第 7 章 数据分析与可视化
本章将介绍使用matplotlib、pandas和IPython进行数据可视化、制作图表、交互式计算的相关知识。数据可视化是通过图形或图示的形式表示数据。这可以帮助用户简单快速地理解数据的信息。“制作图表”(plotting)指的是用图表的形式表示数据集,以呈现两个或更多变量之间的关系。“交互式计算”指的是可以接受用户输入的软件。通常,用户输入是由软件处理的命令。接受用户输入之后,软件会处理用户输入的每一行命令。这些概念将在后面的示例程序中演示。
本章将要介绍的主题如下:
用matplotlib画图的相关概念
通过示例程序演示各种图表
介绍pandas的基本概念
通过示例程序演示pandas数据结构
用pandas进行数据分析
IPython的交互式计算功能组件
IPython的其他功能组件
pandas是数据分析工具程序库,带有高性能、易使用的数据结构。它可以让用户按照标准样式和自定义样式画出各种各样的图形。
IPython是支持在多种编程语言中进行交互式计算的命令行工具,是专门为Python设计的。
7.1 matplotlib
matplotlib是Python最流行的画二维图形和图表的软件包。它为不同类型的图形和图表提供了简便快捷的数据可视化方式。它还支持不同的图形导出格式。首先从matplotlib的基础和结构开始介绍,然后用简单的程序演示不同类型图表的绘制方法。
7.1.1 matplotlib的架构
最重要的matplotlib对象是Figure。它包含并管理着图表/图形的所有元素。matplotlib将图形的显示和操作与Figure对象在用户界面屏幕或设备上的渲染分离开来。这样用户就可以设计和开发有趣的图形特性和显示逻辑,而且后台和设备操作依然很简单。matplotlib支持不同设备上的图像渲染,也支持许多主流图形用户界面设计工具箱的事件处理。
matplotlib的架构分为三层,分别是后端(backend)、艺术家(artist)和脚本(scripting)。这三层构成一个栈,上层架构懂得与下层架构通信的方式,而下层架构不知道上层架构的动作。其中,后端架构是底层,脚本架构是顶层,艺术家层是中间层。现在让我们仔细看看从顶层到底层的内容。
1. 脚本层(pyplot)
matplotlib的pyplot接口非常直观,科学家和分析师使用起来非常简单。它简化了完成数据分析与可视化的常规操作。pyplot接口管理创建图形、坐标轴以及它们与后端层的连接。它隐藏了表现图形和坐标轴的数据结构的内部细节。
下面用一个例子来演示脚本层的易用性:
import matplotlib.pyplot as pltimport numpy as npvar = np.random.randn(5300)plt.hist(var, 530)plt.title(r'Normal distribution ($\mu=0, \sigma=1$)')plt.show()
如果要把直方图保存为图像文件,可以在倒数第二行增加plt.savefig('sample_histogram.png')代码,然后再显示图形。
2. 艺术家层
matplotlib栈的这个中间层管理漂亮图形背后的大多数内部活动。这个层的基类是matplotlib.artist.Artist。它知道如何将要画的内容渲染到画布上。在matplotlib的Figure中显示的每个对象都是Artist的一个实例,包括图形标题、坐标轴和数字标签、图像、线、条形图与点。每一个Artist实例都是为了这些元素而创建的。
艺术家层会将大量的属性分享给每个实例。第一个属性就是图形变换,实现艺术家坐标体系和画布坐标体系之间的转换。另一个属性是能见度,用于管理艺术家层可以画图的区域。图形中的标签也是一个属性,还有一个属性是通过鼠标点击实现用户行为的接口。
3. 后端层
后端层是matplotlib的底层,里面实现了大量的抽象接口类,即FigureCanvas、Renderer和Event类。其中,FigureCanvas类扮演绘画底板的角色。与真实的绘画类比,FigureCanvas就像是绘画用的纸。Renderer类实现上色的功能,好像是真实绘画中使用的刷子。Event类处理键盘与鼠标动作。
这个层还可以和用户界面工具箱整合在一起,例如Qt。与用户界面工具箱整合的抽象基类位于matplotlib.backend_bases。这个类可以为不同的用户界面工具箱派生专门的子类,如matplotlib.backends.backend_qt4agg。
为了创建一个图形,后端层提供了标题、字体、函数,可以将图形保存为不同格式,包括PDF、PNG、PS和SVG等格式。
Renderer类提供了画图接口,可以在画布上画出图形。
7.1.2 matplotlib的画图方法
用户使用matplotlib可以画出各种各样的二维图。这部分内容将介绍一些简单的图形和两种特殊图形:等高线图和矢量图。下面的程序画了一个线图,表示圆的半径和面积的对应关系:
import matplotlib.pyplot as plt# 半径r = [1.5, 2.0, 3.5, 4.0, 5.5, 6.0]# 圆的面积a = [7.06858, 12.56637, 38.48447, 50.26544, 95.03309, 113.09724]plt.plot(r, a)plt.xlabel('Radius')plt.ylabel('Area')plt.title('Area of Circle')plt.show()
下面的程序画出了一个线图,其中有两种不同的线,分别表示正弦曲线和余弦曲线。通常,这些类型的图形都是用来做比较的。因此,matplotlib为图形提供了不同的颜色、线形和标记。绘图函数的第三个参数表示线条的颜色、线形和标记。第一个字符表示颜色, 它的值可以是b、g、r、c、m、y、k和w中的任何一个。其中k表示黑色(black),其他字母的含义都很明显。第二个字符表示线条的形状,可以用-、--、-..和:表示。这些符号分别表示实线、虚线、点划线和点线。最后一个字符表示标记,如.、x、+、o和*。
import matplotlib.pyplot as pltvar = arange(0.,100,0.2)cos_var = cos(var)sin_var = sin(var)plt.plot(var,cos_var,'b-*',label='cosine')plt.plot(var,sin_var,'r-.',label='sine')plt.legend(loc='upper left')plt.xlabel('xaxis')plt.ylabel('yaxis')plt.show()
在这个图形中,可以通过xlim或ylim函数设置 x 轴和 y 轴的坐标值范围。你可以在倒数第二行加plot.ylim(-2,2)看看效果。
下面的程序画的是服从正态分布的直方图。数据是通过正态分布函数产生的:
import matplotlib.pyplot as pltfrom numpy.random import normalsample_gauss = normal(size=530)plt.hist(sample_gauss, bins=15)plt.title("Histogram Representing Gaussian Numbers")plt.xlabel("Value")plt.ylabel("Frequency")plt.show()
下面的程序画的是等高线图,用linspace函数生成的线性空间矢量构成:
import matplotlib.pyplot as pltfrom numpy importx = linspace(0,10.5,40)y = linspace(1,8,30)(X,Y) = meshgrid(x,y)func = exp(-((X-2.5)*2 + (Y-4)**2)/4) - exp(-((X-7.5)**2 + (Y-4)**2)/4)contr = plt.contour(x,y,func)plt.clabel(contr)plt.xlabel("x")plt.ylabel("y")plt.show()
下面的程序画的是矢量图,同样是用linspace函数生成的线性空间矢量构成的。如果后面要重用图形元素,可以把它们保存为变量。程序中倒数第二、三行就是把xlabel和ylabel保存为变量:
