第 7 章 像高手一样玩转数据
本章将学到许多操作数据的方法,它们大多与下面这两种内置的 Python 数据类型有关。
- 字符串
Unicode 字符组成的序列,用于存储文本数据。
- 字节和字节数组
8 比特整数组成的序列,用于存储二进制数据。
7.1 文本字符串
对大多数读者来说,文本应该是最熟悉的数据类型了,因此我们从文本入手,首先介绍一些 Python 中有关字符串操作的强大特性。
7.1.1 Unicode
到目前为止,书中例子使用的都是用原始 ASCII 编码的字符串。ASCII 诞生于 20 世纪 60 年代,那时的计算机还和冰箱差不多大,运算速度也仅仅比人力稍快一些。众所周知,计算机的基本存储单元是字节(byte),它包含 8 位 / 比特(bit),可以存储 256 种不同的值。出于一些设计目的,ASCII 只使用了 7 位(128 种取值):26 个大写字母、26 个小写字母、10 个阿拉伯数字、一些标点符号、空白符以及一些不可打印的控制符。
不幸的是,世界上现存的字符远远超过了 ASCII 所能支持的 128 个。设想在一个只有 ASCII 字符的世界中,你可以在小餐馆点个热狗,但永远不能在咖啡厅点 Gewürztraminer 酒 1。为了支持更多的字母及符号,人们已经做出了许多努力,其中有些成果你可能见到过。例如下面这两个:
1这个词在德语中原本含有曲音符,但传到法国时就丢失了。
Latin-1 或 ISO 8859-1
Windows code page 1252
上面这些编码规则使用全 8 比特(ASCII 只使用了 7 比特)进行编码,但这明显不够用,尤其是当你需要表示非印欧语系的语言符号时。Unicode 编码是一种正在发展中的国际化规范,它可以包含世界上所有语言以及来自数学领域和其他领域的各种符号。
Unicode 为每个字符赋予了一个特殊的数字编码,这些编码与具体平台、程序、语言均无关。
—— Unicode 协会
Unicode Code Charts 页面(http://www.unicode.org/charts/)包含了通往目前已定义的所有字符集的链接,且包含字符图示。最新的版本(6.2)定义了超过 110 000 种字符,每一种都有自己独特的名字和标识数。这些字符被分成了若干个 8 比特的集合,我们称之为平面(plane)。前 256 个平面为基本多语言平面(basic multilingual plane)。你可以在维基百科中查看更多关于 Unicode 平面的信息(http://en.wikipedia.org/wiki/Plane_(Unicode))。
1. Python 3中的Unicode字符串
Python 3 中的字符串是 Unicode 字符串而不是字节数组。这是与 Python 2 相比最大的差别。在 Python 2 中,我们需要区分普通的以字节为单位的字符串以及 Unicode 字符串。
如果你知道某个字符的 Unicode ID,可以直接在 Python 字符串中引用这个 ID 获得对应字符。下面是几个例子。
用
\u及 4 个十六进制的数字 2 可以从 Unicode 256 个基本多语言平面中指定某一特定字符。其中,前两个十六进制数字用于指定平面号(00到FF),后面两个数字用于指定该字符位于平面中的位置索引。00号平面即为原始的 ASCII 字符集,字符在该平面的位置索引与它的 ASCII 编码一致。我们需要使用更多的比特位来存储那些位于更高平面的字符。Python 为此而设计的转义序列以
\U开头,后面紧跟着 8 个十六进制的数字,其中最左一位需为0。你也可以通过
\N{name}来引用某一字符,其中name为该字符的标准名称,这对所有平面的字符均适用。在 Unicode 字符名称索引页(http://www.unicode.org/charts/charindex.html)可以查到字符对应的标准名称。
20~9、A~F,共 16 个字符。
Python 中的 unicodedata 模块提供了下面两个方向的转换函数:
lookup()——接受不区分大小写的标准名称,返回一个 Unicode 字符;name()——接受一个 Unicode 字符,返回大写形式的名称。
下面的例子中,我们将编写一个测试函数,它接受一个 Python Unicode 字符,查找它对应的名称,再用这个名称查找对应的 Unicode 字符(它应该与原始字符相同):
>>> def unicode_test(value):... import unicodedata... name = unicodedata.name(value)... value2 = unicodedata.lookup(name)... print('value="%s", name="%s", value2="%s"' % (value, name, value2))...
