- 第 3 章 Python 容器:列表、元组、字典与集合
- 3.1 列表和元组
- 3.2 列表
- 3.2.1 使用
[]或list()创建列表 - 3.2.2 使用
list()将其他数据类型转换成列表 - 3.2.3 使用
[offset]获取元素 - 3.2.4 包含列表的列表
- 3.2.5 使用
[offset]修改元素 - 3.2.6 指定范围并使用切片提取元素
- 3.2.7 使用
append()添加元素至尾部 - 3.2.8 使用
extend()或+=合并列表 - 3.2.9 使用
insert()在指定位置插入元素 - 3.2.10 使用
del删除指定位置的元素 - 3.2.11 使用
remove()删除具有指定值的元素 - 3.2.12 使用
pop()获取并删除指定位置的元素 - 3.2.13 使用
index()查询具有特定值的元素位置 - 3.2.14 使用
in判断值是否存在 - 3.2.15 使用
count()记录特定值出现的次数 - 3.2.16 使用
join()转换为字符串 - 3.2.17 使用
sort()重新排列元素 - 3.2.18 使用
len()获取长度 - 3.2.19 使用
=赋值,使用copy()复制
- 3.2.1 使用
- 3.3 元组
- 3.4 字典
- 3.5 集合
- 3.6 比较几种数据结构
- 3.7 建立大型数据结构
- 3.8 练习
第 3 章 Python 容器:列表、元组、字典与集合
第 2 章介绍了 Python 最底层的基本数据类型:布尔型、整型、浮点型以及字符串型。如果把这些数据类型看作组成 Python 的原子,那么本章将要提到的数据结构就像分子一样。在这一章中,我们会把之前所学的基本 Python 类型以更为复杂的方式组织起来。这些数据结构以后会经常用到。在编程中,最常见的工作就是将数据进行拆分或合并,将其加工为特定的形式,而数据结构就是用以切分数据的钢锯以及合并数据的粘合枪。
3.1 列表和元组
大多数编程语言都有特定的数据结构来存储由一系列元素组成的序列,这些元素以它们所处的位置为索引:从第一个到最后一个依次编号。前一章已经见过 Python 字符串了,它本质上是字符组成的序列。你也在上一章初识了列表结构——由任意类型元素组成的序列。本章将更深入地了解列表。
除字符串外,Python 还有另外两种序列结构:元组和列表。它们都可以包含零个或多个元素。与字符串不同的是,元组和列表并不要求所含元素的种类相同,每个元素都可以是任何 Python 类型的对象。得益于此,你可以根据自己的需求和喜好创建具有任意深度及复杂度的数据结构。
为什么 Python 需要同时设定列表和元组这两种序列呢?这是因为元组是不可变的,当你给元组赋值时,这些值便被固定在了元组里,再也无法修改。然而,列表却是可变的,这意味着可以随意地插入或删除其中的元素。在后面的内容中,我会举许多关于这两种结构的例子,但重点会放在列表上。
说一点题外话,你可能听到过元组(tuple)的两种不同发音,究竟哪一种是正确的?是不是会担心,如果猜错了就会被别人认为是个装腔作势假装懂 Python 的人?其实你一点也不用担心。Python 之父吉多 ·范罗苏姆在 Twitter(https://twitter.com/gvanrossum/status/86144775731941376)上说:“每周的一三五我会把 tuple 念作 too-pull,而二四六我喜欢念作 tub-pull。至于礼拜天嘛,我从不会讨论这些。 :)”
3.2 列表
列表非常适合利用顺序和位置定位某一元素,尤其是当元素的顺序或内容经常发生改变时。与字符串不同,列表是可变的。你可以直接对原始列表进行修改:添加新元素、删除或覆盖已有元素。在列表中,具有相同值的元素允许出现多次。
3.2.1 使用[]或list()创建列表
列表可以由零个或多个元素组成,元素之间用逗号分开,整个列表被方括号所包裹:
>>> empty_list = [ ]>>> weekdays = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']>>> big_birds = ['emu', 'ostrich', 'cassowary']>>> first_names = ['Graham', 'John', 'Terry', 'Terry', 'Michael']
也可以使用 list() 函数来创建一个空列表:
>>> another_empty_list = list()>>> another_empty_list[]
上面的例子中,只有 weekdays 列表充分利用了列表的顺序性。first_names 则展示了列表中的值允许重复这一性质。
big_birds就更适合存储在一个集合中。本章的后半部分会了解到一些关于集合的内容。
3.2.2 使用list()将其他数据类型转换成列表
Python 的 list() 函数可以将其他数据类型转换成列表类型。下面的例子将一个字符串转换成了由单个字母组成的列表:
>>> list('cat')['c', 'a', 't']
接下来的例子将一个元组(在列表之后介绍)转换成了列表:
>>> a_tuple = ('ready', 'fire', 'aim')>>> list(a_tuple)['ready', 'fire', 'aim']
正如 2.3.9 节所述,使用 split() 可以依据分隔符将字符串切割成由若干子串组成的列表:
>>> birthday = '1/6/1952'>>> birthday.split('/')['1', '6', '1952']
如果待分割的字符串中包含连续的分隔符,那么在返回的列表中会出现空串元素:
>>> splitme = 'a/b//c/d///e'>>> splitme.split('/')['a', 'b', '', 'c', 'd', '', '', 'e']
如果把上面例子中的分隔符改成 // 则会得到如下结果:
>>> splitme = 'a/b//c/d///e'>>> splitme.split('//')>>>['a/b', 'c/d', '/e']
3.2.3 使用[offset]获取元素
和字符串一样,通过偏移量可以从列表中提取对应位置的元素:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> marxes[0]'Groucho'>>> marxes[1]'Chico'>>> marxes[2]'Harpo'
同样,负偏移量代表从尾部开始计数:
>>> marxes[-1]'Harpo'>>> marxes[-2]'Chico'>>> marxes[-3]'Groucho'>>>
5,从0开始计数)或者倒数第 5 个 marxes 元素时产生的异常:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> marxes[5]Traceback (most recent call last):File "<stdin>", line 1, in <module>IndexError: list index out of range>>> marxes[-5]Traceback (most recent call last):File "<stdin>", line 1, in <module>IndexError: list index out of range
3.2.4 包含列表的列表
列表可以包含各种类型的元素,包括其他列表,如下所示:
>>> small_birds = ['hummingbird', 'finch']>>> extinct_birds = ['dodo', 'passenger pigeon', 'Norwegian Blue']>>> carol_birds = [3, 'French hens', 2, 'turtledoves']>>> all_birds = [small_birds, extinct_birds, 'macaw', carol_birds]
all_birds 这个列表的结构是什么样子的?