import matplotlib.pyplot as pltfrom numpy importx = linspace(0,15,11)y = linspace(0,10,13)(X,Y) = meshgrid(x,y)arr1 = 15Xarr2 = 15*Ymain_plot = plt.quiver(X,Y,arr1,arr2,angles='xy',scale=1000,color='b')main_plot_key = plt.quiverkey(main_plot,0,15,30,"30 m/s",coordinates='data',color='b')xl = plt.xlabel("x in (km)")yl = plt.ylabel("y in (km)")plt.show()
输出结果
画图的结果可以输出为不同的文件格式,例如图片、PDF、PS文件等。要把图形保存为文件,有两种方法。
- 第一种也是比较简单的方法就是直接在屏幕上用保存按钮,如下面的截图所示。
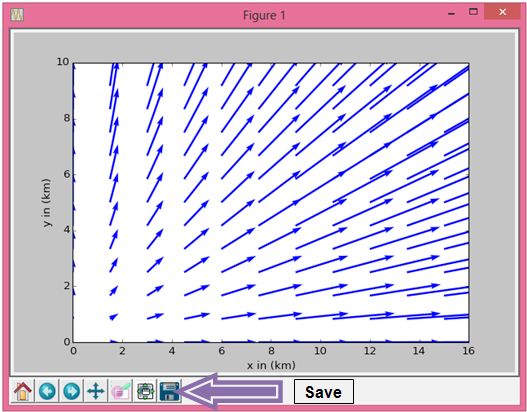
图形显示屏幕的左下角有许多按钮,最右边的按钮可以把图形保存为图片文件。点击之后,会出现对话框,提示你选择保存的格式、保存的位置和文件名称。
- 第二种方法是在
plt.show()方法运行之前使用plt.savefig方法。还可以设置输出文件的名称、样式与格式。
下面的程序把多个图形保存在一个PDF文件的不同页面中,同时还演示了把图形保存为PNG文件的方法:
from matplotlib.backends.backend_pdf import PdfPagesimport matplotlib.pyplot as pltimport matplotlib as mplfrom numpy.random import normalfrom numpy import# PDF初始化pdf = mpl.backends.backend_pdf.PdfPages("output.pdf")# 第一幅图保存到PDF第一页sample_gauss = normal(size=530)plt.hist(sample_gauss, bins=15)plt.xlabel("Value")plt.ylabel("Frequency")plt.title("Histogram Representing Gaussian Numbers")pdf.savefig()plt.close()# 创建第二幅图,保存到PDF第二页var = arange(0.,100,0.2)cos_var = cos(var)sin_var = sin(var)plt.legend(loc='upper left')plt.xlabel('xaxis')plt.ylabel('yaxis')plt.plot(var,cos_var,'b-',label='cosine')plt.plot(var,sin_var,'r-.',label='sine')pdf.savefig()pdf.close()plt.close()# 输出PNG文件r = [1.5, 2.0, 3.5, 4.0, 5.5, 6.0]a = [7.06858, 12.56637, 38.48447, 50.26544, 95.03309, 113.09724]plt.plot(r, a)plt.xlabel('Radius')plt.ylabel('Area')plt.title('Area of Circle')plt.savefig("sample_output.png")plt.show()
7.2 pandas程序库
pandas程序库的工具适合完成高性能数据分析任务。这个程序库同时适用于商务与科学领域。“pandas”是计量经济学的“面板数据”(panel data)和“Python数据分析”(data analysis)的英文缩写。数据分析和数据处理的五个步骤是加载、准备、操作、建模和分析。
pandas为Python数据结构增加了三个数据类型,分别是Series、DataFrame和Panel。这些数据结构都是在NumPy的基础上建立的。下面让我们具体看看每种数据类型。
7.2.1 Series
Series是一维对象,类似于数组、列表或表格中的一列。它可以存储任意Python数据类型,包括整型、浮点型、字符串以及任意Python对象。Series的每个项目还有一个标签索引。默认情况下,索引从0到 N 表示N+1个项目。我们可以用Series从NumPy数组或Python词典(dict)创建一个Series对象。同时,我们也可以为Series的数据设置对应的索引。
让我们用一个简单的程序来演示Series数据结构:
import numpy as nprandn = np.random.randnfrom pandas import *s = Series(randn(10), index=['I', 'II', 'III', 'IV', 'V', 'VI', 'VII','VIII', 'IX', 'X' ])ss.indexSeries(randn(10))d = {'a' : 0., 'e' : 1., 'i' : 2.}Series(d)Series(d, index=['e', 'i', 'o', 'a'])# Series用标量值创建Series(6., index=['a', 'e', 'i', 'o', 'u', 'y'])Series([10, 20, 30, 40], index=['a', 'e', 'i', 'o'])Series({'a': 10, 'e': 20, 'i': 30})s.get('VI')# 可以设置name属性,定义Series名称s = Series(np.random.randn(5), name='RandomSeries')
7.2.2 DataFrame
pandas的二维数据结构叫DataFrame。DataFrame是由行和列构成的数据结构,类似于数据库表或Excel表格。
与Series类似,DataFrame也支持不同的输入类型,例如:
一维NumPy数组、列表、序列值和词典(
dict)的词典二维NumPy数组
一个结构体/记录(structure/record,下文指元组列表)的NumPy数组
一个pandas的Series或DataFrame对象
虽然索引和列名称参数是可选的,但是最好把它们设置一下。索引可以看成是行标签,列名称可以看成是列标签。下面的程序首先从词典(dict)创建DataFrame。如果列名称未设置,则使用排序过的词典键作为列名。
然后,通过N维数组/列表的词典(dict)创建DataFrame。最后,用结构体或记录的数组创建DataFrame:
import numpy as nprandn = np.random.randnfrom pandas import *# 从序列字典或字典生成DataFramed = {'first' : Series([10., 20., 30.], index=['I', 'II', 'III']),'second' : Series([10., 20., 30., 40.], index=['I', 'II', 'III','IV'])}DataFrame(d, index=['IV', 'II', 'I'])DataFrame(d, index=['IV', 'II', 'I'], columns=['second', 'third'])df = DataFrame(d)dfdf.indexdf.columns# 从_N_维数组字典或列表字典生成DataFramed = {'one' : [10., 20., 30., 40.],'two' : [40., 30., 20., 10.]}DataFrame(d)DataFrame(d, index=['I', 'II', 'III', 'IV'])# 结构化的数组或记录data = np.zeros((2,),dtype=[('I', 'i4'),('II', 'f4'),('III', 'a10')])data[:] = [(10,20.,'Very'),(20,30.,"Good")]DataFrame(data)DataFrame(data, index=['first', 'second'])DataFrame(data, columns=['III', 'I', 'II'])
7.2.3 Panel