用一些字符来测试一下吧。首先试一下纯 ASCII 字符:
>>> unicode_test('A')value="A", name="LATIN CAPITAL LETTER A", value2="A"
ASCII 标点符号:
>>> unicode_test('$')value="$", name="DOLLAR SIGN", value2="$"
Unicode 货币字符:
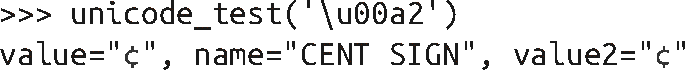
另一个 Unicode 货币字符:
>>> unicode_test('\u20ac')value="€", name="EURO SIGN", value2="€"
这些例子唯一可能遇到的问题来源于使用的字体自身的限制。没有任何一种字体涵盖了所有 Unicode 字符,当缺失对应字符的图片时,会以占位符的形式显示。例如下面是尝试打印 SNOWMAN 字符得到的结果,这里使用的是 dingbat 字体:
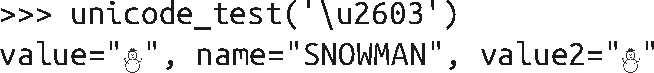
假设想在 Python 字符串中存储 café 这个词。一种方式是从其他文件或者网站中复制粘贴出来,但这并不一定成功,只能祈祷一切正常:
>>> place = 'café'>>> place'café'
示例中之所以成功是因为我是从以 UTF-8 编码(马上你就会了解)的文本源复制粘贴过来的。
有没有什么办法能够直接指定末尾的 é 字符呢?如果你查看了 E 索引(http://www.unicode.org/charts/charindex.html#E)下的字符会发现,我们所需字符 E WITH ACUTE, LATIN SMALL LETTER 对应的 Unicode 值为 00E9。我们用刚刚的 name() 函数和 lookup() 函数来检测一下,首先用编码值查询字符名称:
>>> unicodedata.name('\u00e9')'LATIN SMALL LETTER E WITH ACUTE'
接着,通过名称查询对应的编码值:
>>> unicodedata.lookup('E WITH ACUTE, LATIN SMALL LETTER')Traceback (most recent call last):File "<stdin>", line 1, in <module>KeyError: "undefined character name 'E WITH ACUTE, LATIN SMALL LETTER'"
为了方便查阅,Unicode 字符名称索引页列出的字符名称是经过修改的,因此与由
name()函数得到的名称有所不同。如果需要将它们转化为真实的 Unicode 名称(Python 使用的),只需将逗号舍去,并将逗号后面的内容移到最前面即可。据此,我们应将E WITH ACUTE, LATIN SMALL LETTER改为LATIN SMALL LETTER E WITH ACUTE:
>>> unicodedata.lookup('LATIN SMALL LETTER E WITH ACUTE')'é'
现在,可以通过字符名称或者编码值来指定 café 这个词了:
>>> place = 'caf\u00e9'>>> place'café'>>> place = 'caf\N{LATIN SMALL LETTER E WITH ACUTE}'>>> place'café'
上面的代码中,我们将 é 直接插入了字符串中。也可以使用拼接来构造字符串:
>>> u_umlaut = '\N{LATIN SMALL LETTER U WITH DIAERESIS}'>>> u_umlaut'ü'>>> drink = 'Gew' + u_umlaut + 'rztraminer'>>> print('Now I can finally have my', drink, 'in a', place)Now I can finally have my Gewürztraminer in a café
字符串函数 len 可以计算字符串中 Unicode 字符的个数,而不是字节数:
>>> len('$')1>>> len('\U0001f47b')1
2. 使用UTF-8编码和解码
对字符串进行处理时,并不需要在意 Python 中 Unicode 字符的存储细节。
但当需要与外界进行数据交互时则需要完成两件事情:
将字符串编码为字节;
将字节解码为字符串。
如果 Unicode 包含的字符种类不超过 64 000 种,我们就可以将字符 ID 统一存储在 2 字节中。遗憾的是,Unicode 所包含的字符种类远不止于此。诚然,我们可以将字符 ID 统一编码在 3 或 4 字节中,但这会使空间开销(内存和硬盘)增加 3 到 4 倍。
两位为 Unix 开发者所熟知的大神 Ken Thompson 和 Rob Pike 在新泽西共用晚餐时解决了这个问题,他们在餐桌垫上设计出了 UTF-8 动态编码方案。这种方案会动态地为每一个 Unicode 字符分配 1 到 4 字节不等:
为 ASCII 字符分配 1 字节;
为拉丁语系(除西里尔语)的语言分配 2 字节;
为其他的位于基本多语言平面的字符分配 3 字节;
为剩下的字符集分配 4 字节,这包括一些亚洲语言及符号。
UTF-8 是 Python、Linux 以及 HTML 的标准文本编码格式。这种编码方式简单快速、字符覆盖面广、出错率低。在代码中全都使用 UTF-8 编码会是一种非常棒的体验,你再也不需要不停地转化各种编码格式。
3. 编码
编码是将字符串转化为一系列字节的过程。字符串的 encode() 函数所接收的第一个参数是编码方式名。可选的编码方式列在了表 7-1 中。
表7-1:编码方式
| 编码 | 说明 |
|---|---|
'ascii'
| 经典的 7 比特 ASCII 编码 |
'utf-8'
| 最常用的以 8 比特为单位的变长编码 |
'latin-1'
| 也被称为 ISO 8859-1 编码 |
'cp-1252'
| Windows 常用编码 |
'unicode-escape'
|
Python 中 Unicode 的转义文本格式,\uxxxx 或者 \Uxxxxxxxx
|
你可以将任何 Unicode 数据以 UTF-8 的方式进行编码。我们试着将 Unicode 字符串 '\u2603' 赋值给 snowman:
>>> snowman = '\u2603'
snowman 是一个仅包含一个字符的 Unicode 字符串,这与它存储所需的字节数没有任何关系:
>>> len(snowman)1
下一步将这个 Unicode 字符编码为字节序列:
>>> ds = snowman.encode('utf-8')
就像我之前提到的,UTF-8 是一种变长编码方式。在这个例子中,单个 Unicode 字符 snowman 占用了 3 字节的空间:
>>> len(ds)3>>> dsb'\xe2\x98\x83'
现在,len() 返回了字节数(3),因为 ds 是一个 bytes 类型的变量。
当然,你也可以使用 UTF-8 以外的编码方式,但该 Unicode 字符串有可能无法被指定的编码方式处理,此时 Python 会抛出异常。例如,如果你想要使用 ascii 方式进行编码,必须保证待编码的字符串仅包含 ASCII 字符集里的字符,不含有任何其他的 Unicode 字符,否则会出现错误:
>>> ds = snowman.encode('ascii')Traceback (most recent call last):File "<stdin>", line 1, in <module>UnicodeEncodeError: 'ascii' codec can't encode character '\u2603'in position 0: ordinal not in range(128)
encode() 函数可以接受额外的第二个参数来帮助你避免编码异常。它的默认值是 'strict',如上例所示,当函数检测到需要处理的字符串包含非 ASCII 字符时,会抛出 UnicodeEncodeError 异常。当然,该参数还有别的可选值,例如 'ignore' 会抛弃任何无法 进行编码的字符:
>>> snowman.encode('ascii', 'ignore')b''
'replace' 会将所有无法进行编码的字符替换为 ?:
>>> snowman.encode('ascii', 'replace')b'?'