>>> all_birds[['hummingbird', 'finch'], ['dodo', 'passenger pigeon', 'Norwegian Blue'], 'macaw',[3, 'French hens', 2, 'turtledoves']]
来访问第一个元素看看:
>>> all_birds[0]['hummingbird', 'finch']
第一个元素还是一个列表:事实上,它就是 small_birds,也就是创建 all_birds 列表时设定的第一个元素。以此类推,不难猜测第二个元素是什么:
>>> all_birds[1]['dodo', 'passenger pigeon', 'Norwegian Blue']
和预想的一样,这是之前指定的第二个元素 extinct_birds。如果想要访问 extinct_birds 的第一个元素,可以指定双重索引从 all_birds 中提取:
>>> all_birds[1][0]'dodo'
上面例子中的 [1] 指向外层列表 all_birds 的第二个元素,而 [0] 则指向内层列表的第一个元素。
3.2.5 使用[offset]修改元素
就像可以通过偏移量访问某元素一样,你也可以通过赋值对它进行修改:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> marxes[2] = 'Wanda'>>> marxes['Groucho', 'Chico', 'Wanda']
与之前一样,列表的偏移量必须是合法有效的。
通过这种方式无法修改字符串中的指定字符,因为字符串是不可变的。列表是可变的,因此你可以改变列表中的元素个数,以及元素的值。
3.2.6 指定范围并使用切片提取元素
你可以使用切片提取列表的一个子序列:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> marxes[0:2]['Groucho', 'Chico']
列表的切片仍然是一个列表。
与字符串一样,列表的切片也可以设定除 1 以外的步长。下面的例子从列表的开头开始每 2 个提取一个元素:
>>> marxes[::2]['Groucho', 'Harpo']
再试试从尾部开始提取,步长仍为 2:
>>> marxes[::-2]['Harpo', 'Groucho']
利用切片还可以巧妙地实现列表逆序:
>>> marxes[::-1]['Harpo', 'Chico', 'Groucho']
3.2.7 使用append()添加元素至尾部
传统的向列表中添加元素的方法是利用 append() 函数将元素一个个添加到尾部。假设前面的例子中我们忘记了添加 Zeppo,没关系,由于列表是可变的,可以方便地把它添加到尾部:
>>> marxes.append('Zeppo')>>> marxes['Groucho', 'Chico', 'Harpo', 'Zeppo']
3.2.8 使用extend()或+=合并列表
使用 extend() 可以将一个列表合并到另一个列表中。一个好心人又给了我们一份 Marx 兄弟的名字列表 others,我们希望能把它加到已有的 marxes 列表中:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> others = ['Gummo', 'Karl']>>> marxes.extend(others)>>> marxes['Groucho', 'Chico', 'Harpo', 'Zeppo', 'Gummo', 'Karl']
也可以使用 +=:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> others = ['Gummo', 'Karl']>>> marxes += others>>> marxes['Groucho', 'Chico', 'Harpo', 'Zeppo', 'Gummo', 'Karl']
如果错误地使用了 append(),那么 others 会被当成一个单独的元素进行添加,而不是将其中的内容进行合并:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> others = ['Gummo', 'Karl']>>> marxes.append(others)>>> marxes['Groucho', 'Chico', 'Harpo', 'Zeppo', ['Gummo', 'Karl']]
这个例子再次体现了列表可以包含不同类型的元素。上面的列表包含了四个字符串元素以及一个含有两个字符串的列表元素。
3.2.9 使用insert()在指定位置插入元素
append() 函数只能将新元素插入到列表尾部,而使用 insert() 可以将元素插入到列表的任意位置。指定偏移量为 0 可以插入列表头部。如果指定的偏移量超过了尾部,则会插入到列表最后,就如同 append() 一样,这一操作不会产生 Python 异常。
>>> marxes.insert(3, 'Gummo')>>> marxes['Groucho', 'Chico', 'Harpo', 'Gummo', 'Zeppo']>>> marxes.insert(10, 'Karl')>>> marxes['Groucho', 'Chico', 'Harpo', 'Gummo', 'Zeppo', 'Karl']
3.2.10 使用del删除指定位置的元素
校对员刚刚通知说 Gummo 确实是 Marx 兄弟的一员,但 Karl 并不是,因此我们需要撤销刚才最后插入的元素:
>>> del marxes[-1]>>> marxes['Groucho', 'Chico', 'Harpo', 'Gummo', 'Zeppo']
当列表中一个元素被删除后,位于它后面的元素会自动往前移动填补空出的位置,且列表长度减 1。再试试从更新后的 marxes 列表中删除 'Harpo':
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Zeppo']>>> marxes[2]'Harpo'>>> del marxes[2]>>> marxes['Groucho', 'Chico', 'Gummo', 'Zeppo']>>> marxes[2]'Gummo'
del是 Python 语句,而不是列表方法——无法通过marxes[-2].del()进行调用。del就像是赋值语句(=)的逆过程:它将一个 Python 对象与它的名字分离。如果这个对象无其他名称引用,则其占用空间也被会清除。
3.2.11 使用remove()删除具有指定值的元素
如果不确定或不关心元素在列表中的位置,可以使用 remove() 根据指定的值删除元素。再见了,Gummo:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Gummo', 'Zeppo']>>> marxes.remove('Gummo')>>> marxes['Groucho', 'Chico', 'Harpo', 'Zeppo']
3.2.12 使用pop()获取并删除指定位置的元素