Panel数据结构可以存储三维数据。这个名称源自统计学和计量经济学,里面的多维数据经常有多个时间周期。通常,Panel包括同一个组织或人的多个时间周期的多项数据。
Panel数据结构有三个组成部分——项目(item)、主轴(major axis)和次轴(minor axis),解释如下。
items:指的是Panel里每个DataFrame的数据项。major axis:指的是每个DataFrame的索引(行标签)。minor axis:指的是每个DataFrame的列。
下面的程序演示了创建Panel的不同方法:项目选择/索引,数据压缩,转换成多层索引的DataFrame。程序的最后两行是利用to_frame方法把Panel转换成DataFrame:
import numpy as nprandn = np.random.randnfrom pandas import *# 通过带标签的三维数组创建Panelworkpanel = Panel(randn(2, 3, 5), items=['FirstItem', 'SecondItem'],major_axis=date_range('1/1/2010', periods=3),minor_axis=['A', 'B', 'C', 'D', 'E'])workpanel# 通过值是DataFrame的Python字典创建Paneldata = {'FirstItem' : DataFrame(randn(4, 3)),'SecondItem' : DataFrame(randn(4, 2))}Panel(data)# orient=minor表示用DataFrame的列名作为Panel的item(项)Panel.from_dict(data, orient='minor')df = DataFrame({'x': ['one', 'two', 'three', 'four'],'y': np.random.randn(4)})dfdata = {'firstitem': df, 'seconditem': df}panel = Panel.from_dict(data, orient='minor')panel['x']panel['y']panel['y'].dtypes# 选择Panel的某一项workpanel['FirstItem']# 对Panel进行转置操作,有C(3,2)即6种组合方式workpanel.transpose(2, 0, 1)# 从major_axis标签获取一个切片workpanel.major_xs(workpanel.major_axis[1])workpanel.minor_axis# 从minor_axis标签获取一个切片workpanel.minor_xs('D')# 利用squeeze方法抽取部分维度数据,与workpanel['FirstItem']和# workpanel['FirstItem']['B']类似workpanel.reindex(items=['FirstItem']).squeeze()workpanel.reindex(items=['FirstItem'],minor=['B']).squeeze()forconversionpanel = Panel(randn(2, 4, 5), items=['FirstItem', 'SecondItem'],major_axis=date_range('1/1/2010', periods=4),minor_axis=['A', 'B', 'C', 'D', 'E'])forconversionpanel.to_frame()
7.2.4 pandas数据结构的常用函数
这些数据结构有一些共同的功能。这些功能在每个数据结构上都会实现同样的操作。不同的数据结构之间具有共同的属性。下面的程序展示了pandas数据结构的常用功能/操作和属性:
import numpy as nprandn = np.random.randnfrom pandas import *index = date_range('1/1/2000', periods=10)s = Series(randn(10), index=['I', 'II', 'III', 'IV', 'V', 'VI', 'VII','VIII', 'IX', 'X' ])df = DataFrame(randn(10, 4), index=['I', 'II', 'III', 'IV', 'V', 'VI','VII', 'VIII', 'IX', 'X' ], columns=['A', 'B', 'C', 'D'])workpanel = Panel(randn(2, 3, 5), items=['FirstItem', 'SecondItem'],major_axis=date_range('1/1/2010', periods=3),minor_axis=['A', 'B', 'C', 'D', 'E'])series_with100elements = Series(randn(100))series_with100elements.head()series_with100elements.tail(3)series_with100elements[:3]df[:2]workpanel[:2]df.columns = [x.lower() for x in df.columns]df# 利用values属性可以获取数值s.valuesdf.valueswp.values
有一些功能/属性只能用于Series和DataFrame。下面的程序将演示这些功能/属性,包括描述性统计函数describe、最大/最小索引(idxmin/idxmax)、按照行/列标签或数值排序、对象功能转换、数值类型属性(dtypes),等等:
import numpy as nprandn = np.random.randnfrom pandas import# 描述性统计describe函数series = Series(randn(440))series[20:440] = np.nanseries[10:20] = 5series.nunique()series = Series(randn(1700))series[::3] = np.nanseries.describe()frame = DataFrame(randn(1200, 5), columns=['a', 'e', 'i', 'o', 'u'])frame.ix[::3] = np.nanframe.describe()series.describe(percentiles=[.05, .25, .75, .95])s = Series(['x', 'x', 'y', 'y', 'x', 'x', np.nan, 'u', 'v', 'x'])s.describe()frame = DataFrame({'x': ['Y', 'Yes', 'Yes', 'N', 'No', 'No'], 'y':range(6)})frame.describe()frame.describe(include=['object'])frame.describe(include=['number'])frame.describe(include='all')# 最大索引与最小索引的值s1 = Series(randn(10))s1s1.idxmin(), s1.idxmax()df1 = DataFrame(randn(5,3), columns=['X','Y','Z'])df1df1.idxmin(axis=0)df1.idxmax(axis=1)df3 = DataFrame([1, 2, 2, 3, np.nan], columns=['X'],index=list('aeiou'))df3df3['X'].idxmin()# 按标签排序和按数值排序unsorted_df = df.reindex(index=['a', 'e', 'i', 'o'],columns=['X', 'Y', 'Z'])unsorted_df.sort_index()unsorted_df.sort_index(ascending=False)unsorted_df.sort_index(axis=1)df1 = DataFrame({'X':[5,3,4,4],'Y':[5,7,6,8],'Z':[9,8,7,6]})df1.sort_index(by='Y')df1[['X', 