第 8 章 用神经网络破解验证码
理解图像中的信息一直是数据挖掘领域的一个难题,直到最近几年才开始得到真正解决。图像检测和理解算法已相当成熟,几大厂商使用这些算法研制的监测系统已投入商用,用来处理实际问题。这些系统能够理解和识别视频画面中的人和物体。
从图像中抽取信息很难。图像包含大量原始数据,图像的标准编码单元——像素——提供的信息量很少。图像——特别是照片——可能存在一系列问题,比如模糊不清、离目标太近、光线很暗或太亮、比例失真、残缺、扭曲等,这会增加计算机系统抽取有用信息的难度。
本章介绍如何用神经网络识别图像中的字母,从而自动识别验证码。验证码的设计初衷是便于人类理解,而不易被计算机识破。验证码的英文名叫作CAPTCHA,它取自以下短语中几个单词的首字母“Completely Automated Public Turing test to tell Computers and Humans Apart”,意思是能够区别计算机和人类的全自动的公共图灵测试。很多网站都在注册、评论系统中使用验证码,以防止别人恶意注册虚假账号或发布垃圾评论。
本章主要介绍如下内容。
神经网络
创建验证码和字母数据集
用
scikitimage库处理图像数据神经网络库
PyBrain从图像中抽取基本特征
使用神经网络进行更大规模的分类任务
用后处理提升效果
8.1 人工神经网络
神经网络算法最初是根据人类大脑的工作机制设计的。然而,该领域近年所取得的进展主要得益于数学而不是生物学。神经网络由一系列相互连接的神经元组成。每个神经元都是一个简单的函数,接收一定输入,给出相应输出。
神经元可以使用任何标准函数来处理数据,比如线性函数,这些函数统称为激活函数(activation function)。一般来说,神经网络学习算法要能正常工作,激活函数应当是可导(derivable)和光滑的。常用的激活函数有逻辑斯谛函数,函数表达式如下(x 为神经元的输入,k、L 通常为1,这时函数达到最大值)。
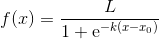
下图为 x 取-6到6之间的函数图像。
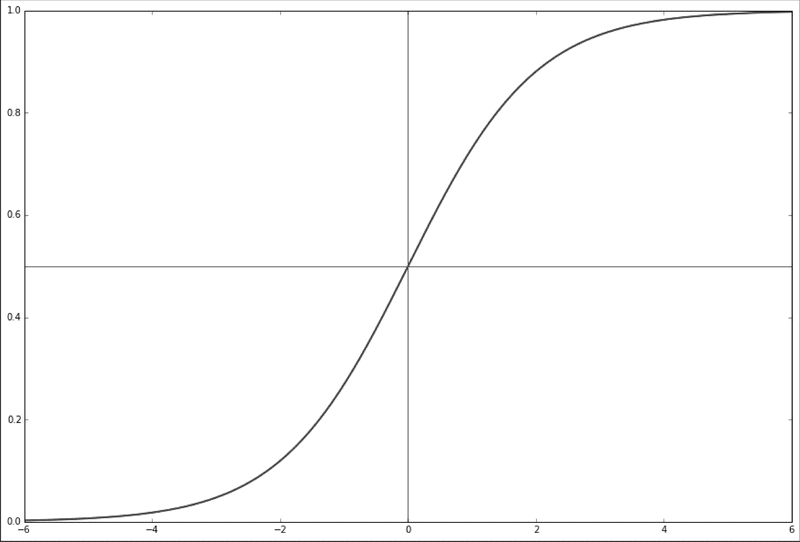
两条红线的交点表示 x 为0时,函数值为0.5。
每个神经元接收几个输入,根据这几个输入1,计算输出。这样的一个个神经元连接在一起组成了神经网络,对数据挖掘应用来说,它非常强大。这些神经元紧密连接,密切配合,能够通过学习得到一个模型,使得神经网络成为机器学习领域最强大的概念之一。
1对带权重的输入加总。——译者注
神经网络简介
用于数据挖掘应用的神经网络,神经元按照层级进行排列。第一层,也就是输入层,接收来自数据集的输入。第一层中的每个神经元对输入进行计算,把得到的结果传给第二层的神经元。这种叫作前向神经网络。本章暂且把它简称为神经网络。此外,还有几种神经网络,适用于不同的应用。第11章会讲到另外一种类型的神经网络。
神经网络中,上一层的输出作为下一层的输入,直到到达最后一层:输出层。输出结果表示的是神经网络分类器给出的分类结果。输入层和输出层之间的所有层被称为隐含层,因为在这些层中,其数据表现方式,常人难以理解。大多数神经网络至少有三层,而如今大多数应用所使用的神经网络层次比这多得多。
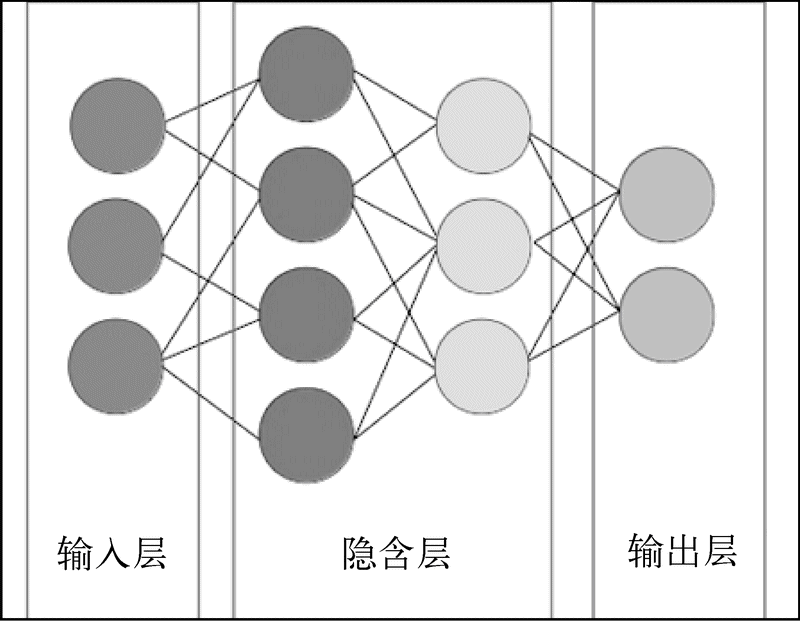
我们优先考虑使用全连接层,即上一层中每个神经元的输出都输入到下一层的所有神经元。实际构建神经网络时,就会发现,训练过程中,很多权重都会被设置为0,有效地减少边的数量。比起其他连接模式,全连接神经网络更简单,计算起来更快捷。
神经元激活函数通常使用逻辑斯谛函数,每层神经元之间为全连接,创建和训练神经网络还需要用到其他几个参数。创建过程,指定神经网络的规模需要用到两个参数:神经网络共有多少层,隐含层每层有多少个神经元(输入层和输出层神经元数量通常由数据集来定)。
训练过程还会用到一个参数:神经元之间边的权重。一个神经元连接到另外一个神经元,两者之间的边具有一定的权重,在计算输出时,用边的权重乘以信号的大小(signal,第一个神经元的输出)。如果边的权重为0.8,神经元激活后,输出值为1,那么下一个神经元从前面这个神经元得到的输入就是0.8。如果第一个神经元没有激活,值为0,那么输出到第二个神经元的值就是0。
神经网络大小合适,且权重经过充分训练,它的分类效果才能精确。大小合适并不是越大越好,因为神经网络过大,训练时间会很长,更容易出现过拟合训练集的情况。
通常,开始时使用随机选取的权重,训练过程中再逐步更新。