'backslashreplace' 则会创建一个和 unicode-escape 类似的 Unicode 字符串:
>>> snowman.encode('ascii', 'backslashreplace')b'\\u2603'
如果你需要一份 Unicode 转义符序列的可打印版本,可以考虑使用上面这种方式。
下面的代码可以用于创建网页中使用的字符实体串:
>>> snowman.encode('ascii', 'xmlcharrefreplace')b'☃'
4. 解码
解码是将字节序列转化为 Unicode 字符串的过程。我们从外界文本源(文件、数据库、网站、网络 API 等)获得的所有文本都是经过编码的字节串。重要的是需要知道它是以何种方式编码的,这样才能逆转编码过程以获得 Unicode 字符串。
问题是字节串本身不带有任何指明编码方式的信息。之前我也提到过从网站随意复制粘贴文本的风险,你也可能遇到过网页乱码的情况,本应是 ASCII 字符的位置却被奇怪的字符占据了,这些都是编码和解码的方式不一致导致的。
创建一个 place 字符串,赋值为 'café':
>>> place = 'caf\u00e9'>>> place'café'>>> type(place)<class 'str'>
将它以 UTF-8 格式编码为 bytes 型变量,命名为 place_bytes:
>>> place_bytes = place.encode('utf-8')>>> place_bytesb'caf\xc3\xa9'>>> type(place_bytes)<class 'bytes'>
注意,place_bytes 包含 5 个字节。前 3 个字节的内容与 ASCII 一样(UTF-8 的强大之处),最后两个字节用于编码 'é'。现在,将字节串转换回 Unicode 字符串:
>>> place2 = place_bytes.decode('utf-8')>>> place2'café'
一切正常,这是因为编码和解码使用的都是 UTF-8 格式。如果使用其他格式进行解码会发生什么?
>>> place3 = place_bytes.decode('ascii')Traceback (most recent call last):File "<stdin>", line 1, in <module>UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3:ordinal not in range(128)
ASCII 解码器会抛出异常,因为字节值 0xc3 在 ASCII 编码中是非法值。对于另一些使用 8 比特编码的方式而言,位于 128(十六进制 80)到 255(十六进制 FF)之间的 8 比特的字符集可能是合法的,但解码得到的结果显然与 UTF-8 不同:
>>> place4 = place_bytes.decode('latin-1')>>> place4'café'>>> place5 = place_bytes.decode('windows-1252')>>> place5'café'
这个故事告诉我们:尽可能统一使用 UTF-8 编码。况且它出错率低,兼容性好,可以表达所有的 Unicode 字符,编码和解码的速度又快,这么多优点,何乐而不为?
5. 更多内容
如果想要了解更多关于 Unicode 的细节,下面这些链接对你可能会有所帮助:
Unicode HOWTO(https://docs.python.org/3/howto/unicode.html)
Pragmatic Unicode(http://nedbatchelder.com/text/unipain.html)
The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)(http://www.joelonsoftware.com/articles/Unicode.html)
7.1.2 格式化
之前几乎都没有提到过文本格式化的问题,现在有必要关注一下这方面的内容了。第 2 章曾经用过一些字符串排版函数,那些示例代码要么简单地使用 print() 语句,要么直接在交互式解释器显示。现在是时候看看如何使用不同的格式化方法将变量插值(interpolate)到字符串中了,即将变量的值嵌入字符串中。你可以用这种方法来生成那些格式框架看起来一样的报告或者其他固定格式的输出。
Python 有两种格式化字符串的方式,我们习惯简单地称之为旧式(old style)和新式(new style)。这两种方式在 Python 2 和 Python 3 中都适用(新式格式化方法适用于 Python 2.6 及以上)。旧式格式化相对简单些,因此我们从它开始。
1. 使用%的旧式格式化
旧式格式化的形式为 string % data。其中 string 包含的是待插值的序列。表 7-2 展示了最简单的插值序列,它仅由 % 以及一个用于指定数据类型的字母组成。
表7-2:转换类型
%s | 字符串 |
%d | 十进制整数 |
%x | 十六进制整数 |
%o | 八进制整数 |
%f | 十进制浮点数 |
%e | 以科学计数法表示的浮点数 |
%g | 十进制或科学计数法表示的浮点数 |
%% | 文本值 % 本身 |
下面是一些简单的例子。首先格式化一个整数:
>>> '%s' % 42'42'>>> '%d' % 42'42'>>> '%x' % 42'2a'>>> '%o' % 42'52'
接着是浮点数:
>>> '%s' % 7.03'7.03'>>> '%f' % 7.03'7.030000'>>> '%e' % 7.03'7.030000e+00'>>> '%g' % 7.03'7.03'
整数和字面值 %:
>>> '%d%%' % 100'100%'
下面是一些关于字符串和整数的插值操作:
>>> actor = 'Richard Gere'>>> cat = 'Chester'>>> weight = 28>>> "My wife's favorite actor is %s" % actor"My wife's favorite actor is Richard Gere">>> "Our cat %s weighs %s pounds" % (cat, weight)'Our cat Chester weighs 28 pounds'
字符串内的 %s 意味着需要插入一个字符串。字符串中出现 % 的次数需要与 % 之后所提供的数据项个数相同。如果只需插入一个数据,例如前面的 actor,直接将需要插入的数据置于 % 后即可。如果需要插入多个数据,则需要将它们封装进一个元组(以圆括号为界,逗号分开),例如上例中的 (cat, weight)。
尽管 weight 是一个整数,格式化串中的 %s 也会将它转化为字符串型。
你可以在 % 和指定类型的字母之间设定最大和最小宽度、排版以及填充字符,等等。
我们来定义一个整数 n、一个浮点数 f 以及一个字符串 s:
>>> n = 42>>> f = 7.03>>> s = 'string cheese'
使用默认宽度格式化它们:
>>> '%d %f %s' % (n, f, s)'42 7.030000 string cheese'
为每个变量设定最小域宽为 10 个字符,右对齐,左侧不够用空格填充:
>>> '%10d %10f %10s' % (n, f, s)' 42 7.030000 string cheese'
和上面的例子使用同样的域宽,但改成左对齐:
>>> '%-10d %-10f %-10s' % (n, f, s)'42 7.030000 string cheese'
这次仍然使用之前的域宽,但是设定最大字符宽度为 4,右对齐。这样的设置会截断超过长度限制的字符串,并且将浮点数的精度限制在小数点后 4 位:
>>> '%10.4d %10.4f %10.4s' % (n, f, s)' 0042 7.0300 stri'
去掉最小域宽为 10 的限制:
>>> '%.4d %.4f %.4s' % (n, f, s)'0042 7.0300 stri'
最后,改变一下上面例子的硬编码方式,将域宽、字符宽度等设定作为参数:
>>> '%*.*d %*.*f %*.*s' % (10, 4, n, 10, 4, f, 10, 4, s)' 0042 7.0300 stri'
2. 使用{}和format的新式格式化
旧式格式化方式现在仍然兼容。Python 2(将永远停止在 2.7 版本)会永远提供对旧式格式化的支持。然而,如果你在使用 Python 3,新式格式化更值得推荐。
新式格式化最简单的用法如下所示:
>>> '{} {} {}'.format(n, f, s)'42 7.03 string cheese'
旧式格式化中传入参数的顺序需要与 % 占位符出现的顺序完全一致,但在新式格式化里,可以自己指定插入的顺序:
>>> '{2} {0} {1}'.format(f, s, n)'42 7.03 string cheese'
0 代表第一个参数 f;1 代表字符串 s;2 代表最后一个参数,整数 n。
参数可以是字典或者命名变量,格式串中的标识符可以引用这些名称:
>>> '{n} {f} {s}'.format(n=42, f=7.03, s='string cheese')'42 7.03 string cheese'
下面的例子中,我们试着将之前作为参数的 3 个值存到一个字典中,如下所示:
>>> d = {'n': 42, 'f': 7.03, 's': 'string cheese'}
下面的例子中,{0} 代表整个字典,{1} 则代表字典后面的字符串 'other':
>>> '{0[n]} {0[f]} {0[s]} {1}'.format(d, 'other')'42 7.03 string cheese other'
上面这些例子都是以默认格式打印结果的。旧式格式化允许在 % 后指定参数格式,但在新式格式化里,将这些格式标识符放在 : 后。首先使用位置参数的例子:
>>> '{0:d} {1:f} {2:s}'.format(n, f, s)'42 7.030000 string cheese'
接着使用相同的值,但这次它们作为命名参数:
>>> '{n:d} {f:f} {s:s}'.format(n=42, f=7.03, s='string cheese')'42 7.030000 string cheese'
新式格式化也支持其他各类设置(最小域宽、最大字符宽、排版,等等)。
下面是一个最小域宽设为 10、右对齐(默认)的例子:
>>> '{0:10d} {1:10f} {2:10s}'.format(n, f, s)' 42 7.030000 string cheese'
与上面例子一样,但使用 > 字符设定右对齐显然要更为直观:
>>> '{0:>10d} {1:>10f} {2:>10s}'.format(n, f, s)' 42 7.030000 string cheese'
最小域宽为 10,左对齐:
>>> '{0:<10d} {1:<10f} {2:<10s}'.format(n, f, s)'42 7.030000 string cheese'
最小域宽为 10,居中:
>>> '{0:^10d} {1:^10f} {2:^10s}'.format(n, f, s)' 42 7.030000 string cheese'
新式格式化与旧式格式化相比有一处明显的不同:精度(precision,小数点后面的数字)对于浮点数而言仍然代表着小数点后的数字个数,对于字符串而言则代表着最大字符个数,但在新式格式化中你无法对整数设定精度:
>>> '{0:>10.4d} {1:>10.4f} {2:10.4s}'.format(n, f, s)Traceback (most recent call last):File "<stdin>", line 1, in <module>ValueError: Precision not allowed in integer format specifier>>> '{0:>10d} {1:>10.4f} {2:>10.4s}'.format(n, f, s)' 42 7.0300 stri'
最后一个可设定的值是填充字符。如果想要使用空格以外的字符进行填充,只需把它放在 : 之后,其余任何排版符(<、>、^)和宽度标识符之前即可:
>>> '{0:!^20s}'.format('BIG SALE')'!!!!!!BIG SALE!!!!!!'
7.1.3 使用正则表达式匹配
第 2 章接触到一些简单的字符串操作。有了这些知识,你可能已经会在命令行里使用一些简单的“通配符”模式了,例如 ls*.py,这条命令的意思是“列出当前目录下所有以 .py 结尾的文件名”。
是时候使用正则表达式(regular expression)探索一些复杂模式匹配的方法了。与之相关的功能都位于标准库模块 re 中,因此首先需要引用它。你需要定义一个用于匹配的模式(pattern)字符串以及一个匹配的对象:源(source)字符串。简单的匹配,如下所示:
result = re.match('You', 'Young Frankenstein')
这里,'You' 是模式,'Young Frankenstein' 是源——你想要检查的字符串。match() 函数用于查看源是否以模式开头。
对于更加复杂的匹配,可以先对模式进行编译以加快匹配速度:
youpattern = re.compile('You')
然后就可以直接使用编译好的模式进行匹配了:
result = youpattern.match('Young Frankenstein')
match() 并不是比较 source 和 pattern 的唯一方法。下面列出了另外一些可用的方法:
search()会返回第一次成功匹配,如果存在的话;findall()会返回所有不重叠的匹配,如果存在的话;split()会根据 pattern 将 source 切分成若干段,返回由这些片段组成的列表;sub()还需一个额外的参数 replacement,它会把 source 中所有匹配的 pattern 改成 replacement。
1. 使用match()进行准确匹配
字符串 'Young Frankenstein' 是以单词 'You' 开头的吗?以下是一些带注释的代码:
>>> import re>>> source = 'Young Frankenstein'>>> m = re.match('You', source) # 从源字符串的开头开始匹配>>> if m: # 匹配成功返回了对象,将它输出看看匹配得到的是什么... print(m.group())...You>>> m = re.match('^You', source) # 起始锚点也能起到同样作用>>> if m:... print(m.group())...You
尝试匹配 'Frank' 又会如何?
>>> m = re.match('Frank', source)>>> if m:... print(m.group())...