'Y', 'Z']].sort_index(by=['X','Y'])s = Series(['X', 'Y', 'Z', 'XxYy', 'Yxzx', np.nan, 'ZXYX', 'Zoo', 'Yet'])s[3] = np.nans.order()s.order(na_position='first')# 将目标值插入既定顺序,查找包含区间值的索引ser = Series([4, 6, 7, 9])ser.searchsorted([0, 5])ser.searchsorted([1, 8])ser.searchsorted([5, 10], side='right')ser.searchsorted([1, 8], side='left')s = Series(np.random.permutation(17))ss.order()s.nsmallest(5)s.nlargest(5)# 对多维索引进行排序df1.columns = MultiIndex.from_tuples([('x','X'),('y','Y'),('z','X')])df1.sort_index(by=('x','X'))# 查看DataFrame和Series的数值类型dft = DataFrame(dict( I = np.random.rand(5),II = 8,III = 'Dummy',IV = Timestamp('19751008'),V = Series([1.6]5).astype('float32'),VI = True,VII = Series([2]*5,dtype='int8'),VIII = False))dftdft.dtypesdft['III'].dtypedft['II'].dtype# 统计每种数据类型出现的次数dft.get_dtype_counts()df1 = DataFrame(randn(10, 2), columns = ['X', 'Y'], dtype = 'float32')df1df1.dtypesdf2 = DataFrame(dict( X = Series(randn(10)),Y = Series(randn(10),dtype='uint8'),Z = Series(np.array(randn(10),dtype='float16'))))df2df2.dtypes# 转换DataFrame和Series的数据类型df3['D'] = '1.'df3['E'] = '1'df3.convert_objects(convert_numeric=True).dtypes# 同上,但是转换为指定数据类型df3['D'] = df3['D'].astype('float16')df3['E'] = df3['E'].astype('int32')df3.dtypess = Series([datetime(2001,1,1,0,0),'foo', 1.0, 1, Timestamp('20010104'),'20010105'],dtype='O')ss.convert_objects(convert_dates='coerce')
实现迭代操作非常简单,每种数据结构都是同样的方式。Series数据结构的数据操作有一个存取器。下面的程序演示了这些概念:
import numpy as nprandn = np.random.randnfrom pandas import *workpanel = Panel(randn(2, 3, 5), items=['FirstItem', 'SecondItem'],major_axis=date_range('1/1/2010', periods=3),minor_axis=['A', 'B', 'C', 'D', 'E'])df = DataFrame({'one-1' : Series(randn(3), index=['a', 'b', 'c']),'two-2' : Series(randn(4), index=['a', 'b', 'c','d']),'three-3' : Series(randn(3), index=['b', 'c', 'd'])})for columns in df:print(columns)for items, frames in workpanel.iteritems():print(items)print(frames)for r_index, rows in df2.iterrows():print('%s\n%s' % (r_index, rows))df2 = DataFrame({'x': [1, 2, 3, 4, 5], 'y': [6, 7, 8, 9, 10]})print(df2)print(df2.T)df2_t = DataFrame(dict((index,vals) for index, vals in df2.iterrows()))print(df2_t)df_iter = DataFrame([[1, 2.0, 3]], columns=['x', 'y', 'z'])row = next(df_iter.iterrows())[1]print(row['x'].dtype)print(df_iter['x'].dtype)for row in df2.itertuples():print(row)# 用dt存取器处理时间s = Series(date_range('20150509 01:02:03',periods=5))ss.dt.hours.dt.seconds.dt.days[s.dt.day==2]# 时区转换也非常方便stimezone = s.dt.tz_localize('US/Eastern')stimezonestimezone.dt.tzs.dt.tz_localize('UTC').dt.tz_convert('US/Eastern')# 周期s = Series(period_range('20150509',periods=5,freq='D'))ss.dt.years.dt.day# 时间间隔s = Series(timedelta_range('1 day 00:00:05',periods=4,freq='s'))ss.dt.dayss.dt.secondss.dt.components
pandas提供了大量的方法来实现描述性统计量的计算,此外还有聚合函数,如计数、求和、最小值、最大值、均值、中位数、众数、标准偏差、方差、偏度、峰度、分位数、累计求和等函数。
下面的程序演示了Series、DataFrame和Panel数据结构如何使用这些函数。这些方法都有一个可选参数skipna,可以在统计时忽略缺失数据(NaN)。该参数的初始值为True。
import numpy as nprandn = np.random.randnfrom pandas import *df = DataFrame({'one-1' : Series(randn(3), index=['a', 'b', 'c']),'two-2' : Series(randn(4), index=['a', 'b', 'c','d']),'three-3' : Series(randn(3), index=['b', 'c', 'd'])})dfdf.mean(0)df.mean(1)df.mean(0, skipna=False)df.mean(axis=1, skipna=True)df.sum(0)df.sum(axis=1)df.sum(0, skipna=False)df.sum(axis=1, skipna=True)# NumPy的mean不统计缺失值np.mean(df['one-1'])np.mean(df['one-1'].values)ser = Series(randn(10))ser.pct_change(periods=3)# 指定周期的df = DataFrame(randn(8, 4))df.pct_change(periods=2)ser1 = Series(randn(530))ser2 = Series(randn(530))ser1.cov(ser2)frame = DataFrame(randn(530, 5), columns=['i', 'ii', 'iii', 