设置好第一个参数(网络的大小),再从训练集中训练得到边的权重参数后,就能构造分类器。然后,就可以用它进行分类,跟前几章用到的分类器算法很像。但是,首先需要准备训练集和测试集。
8.2 创建数据集
本章,我们将扮演骇客这个角色,我们想编写破解网站验证码的程序,这样我们就有能力在别人网站上发布恶意广告。需要注意的是,我们要破解的验证码,难度比不上现在网上常用的;还有就是发表垃圾广告不太道德。
我们只使用长度为4个字母的英文单词作为验证码,如下图所示。

我们的目标是编写程序还原图像中的单词,步骤如下。
(1) 把大图像分成只包含一个字母的4张小图像。
(2) 为每个字母分类。
(3) 把字母重新组合为单词。
(4) 用词典修正单词识别错误。
我们的验证码破解算法做出了以下几个假设。首先,验证码中的单词是一个完整的、有效的英文单词,其长度为4个字母(实际上,生成和破解验证码,我们都使用同一个词典)。其次,单词全部字母均为大写形式,不使用符号、数字或空格。为了增加难度,在生成图像时对单词使用不同的错切(shear)变化效果。
8.2.1 绘制验证码
接下来,我们编写创建验证码的函数,目标是绘制一张含有单词的图像,对单词使用错切变化效果。绘制图像要用到PIL库,错切变化需要使用scikitimage库。scikitimage库能够接收PIL库导出的numpy数组格式的图像数据,因此这两个工具可以结合使用。
PIL和scikitimage库都可以用pip安装:
pip install PILpip install scikitimage
首先,导入即将用到的库和模块。导入numpy,从PIL中导入Image等绘图函数。
import numpy as npfrom PIL import Image, ImageDraw, ImageFontfrom skimage import transform as tf
接着,创建用于生成验证码的基础函数。这个函数接收一个单词和错切值(通常在0到0.5之间),返回用numpy数组格式表示的图像。该函数还提供指定图像大小的参数,因为后面还会用它生成只包含单个字母的测试数据。代码如下:
def create_captcha(text, shear=0, size=(100, 24)):
我们使用字母L来生成一张黑白图像,为ImageDraw类初始化一个实例。这样,我们就可以用PIL绘图。代码如下:
im = Image.new("L", size, "black")draw = ImageDraw.Draw(im)
指定验证码文字所使用的字体。这里要用到字体文件,下面代码中的文件名(Coval.otf)应该指向文件存放位置(我把它放到当前笔记本所在目录)。
font = ImageFont.truetype(r"Coval.otf", 22)draw.text((2, 2), text, fill=1, font=font)
把PIL图像转换为numpy数组,以便用scikitimage库为图像添加错切变化效果。scikitimage大部分计算都使用numpy数组格式。代码如下:
image = np.array(im)
然后,应用错切变化效果,返回图像。
affine_tf = tf.AffineTransform(shear=shear)image = tf.warp(image, affine_tf)return image / image.max()
上面最后一行代码对图像特征进行归一化处理,确保特征值落在0到1之间。归一化处理可在数据预处理、分类或其他阶段进行。
现在,我们可以轻松生成图像,使用pyplot绘制图像。首先设定魔术方法%matplotlib,指定在当前笔记本作图,导入pyplot。代码如下:
%matplotlib inlinefrom matplotlib import pyplot as plt
生成验证码图像并显示它。
image = create_captcha("GENE", shear=0.5)plt.imshow(image, cmap='Greys')
生成的图像就是本节开头你见到的那张,效果还不错吧。
8.2.2 将图像切分为单个的字母
虽然我们的验证码是单词,但是我们不打算构造能够识别成千上万个单词的分类器,而是把大问题转化为更小的问题:识别字母。
验证码识别算法的下一步是分割单词,找到其中的字母。具体做法是,创建一个函数,寻找图像中连续的黑色像素,抽取它们作为新的小图像。这些小图像(或者至少应该)就是我们要找的字母。
首先,导入图像分割函数要用到的label、regionprops函数。