这一次,match() 什么也没有返回,if 也没有执行内部的 print 语句。如前所述,match() 只能检测以模式串作为开头的源字符串。但是 search() 可以检测任何位置的匹配:
>>> m = re.search('Frank', source)>>> if m:... print(m.group())...Frank
改变一下匹配的模式:
>>> m = re.match('.*Frank', source)>>> if m: # match返回对象... print(m.group())...Young Frank
以下是对新模式能够匹配成功的简单解释:
.代表任何单一字符;*代表任意一个它之前的字符,.*代表任意多个字符(包括 0 个);Frank是我们想要在源字符串中某处进行匹配的短语。
match() 返回了匹配 .*Frank 的字符串:'Young Frank'。
2. 使用 search() 寻找首次匹配
你可以使用 search() 在源字符串 'Young Frankenstein' 的任意位置寻找模式 'Frank',无需通配符 .*:
>>> m = re.search('Frank', source)>>> if m: # search返回对象... print(m.group())...Frank
3. 使用 findall() 寻找所有匹配
之前的例子都是查找到一个匹配即停止。但如果想要知道一个字符串中出现了多少次字母 'n' 应该怎么办?
>>> m = re.findall('n', source)>>> m # findall返回了一个列表['n', 'n', 'n', 'n']>>> print('Found', len(m), 'matches')Found 4 matches
将模式改成 'n',紧跟着任意一个字符,结果又如何?
>>> m = re.findall('n.', source)>>> m['ng', 'nk', 'ns']
注意,上面例子中最后一个 'n' 并没有匹配成功,需要通过 ? 说明 'n' 后面的字符是可选的:
>>> m = re.findall('n.?', source)>>> m['ng', 'nk', 'ns', 'n']
4. 使用 split() 按匹配切分
下面的示例展示了如何依据模式而不是简单的字符串(就像普通的 split() 方法做的)将一个字符串切分成由一系列子串组成的列表:
>>> m = re.split('n', source)>>> m # split返回的列表['You', 'g Fra', 'ke', 'stei', '']
5. 使用 sub() 替换匹配
这和字符串 replace() 方法有些类似,只不过使用的是模式而不是文本串:
>>> m = re.sub('n', '?', source)>>> m # sub返回的字符串'You?g Fra?ke?stei?'
6. 模式:特殊的字符
许多书中关于正则表达式的描述都是从如何定义它开始的,我觉得这不太符合学习的逻辑。正则表达式不是一两句就能说清楚的小语言,它拥有大量的语言细节,会完全占据你的大脑让你无所适从。它使用的符号实在是太多了,看起来简直就像是幽灵画符一样!
有了上面介绍的方法(match()、search()、findall() 和 sub())做铺垫,现在可以从应用讲起并研究如何构造正则表达式了,即上述方法中的模式。
已经见过的一些基本模式:
普通的文本值代表自身,用于匹配非特殊字符;
使用
.代表任意除\n外的字符;使用
*表示任意多个字符(包括 0 个);使用
?表示可选字符(0 个或 1 个)。
接下来要介绍一些特殊字符,参见表 7-3。
表7-3:特殊字符
| 模式 | 匹配 |
|---|---|
\d
| 一个数字字符 |
\D
| 一个非数字字符 |
\w
| 一个字母或数字字符 |
\W
| 一个非字母非数字字符 |
\s
| 空白符 |
\S
| 非空白符 |
\b
|
单词边界(一个 \w 与\W 之间的范围,顺序可逆)
|
\B
| 非单词边界 |
Python 的 string 模块中预先定义了一些可供我们测试用的字符串常量。我们将使用其中的 printable 字符串,它包含 100 个可打印的 ASCII 字符,包括大小写字母、数字、空格符以及标点符号:
>>> import string>>> printable = string.printable>>> len(printable)100>>> printable[0:50]'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMN'>>> printable[50:]'OPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
printable 中哪些字符是数字?
>>> re.findall('\d', printable)['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
哪些字符是数字、字符或下划线?
>>> re.findall('\w', printable)['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b','c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n','o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z','A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L','M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '_']
哪些属于空格符?
>>> re.findall('\s', printable)[' ', '\t', '\n', '\r', '\x0b', '\x0c']
正则表达式不仅仅适用于 ASCII 字符,例如 \d 还可以匹配 Unicode 的数字字符,并不局限于 ASCII 中的 '0' 到 '9'。我们从 FileFormat.info(http://www.fileformat.info/info/unicode/category/Ll/list.htm)中引入两个新的非 ASCII 编码的小写字母。
这个测试例子中,在模式中添加以下内容:
三个 ASCII 字母
三个不会被
\w所匹配的标点符号Unicode 中的 LATIN SMALL LETTER E WITH CIRCUMFLEX(
\u00ea)Unicode 中的 LATIN SMALL LETTER E WITH BREVE(
\u0115)
>>> x = 'abc' + '-/*' + '\u00ea' + '\u0115'
与预期的一样,应用这个模式可以匹配出下面这些字母:
>>> re.findall('\w', x)['a', 'b', 'c', 'ê', 'ě']
7. 模式:使用标识符
现在试着用表 7-4 中所包含的一些常用的模式标识符来烹饪一道“符号比萨”大餐。
表中,expr 和其他斜体的单词表示合法的正则表达式。
表7-4:模式标识符
| 模式 | 匹配 |
|---|---|
abc
|
文本值abc
|
| (expr) | expr |
| expr 1 | expr 2 | expr 1 或 expr 2 |
.
|
除 \n 外的任何字符
|
^
| 源字符串的开头 |
$
| 源字符串的结尾 |
prev?
| 0 个或 1 个prev |
prev*
| 0 个或多个prev,尽可能多地匹配 |
prev*?
| 0 个或多个prev,尽可能少地匹配 |
prev+
| 1 个或多个prev,尽可能多地匹配 |
prev+?
| 1 个或多个prev,尽可能少地匹配 |
prev{m}
| m 个连续的prev |
prev{m, n}
| m 到 n 个连续的prev,尽可能多地匹配 |
prev{m, n}?
| m 到 n 个连续的prev,尽可能少地匹配 |
[abc]
|
a 或 b 或 c(和 a|b|c 一样)
|
[^abc]
|
非(a 或 b 或c)
|
prev (?=next)
| 如果后面为next,返回prev |
prev (?!next)
| 如果后面非next,返回prev |
(?<=prev) next
| 如果前面为prev,返回next |
(?prev) next
| 如果前面非prev,返回next |
在看下面的例子时,你可能需要时不时地查阅上面的表格。先来定义我们使用的源字符串:
>>> source = '''I wish I may, I wish I might... Have a dish of fish tonight.'''