'iv', 'v'])frame.cov()frame = DataFrame(randn(26, 3), columns=['x', 'y', 'z'])frame.ix[:8, 'i'] = np.nanframe.ix[8:12, 'ii'] = np.nanframe.cov()frame.cov(min_periods=10)frame = DataFrame(randn(530, 5), columns=['i', 'ii', 'iii', 'iv', 'v'])frame.ix[::4] = np.nan# 用Pearson方法(默认方法)计算标准相关系数frame['i'].corr(frame['ii'])# 也可以指定用Kendall方法和Spearman方法frame['i'].corr(frame['ii'], method='kendall')frame['i'].corr(frame['ii'], method='spearman')index = ['i', 'ii', 'iii', 'iv']columns = ['first', 'second', 'third']df1 = DataFrame(randn(4, 3), index=index, columns=columns)df2 = DataFrame(randn(3, 3), index=index[:3], columns=columns)df1.corrwith(df2)df2.corrwith(df1, 1)s = Series(np.random.randn(10), index=list('abcdefghij'))s['d'] = s['b'] # 单个元素复制操作s.rank()df = DataFrame(np.random.randn(8, 5))df[4] = df[2][:5] # 多个元素(第三列前五个元素)复制操作,缺失位置用NaNdfdf.rank(1)
7.2.5 时间序列与日期函数
pandas提供了丰富的时间序列与日期操作函数,可以实现时间和日期相关的计算。
pandas通过TimeStamp数据类型,可以获得大量的时间和日期属性,其中部分属性如下所示。
year:年。month:月。day:日。hour:小时。minute:分钟。second:秒。microsecond:微秒,百万分之一秒。nanosecond:纳秒,十亿分之一秒。date:日期。time:时间。dayofyear:天数,范围1~365/366(闰年)。weekofyear:周数。dayofweek:星期几,周一用0表示,周日用6表示。quarter:季度,一月到三月用1表示,四月到六月用2表示,以此类推。
下面的程序演示了这些函数的用法:
import numpy as nprandn = np.random.randnfrom pandas import *# 创建日期区间,从06/03/2015开始152个小时range_date = date_range('6/3/2015', periods=152, freq='H')range_date[:5]# 时间作为索引ts = Series(randn(len(range_date)), index=range_date)ts.head()# 把索引值的频率更新为40分钟converted = ts.asfreq('40Min', method='pad')converted.head()ts.resample('D', how='mean')dates = [datetime(2015, 6, 10), datetime(2015, 6, 11), datetime(2015, 6, 12)]ts = Series(np.random.randn(3), dates)type(ts.index)ts# 创建周期索引periods = PeriodIndex([Period('2015-10'), Period('2015-11'),Period('2015-12')])ts = Series(np.random.randn(3), periods)type(ts.index)ts# 转换时间戳to_datetime(Series(['Jul 31, 2014', '2015-01-08', None]))to_datetime(['1995/10/31', '2005.11.30'])# 日期数值如果按照月-日-年的形式,就用dayfirst=Trueto_datetime(['01-01-2015 11:30'], dayfirst=True)to_datetime(['14-03-2007', '03-14-2007'], dayfirst=True)# 如果日期数值中有无效值,则用coerce=True转换成NaTto_datetime(['2012-07-11', 'xyz'])to_datetime(['2012-07-11', 'xyz'], coerce=True)# 混合数据类型无法正确处理to_datetime([1, '1'])# 纪元时间戳(Epoch timestamp : 整型与浮点型纪元时间戳可以转换成标准时间戳# 默认使用纳秒,可以转换成秒与微秒# 初始时间是01/01/1970to_datetime([1449720105, 1449806505, 1449892905,1449979305, 1450065705], unit='s')to_datetime([1349720105100, 1349720105200, 1349720105300,1349720105400, 1349720105500 ], unit='ms')to_datetime([8])to_datetime([8, 4.41], unit='s')# 取一定范围的日期dates = [datetime(2015, 4, 10), datetime(2015, 4, 11), datetime(2015,4, 12)]index = DatetimeIndex(dates)index = Index(dates)index = date_range('2010-1-1', periods=1700, freq='M')indexindex = bdate_range('2014-10-1', periods=250)indexstart = datetime(2005, 1, 1)end = datetime(2015, 1, 1)range1 = date_range(start, end)range1range2 = bdate_range(start, end)range2
日期信息也可以作为pandas数据结构的索引使用。下面的程序演示了用日期做索引,里面还使用了DateOffset对象:
import numpy as nprandn = np.random.randnfrom pandas import *from pandas.tseries.offsets import *start = datetime(2005, 1, 1)end = datetime(2015, 1, 1)rng = date_range(start, end, freq='BM')ts = Series(randn(len(rng)), index=rng)ts.indexts[:8].indexts[::1].index# 可以直接用日期和字符串作为索引ts['8/31/2012']ts[datetime(2012, 07, 11):]ts['10/08/2005':'12/31/2014']ts['2012']ts['2012-7']dft = DataFrame(randn(50000,1),columns=['X'],index=date_range('20050101',periods=50000,freq='T'))dftdft['2005']# 从第一个参数里月份的最早时间到最后一个参数里月份的最晚时间dft['2005-1':'2013-4']dft['2005-1':'2005-3-31']# 可以指定停止时间dft['2005-1':'2005-3-31 00:00:00']dft['2005-1-17':'2005-1-17 05:30:00']# 日期索引dft[datetime(2005, 1, 1):datetime(2005,3,31)]dft[datetime(2005, 1, 1, 01, 02, 0):datetime(2005, 3, 31, 01, 02, 0)]# 用loc选择一行数据dft.loc['2005-1-17 05:30:00']# 截取一段时间ts.truncate(before='1/1/2010', after='12/31/2012')
