可用,只不过你需要将它们全都放到一组方括号中。再次创 建我们熟悉的测试数组:
>>> a = np.arange(10)>>> a = a.reshape(2, 5)>>> aarray([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
使用分片操作访问第一行中从偏移量为 2 的元素开始的所有元素:
>>> a[0, 2:]array([2, 3, 4])
接下来试着获取最后一行的倒数三个元素:
>>> a[-1, :3]array([5, 6, 7])
你还可以使用分片同时给多个元素赋值。例如下面的语句将每一行的第 2 列和第 3 列(偏移位置)元素赋值为 1000:
>>> a[:, 2:4] = 1000>>> aarray([[ 0, 1, 1000, 1000, 4],[ 5, 6, 1000, 1000, 9]])
C.3.6 数组运算
创建数组和数组变形太有趣了,以至于我们差点忘了介绍如何对数组中的数据进行处理。下面要介绍的第一个技巧是使用 NumPy 中重定义的乘法运算符(*)对 NumPy 数组中的
所有元素进行批量乘法:
>>> from numpy import>>> a = arange(4)>>> aarray([0, 1, 2, 3])>>> a = 3>>> aarray([0, 3, 6, 9])
如果你想要对一个普通 Python 列表中所有元素进行乘法操作,需要使用循环或者列表迭代:
>>> plain_list = list(range(4))>>> plain_list[0, 1, 2, 3]>>> plain_list = [num * 3 for num in plain_list]>>> plain_list[0, 3, 6, 9]
这种批量操作同样适用于加法、减法、除法以及其他一些 NumPy 库中的函数。例如,通过组合使用 zeros() 和 +,你可以将新创建的数组中所有元素初始化为某一个相同的值:
>>> from numpy import *>>> a = zeros((2, 5)) + 17.0>>> aarray([[ 17., 17., 17., 17., 17.],[ 17., 17., 17., 17., 17.]])
C.3.7 线性代数
NumPy 包含许多与线性代数有关的函数,比如我们定义下面这组线性方程:
4x + 5y = 20x + 2y = 13
如何对 x 和 y 进行求解?首先需要创建两个矩阵:
系数矩阵(coefficient,
x和y的系数组成的矩阵)因变量矩阵(等式右侧)
>>> import numpy as np>>> coefficients = np.array([ [4, 5], [1, 2] ])>>> dependents = np.array( [20, 13] )
现在使用 linalg 模块中的 solve() 函数:
>>> answers = np.linalg.solve(coefficients, dependents)>>> answersarray([ -8.33333333, 10.66666667])
运行结果显示 x 的值大约是 -8.3,y 的值大约是 10.6。这个解正确吗?
>>> 4 answers[0] + 5 answers[1]20.0>>> 1 answers[0] + 2 answers[1]13.0
觉得有些繁琐?那看看下面的做法如何。直接让 NumPy 为我们计算两个矩阵的点积(dot product),以省去一些敲打键盘的时间:
>>> product = np.dot(coefficients, answers)>>> productarray([ 20., 13.])