from skimage.measure import label, regionprops
图像分割函数接收图像,返回小图像列表,每张小图像为单词的一个字母,函数声明如下:
def segment_image(image):
我们要做的第一件事就是检测每个字母的位置,这就要用到scikitimage的label函数,它能找出图像中像素值相同且又连接在一起的像素块。这有点像第7章中的连通分支。
label函数的参数为图像数组,返回跟输入同型的数组。在返回的数组中,图像连接在一起的区域用不同的值来表示,在这些区域以外的像素用0来表示。代码如下:
labeled_image = label(image > 0)
抽取每一张小图像,将它们保存到一个列表中。
subimages = []
scikitimage库还提供抽取连续区域的函数:regionprops。遍历这些区域,分别对它们进行处理。
for region in regionprops(labeled_image):
这样,通过region对象就能获取到当前区域的相关信息。我们这里要用到当前区域的起始和结束位置的坐标。
start_x, start_y, end_x, end_y = region.bbox
用这两组坐标作为索引就能抽取到小图像(image对象为numpy数组,可以直接用索引值),然后,把它保存到subimages列表中。代码如下:
subimages.append(image[start_x:end_x,start_y:end_y])
最后(循环外面),返回找到的小图像,每张(希望如此)小图像包含单词的一个字母区域。没有找到小图像的情况,直接把原图像作为子图返回。代码如下:
if len(subimages) == 0:return [image,]return subimages
使用刚定义的这个函数,就能从前面生成的验证码中找到小图像。
subimages = segment_image(image)
还可以像下面这样查看每张小图像。
f, axes = plt.subplots(1, len(subimages), figsize=(10, 3))for i in range(len(subimages)):axes[i].imshow(subimages[i], cmap="gray")
结果如下。
图像切割效果还不错,但是你可能注意到,每张小图像都多少带有相邻字母的一部分。
8.2.3 创建训练集
使用图像切割函数就能创建字母数据集,其中字母使用了不同的错切效果。然后,就可以训练神经网络分类器来识别图像中的字母。
首先,指定随机状态值,创建字母列表,指定错切值。这里几乎没有新内容,numpy的arange函数你可能没用过,它跟Python的range函数类似——只不过arange函数可以和numpy的数组一起用,步长可以使用浮点数。代码如下:
from sklearn.utils import check_random_staterandom_state = check_random_state(14)letters = list("ABCDEFGHIJKLMNOPQRSTUVWXYZ")shear_values = np.arange(0, 0.5, 0.05)
再来创建一个函数(用来生成一条训练数据),从我们提供的选项中随机选取字母和错切值。代码如下:
def generate_sample(random_state=None):random_state = check_random_state(random_state)letter = random_state.choice(letters)shear = random_state.choice(shear_values)
返回字母图像及表示图像中字母属于哪个类别的数值。字母A为类别0,B为类别1,C为类别2,以此类推。代码如下:
return create_captcha(letter, shear=shear, size=(20, 20)),letters.index(letter)
在上述函数体的外面,调用该函数,生成一条训练数据,用pyplot显示图像。
image, target = generate_sample(random_state)plt.imshow(image, cmap="Greys")print("The target for this image is: {0}".format(target))
调用几千次该函数,就能生成足够的训练数据。把这些数据传入到numpy的数组里,因为数组操作起来比列表更容易。代码如下:
dataset, targets = zip(*(generate_sample(random_state) for i inrange(3000)))dataset = np.array(dataset, dtype='float')targets = np.array(targets)
我们共有26个类别,每个类别(字母)用从0到25之间的一个整数表示。神经网络一般不支持一个神经元输出多个值,但是多个神经元就能有多个输出,每个输出值在0到1之间。因此,我们对类别使用一位有效码编码方法,这样,每条数据就能得到26个输出。如果结果像某字母,使用近似于1的值;如果不像,就用近似于0的值。代码如下:
from sklearn.preprocessing import OneHotEncoderonehot = OneHotEncoder()y = onehot.fit_transform(targets.reshape(targets.shape[0],1))
我们用的库不支持稀疏矩阵,因此,需要将稀疏矩阵转换为密集矩阵。代码如下:
y = y.todense()
8.2.4 根据抽取方法调整训练数据集
得到的数据集跟即将使用的方法有较大出入。数据集每条数据都是一个恰好为20像素见方的字母。我们所使用的方法是从单词中抽取字母,而这可能会挤压图像,使图像偏离中心或者引入其他问题。
理想情况下,训练分类器所使用的数据应该与分类器即将处理的数据尽可能相似。但实际中,经常有所不同,但是应尽量缩小两者之间的差别。
对于验证码识别实验,最理想的情况是,从实际的验证码中抽取字母,并对它们进行标注。为了节省时间,我们只在训练集上运行分割函数,返回分割后得到的字母图像 。
我们需要用到scikitimage库中的resize函数,因为我们得到的小图像并不总是20像素见方。代码如下:
from skimage.transform import resize
现在,就可以对每条数据运行segment_image函数,将得到的小图像调整为20像素见方。代码如下:
dataset = np.array([resize(segment_image(sample)[0], (20, 20)) forsample in dataset])
最后,创建我们的数据集。dataset数组为三维的,因为它里面存储的是二维图像信息。由于分类器接收的是二维数组,因此,需要将最后两维扁平化。
X = dataset.reshape((dataset.shape[0], dataset.shape[1] * dataset.shape[2]))
使用scikitlearn中的train_test_split函数,把数据集切分为训练集和测试集。代码如下:
from sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = \train_test_split(X, y, train_size=0.9)
8.3 训练和分类
接下来,我们就来构造神经网络分类器,接收图像,预测图像中的(单个)字母是什么。
我们将使用之前创建的单个字母训练集。数据集本身很简单。每张图像为20像素大小,每个像素用1(黑)或0(白)来表示。每张图像有400个特征,将把它们作为神经网络的输入。输出结果为26个0到1之间的值。值越大,表示图像中的字母为该值所对应的字母(输出的第一个值对应字母A,第二个对应字母B,以此类推)的可能性越大。
我们用PyBrain库来构建神经网络分类器。
跟我们之前见到的所有库一样,
PyBrain也可以用pip来安装:pip install pybrain。
PyBrain库使用自己的数据集格式,好在创建这种格式的训练集和测试集并不太难。代码如下:
from pybrain.datasets import SupervisedDataSet
首先,遍历我们的训练集,把每条数据添加到一个新的SupervisedDataSet实例中。代码如下:
training = SupervisedDataSet(X.shape[1], y.shape[1])for i in range(X_train.shape[0]):training.addSample(X_train[i], y_train[i])
然后,遍历测试集,同样把每条数据添加到一个新的SupervisedDataSet实例中。代码如下:
testing = SupervisedDataSet(X.shape[1], y.shape[1])for i in range(X_test.shape[0]):testing.addSample(X_test[i], y_test[i])
现在就可以创建神经网络了。我们将创建一个最基础的、具有三层结构的神经网络,它由输入层、输出层和一层隐含层组成。输入层和输出层的神经元数量是固定的。数据集有400个特征,那么第一层就需要有400个神经元,而26个可能的类别表明我们需要26个用于输出的神经元。
确定隐含层的神经元数量可能相当困难。如果神经元数量过多,神经网络呈现出稀疏的特点,这时要训练足够多的神经元恰当地表示数据就有困难,这往往会导致过拟合训练数据的问题。相反,如果神经元过少,每个对分类结果的贡献过大,再加上训练不充分,就很可能产生低拟合现象。我发现一开始用漏斗形状不错,即隐含层神经元数量介于输入和输出层之间。本章,隐含层用100个神经元,你可以尝试其他值,看看能不能取得更好的效果。
导入buildNetwork函数,指定维度,创建神经网络。第一个参数X.shape[1]为输入层神经元的数量,也就是特征数(数据集X的列数)。第二个参数指隐含层的神经元数量,这里设置为100。第三个参数为输出层神经元数量,由类别数组y的形状来确定。最后,除去输出层外,我们每层使用一个一直处于激活状态的偏置神经元(bias neuron,它与下一层神经元之间有边连接,边的权重经过训练得到)。代码如下:
from pybrain.tools.shortcuts import buildNetworknet = buildNetwork(X.shape[1], 100, y.shape[1], bias=True)
现在,我们就可以训练神经网络,寻找合适的权重值。但是如何训练神经网络呢?
8.3.1 反向传播算法
反向传播算法(back propagation,backprop)的工作机制为对预测错误的神经元施以惩罚。从输出层开始,向上层层查找预测错误的神经元,微调这些神经元输入值的权重,以达到修复输出错误的目的。
神经元之所以给出错误的预测,原因在于它前面为其提供输入的神经元,更确切来说是由这两个神经元之间边的权重及输入值决定的。我们可以尝试对权重进行微调。每次调整的幅度取决于以下两个方面:神经元各边权重的误差函数的偏导数和一个叫作学习速率的参数(通常使用很小的值)。计算出函数误差的梯度,再乘以学习速率,用总权重减去得到的值。下面将给出例子。梯度的符号由误差决定,每次对权重的修正都是朝着给出正确的预测值努力。有时候,修正结果为局部最优(local optima),比起其他权重组合要好,但所得到的各权重还不是最优组合。
反向传播算法从输出层开始,层层向上回溯到输入层。到达输入层后,所有边的权重更新完毕。
PyBrain提供了backprop算法的一种实现,在神经网络上调用trainer类即可。代码如下:
from pybrain.supervised.trainers import BackpropTrainertrainer = BackpropTrainer(net, training, learningrate=0.01,weightdecay=0.01)
backprop算法在训练集上进行迭代,每次都对权重进行微调。当误差减小的幅度很小时,表明算法无法进一步缩小误差,继续训练已无意义,这时就可以停止算法运行。理论上,等误差不再缩小时,再停止运行。这个过程叫作算法收敛。但实际上我们不会等到误差停止缩小,因为这通常要花很长时间且效果有限。
此外,更简单的做法是,运行代码固定的步数(epoch)。每一步所包含的次数越多,所用时间也就越多,效果越好(每一步的提升效果呈下降趋势)。我们这里训练时,使用了20步,数量再多些,效果可能会有所改善(也许幅度很小)。代码如下:
trainer.trainEpochs(epochs=20)
运行前面的代码,这可能要花几分钟时间,长短取决于硬件,然后我们就能在测试集上进行预测。PyBrain提供了相应函数,只要在trainer实例上调用即可。
predictions = trainer.testOnClassData(dataset=testing)
得到预测值后,可以用scikitlearn计算F1值。
from sklearn.metrics import f1_scoreprint("F-score: {0:.2f}".format(f1_score(predictions,y_test.argmax(axis=1) )))
F1值为0.97,对于相对较小的模型来说,这个结果很了不起。别忘了我们的特征值只是简单的像素值,神经网络竟然知道怎么使用它们。