7.2.6 处理缺失数据
缺失数据是指数据为空(null)或没显示。通常用Na*表示缺失数据,这里的*表示数值类型,比如N表示缺失数值(NaN),T表示缺失时间值(NaT)。下面的程序演示了pandas检查缺失数据的函数isnull和notnull,用fillna、dropna、rloc、iloc和interpolate填补缺失数据。如果对NaN对象执行任何操作,结果仍为NaN:
import numpy as nprandn = np.random.randnfrom pandas import *df = DataFrame(randn(8, 4), index=['I', 'II', 'III', 'IV', 'VI','VII', 'VIII', 'X' ],columns=['A', 'B', 'C', 'D'])df['E'] = 'Dummy'df['F'] = df['A'] > 0.5df# 通过增加索引来引入缺失值df2 = df.reindex(['I', 'II', 'III', 'IV', 'V', 'VI', 'VII', 'VIII','IX', 'X'])df2df2['A']# 检查是否存在缺失值isnull(df2['A'])df2['D'].notnull()df3 = df.copy()df3['timestamp'] = Timestamp('20120711')df3# 把timestamp列缺失值设置为NaTdf3.ix[['I','III','VIII'],['A','timestamp']] = np.nandf3s = Series([5,6,7,8,9])s.loc[0] = Noness = Series(["A", "B", "C", "D", "E"])s.loc[0] = Nones.loc[1] = np.nans# 用fillna方法填充缺失值df2df2.fillna(0) # 填充索引缺失值为0df2['D'].fillna('missing') # 为某一列填充缺失值df2.fillna(method='pad')df2df2.fillna(method='pad', limit=1)df2.dropna(axis=0)df2.dropna(axis=1)ts = Series(randn(30))ts.count()ts[10:30]=Nonets.count()# 利用插值方法填充缺失值# 默认使用线性插值ts.interpolate()ts.interpolate().count()
7.3 I/O操作
pandas的I/O API是一组返回pandas对象的read_函数。通过这些函数非常方便加载数据。能够载入pandas数据结构的数据格式很多,包括CSV、Excel、HDF、SQL、JSON、HTML、Google Big Query、pickle、stats格式,甚至粘贴板。其中一些读取函数的名称(一个函数读取一种文件格式)是read_csv、read_excel、read_hdf、read_sql、read_json。加载之后,数据就可以分析了。这些函数也支持异常检测、数据标准化、编组、转换和排序。
7.3.1 处理CSV文件
下面的程序演示pandas读取CSV文件,并进行各种操作。这里使用的是Book-Crossing数据集的CSV格式,可以在http://www2.informatik.uni-freiburg.de/~cziegler/BX/下载。这个数据集里包括三个CSV文件(BX-Books.csv、BX-Users.csv和BX-Book-Ratings.csv),里面包括书籍、读者和读者评分。pandas读取CSV文件名有两种方法:一是在任意文件夹里使用CSV的绝对路径,二是在CSV的同一个文件夹里直接使用文件名。下面的程序是在Windows系统里使用文件的绝对路径:
import numpy as nprandn = np.random.randnfrom pandas import *user_columns = ['User-ID', 'Location', 'Age']users = read_csv('c:\BX-Users.csv', sep=';', names=user_columns)rating_columns = ['User-ID', 'ISBN', 'Rating']ratings = read_csv('c:\BX-Book-Ratings.csv', sep=';', names=rating_columns)book_columns = ['ISBN', 'Book-Title', 'Book-Author', 'Year-Of- \Publication', 'Publisher', 'Image-URL-S']books = read_csv('c:\BX-Books.csv', sep=';', names=book_columns,usecols=range(6))booksbooks.dtypesusers.describe()print books.head(10)print books.tail(8)print books[5:10]users['Location'].head()print users[['Age', 'Location']].head()desired_columns = ['User-ID', 'Age']print users[desired_columns].head()print users[users.Age > 25].head(4)print users[(users.Age < 50) & (users.Location == 'chicago, illinois,\usa')].head(4)print users.set_index('User-ID').head()print users.head()with_new_index = users.set_index('User-ID')print with_new_index.head()users.set_index('User_ID', inplace=True)print users.head()print users.ix[62]print users.ix[[1, 100, 200]]users.reset_index(inplace=True)print users.head()
下面的程序演示在Book-Crossing数据集上的merge、groupby和相关操作,如排序、分类、寻找最大的n个数以及数据聚合:
import numpy as nprandn = np.random.randnfrom pandas import *user_columns = ['User-ID', 'Location', 'Age']users = read_csv('c:\BX-Users.csv', sep=';', names=user_columns)rating_columns = ['User-ID', 'ISBN', 'Rating']ratings = read_csv('c:\BX-Book-Ratings.csv', sep=';', names=rating_columns)book_columns = ['ISBN', 'Title', 'Book-Author', 'Year-Of-Publication','Publisher', 'Image-URL-S']books = read_csv('c:\BX-Books.csv', sep=';', names=book_columns,usecols=range(6))# 创建合并的DataFramebook_ratings = merge(books, ratings)users_ratings = merge(book_ratings, users)most_rated = users_ratings.groupby('Title').size(). \order(ascending=False)[:25]print most_ratedusers_ratings.Title.value_counts()[:17]book_stats = users_ratings.groupby('Title').agg({'Rating': [np.size,np.mean]})print book_stats.head()# 按照评分等级Rating与均值mean排序print book_stats.sort([('Rating', 'mean')], ascending=False).head()greater_than_100 = book_stats['Rating'].size >= 100print book_stats[greater_than_100].sort([('Rating', 'mean')],ascending=False)[:15]top_fifty = users_ratings.groupby('ISBN').size().\order(ascending=False)[:50]