使用 pop() 同样可以获取列表中指定位置的元素,但在获取完成后,该元素会被自动删除。 如果你为 pop() 指定了偏移量,它会返回偏移量对应位置的元素;如果不指定,则默认使 用 -1。因此,pop(0) 将返回列表的头元素,而 pop() 或 pop(-1) 则会返回列表的尾元素:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> marxes.pop()'Zeppo'>>> marxes['Groucho', 'Chico', 'Harpo']>>> marxes.pop(1)'Chico'>>> marxes['Groucho', 'Harpo']
append()来添加元素到尾部,并通过pop()从尾部删除元素,实际上,实现了一个被称为 LIFO(后进先出)队列的数据结构。我们更习惯称之为栈(stack)。如果使用pop(0)来删除元素则创建了一个 FIFO(先进先出)队列。这两种数据结构非常有用,你可以不断接收数据,并根据需求对最先到达的数据(FIFO)或最后到达的数据(LIFO)进行处理。
3.2.13 使用index()查询具有特定值的元素位置
如果想知道等于某一个值的元素位于列表的什么位置,可以使用 index() 函数进行查询:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> marxes.index('Chico')1
3.2.14 使用in判断值是否存在
判断一个值是否存在于给定的列表中有许多方式,其中最具有 Python 风格的是使用 in:
>>> marxes = ['Groucho', 'Chico', 'Harpo', 'Zeppo']>>> 'Groucho' in marxesTrue>>> 'Bob' in marxesFalse
同一个值可能出现在列表的多个位置,但只要至少出现一次,in 就会返回 True:
>>> words = ['a', 'deer', 'a', 'female', 'deer']>>> 'deer' in wordsTrue
3.2.15 使用count()记录特定值出现的次数
使用 count() 可以记录某一个特定值在列表中出现的次数:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> marxes.count('Harpo')1>>> marxes.count('Bob')0>>> snl_skit = ['cheeseburger', 'cheeseburger', 'cheeseburger']>>> snl_skit.count('cheeseburger')3
3.2.16 使用join()转换为字符串
2.3.10 节详细地讨论了 join() 的使用方法,这里又提供了一种新的使用方式:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> ', '.join(marxes)'Groucho, Chico, Harpo'
等等,你可能会觉得 join() 的使用顺序看起来有点别扭。这是因为 join() 实际上是一个字符串方法,而不是列表方法。不能通过 marxes.join(',') 进行调用,尽管这可能看起来更直观。join() 函数的参数是字符串或者其他可迭代的包含字符串的序列(例如上面例子中的字符串列表),它的输出是一个字符串。如果 join() 是列表方法,将无法对其他可迭代的对象(例如元组、字符串)使用。如果坚持想让它能接受任何迭代类型,你必须亲自为每一种类型的序列编写合并代码,这太过费力。试着这样来记忆 join() 的调用顺序:join() 是 split() 的逆过程,如下所示:
>>> friends = ['Harry', 'Hermione', 'Ron']>>> separator = ' * '>>> joined = separator.join(friends)>>> joined'Harry Hermione Ron'>>> separated = joined.split(separator)>>> separated['Harry', 'Hermione', 'Ron']>>> separated == friendsTrue
3.2.17 使用sort()重新排列元素
在实际应用中,经常需要将列表中的元素按值排序,而不是按照偏移量排序。Python 为此提供了两个函数:
列表方法
sort()会对原列表进行排序,改变原列表内容;通用函数
sorted()则会返回排好序的列表副本,原列表内容不变。
如果列表中的元素都是数字,它们会默认地被排列成从小到大的升序。如果元素都是字符串,则会按照字母表顺序排列:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> sorted_marxes = sorted(marxes)>>> sorted_marxes['Chico', 'Groucho', 'Harpo']
sorted_marxes 是一个副本,它的创建并不会改变原始列表的内容:
>>> marxes['Groucho', 'Chico', 'Harpo']
但对 marxes 列表调用列表函数 sort() 则会改变它的内容:
>>> marxes.sort()>>> marxes['Chico', 'Groucho', 'Harpo']
当列表中的所有元素都是同一种类型时(例如 marxes 中都是字符串),sort() 会正常工作。有些时候甚至多种类型也可——例如整型和浮点型——只要它们之间能够自动地互相转换:
>>> numbers = [2, 1, 4.0, 3]>>> numbers.sort()>>> numbers[1, 2, 3, 4.0]
默认的排序是升序的,通过添加参数 reverse=True 可以改变为降序排列:
>>> numbers = [2, 1, 4.0, 3]>>> numbers.sort(reverse=True)>>> numbers[4.0, 3, 2, 1]
3.2.18 使用len()获取长度
len() 可以返回列表长度:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> len(marxes)3
3.2.19 使用=赋值,使用copy()复制
如果将一个列表赋值给了多个变量,改变其中的任何一处会造成其他变量对应的值也被修改,如下所示:
>>> a = [1, 2, 3]>>> a[1, 2, 3]>>> b = a>>> b[1, 2, 3]>>> a[0] = 'surprise'>>> a['surprise', 2, 3]
现在,b 的值是什么?它会保持 [1, 2, 3],还是改变为 ['surprise', 2, 3] ?试一试:
>>> b['surprise', 2, 3]
还记得第 2 章中贴标签的比喻吗? b 与 a 实际上指向的是同一个对象,因此,无论我们是通过 a 还是通过 b 来修改列表的内容,其结果都会作用于双方:
>>> b['surprise', 2, 3]>>> b[0] = 'I hate surprises'>>> b['I hate surprises', 2, 3]>>> a['I hate surprises', 2, 3]