既然构建好了具有高精度的字母分类器,接下来看下怎么用它来识别单词,实现验证码破解功能。
8.3.2 预测单词
我们想分别识别每张小图像中的字母,然后把它们拼成单词,完成验证码识别。
我们来定义一个函数,接收验证码,用神经网络进行训练,返回单词预测结果。
def predict_captcha(captcha_image, neural_network):
使用前面定义的图像切割函数segment_image抽取小图像。
subimages = segment_image(captcha_image)
最终的预测结果——单词,将由小图像中的字母组成。这些小图像根据位置进行排序,从而保证拼接后得到的单词中各字母处在正确的位置上。
predicted_word = ""
遍历四张小图像。
for subimage in subimages:
每张小图像不太可能正好是20像素见方。调整大小后,才能用神经网络处理。
subimage = resize(subimage, (20, 20))
把小图像数据传入神经网络的输入层,激活神经网络。这些数据将在神经网络中进行传播,返回输出结果。神经网络在前面已经创建好了,现在只需激活它。代码如下:
outputs = net.activate(subimage.flatten())
神经网络输出26个值,每个值都有索引号,分别对应letters列表中有着相同索引的字母,每个值的大小表示与对应字母的相似度。为了获得实际的预测值,我们取到最大值的索引,再通过letters列表找到对应的字母。例如,如果第五个值最大,那么预测结果就为字母E。代码如下:
prediction = np.argmax(outputs)
把上面得到的字母添加到正在预测的单词中。
predicted_word += letters[prediction]
循环结束后,我们就已经找到了单词的各个字母,将其拼接成单词,最后返回这个单词。
return predicted_word
可以使用下面代码来做下测试。尝试不同的单词,看看可能会遇到什么错误,别忘了我们的神经网络只能处理大写字母。
word = "GENE"captcha = create_captcha(word, shear=0.2)print(predict_captcha(captcha, net))
我们可以把上面代码整合到一个函数里,便于进行多次尝试。这里沿用之前每个单词只包含四个字母的假设,降低预测任务的难度。删除prediction = prediction[:4],试试看可能会出什么错误。代码如下:
def test_prediction(word, net, shear=0.2):captcha = create_captcha(word, shear=shear)prediction = predict_captcha(captcha, net)prediction = prediction[:4]return word == prediction, word, prediction
上述函数返回结果依次为预测结果是否正确、验证码中的单词和预测结果的前四个字符。
上面代码能正确识别单词GENE,但是其他单词会出错。正确率如何?我们借助NLTK模块创建单词数据集,只使用长度为4的单词。从NLTK中导入words,代码如下:
from nltk.corpus import words
words实际上为corpus(语料库)对象,调用它的words()方法才能取到里面的单词。下面代码还加了长度为4的过滤条件。代码如下:
valid_words = [word.upper() for word in words.words() if len(word) ==4]
识别得到的所有长度为4的单词,分别统计识别正确和错误的数量。
num_correct = 0num_incorrect = 0for word in valid_words:correct, word, prediction = test_prediction(word, net,shear=0.2)if correct:num_correct += 1else:num_incorrect += 1print("Number correct is {0}".format(num_correct))print("Number incorrect is {0}".format(num_incorrect))
正确识别2832个单词,错误识别2681个,正确率仅为51%。而字母识别率为97%,两者差距太大。到底怎么回事?