下面处理CSV文件的程序位于https://github.com/gjreda/gregreda.com/blob/master/content/notebooks/data/city-of-chicago-salaries.csv?raw=true。
下面的程序演示了DataFrame的合并与连接操作:
import numpy as nprandn = np.random.randnfrom pandas import *first_frame = DataFrame({'key': range(10),'left_value': ['A', 'B', 'C', 'D', 'E','F', 'G', 'H', 'I', 'J']})second_frame = DataFrame({'key': range(2, 12),'right_value': ['L', 'M', 'N', 'O', 'P','Q', 'R', 'S', 'T', 'U']})print first_frameprint second_frame# 默认合并join操作(inner join)print merge(left_frame, right_frame, on='key', how='inner')# 其他合并操作(left,right,outer)print merge(left_frame, right_frame, on='key', how='left')print merge(left_frame, right_frame, on='key', how='right')print merge(left_frame, right_frame, on='key', how='outer')concat([left_frame, right_frame])concat([left_frame, right_frame], axis=1)headers = ['name', 'title', 'department', 'salary']chicago_details = read_csv('c:\city-of-chicago-salaries.csv',header=False,names=headers,converters={'salary': lambda x: float(x.replace('$', ''))})print chicago_detail.head()dept_group = chicago_details.groupby('department')print dept_groupprint dept_group.count().head(10)print dept_group.size().tail(10)print dept_group.sum()[10:17]print dept_group.mean()[10:17]print dept_group.median()[10:17]chicago_details.sort('salary', ascending=False, inplace=True)
7.3.2 即开即用数据集
pandas程序里还有一些经济学数据源和使用这些数据的模块。我们可以用pandas.io.data和pandas.io.ga(Google Analytics)模块从不同的网络源获取数据,并加载为DataFrame。目前支持的数据源如下。
雅虎财经。
谷歌财经。
St. Louis Fed:美联储经济数据(federal reserve economic data,FRED)包含了80源数据库的267 000多份经济时间序列数据。
Kenneth French的数字图书馆。
世界银行。
Google Analytics。
下面的小程序演示了从不同的数据源读取数据:
import pandas.io.data as webimport datetimef1=web.DataReader("F", 'yahoo', datetime.datetime(2010, 1, 1),datetime.datetime(2011, 12, 31))f2=web.DataReader("F", 'google', datetime.datetime(2010, 1, 1),datetime.datetime(2011, 12, 31))f3=web.DataReader("GDP", "fred", datetime.datetime(2010, 1, 1),datetime.datetime(2011, 12, 31))f1.ix['2010-05-12']
pandas画图功能
pandas数据结构通过封装plt.plot()支持画图功能。默认情况下,画的图都是线图,可以通过修改画图函数的kind属性改变图形的样式。df.plot()不同图形的样式的参数如下所示。
条形图:
df.plot(kind='bar')直方图:
df.plot(kind='hist')箱体图:
df.plot(kind='box')面积图:
df.plot(kind='area')散点图:
df.plot(kind='scatter')饼图:
df.plot(kind='pie')
下面的程序演示了一个简单的pandas画图方法。程序的输出结果如下面的截图所示。
from pandas import *randn = np.random.randnimport matplotlib.pyplot as pltx1 = np.array( ((1,2,3), (1,4,6), (2,4,8)) )df = DataFrame(x1, index=['I', 'II', 'III'], columns=['A', 'B', 'C'])df = df.cumsum()df.plot(kind='pie', subplots=True)plt.figure()plt.show()
7.4 IPython
IPython设计和开发的初衷是要增强Python命令行工具的功能,让它支持交互式的分布式和并行计算。IPython的工具可以支持许多交互性科学计算需求。主要的两种工具如下:
功能增强的IPython命令行工具
交互式并行计算架构
这一节主要介绍IPython的交互式命令行工具。关于交互式并行计算的内容,将在第8章介绍。
7.4.1 IPython终端与系统命令行工具
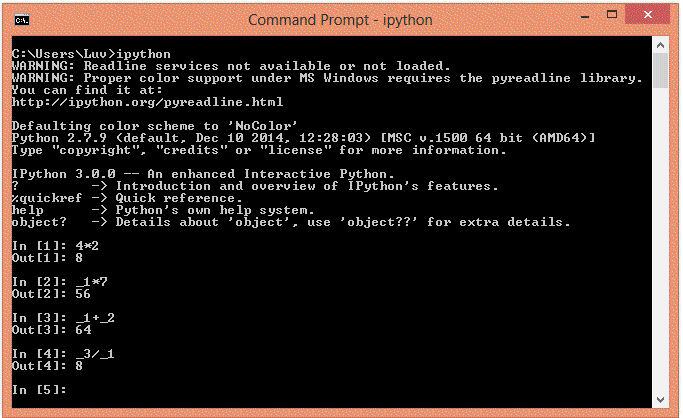
IPython的终端界面如下图所示。它支持不同的配色主题,默认的主题是NoColor,还有其他主题,如Linux和LightBG。IPython的重要特征之一是它是有状态的,就是说它会保留计算过程。IPython的输出结果都保存在_N里面,N是输出和计算结果的序号。当我们进入IPython命令行的时候,交互式的编程界面如下所示。
IPython 3.0.0 -- An enhanced Interactive Python.? -> Introduction and overview of IPython's features.%quickref -> Quick reference.help -> Python's own help system.object? -> Details about 'object', use 'object??' for extra details.
