附录 B 工作中的 Python
“生意!”鬼魂攥紧手凄凉地说道,“我为什么不把人看成是我的生意的一部分……”
—— 查尔斯·狄更斯的《圣诞颂歌》
男性商务人士总是习惯一身西装戴着领带。但不知为何,每当他们要真正开始干活时总是磨磨蹭蹭的,他们会先把夹克扔到椅背上,然后解开领带,卷起袖口,再冲些咖啡。与此同时,女员工往往已经默默地把活都干完了。也许会有一杯拿铁相伴。
在实际商业活动中,我们会使用到前面曾介绍过的所有技术——数据库、互联网、系统和网络。Python 凭借着它极高的生产力被广泛应用于企业(http://opensource.com/life/13/11/python-enterprise-jessica-mckellar)和创业公司(http://opensource.com/business/13/12/why-python-perfect-startups)。
在商业界,人们曾在很长的一段时间内寻求能够一击解决遗产问题(legacy problem)的银色子弹。这些遗产问题包括:互不兼容的文件格式、晦涩难懂的网络协议、开发语言独占以及文档准确性普遍不高。然而今天,我们已经可以看到一些科学技术开始可以协同工作、成规模发展。通过采用下面这些建议,公司可以创建更快捷、更便宜且更易于扩展的应用:
像 Python 一样的动态语言
将互联网作为通用 GUI
使用 RESTful API 作为独立于语言的服务接口
关系型数据库和 NoSQL 数据库
大数据及大数据分析
通过“云”进行部署,节省开支
B.1 Microsoft Office套件
当今商业的正常运行对 Microsoft Office 应用及其文件格式有着很强的依赖性。Python 中有一些可以对 Office 文件进行处理的库,但它们大都没什么名气,甚至有些连像样的文档都没有。下面是一些可以用来处理 Office 文件的 Python 库的例子。
这个库可以用于创建、读取、写入 Microsoft Office Word 2007 及以上使用的 .docx 文件。
- python-excel(http://www.python-excel.org/)
这个库有一份 PDF 教程(http://www.simplistix.co.uk/presentations/python-excel.pdf),介绍了如何使用 xlrd、xlwt 和 xlutils 模块。Excel 还可以对逗号分隔值(Comma-Saparated Value,CSV)格式的文件进行读写。你应该已经知道如何使用 csv 模块处理 CSV 文件了。
- oletools(http://www.decalage.info/python/oletools)
这个库可以从 Office 格式的文件中抽取数据。
下面这些模块可自动化处理 Windows 应用:
这个模块可以自动化处理许多 Windows 应用 1。但是它仅限在 Python 2 环境中使用,而且文档不全。你可以参考博客:http://www.galalaly.me/index.php/2011/09/use-python-to-parse-microsoft-word-documents-using-pywin32-library/ 和 http://www.blog.pythonlibrary.org/2010/07/16/python-and-microsoft-office-using-pywin32/。
pywinauto(https://code.google.com/p/pywinauto/)
这个模块也是用于自动化处理 Windows 应用的,同样限制于 Python 2。使用方法可以参考这篇博客:https://techsaju.wordpress.com/2013/03/06/using-python-pywinauto-for-automating-windows-gui-applications/。
swapy 可以直接根据用户的原始操作生成对应的 pywinauto 的代码。
1类似于 Windows 中宏的作用,它可以记录你执行的可重复性操作便于以后复用。——译者注
OpenOffice(http://www.openoffice.org/)是一款开源的 Office 应用的替代品。它可以在 Linux、Unix、Windows 以及 OS X 上运行,可以对 Office 格式的文件进行读写操作。OpenOffice 自身也绑定了供自己使用的 Python 3。你可以通过 PyUNO 库(http://www.openoffice.org/udk/python/python-bridge.html)对 OpenOffice 进行 Python 编程(https://wiki.openoffice.org/wiki/Python)。