首先,来看下正确率本身。其余条件相同的情况下,我们有四个字母,每个字母的正确率为97%,四个字母都正确的话,正确率约为88%(约为0.974)。一个字母出错将导致整个单词识别错误。
其次,错切值对正确率有影响。这次创建数据集时,随机从0到0.5之间选取一个数作为错切值。先前测试时错切值为0.2。错切值为0时,正确率为75%;错切值取0.5时,正确率只有2.5%。错切值越大,正确率越低。
另外一个原因在于我们之前随机选取字母组成单词,而字母在单词中的分布不是随机的。例如,字母E显然就比Q等其他字母使用频率更高。使用频度较高,但却常常被识别错误的字母,也会导致错误率上升。
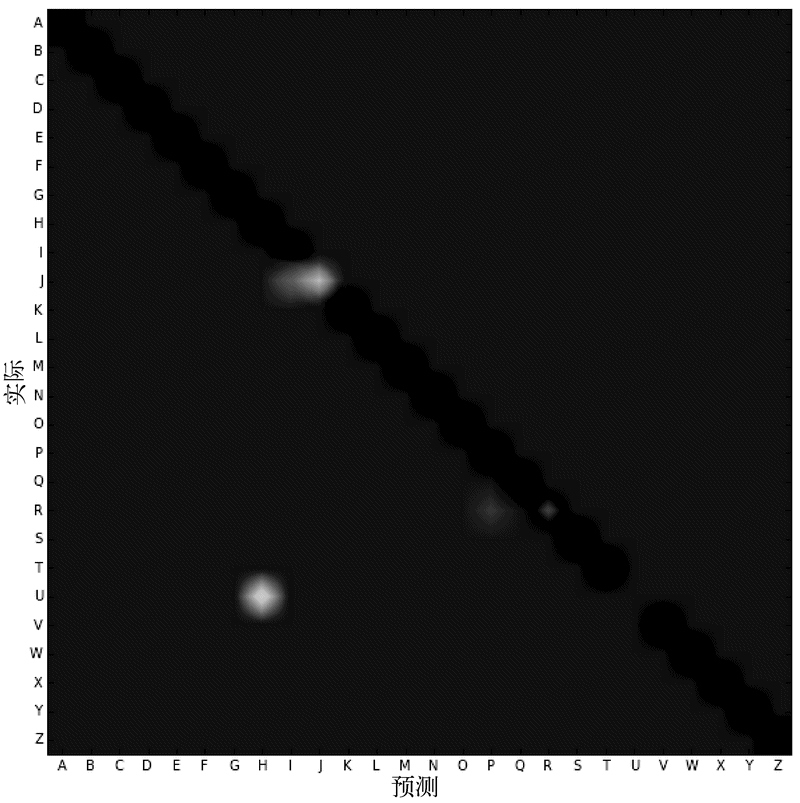
我们可以把经常识别错误的字母统计出来,用二维混淆矩阵来表示。每行和每列均为一个类别(字母)。
矩阵的每一项表示一个类别(行对应的类)被错误识别为另一个类别(列对应的类)的次数。例如,(4,2)这一项的值为6,表示字母D有6次被错误地识别为字母B。
from sklearn.metrics import confusion_matrixcm = confusion_matrix(np.argmax(y_test, axis=1), predictions)
理想情况下,混淆矩阵应该只有处于对角线的项(i,i)值不为零,其余各项的值均为零,否则就是分类有误。
用pyplot做成图,哪些字母容易混淆就一目了然,代码如下:
plt.figure(figsize=(10, 10))plt.imshow(cm)
下面代码中的tick_marks表示刻度,在坐标轴上标出每个字母,便于理解。
tick_marks = np.arange(len(letters))plt.xticks(tick_marks, letters)plt.yticks(tick_marks, letters)plt.ylabel('Actual')plt.xlabel('Predicted')plt.show()
结果如下图所示。从图中,我们就能清楚地看到主要的错误在于几乎无一例外地把U识别为H!
我们的词表中17%的单词含有字母U,这些单词几乎都会被识别错误。U的出现频率要高于H(11%的单词),我们不禁想到了一个提升正确率的简单方法(可能不够健壮):把所有预测结果为H的,都改为U。
下节将采用更为巧妙的方法,从词典中搜索跟预测结果相似的单词。
8.4 用词典提升正确率
我们刚刚是直接返回预测结果,其实返回之前可以先检查一下词典里是否包含该词条。如果单词在词典里,那么就返回预测结果,如果不在,我们找到和预测结果相似的单词,再把它作为更新过的预测结果返回。注意,该方法是基于所有验证码中的单词都是英语单词的假设,因此,对于随机选取字母组成的验证码来说不适用。其实这正是很多验证码不使用单词的原因之一。
还有一个问题要解决——如何找到最相近的单词?方法有很多。例如,比较词长。词长差不多的两个单词更相似。然而,通常认为,在相同位置有相同字母的两个单词更相似,这就要用到编辑距离。
8.4.1 寻找最相似的单词
列文斯坦编辑距离(Levenshtein edit distance)是一种通过比较两个短字符串,确定它们相似度的方法。它不太适合扩展,字符串很长时通常不用这种方法。编辑距离需要计算从一个单词变为另一个单词所需要的步骤数。以下操作都算一步。
(1) 在单词的任意位置插入一个新字母。
(2) 从单词中删除任意一个字母。
(3) 把一个字母替换为另外一个字母。
把一个单词转变为另外一个单词所需步数越少,这两个单词越相似,反之,差别越大。
NLTK实现了编辑距离算法,可以直接拿来用。导入后,指定两个单词,看下它们的编辑距离。
from nltk.metrics import edit_distancesteps = edit_distance("STEP", "STOP")print("The number of steps needed is: {0}".format(steps))
尝试不同的单词,你会发现编辑距离返回的结果跟我们的直觉很相近。编辑距离在检查拼写、听写错误和名称匹配(比如Marc和Mark的拼写形式就极易被搞混)方面用处很大。
然而,我们这里没这么复杂,只需要比较两个单词同等位置上的字母是否一致即可,不涉及字母的移动。因此,我们自己来编写距离度量函数,也就是统计同等位置上字母不同的数量。代码如下:
def compute_distance(prediction, word):return len(prediction) - sum(prediction[i] == word[i] for i inrange(len(prediction)))