首先,在源字符串中检索 wish:
>>> re.findall('wish', source)['wish', 'wish']
接着,对源字符串任意位置查询 wish 或者 fish:
>>> re.findall('wish|fish', source)['wish', 'wish', 'fish']
从字符串开头开始匹配 wish:
>>> re.findall('^wish', source)[]
从字符串开头开始匹配 I wish:
>>> re.findall('^I wish', source)['I wish']
从字符串结尾开始匹配 fish:
>>> re.findall('fish$', source)[]
最后,从字符串结尾开始匹配 fish tonight.:
>>> re.findall('fish tonight.$', source)['fish tonight.']
^ 和 $ 叫作锚点(anchor):^ 将搜索域定位到源字符串的开头,$ 则定位到末尾。上面例子中的 .$ 可以匹配末尾的任意字符,包括句号,因此能成功匹配。但更准确地说,上面的例子应该使用转义符将 . 转义为句号,这才是我们真正想示意的纯文本值匹配:
>>> re.findall('fish tonight\.$', source)['fish tonight.']
接下来查询以 w 或 f 开头,后面紧接着 ish 的匹配:
>>> re.findall('[wf]ish', source)['wish', 'wish', 'fish']
查询以若干个 w、s 或 h 组合的匹配:
>>> re.findall('[wsh]+', source)['w', 'sh', 'w', 'sh', 'h', 'sh', 'sh', 'h']
查询以 ght 开头,后面紧跟一个非数字非字母字符的匹配:
>>> re.findall('ght\W', source)['ght\n', 'ght.']
查询以 I 开头,后面跟着 wish 的匹配(wish 出现次数尽量少):
>>> re.findall('I (?=wish)', source)['I ', 'I ']
最后查询以 wish 结尾,前面为 I 的匹配(I 出现的次数尽量少):
>>> re.findall('(?<=I) wish', source)[' wish', ' wish']
有时,正则表达式的语法可能会与 Python 本身的语法冲突。例如,我们期望下面例子中的模式能匹配任何以 fish 开头的词:
>>> re.findall('\bfish', source)[]
为什么没有匹配成功?第 2 章曾提到,Python 字符串会使用一些特殊的转义符。例如上面的 \b,它在字符串中代表退格,但在正则表达式中,它代表一个单词的开头位置。因此,把 Python 的普通字符串用作正则表达式的模式串时需要特别注意,不要像上面一样与转义符产生冲突。或者在任何使用正则表达式的地方都记着在模式串的前面添加字符 r,这样可以告诉 Python 这是一个正则表达式,从而禁用字符串转义符,如下所示:
>>> re.findall(r'\bfish', source)['fish']
8. 模式:定义匹配的输出
当使用 match() 或 search() 时,所有的匹配会以 m.group() 的形式返回到对象 m 中。如果你用括号将某一模式包裹起来,括号中模式匹配得到的结果归入自己的 group(无名称)中,而调用 m.groups() 可以得到包含这些匹配的元组,如下所示:
>>> m = re.search(r'(. dish\b).*(\bfish)', source)>>> m.group()'a dish of fish'>>> m.groups()('a dish', 'fish')
(?P< name >expr) 这样的模式会匹配 expr,并将匹配结果存储到名为 name 的组中:
>>> m = re.search(r'(?P<DISH>. dish\b).*(?P<FISH>\bfish)', source)>>> m.group()'a dish of fish'>>> m.groups()('a dish', 'fish')>>> m.group('DISH')'a dish'>>> m.group('FISH')'fish'
7.2 二进制数据
处理文本数据比较晦涩难懂(新旧格式化、正则表达式等),而处理二进制数据就有趣多了。你需要了解像字节序(endianness,电脑处理器是如何将数据组织存储为字节的)以及整数的符号位(sign bit)之类的概念。你可能需要研究二进制文件格式、网络包等内容,从而对其中的数据进行提取甚至修改。本节将了解到 Python 中有关二进制数据的一些基本操作。
7.2.1 字节和字节数组
Python 3 引入了下面两种使用 8 比特序列存储小整数的方式,每 8 比特可以存储从 0~255 的值:
字节是不可变的,像字节数据组成的元组;
字节数组是可变的,像字节数据组成的列表。
我们的示例从创建列表 blist 开始。接着需使用这个列表创建一个 bytes 类型的变量 the_bytes 以及一个 bytearray 类型的变量 the_byte_array:
>> blist = [1, 2, 3, 255]>>> the_bytes = bytes(blist)>>> the_bytesb'\x01\x02\x03\xff'>>> the_byte_array = bytearray(blist)>>> the_byte_arraybytearray(b'\x01\x02\x03\xff')
bytes类型值的表示形式比较特殊:以b开头,接着是一个单引号,后面跟着由十六进制数(例如\x02)或 ASCII 码组成的序列,最后以配对的单引号结束。Python 会将这些十六进制数或者 ASCII 码转换为整数,如果该字节的值为有效 ASCII 编码则会显示 ASCII 字符。
>>> b'\x61'b'a'>>> b'\x01abc\xff'b'\x01abc\xff'
下面的例子说明了 bytes 类型的不可变性:
>>> the_bytes[1] = 127Traceback (most recent call last):File "<stdin>", line 1, in <module>TypeError: 'bytes' object does not support item assignment
但 bytearray 类型的变量是可变的:
>>> the_byte_array = bytearray(blist)>>> the_byte_arraybytearray(b'\x01\x02\x03\xff')>>> the_byte_array[1] = 127>>> the_byte_arraybytearray(b'\x01\x7f\x03\xff')
下面两行代码都会创建一个包含 256 个元素的结果,包含 0~255 的所有值:
>>> the_bytes = bytes(range(0, 256))>>> the_byte_array = bytearray(range(0, 256))
打印 bytes 或 bytearray 数据时,Python 会以 \xxx 的形式表示不可打印的字符,以 ASCII 字符的形式表示可打印的字符(以及一些转义字符,例如 \n 而不是 \x0a)。下面是 the_bytes 的打印结果(手动设置为一行显示 16 个字节):
>>> the_bytesb'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f!"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff'
看起来可能有些困惑,毕竟上面输出的数据是字节(小整数)而不是字符。