如果我们像普通命令一样输入一个问号(?),就会显示IPython的功能列表。类似地,%quickref会显示IPython命令的简介,%magic会显示IPython魔法命令的具体使用方法。
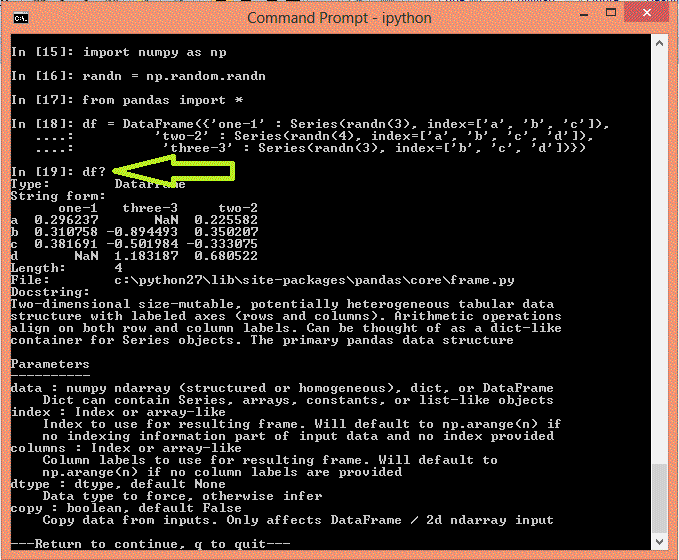
如果我们输入任意Python对象后加问号(objname?),IPython终端就会显示这个对象的文字说明、功能以及构建方法,如下图所示。我们创建了pandas的一个DataFrame对象df,然后用df?查看它的属性。
- 操作系统命令接口
我们经常需要用操作系统的命令辅助进行计算。用户可以通过命令别名速记常用命令。IPython终端还支持UNIX系统的ls等命令,用户只要在命令前面加一个感叹号!,就可以执行任何操作系统命令和系统脚本文件。

在IPython命令行中执行一个操作系统命令
- 无阻塞的画图功能
在Python命令行里创建图形,然后用show()命令显示的时候,会在新窗口显示图形,并且在用户关闭图形窗口之前,命令行都是阻塞状态,不可继续使用。但是,IPython有一个–pylab标记。如果通过IPython –pylab命令启动IPython命令行,在显示图形时,图形会直接出现在命令行窗口,不会阻塞命令行继续运行。如下图所示,当使用IPython –pylab命令时,图形显示不会阻塞命令行。
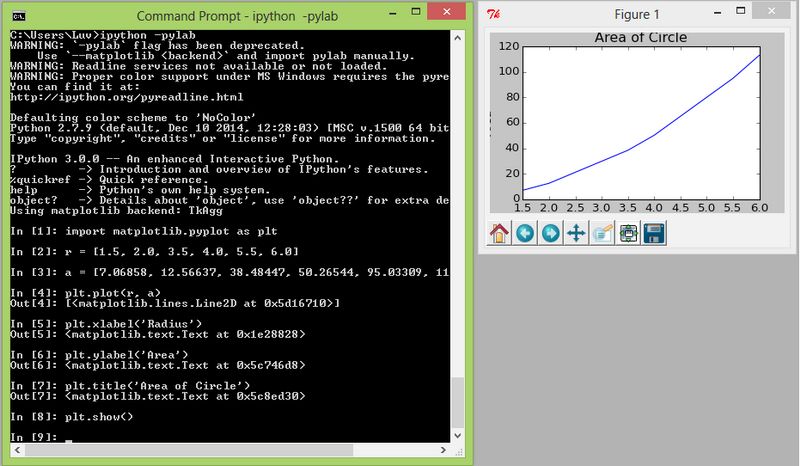
- 调试
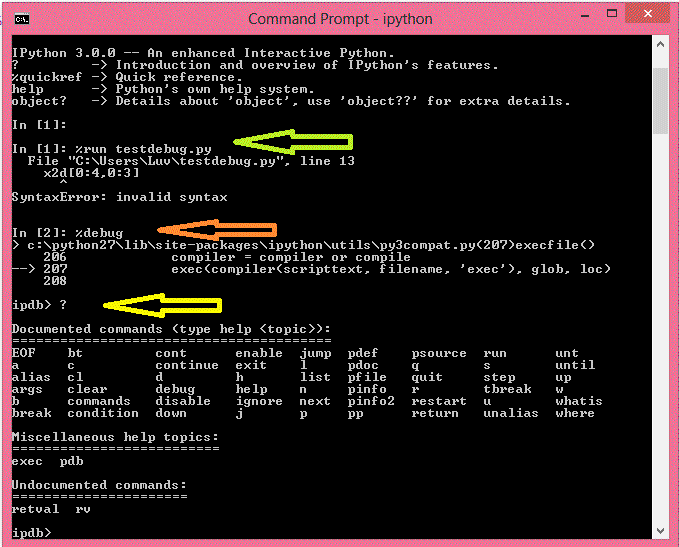
IPython具有非常强大的程序调试以及错误和异常追踪功能。当我们运行脚本之后,通过%debug命令就可以启动Python的调试器(pdb)来分析问题。我们可以在这里调试,因为我们可以打印变量结果,执行语句,追踪异常来源。这个功能可以让用户轻松调试,不需要借助其他外部调试工具。
%debug命令的截图如下所示。
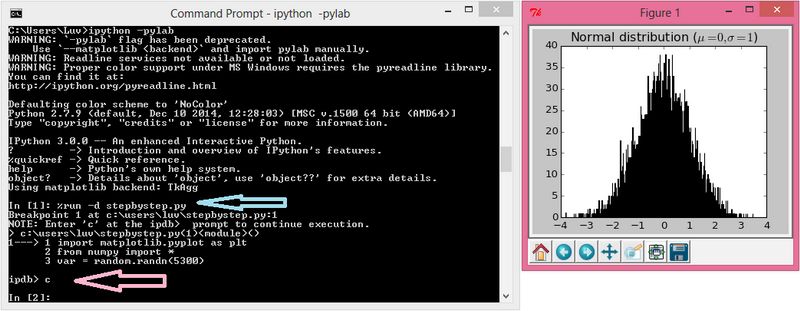
用户可以通过%run -d programname.py命令单步调试程序,如下图所示。我们可以对stepbystep.py文件进行单步调试。在每一行,调速器都会提醒用户输入c确认继续调试下一行代码。
7.4.2 IPython Notebook
IPython的网页版应用叫Notebook。设计和开发它的目的,是让用户可以通过网页丰富的展现形式体验交互式计算,可以编写解释概念的文字、数学公式、计算程序代码并输出图形。程序的输入和输出可以根据需要放在不同的单元中。
下图取自http://ipython.org/notebook.html,演示了IPython Notebook的功能。

7.5 小结
这一章首先介绍了matplotlib的基本概念和组成部分,然后通过一些小程序演示了不同图形的制作方法。此外还介绍了将图形保存为不同格式的方法,以及用pandas进行数据分析的方法。
与此同时,我们还介绍了pandas的数据结构。通过对pandas数据结构的详细介绍,你可以掌握许多数据分析的技能。最后一部分介绍了IPython的交互式编程的概念、用法和网页应用IPython Notebook。
下一章将对Python科学计算中的并行与高性能计算进行全面的介绍。首先将会介绍并行与高性能计算的基本概念以及现有的框架和技术等,然后深入介绍Python并行与高性能计算框架与工具的用法。