通过下面任意一种方法,都可以将一个列表的值复制到另一个新的列表中:
列表
copy()函数list()转换函数列表分片
[:]
测试初始时我们的列表叫作 a,然后利用 copy() 函数创建 b,利用 list() 函数创建 c,并使用列表分片创建 d:
>>> a = [1, 2, 3]>>> b = a.copy()>>> c = list(a)>>> d = a[:]
再次注意,在这个例子中,b、c、d 都是 a 的复制:它们是自身带有值的新对象,与原始的 a 所指向的列表对象 [1, 2, 3] 没有任何关联。改变 a 不影响 b、c 和 d 的复制:
>>> a[0] = 'integer lists are boring'>>> a['integer lists are boring', 2, 3]>>> b[1, 2, 3]>>> c[1, 2, 3]>>> d[1, 2, 3]
3.3 元组
与列表类似,元组也是由任意类型元素组成的序列。与列表不同的是,元组是不可变的,这意味着一旦元组被定义,将无法再进行增加、删除或修改元素等操作。因此,元组就像是一个常量列表。
3.3.1 使用()创建元组
下面的例子展示了创建元组的过程,它的语法与我们直观上预想的有一些差别。
可以用 () 创建一个空元组:
>>> empty_tuple = ()>>> empty_tuple()
创建包含一个或多个元素的元组时,每一个元素后面都需要跟着一个逗号,即使只包含一个元素也不能省略:
>>> one_marx = 'Groucho',>>> one_marx('Groucho',)
如果创建的元组所包含的元素数量超过 1,最后一个元素后面的逗号可以省略:
>>> marx_tuple = 'Groucho', 'Chico', 'Harpo'>>> marx_tuple('Groucho', 'Chico', 'Harpo')
Python 的交互式解释器输出元组时会自动添加一对圆括号。你并不需要这么做——定义元组真正靠的是每个元素的后缀逗号——但如果你习惯添加一对括号也无可厚非。可以用括号将所有元素包裹起来,这会使得程序更加清晰:
>>> marx_tuple = ('Groucho', 'Chico', 'Harpo')>>> marx_tuple('Groucho', 'Chico', 'Harpo')
可以一口气将元组赋值给多个变量:
>>> marx_tuple = ('Groucho', 'Chico', 'Harpo')>>> a, b, c = marx_tuple>>> a'Groucho'>>> b'Chico'>>> c'Harpo'
有时这个过程被称为元组解包。
可以利用元组在一条语句中对多个变量的值进行交换,而不需要借助临时变量:
>>> password = 'swordfish'>>> icecream = 'tuttifrutti'>>> password, icecream = icecream, password>>> password'tuttifrutti'>>> icecream'swordfish'>>>
tuple() 函数可以用其他类型的数据来创建元组:
>>> marx_list = ['Groucho', 'Chico', 'Harpo']>>> tuple(marx_list)('Groucho', 'Chico', 'Harpo')
3.3.2 元组与列表
在许多地方都可以用元组代替列表,但元组的方法函数与列表相比要少一些——元组没有 append()、insert(),等等——因为一旦创建元组便无法修改。既然列表更加灵活,那为什么不在所有地方都使用列表呢?原因如下所示:
元组占用的空间较小
你不会意外修改元组的值
可以将元组用作字典的键(详见 3.4 节)
命名元组(详见第 6 章“命名元组”小节)可以作为对象的替代
函数的参数是以元组形式传递的(详见 4.7 节)
这一节不会再介绍更多关于元组的细节了。实际编程中,更多场合用到的是列表和字典,而接下来要介绍的就是字典结构。
3.4 字典
字典(dictionary)与列表类似,但其中元素的顺序无关紧要,因为它们不是通过像 0 或 1 的偏移量访问的。取而代之,每个元素拥有与之对应的互不相同的键(key),需要通过键来访问元素。键通常是字符串,但它还可以是 Python 中其他任意的不可变类型:布尔型、整型、浮点型、元组、字符串,以及其他一些在后面的内容中会见到的类型。字典是可变的,因此你可以增加、删除或修改其中的键值对。
如果使用过只支持数组或列表的语言,那么你很快就会爱上 Python 里的字典类型。
3.4.1 使用{}创建字典
用大括号({})将一系列以逗号隔开的键值对(key:value)包裹起来即可进行字典的创建。最简单的字典是空字典,它不包含任何键值对:
>>> empty_dict = {}>>> empty_dict{}
引用 Ambrose Bierce 的《魔鬼辞典》(The Devil's Dictionary)来创建一个字典:
>>> bierce = {... "day": "A period of twenty-four hours, mostly misspent",... "positive": "Mistaken at the top of one's voice",... "misfortune": "The kind of fortune that never misses",... }>>>
在交互式解释器中输入字典名会打印出它所包含的所有键值对:
>>> bierce{'misfortune': 'The kind of fortune that never misses','positive': "Mistaken at the top of one's voice",'day': 'A period of twenty-four hours, mostly misspent'}
3.4.2 使用dict()转换为字典
可以用 dict() 将包含双值子序列的序列转换成字典。(你可能会经常遇到这种子序列,例如“Strontium,90,Carbon,14”或者“Vikings,20,Packers,7”,等等。)每个子序列的第一个元素作为键,第二个元素作为值。
首先,这里有一个使用 lol(a list of two-item list)创建字典的小例子:
>>> lol = [ ['a', 'b'], ['c', 'd'], ['e', 'f'] ]>>> dict(lol){'c': 'd', 'a': 'b', 'e': 'f'}
可以对任何包含双值子序列的序列使用 dict(),下面是其他例子。
包含双值元组的列表:
>>> lot = [ ('a', 'b'), ('c', 'd'), ('e', 'f') ]>>> dict(lot){'c': 'd', 'a': 'b', 'e': 'f'}
包含双值列表的元组:
>>> tol = ( ['a', 'b'], ['c', 'd'], ['e', 'f'] )>>> dict(tol){'c': 'd', 'a': 'b', 'e': 'f'}
双字符的字符串组成的列表:
>>> los = [ 'ab', 'cd', 'ef' ]>>> dict(los){'c': 'd', 'a': 'b', 'e': 'f'}