7.2.2 使用struct转换二进制数据
如你所见,Python 中有许多文本处理工具(模块、函数等),然而处理二进制数据的工具则要少得多。标准库里有一个 struct 模块,专门用于处理类似 C 和 C++ 中结构体的数据。你可以使用 struct 模块的功能将二进制数据转换为 Python 中的数据结构。
以一个 PNG 文件(一种常见的图片格式,其他图片格式还有 GIF、JPEG 等)为例看看 struct 是如何工作的。我们来编写一个小程序,从 PNG 文件中获得图片的宽度和高度信息。使用 O'Reilly 的经典标志:一只睁大了眼睛的眼镜猴,见图 7-1。

图 7-1:O'Reilly 的标志眼镜猴
你可以在Wikipedia(http://upload.wikimedia.org/wikipedia/en/9/95/O'Reilly_logo.png)上获取这张图片的 PNG 文件。第 8 章之前都不会讨论读取文件的方法,因此这里我仅仅是将这个文件下载下来,并编写了一个简单的小程序将它的数据以字节形式打印出来,然后将起始的 30 字节数据存入 Python bytes 型变量 data 中,如下所示。方便起见,你只需复制这部分数据即可。(PNG 格式规定了图片的宽度和高度信息存储在初始 24 字节中,因此不需要其他的额外数据。)
>>> import struct>>> valid_png_header = b'\x89PNG\r\n\x1a\n'>>> data = b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR' + \... b'\x00\x00\x00\x9a\x00\x00\x00\x8d\x08\x02\x00\x00\x00\xc0'>>> if data[:8] == valid_png_header:... width, height = struct.unpack('>LL', data[16:24])... print('Valid PNG, width', width, 'height', height)... else:... print('Not a valid PNG')...Valid PNG, width 154 height 141
以上代码说明:
data包含了 PNG 文件的前 30 字节内容,为了书的排版,我将这 30 字节数据放到了两行字节串中,并用+和续行符(\)将它们连接起来;valid_png_header包含 8 字节序列,它标志着这是一个有效的 PNG 格式文件;width值位于第 16~20 字节,height值则位于第 21~24 字节。
上面代码中的 >LL 是一个格式串,它用于指导 unpack() 正确解读字节序列并将它们组装成 Python 中的数据类型。可以将它分解成下面几个基本格式标志:
>用于指明整数是以大端(big-endian)方案存储的;每个
L代表一个 4 字节的无符号长(unsigned long)整数。
你可以直接获取 4 字节数据:
>>> data[16:20]b'\x00\x00\x00\x9a'>>> data[20:24]0x9ab'\x00\x00\x00\x8d'
大端方案将高字节放在左侧。由于宽度和高度都小于 255,因此它们存储在每一个 4 字节序列的最后一字节中。不难验证,上面的十六进制数转换为十进制后与我们预期的数值(图片的宽和高)一致:
>>> 0x9a154>>> 0x8d141
如果想要执行上述过程的逆过程,将 Python 数据转换为字节,可以使用 struct pack() 函数:
>>> import struct>>> struct.pack('>L', 154)b'\x00\x00\x00\x9a'>>> struct.pack('>L', 141)b'\x00\x00\x00\x8d'
表 7-5 和表 7-6 列出了 pack() 和 unpack() 使用的一些格式标识符。
首先是字节序标识符。
表7-5:字节序标识符
| 标识符 | 字节序 |
|---|---|
<
| 小端方案 |
>
| 大端方案 |
表7-6:格式标识符
| 标识符 | 描述 | 字节 |
|---|---|---|
x
| 跳过一个字节 | 1 |
b
| 有符号字节 | 1 |
B
| 无符号字节 | 1 |
h
| 有符号短整数 | 2 |
H
| 无符号短整数 | 2 |
i
| 有符号整数 | 4 |
I
| 无符号整数 | 4 |
l
| 有符号长整数 | 4 |
L
| 无符号长整数 | 4 |
Q
| 无符号 long long 型整数 | 8 |
f
| 单精度浮点数 | 4 |
d
| 双精度浮点数 | 8 |
p
| 数量和字符 | 1 + 数量 |
s
| 字符 | 数量 |
类型标识符紧跟在字节序标识符的后面。任何标识符的前面都可以添加数字用于指定需要匹配的数量,例如 5B 代表 BBBBB。
可以使用数量前缀改写 >LL:
>>> struct.unpack('>2L', data[16:24])(154, 141)
之前的例子中使用了切片 data[16:24] 直接获取所需的特定字节,也可以使用 x 标识符来跳过不需要的字节:
>>> struct.unpack('>16x2L6x', data)(154, 141)
上面格式串的含义如下:
使用大端方案(
>)跳过 16 个字节(
16x)读取 8 字节内容——两个无符号长整数(
2L)跳过最后 6 个字节(
6x)
7.2.3 其他二进制数据工具
一些第三方开源包提供了下面这些更加直观地定义和提取二进制数据的方法:
bitstring(https://code.google.com/p/python-bitstring/)
construct(http://construct.readthedocs.org/en/latest/)
binio(http://spika.net/py/binio/)
你可以在附录 D 查看下载和安装外部包的详细过程,这里不再赘述。接下来的几个例子需要提前安装 construct 包,只需执行下面这行代码即可:
$ pip install construct
下面的例子展示了如何使用 construct 从之前的 data 中提取 PNG 图片的尺寸:
>>> from construct import Struct, Magic, UBInt32, Const, String>>> # 基于https://github.com/construct上的代码修改而来>>> fmt = Struct('png',... Magic(b'\x89PNG\r\n\x1a\n'),... UBInt32('length'),... Const(String('type', 4), b'IHDR'),... UBInt32('width'),... UBInt32('height')... )>>> data = b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR' + \... b'\x00\x00\x00\x9a\x00\x00\x00\x8d\x08\x02\x00\x00\x00\xc0'>>> result = fmt.parse(data)>>> print(result)Container:length = 13type = b'IHDR'width = 154height = 141>>> print(result.width, result.height)154, 141
7.2.4 使用binascii()转换字节/字符串
标准 binascii 模块提供了在二进制数据和多种字符串表示(十六进制、六十四进制、uuencoded,等等)之间转换的函数。例如,下面的小例子将 8-字节的 PNG 头打印为十六进制值的形式,而不是 Python 默认的打印 bytes 型变量的方式:混合使用 ASCII 和转义的 \x xx。