如果得到的解是正确的,那么 product 数组中的值应该与 dependents 中的值相近。你可以使用 allclose() 函数来检查两个数组是否近似相等(点积得到的结果可能与因变量矩阵不完全相同,因为存在浮点小数的取整问题):
>>> np.allclose(product, dependents)True
NumPy 还提供了与多项式、傅立叶变换、统计以及一些概率分布相关的模块。
C.4 SciPy库
SciPy(http://www.scipy.org/)是一个建立在 NumPy 的基础之上的库,它包含了更多的数学函数和统计函数。SciPy 发布包(http://www.scipy.org/scipylib/download.html)包括 NumPy、SciPy、Pandas(本附录后面会讲到)以及一些其他的库。
SciPy 包含许多模块,可以完成下面这些计算任务:
优化
统计
插值
线性回归
积分
图像处理
信号处理
如果你曾经使用过其他的科学计算工具,就会发现 Python、NumPy、SciPy 可以涵盖商业的 MATLAB(http://cn.mathworks.com/products/matlab/)以及开源的 R(http://www.r-project.org/)中的大部分功能。
C.5 SciKit库
同样遵循根据已有的软件包进行扩展的模式,SciKit(https://scikits.appspot.com/scikits)是一组建立在 SciPy 基础上的科学计算软件包。SciKit 的特长在于机器学习(machine learning)。它支持建模、分类、聚类以及多种机器学习算法。
C.6 IPython库
IPython(http://ipython.org/)的诸多优点让它非常值得我们花时间学习,下面列出了其中几点:
改进的交互式解释器(简单来说,就是本书中一直使用的
>>>的扩展);在基于网页的笔记本(notebook)中发布代码、图形、文本以及其他形式的文件;
支持并行化计算(parallel computing,http://ipython.org/ipython-doc/stable/parallel/parallel_intro.html)。
我们主要来看看解释器和笔记本部分。
C.6.1 更好的解释器
IPython 有分别针对 Python 2 和 Python 3 的两个不同的版本,在安装 Anaconda 或其他科学计算版 Python 时会自动安装。使用 ipython3 运行与 Python 3 对应的版本。
$ ipython3Python 3.3.3 (v3.3.3:c3896275c0f6, Nov 16 2013, 23:39:35)Type "copyright", "credits" or "license" for more information.IPython 0.13.1 -- An enhanced Interactive Python.? -> Introduction and overview of IPython's features.%quickref -> Quick reference.help -> Python's own help system.object? -> Details about 'object', use 'object??' for extra details.In [1]:
标准 Python 解释器使用 >>> 和 … 作为输入提示符,其中,… 表示你仍需要输入一些代码以保证正常运行。IPython 会将你输入的所有东西保存在名为 In 的列表中,同时将所有输入的内容保存到 Out 列表中。每个输入可以包含多行数据,通过按下 Shift 加回车可以结束输入并提交你输入的内容。下面是一个一行的例子:
In [1]: print("Hello? World?")Hello? World?In [2]:
In 和 Out 是自动编号的列表,这让你可以方便地访问任何你输入的内容和得到的输出内容。
如果你在一个变量后边输入 ?,IPython 会显示出它的类型、值、创建该类变量的方式以及其他一些相关信息:
In [4]: answer = 42In [5]: answer?Type: intString Form:42Docstring:int(x=0) -> integerint(x, base=10) -> integerConvert a number or string to an integer, or return 0 if no argumentsare given. If x is a number, return x.__int__(). For floating pointnumbers, this truncates towards zero.If x is not a number or if base is given, then x must be a string,bytes, or bytearray instance representing an integer literal in thegiven base. The literal can be preceded by '+' or '-' and be surroundedby whitespace. The base defaults to 10. Valid bases are 0 and 2-36.Base 0 means to interpret the base from the string as an integer literal.>>> int('0b100', base=0)4
名称查找是像 IPython 这样的 IDE 中常见的功能。如果你在输入了一串字符后按下 Tab 键,IPython 会显示出所有以当前字符串为开头的变量、关键词、函数,等等。我们首先来定义一些变量,然后尝试查找所有以 f 开头的内容:
In [6]: fee = 1In [7]: fie = 2In [8]: fo = 3In [9]: fum = 4In [10]: ftab%%file fie finally fo format frozensetfee filter float for from fum
如果你在输入 fe 后按下 Tab 键,它会自动扩展为变量 fee,因为它是当前程序中唯一一个以 fe 开头的内容:
In [11]: feeOut[11]: 1
C.6.2 IPython笔记本
如果你倾向于图形界面,可能会喜欢 IPython 的基于网页的实现。首先打开 Anaconda 的开始窗口(图 C-1)。
图 C-1:Anaconda 开始界面
点击 ipython-notebook 右侧的 launch 图标即可在浏览器中运行笔记本。图 C-2 显示了初始启动页。

图 C-2:iPython 主界面
现在点击创建新笔记本会弹出一个类似图 C-3 的窗口。

图 C-3:iPython 笔记本页面
在图形界面下重新输入我们之前例子中的代码,如图 C-4 所示。

图 C-4:在 iPython 中输入代码
点击黑色的小三角运行它。运行结果如图 C-5 所示。
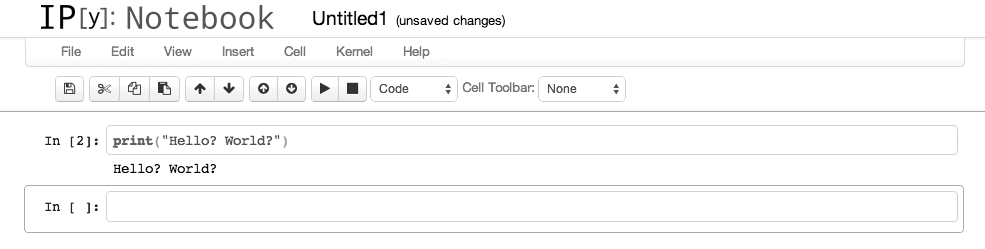
图 C-5:在 iPython 中运行代码
IPython 的笔记本不仅仅是图形化版的 IPython 解释器。除了代码,它还可以包含文本、图片、格式化的数学表达式,等等。
在笔记本界面上方的一排按钮中有一个是下拉菜单(图 C-6),它可以指定你输入内容的方式。下面是几种可选的方式。
- Code
默认的输入方式,用于输入 Python 代码。
- Markdown
HTML 的一种替代,可以将输入文本按照预先指定的格式处理为可读文本。
- 纯文本
无格式文本,从 Heading 1 到 Heading 6,即对应 HTML 中的
图 C-6:可选内容格式菜单
试着在我们的代码中穿插加入些文本,让它看起来像是某种 wiki 页。从下拉菜单中选择 Heading 1 然后输入“Humble Brag Example”,接着按下 Shift 加回车键(Enter)。你应该能看到粗体显示的上面三个单词。然后从下拉菜单中选择 Code 并随便输入一些代码,比如下面这些:
print("Some people say this code is ingenious")
再次按下 Shift+Enter 来完成输入。现在你应该能看到格式化的标题和代码,如图 C-7 所示。
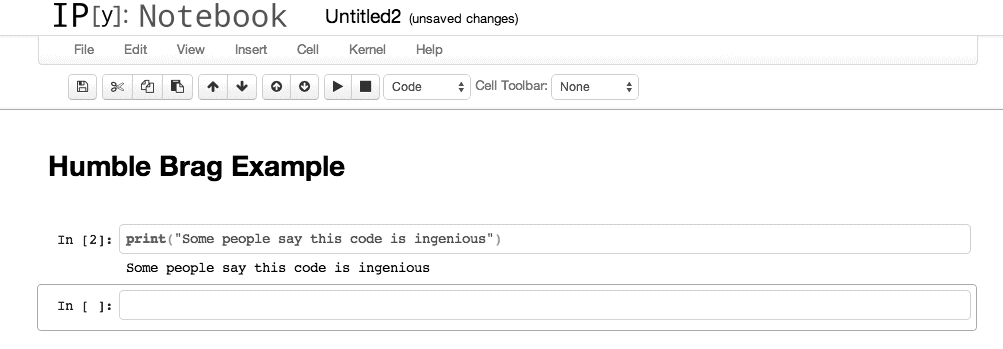
图 C-7:格式化文本和代码
通过将输入代码、输出结果、文本甚至图片穿插起来,你可以创建交互式的笔记本。又由于它是基于网页的,因此你可以从任何浏览器上访问到,十分便捷。