双字符的字符串组成的元组:
>>> tos = ( 'ab', 'cd', 'ef' )>>> dict(tos){'c': 'd', 'a': 'b', 'e': 'f'}
4.5.4 节会教你如何使用 zip() 函数,利用它能非常简单地创建上面这种双元素序列。
3.4.3 使用[key]添加或修改元素
向字典中添加元素非常简单,只需指定该元素的键并赋予相应的值即可。如果该元素的键已经存在于字典中,那么该键对应的旧值会被新值取代。如果该元素的键并未在字典中出现,则会被加入字典。与列表不同,你不需要担心赋值过程中 Python 会抛出越界异常。
我们来建立一个包含大多数 Monty Python 成员名字的字典,用他们的姓当作键,名当作值:
>>> pythons = {... 'Chapman': 'Graham',... 'Cleese': 'John',... 'Idle': 'Eric',... 'Jones': 'Terry',... 'Palin': 'Michael',... }>>> pythons{'Cleese': 'John', 'Jones': 'Terry', 'Palin': 'Michael','Chapman': 'Graham', 'Idle': 'Eric'}
等等,我们好像落下了一个人:生于美国的 Terry Gilliam。下面是一个糟糕的程序员为了将 Gilliam 添加进字典而编写的代码,他粗心地将 Gilliam 的名字打错了:
>>> pythons['Gilliam'] = 'Gerry'>>> pythons{'Cleese': 'John', 'Gilliam': 'Gerry', 'Palin': 'Michael','Chapman': 'Graham', 'Idle': 'Eric', 'Jones': 'Terry'}
下面是另一位颇具 Python 风格的程序员的修补代码:
>>> pythons['Gilliam'] = 'Terry'>>> pythons{'Cleese': 'John', 'Gilliam': 'Terry', 'Palin': 'Michael','Chapman': 'Graham', 'Idle': 'Eric', 'Jones': 'Terry'}
通过使用相同的键('Gilliam')将原本的对应值 'Gerry' 修改为了 'Terry'。
记住,字典的键必须保证互不相同。这就是为什么在这里使用姓作为键,而不是使用名——Monty Python 的成员中有两个都叫 Terry !如果创建字典时同一个键出现了两次,那么后面出现的值会取代之前的值:
>>> some_pythons = {... 'Graham': 'Chapman',... 'John': 'Cleese',... 'Eric': 'Idle',... 'Terry': 'Gilliam',... 'Michael': 'Palin',... 'Terry': 'Jones',... }>>> some_pythons{'Terry': 'Jones', 'Eric': 'Idle', 'Graham': 'Chapman','John': 'Cleese', 'Michael': 'Palin'}
上面例子中,我们首先将 'Gilliam' 赋值给了键 'Terry',然后又用 'Jones' 把它取代掉了。
3.4.4 使用update()合并字典
使用 update() 可以将一个字典的键值对复制到另一个字典中去。
首先定义一个包含所有成员的字典 pythons:
>>> pythons = {... 'Chapman': 'Graham',... 'Cleese': 'John',... 'Gilliam': 'Terry',... 'Idle': 'Eric',... 'Jones': 'Terry',... 'Palin': 'Michael',... }>>> pythons{'Cleese': 'John', 'Gilliam': 'Terry', 'Palin': 'Michael','Chapman': 'Graham', 'Idle': 'Eric', 'Jones': 'Terry'}
接着定义一个包含其他喜剧演员的字典,命名为 others:
>>> others = { 'Marx': 'Groucho', 'Howard': 'Moe' }
现在,出现了另一个糟糕的程序员,它认为 others 应该被归入 Monty Python 成员中:
>>> pythons.update(others)>>> pythons{'Cleese': 'John', 'Howard': 'Moe', 'Gilliam': 'Terry','Palin': 'Michael', 'Marx': 'Groucho', 'Chapman': 'Graham','Idle': 'Eric', 'Jones': 'Terry'}
如果待添加的字典与待扩充的字典包含同样的键会怎样?是的,新归入字典的值会取代原有的值:
>>> first = {'a': 1, 'b': 2}>>> second = {'b': 'platypus'}>>> first.update(second)>>> first{'b': 'platypus', 'a': 1}
3.4.5 使用del删除具有指定键的元素
技术上来说,上面那个糟糕的程序员写的代码倒是正确的。但是他不应该这么做! others 里的成员虽然也很搞笑很出名,但他们终归不是 Monty Python 的成员。把最后添加的两个成员清除出去:
>>> del pythons['Marx']>>> pythons{'Cleese': 'John', 'Howard': 'Moe', 'Gilliam': 'Terry','Palin': 'Michael', 'Chapman': 'Graham', 'Idle': 'Eric','Jones': 'Terry'}>>> del pythons['Howard']>>> pythons{'Cleese': 'John', 'Gilliam': 'Terry', 'Palin': 'Michael','Chapman': 'Graham', 'Idle': 'Eric', 'Jones': 'Terry'}
3.4.6 使用clear()删除所有元素
使用 clear(),或者给字典变量重新赋值一个空字典({})可以将字典中所有元素删除:
>>> pythons.clear()>>> pythons{}>>> pythons = {}>>> pythons{}
3.4.7 使用in判断是否存在
如果你希望判断某一个键是否存在于一个字典中,可以使用 in。我们来重新定义一下 pythons 字典,这一次可以省略一两个人名:
>>> pythons = {'Chapman': 'Graham', 'Cleese': 'John','Jones': 'Terry', 'Palin': 'Michael'}
测试一下看看谁在里面:
>>> 'Chapman' in pythonsTrue>>> 'Palin' in pythonsTrue
这一次记得把 Terry Gilliam 添加到成员字典里了吗?