用词长(4)减去同等位置上相同的字母的数量,得到的值越小表示两个词相似度越高。
8.4.2 组装起来
我们现在就来测试改进的预测函数,代码跟之前相似。首先,定义预测函数,这次把单词列表也传进去。
from operator import itemgetterdef improved_prediction(word, net, dictionary, shear=0.2):captcha = create_captcha(word, shear=shear)prediction = predict_captcha(captcha, net)prediction = prediction[:4]
到目前为止,代码跟之前的预测函数一致,还是取到预测结果的前四个字母。然而,这次还要检测单词是否在词典里。如果在,把单词作为预测结果返回;如果不在,找到最相似的单词返回。代码如下:
if prediction not in dictionary:
计算预测结果和词典中每个单词的距离,按照距离由小到大进行排序。代码如下:
distances = sorted([(word, compute_distance(prediction, word))for word in dictionary],key=itemgetter(1))
找到最为匹配的单词——也就是距离最小的单词——随后把这个单词作为预测结果返回。
best_word = distances[0]prediction = best_word[0]
函数返回结果跟之前相同:预测结果是否正确,验证码中的单词和预测结果。
return word == prediction, word, prediction
测试代码中需要变动的地方用粗体表示。
num_correct = 0num_incorrect = 0for word in valid_words:correct, word, prediction = improved_prediction(word, net, valid_words, shear=0.2)if correct:num_correct += 1else:num_incorrect += 1print("Number correct is {0}".format(num_correct))print("Number incorrect is {0}".format(num_incorrect))
上述代码运行时间稍长(计算预测结果跟词典中每个单词之间的距离要耗费一定时间),最终正确识别3037个单词,错误识别2476个,正确率较之前有4个百分点的提升,达到55%。由于预测结果跟词典中很多单词的相似度一致,算法随机从一组最相似的单词中选择最佳的,所以算法效果提升很有限。例如,词典中第一个单词AANI(埃及神话中狗头猿猴),跟其他44个单词距离相同。选中的几率就只有1/44。
如果我们作弊,预测结果只要从最相似的一组词中随机挑一个就算是正确的话,那么预测结果正确率将高达78%(代码请见本书配套的代码包)。
要进一步提升正确率,得改变距离测量方法,看能不能利用之前得到的混淆矩阵,找到经常被混淆的字母或其他有用信息。逐步改进效果,是很多数据挖掘算法的一个特点,这跟科学实验方法是一脉相承的——产生想法,做实验,分析结果,再根据结果做进一步的改进。
8.5 小结
本章的任务是根据验证码图像的像素值识别里面的单词。当然,为了简化难度,验证码使用由四个字母组成的英语单词。网站上实际使用的验证码要比这复杂得多——也应该这样!但是,只要对上面所讲的算法进行改进,就能通过神经网络,使用跟这里类似的方法破解更为复杂的验证码。scikitimage库提供大量图像处理工具,比如从图像中抽取不同形状的小图像和改善图像对比度的方法等。这些方法有助于破解验证码。
我们把识别单词的难题转化为识别字母的小问题,创建前向神经网络识别图像中的字母,取得了97%的准确率。
神经网络由一组组神经元连接而成,神经元为基本的计算单元,每个神经元都只包含一个函数。然而,所有的神经单元连接在一起就能解决复杂程度很高的问题。神经网络是深度学习的基础,后者可是当今数据挖掘领域最受关注的方向之一。
尽管识别字母正确率很高,但是单词识别正确率陡然降至50%多点。原因有很多,其实这恰好说明把算法从实验环境搬到真实环境会遇到各种各样的困难。
使用词典,寻找最匹配的单词,能够提升正确率。我们考虑使用常用的编辑距离表示单词间的相似度;但是我们只关注字母错误而不深究与哪些编辑步骤(插入、删除)相关,因此简化了距离计算方法。最终正确率有所提升,但是还有很多要改进的地方。
下一章将继续研究字符串比较,尝试找出文档的主人(从多名可能的作者中)——只根据文档内容而不使用其他信息!