>>> import binascii>>> valid_png_header = b'\x89PNG\r\n\x1a\n'>>> print(binascii.hexlify(valid_png_header))b'89504e470d0a1a0a'
反过来转换也可以:
>>> print(binascii.unhexlify(b'89504e470d0a1a0a'))b'\x89PNG\r\n\x1a\n'
7.2.5 位运算符
Python 提供了和 C 语言中类似的比特级运算符。表 7-7 列出了这些位运算符并附上了整数 a(十进制 5,二进制 0b0101)和 b(十进制 1,二进制 0b0001)的运算示例。
表7-7:比特级整数运算符
| 运算符 | 描述 | 示例 | 十进制结果 | 二进制结果 |
|---|---|---|---|---|
&
| 与 |
a & b
|
1
|
0b0001
|
|
| 或 |
a | b
|
5
|
0b0101
|
^
| 异或 |
a ^ b
|
4
|
0b0100
|
~
| 翻转 |
~a
|
-6
|
取决于 int 类型的大小
|
<<
| 左位移 |
a << 1
|
10
|
0b1010
|
>>
| 右位移 |
a >> 1
|
2
|
0b0010
|
这些运算和第 3 章的集合运算有些类似。& 返回两个运算数中相同的比特。| 返回两个运算数中任意一者有效的比特。^ 返回仅在一个运算数中有效的比特。~ 将所有比特翻转。现代计算机都使用二进制补码(two's complement)进行运算,其中整数的最高位定义为符号位(0 为正,1 为负),因此翻转操作会改变运算数的符号。<< 和 >> 仅仅将比特向左或向右移动,左位移操作相当于将数字乘以 2,右位移操作相当于将数字除以 2。
7.3 练习
(1) 创建一个 Unicode 字符串 mystery 并将它的值设为 '\U0001f4a9'。打印 mystery,并查看 mystery 的 Unicode 名称。
(2) 使用 UTF-8 对 mystery 进行编码,存入字节型变量 pop_bytes,并将它打印出来。
(3) 使用 UTF-8 对 pop_bytes 进行解码,存入字符串型变量 pop_string,并将它打印出来,看看它与 mystery 是否一致?
(4) 使用旧式格式化方法生成下面的诗句,把 'roast beef'、'ham'、'head' 和 'clam' 依次插入字符串:
My kitty cat likes %s,My kitty cat likes %s,My kitty cat fell on his %sAnd now thinks he's a %s.
(5) 使用新式格式化方法生成下面的套用信函,将下面的字符串存储为 letter(后面的练习中会用到):
Dear {salutation} {name},Thank you for your letter. We are sorry that our {product} {verbed} in your{room}. Please note that it should never be used in a {room}, especiallynear any {animals}.Send us your receipt and {amount} for shipping and handling. We will sendyou another {product} that, in our tests, is {percent}% less likely tohave {verbed}.Thank you for your support.Sincerely,{spokesman}{job_title}
(6) 创建一个字典 response 包含以下键:'salutaion'、'name'、'product'、'verbed'(动词过去式)、'room'、'animals'、'amount'、'percent'、'spokesman' 以及 'job_title'。设定这些键对应的值,并打印由 response 的值填充的 letter。
(7) 正则表达式在处理文本上非常方便,在这个练习中我们会对示例文本尝试做各种各样的操作。示例文本是一首诗,名为 Ode on the Mammoth Cheese,作者是 James McIntyre,写于 1866 年。出于对当时安大略湖手工制造的 7000 磅的巨型奶酪的敬意,它当时甚至在全球巡回展出。如果你不愿意自己一词一句敲出来,直接用搜索引擎搜一下粘贴到你的 Python 代码里即可。你也可以从 Project Gutenberg(http://www.gutenberg.org/ebooks/36068?msg=welcome_stranger)找到。我们将这个字符串命名为 mammoth。
We have seen thee, queen of cheese,Lying quietly at your ease,Gently fanned by evening breeze,Thy fair form no flies dare seize.All gaily dressed soon you'll goTo the great Provincial show,To be admired by many a beauIn the city of Toronto.Cows numerous as a swarm of bees,Or as the leaves upon the trees,It did require to make thee please,And stand unrivalled, queen of cheese.May you not receive a scar asWe have heard that Mr. HarrisIntends to send you off as far asThe great world's show at Paris.Of the youth beware of these,For some of them might rudely squeezeAnd bite your cheek, then songs or gleesWe could not sing, oh! queen of cheese.We'rt thou suspended from balloon,You'd cast a shade even at noon,Folks would think it was the moonAbout to fall and crush them soon.
(8) 引入 re 模块以便使用正则表达式相关函数。使用 re.findall() 打印出所有以 c 开头的单词。
(9) 找到所有以 c 开头的 4 个字母的单词。
(10) 找到所有以 r 结尾的单词。
(11) 找到所有包含且仅包含连续 3 个元音的单词。
(12) 使用 unhexlify() 将下面的十六进制串(出于排版原因将它们拆成两行字符串)转换为 bytes 型变量,命名为 gif:
'47494638396100010001800000000000ffffff21f9' +'0401000000002c000000000100010000020144003b'
(13) gif 定义了一个 1 像素的透明 GIF 文件(最常见的图片格式之一)。合法的 GIF 文件开头由 GIF89a 组成,检测一下上面的 gif 是否为合法的 GIF 文件?
(14) GIF 文件的像素宽度是一个 16 比特的以小端方案存储的整数,偏移量为 6 字节,高度数据的大小与之相同,偏移量为 8。从 gif 中抽取这些信息并打印出来,看看它们是否与预期的一样都为 1 ?

{kind=link}