>>> 'Gilliam' in pythonsFalse
糟糕,好像又忘记了。
3.4.8 使用[key]获取元素
这是对字典最常进行的操作,只需指定字典名和键即可获得对应的值:
>>> pythons['Cleese']'John'
如果字典中不包含指定的键,会产生一个异常:
>>> pythons['Marx']Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: 'Marx'
有两种方法可以避免这种情况的发生。第一种是在访问前通过 in 测试键是否存在,就像在上一小节看到的一样:
>>> 'Marx' in pythonsFalse
另一种方法是使用字典函数 get()。你需要指定字典名,键以及一个可选值。如果键存在,会得到与之对应的值:
>>> pythons.get('Cleese')'John'
反之,若键不存在,如果你指定了可选值,那么 get() 函数将返回这个可选值:
>>> pythons.get('Marx', 'Not a Python')'Not a Python'
否则,会得到 None(在交互式解释器中什么也不会显示):
>>> pythons.get('Marx')>>>
3.4.9 使用keys()获取所有键
使用 keys() 可以获得字典中的所有键。在接下来的几个例子中,我们将换一个示例:
>>> signals = {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera'}>>> signals.keys()dict_keys(['green', 'red', 'yellow'])
keys()会返回一个列表,而在 Python 3 中则会返回dict_keys(),它是键的迭代形式。这种返回形式对于大型的字典非常有用,因为它不需要时间和空间来创建返回的列表。有时你需要的可能就是一个完整的列表,但在 Python 3 中,你只能自己调用list()将dict_keys转换为列表类型。
>>> list( signals.keys() )['green', 'red', 'yellow']在 Python 3 里,你同样需要手动使用
list()将values()和items()的返回值转换为普通的 Python 列表。之后的例子中会用到这些。
3.4.10 使用values()获取所有值
使用 values() 可以获取字典中的所有值:
>>> list( signals.values() )['go', 'smile for the camera', 'go faster']
3.4.11 使用items()获取所有键值对
使用 items() 函数可以获取字典中所有的键值对:
>>> list( signals.items() )[('green', 'go'), ('red', 'smile for the camera'), ('yellow', 'go faster')]
每一个键值对以元组的形式返回,例如 ('green','go')。
3.4.12 使用=赋值,使用copy()复制
与列表一样,对字典内容进行的修改会反映到所有与之相关联的变量名上:
>>> signals = {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera'}>>> save_signals = signals>>> signals['blue'] = 'confuse everyone'>>> save_signals{'blue': 'confuse everyone', 'green': 'go','red': 'smile for the camera', 'yellow': 'go faster'}
若想避免这种情况,可以使用 copy() 将字典复制到一个新的字典中:
>>> signals = {'green': 'go', 'yellow': 'go faster', 'red': 'smile for the camera'}>>> original_signals = signals.copy()>>> signals['blue'] = 'confuse everyone'>>> signals{'blue': 'confuse everyone', 'green': 'go','red': 'smile for the camera', 'yellow': 'go faster'}>>> original_signals{'green': 'go', 'red': 'smile for the camera', 'yellow': 'go faster'}
3.5 集合
集合就像舍弃了值,仅剩下键的字典一样。键与键之间也不允许重复。如果你仅仅想知道某一个元素是否存在而不关心其他的,使用集合是个非常好的选择。如果需要为键附加其他信息的话,建议使用字典。
很久以前,当你还在小学时,可能就学到过一些关于集合论的知识。当然,如果你的学校恰好跳过了这一部分内容(或者实际上教了,但你当时正好盯着窗外发呆,我小时候就总是这样开小差),可以仔细看看图 3-1,它展示了我们对于集合进行的最基本的操作——交和并。
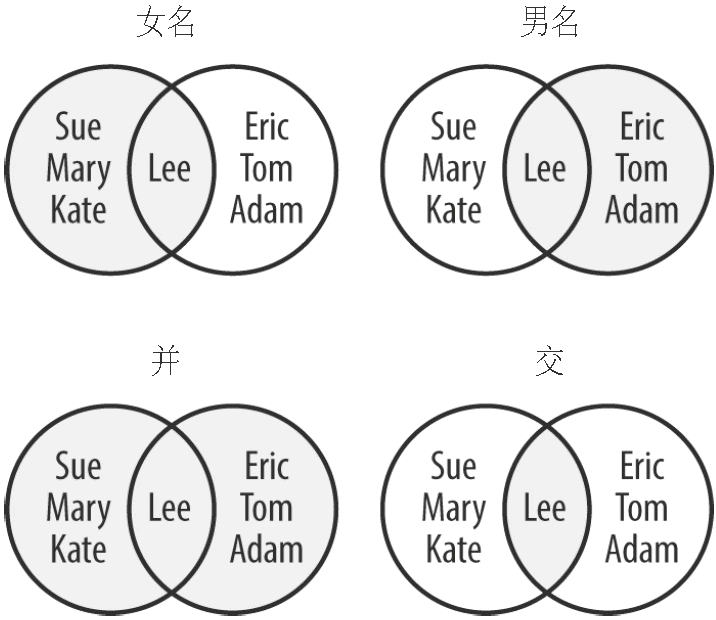
图 3-1:集合的常见操作
假如你将两个包含相同键的集合进行并操作,由于集合中的元素只能出现一次,因此得到的并集将包含两个集合所有的键,但每个键仅出现一次。空或空集指的是包含零个元素的集合。在图 3-1 中,名字以 X 开头的女性组成的集合就是一个空集。
3.5.1 使用set()创建集合
你可以使用 set() 函数创建一个集合,或者用大括号将一系列以逗号隔开的值包裹起来,如下所示:
>>> empty_set = set()>>> empty_setset()>>> even_numbers = {0, 2, 4, 6, 8}>>> even_numbers{0, 8, 2, 4, 6}>>> odd_numbers = {1, 3, 5, 7, 9}>>> odd_numbers{9, 3, 1, 5, 7}
与字典的键一样,集合是无序的。
[]能创建一个空列表,你可能期望{}也能创建空集。但事实上,{}会创建一个空字典,这也是为什么交互式解释器把空集输出为set()而不是{}。为何如此?没有什么特殊原因,仅仅是因为字典出现的比较早并抢先占据了花括号。
3.5.2 使用set()将其他类型转换为集合
你可以利用已有列表、字符串、元组或字典的内容来创建集合,其中重复的值会被丢弃。
首先来试着转换一个包含重复字母的字符串:
>>> set( 'letters' ){'l', 'e', 't', 'r', 's'}
注意,上面得到的集合中仅含有一个 'e' 和一个 't',尽管字符串 'letters' 里各自包含两个。