你可以看到一些转化成静态 HTML(http://nbviewer.ipython.org/)的笔记,或者放置在收藏(https://github.com/ipython/ipython/wiki/A-gallery-of-interesting-IPython-Notebooks)中的笔记。举个具体的例子,你可以看看关于泰坦尼克号上乘客的笔记(http://nbviewer.ipython.org/github/agconti/kaggle-titanic/blob/master/Titanic.ipynb)。它包括一些图表,展示了性别、穷富、位于船上的位置等因素是如何影响生存率的。作为奖励,你还可以读一读如何使用不同的机器学习方法。
科学家们也开始使用 IPython 笔记来发表他们的研究成果,包括所有代码和支持结论的数据。
C.7 Pandas
最近几年,数据科学(data science)这个词变得越来越流行。关于这个词,我看到过这样一些解释:“在 Mac 上完成的统计”或“在旧金山完成的统计”。然而,不管你如何定义数据科学的范畴,本章我们讨论的工具——NumPy、SciPy 以及这一节的主角 Pandas——都是日益流行的数据科学工具中的重要成员。(当然 Mac 和旧金山都是可有可无的。)
Pandas(http://pandas.pydata.org/)是一款全新的用于进行交互式数据分析的工具包。Pandas 融合了 NumPy 进行矩阵运算的能力以及处理电子表格和关系型数据库的能力,因此它在处理真实世界的数据上非常有效。Wes McKinney 编写的 Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython(O'Reilly,http://shop.oreilly.com/product/0636920023784.do)讲解了如何使用 NumPy、IPython 以及 Pandas 进行有效的数据处理。
NumPy 是针对传统科学计算而设计的,它主要用于处理单一类型的多维数据集,通常为浮点型数据。Pandas 更像是一个数据库编辑器,可以处理包含多种数据类型的组(group)。在某些语言中,这种组也被称为记录(record)或者结构(structure)。Pandas 定义一种基本数据结构,叫作 DataFrame(数据帧)。它是一个有序的列的集合,每一列都有自己的名称和类型。数据帧有点像数据库中的表格、Python 中的命名元组和嵌套字典。Pandas 的设计目的在于简化不同类型数据的处理过程,使它不仅仅适用于科学计算中遇到的类型(主要是浮点型)还适用于商业数据。事实上,Pandas 最初就是为了处理金融数据而设计的,它最常见的替代品就是电子表格。
Pandas 是一款用于处理真实世界中各种类型的混杂数据(值的缺失、古怪的格式、稀疏的测量值,等等)的 ETL 工具。你可以用它对数据文件进行划分(split)、合并(join)、扩展(extend)、添加(fill in)、转换(convert)、变形(reshape)、切分(slice)、加载(load)和保存(save)等操作。它整合了我们之前讨论过的那些工具——NumPy、SciPy、IPython——用于进行统计计算、根据模型拟合数据、绘制图表、发表,等等。
大多数科学家们都希望能尽快把他们的工作做完,而不需要花费几个月的时间先成为某种晦涩的计算机语言或应用程序的专家。有了 Python,他们很快就能变得非常有效率。
C.8 Python和科学领域
之前我们讨论的都是可以应用到任何科学领域的 Python 工具。那么,有没有专门针对于某一特定领域的 Python 工具和相关文档呢?下面列出了 Python 在某些特定问题方向的应用,以及一些适用于特定问题的 Python 库。
通用
在科学和工程中使用 Python 进行计算(http://kitchingroup.cheme.cmu.edu/pycse/pycse.html)
科学家的 Python 速成课(http://nbviewer.ipython.org/gist/rpmuller/5920182)
物理
生物和医药
生物学家应学的 Python(http://pythonforbiologists.com/)
使用 Python 处理神经影像(http://nipy.org/)
下面列出一些与 Python 和科学数据处理相关的国际会议:
PyData(http://pydata.org/)
SciPy(http://conference.scipy.org/)
EuroSciPy(https://www.euroscipy.org/)