再试试用列表建立集合:
>>> set( ['Dasher', 'Dancer', 'Prancer', 'Mason-Dixon'] ){'Dancer', 'Dasher', 'Prancer', 'Mason-Dixon'}
再试试元组:
>>> set( ('Ummagumma', 'Echoes', 'Atom Heart Mother') ){'Ummagumma', 'Atom Heart Mother', 'Echoes'}
当字典作为参数传入 set() 函数时,只有键会被使用:
>>> set( {'apple': 'red', 'orange': 'orange', 'cherry': 'red'} ){'apple', 'cherry', 'orange'}
3.5.3 使用in测试值是否存在
这是集合里最常用的功能。我们来建立一个叫 drinks 的字典。每个键都是一种混合饮料的名字,与之对应的值是配料组成的集合:
>>> drinks = {... 'martini': {'vodka', 'vermouth'},... 'black russian': {'vodka', 'kahlua'},... 'white russian': {'cream', 'kahlua', 'vodka'},... 'manhattan': {'rye', 'vermouth', 'bitters'},... 'screwdriver': {'orange juice', 'vodka'}... }
尽管都由花括号({ 和 })包裹,集合仅仅是一系列值组成的序列,而字典是一个或多个键值对组成的序列。
哪种饮料含有伏特加?(注意,后面例子中我会提前使用一点下一章出现的 for、if、and 以及 or 语句。)
>>> for name, contents in drinks.items():... if 'vodka' in contents:... print(name)...screwdrivermartiniblack russianwhite russian
我想挑的饮料需要有伏特加,但不含乳糖。此外,我很讨厌苦艾酒,觉得它尝起来就像煤油一样:
>>> for name, contents in drinks.items():... if 'vodka' in contents and not ('vermouth' in contents or... 'cream' in contents):... print(name)...screwdriverblack russian
后面的内容会将上面的代码改写得更加简洁。
3.5.4 合并及运算符
如果想要查看多个集合之间组合的结果应该怎么办?例如,你想要找到一种饮料,它含有果汁或含有苦艾酒。我们可以使用交集运算符,记作 &:
>>> for name, contents in drinks.items():... if contents & {'vermouth', 'orange juice'}:... print(name)...screwdrivermartinimanhattan
& 运算符的结果是一个集合,它包含所有同时出现在你比较的两个清单中的元素。在上面代码中,如果 contents 里面不包含任何一种指定成分,则 & 会返回一个空集,相当于 False。
现在来改写一下上一小节的例子,就是那个我们想要伏特加但不需要乳脂也不需要苦艾酒的例子:
>>> for name, contents in drinks.items():... if 'vodka' in contents and not contents & {'vermouth', 'cream'}:... print(name)...screwdriverblack russian
将这两种饮料的原料都存储到变量中,以便于后面的例子不用再重复输入:
>>> bruss = drinks['black russian']>>> wruss = drinks['white russian']
之后的例子会涵盖所有的集合运算符。有些运算使用特殊定义过的标点,另一些则使用函数,还有一些运算两者都可使用。这里使用测试集合 a(包含 1 和 2),以及 b(包含 2 和 3):
>>> a = {1, 2}>>> b = {2, 3}
可以通过使用特殊标点符号 & 或者集合函数 intersection() 获取集合的交集(两集合共有元素),如下所示:
>>> a & b{2}>>> a.intersection(b){2}
下面的代码片段使用了我们之前存储的饮料变量:
>>> bruss & wruss{'kahlua', 'vodka'}
下面的例子中,使用 | 或者 union() 函数来获取集合的并集(至少出现在一个集合中的元素):
>>> a | b{1, 2, 3}>>> a.union(b){1, 2, 3}
还有酒精饮料的例子:
>>> bruss | wruss{'cream', 'kahlua', 'vodka'}
使用字符 - 或者 difference() 可以获得两个集合的差集(出现在第一个集合但不出现在第二个集合):
>>> a - b{1}>>> a.difference(b){1}>>> bruss - wrussset()>>> wruss - bruss{'cream'}
到目前为止,出现的都是最常见的集合运算,包括交、并、差。出于完整性的考虑,我会在接下来的例子中列出其他的运算符,这些运算符并不常用。
使用 ^ 或者 symmetric_difference() 可以获得两个集合的异或集(仅在两个集合中出现一次):
>>> a ^ b{1, 3}>>> a.symmetric_difference(b){1, 3}
下面的代码帮我们找到了两种俄罗斯饮料的不同成分:
>>> bruss ^ wruss{'cream'}
使用 <= 或者 issubset() 可以判断一个集合是否是另一个集合的子集(第一个集合的所有元素都出现在第二个集合中):
>>> a <= bFalse>>> a.issubset(b)False
向“黑俄罗斯酒”中加入一些乳脂就变成了“白俄罗斯酒”,因此 wruss 是 bruss 的超集:
>>> bruss <= wrussTrue
一个集合是它本身的子集吗?答案为:是的。
>>> a <= aTrue>>> a.issubset(a)True
当第二个集合包含所有第一个集合的元素,且仍包含其他元素时,我们称第一个集合为第二个集合的真子集。使用 < 可以进行判断:
>>> a < bFalse>>> a < aFalse>>> bruss < wrussTrue
超集与子集正好相反(第二个集合的所有元素都出现在第一个集合中),使用 >= 或者 issuperset() 可以进行判断:
>>> a >= bFalse>>> a.issuperset(b)False>>> wruss >= brussTrue
一个集合是它本身的超集:
>>> a >= aTrue>>> a.issuperset(a)True
最后,使用 > 可以找到一个集合的真超集(第一个集合包含第二个集合的所有元素且还包含其他元素):
>>> a > bFalse>>> wruss > brussTrue
一个集合并不是它本身的真超集:
>>> a > aFalse
3.6 比较几种数据结构
回顾一下,我们学会了使用方括号([])创建列表,使用逗号创建元组,使用花括号({})创建字典。在每一种类型中,都可以通过方括号对单个元素进行访问:
>>> marx_list = ['Groucho', 'Chico', 'Harpo']>>> marx_tuple = 'Groucho', 'Chico', 'Harpo'>>> marx_dict = {'Groucho': 'banjo', 'Chico': 'piano', 'Harpo': 'harp'}>>> marx_list[2]'Harpo'>>> marx_tuple[2]'Harpo'>>> marx_dict['Harpo']'harp'
对于列表和元组来说,方括号里的内容是整型的偏移量;而对于字典来说,方括号里的是键。它们返回的都是元素的值。
3.7 建立大型数据结构
我们从最简单的布尔型、数字、字符串型开始学习,到目前为止,学习到了列表、元组、集合以及字典等数据结构。你可以将这些内置的数据结构自由地组合成更大、更复杂的结构。试着从建立三个不同的列表开始:
>>> marxes = ['Groucho', 'Chico', 'Harpo']>>> pythons = ['Chapman', 'Cleese', 'Gilliam', 'Jones', 'Palin']>>> stooges = ['Moe', 'Curly', 'Larry']
可以把上面每一个列表当作一个元素,并建立一个元组:
>>> tuple_of_lists = marxes, pythons, stooges>>> tuple_of_lists(['Groucho', 'Chico', 'Harpo'],['Chapman', 'Cleese', 'Gilliam', 'Jones', 'Palin'],['Moe', 'Curly', 'Larry'])
同样,可以创建一个包含上面三个列表的列表:
>>> list_of_lists = [marxes, pythons, stooges]>>> list_of_lists[['Groucho', 'Chico', 'Harpo'],['Chapman', 'Cleese', 'Gilliam', 'Jones', 'Palin'],['Moe', 'Curly', 'Larry']]
还可以创建以这三个列表为值的字典。本例中,使用这些喜剧演员组合的名字作为键,成员列表作为值:
>>> dict_of_lists = {'Marxes': marxes, 'Pythons': pythons, 'Stooges': stooges}>> dict_of_lists{'Stooges': ['Moe', 'Curly', 'Larry'],'Marxes': ['Groucho', 'Chico', 'Harpo'],'Pythons': ['Chapman', 'Cleese', 'Gilliam', 'Jones', 'Palin']}
在创建自定义数据结构的过程中,唯一的限制来自于这些内置数据类型本身。比如,字典的键必须为不可变对象,因此列表、字典以及集合都不能作为字典的键,但元组可以作为字典的键。举个例子,我们可以通过 GPS 坐标(纬度,经度,海拔;B.6 节可以看到更多与地图有关的例子)定位感兴趣的位置:
>>> houses = {(44.79, -93.14, 285): 'My House',(38.89, -77.03, 13): 'The White House'}
3.8 练习
在这一章,你见到了一些更为复杂的数据结构:列表、元组、字典和集合。你可以使用这些数据结构以及第 2 章提到的数据类型(数字和字符串)来表示现实生活中各种各样的元素。
(1) 创建一个叫作 years_list 的列表,存储从你出生的那一年到五岁那一年的年份。例如,如果你是 1980 年出生的,那么你的列表应该是 years_list = [1980, 1981, 1982, 1983, 1984, 1985]。
如果你现在还没到五岁却在阅读本书,那我真的没有什么可教你的了。
(2) 在 years_list 中,哪一年是你三岁生日那年?别忘了,你出生的第一年算 0 岁。
(3) 在 years_list 中,哪一年你的年纪最大?
(4) 创 建 一 个 名 为 things 的 列 表, 包 含 以 下 三 个 元 素:"mozzarella"、"cinderella" 和 "salmonella"。
(5) 将 things 中代表人名的字符串变成首字母大写形式,并打印整个列表。看看列表中的元素改变了吗?
(6) 将 things 中代表奶酪的元素全部改成大写,并打印整个列表。
(7) 将代表疾病的元素从 things 中删除,收好你得到的诺贝尔奖,并打印列表。
(8) 创建一个名为 surprise 的列表,包含以下三个元素:"Groucho"、"Chico" 和 "Harpo"。
(9) 将 surprise 列表的最后一个元素变成小写,翻转过来,再将首字母变成大写。
(10) 创建一个名为 e2f 的英法字典并打印出来。这里提供一些单词对:dog 是 chien,cat 是 chat,walrus 是 morse。
(11) 使用你的仅包含三个词的字典 e2f 查询并打印出 walrus 对应的的法语词。
(12) 利用 e2f 创建一个名为 f2e 的法英字典。注意要使用 items 方法。
(13) 使用 f2e,查询并打印法语词 chien 对应的英文词。
(14) 创建并打印由 e2f 的键组成的英语单词集合。
(15) 建立一个名为 life 的多级字典。将下面这些字符串作为顶级键:'animals'、'plants' 以及 'others'。令 'animals' 键指向另一个字典,这个字典包含键 'cats'、'octopi' 以及 'emus'。令 'cat' 键指向一个字符串列表,这个列表包括 'Henri'、'Grumpy' 和 'Lucy'。让其余的键都指向空字典。
(16) 打印 life 的顶级键。
(17) 打印 life['animals'] 的全部键。
(18) 打印 life['animals']['cats'] 的值。