OpenOffice 是由 Sun Microsystems 开发的,当甲骨文将它收购之后,许多用户害怕未来会无法免费使用这款产品。LibreOffice(https://www.libreoffice.org/)因此横空出世。DocumentHacker(https://documenthacker.files.wordpress.com/2013/07/writing_documents-_for_software_engineers_v0002.pdf)描述了如何使用 Python 的 UNO 库对 LibreOffice 进行编程。
为了对 Office 文件进行读写操作,OpenOffice 和 LibreOffice 不得不对 Microsoft 的文件格式进行逆向解析,这个过程难度可不小。通用 Office 转换器(Universal Office Converter,http://dag.wiee.rs/home-made/unoconv/)就依赖于 OpenOffice 和 LibreOffice 中的 UNO 库。 这个转换器可以转换多种文件格式:文档、电子表格、图表和演示文稿。
你可以使用 python-magic(https://github.com/ahupp/python-magic)对格式未知文件中的某些字节序进行分析从而猜测出它的具体格式。
python open document 库(http://appyframework.org/pod.html)允许你根据模板格式提供对应的 Python 代码来创建动态文档。
Adobe 的 PDF 格式在商业中也十分常见,尽管它并不属于 Micorsoft 格式家族。ReportLab(http://www.reportlab.com/opensource/)是一个基于 Python 的 PDF 文件生成器,它包含一个开源版本和一个商用版本。如果你需要用 Python 编辑一个 PDF 文件的话,也许可以从 StackOverflow(http://stackoverflow.com/questions/1180115/add-text-to-existing-pdf-using-python)获取些帮助。
B.2 执行商业任务
无论需要做什么事情,你几乎都可以找到对应的 Python 模块来帮助你。访问 PyPI(https://pypi.python.org/pypi)并将你想要搜索的内容敲进搜索框就可以了。你可能会对其中一些与商业任务相关的模块有兴趣:
使用 Fedex(https://github.com/gtaylor/python-fedex)或 UPS(https://github.com/openlabs/PyUPS)运送货物。
使用 stamps.com(https://github.com/jzempel/stamps)API 邮递。
阅读关于 Python for business intelligence(http://www.slideshare.net/Stiivi/python-business-intelligence-pydata-2012-talk)的讨论。
爱乐压咖啡机在 Anoka 的畅销是正常的消费行为还是有什么内情? Cubes(http://cubes.databrewery.org/)是一个可以进行联机分析处理(Online Analytical Processing,OLAP)的网络服务器,它同时还是一个数据浏览器,可以帮你对上述问题进行分析。
OpenERP(https://www.openerp.com/)是一个大型的商用企业资源计划(Enterprise Resource Planning,ERP)系统。它是由 Python 和 JavaScript 编写的,拥有数千个扩展模块。
B.3 处理商业数据
商业界对数据情有独钟。但不幸的是,它们总是莫名其妙地制造麻烦让数据变得难以使用。
电子表格是一项伟大的发明,随着时间的推移商业界对它愈发痴迷。许多非程序员被诱骗去编程,仅仅因为他们编码的被称作宏(macro)而不是程序。但就如同宇宙在不断扩张一样,数据也在飞速膨胀。旧版本的 Excel 最多支持 65 536 行数据,即使是新版本也只不过能支持百万行。当一个企业所拥有的数据量超过了单一计算机所能承载的最大值,就像企业员工数过百一样——瞬间你会发现旧框架变得不再适用,你亟需新的层级结构、新的媒介以及新的通信方式。
海量数据处理程序的诞生并不是由单机上庞大的数据量导致的,而是由于不同来源的数据倾注到单一业务中聚合导致的。关系型数据库可以同时处理百万行数据而不崩溃,但这种性能也只有在集中写入或更新数据时才能达到。旧的纯文本文件或二进制文件可以增长到 GB 级别的大小,但如果你需要一口气对它进行全面处理的话,就必须有足够大的内存(否则只能分块读取到内存中进行处理)。传统的桌面程序并不是为解决这些问题而设计的。但像 Google 和亚马逊这样的公司则不得不去寻找大规模处理数据的解决方案。Netflix(http://techblog.netflix.com/2013/03/python-at-netflix.html)就是一个例子,它建立在亚马逊的 AWS 云系统上,使用 Python 将 RESTful API、信息安全、部署调度、数据库有机地结合了起来,提供了一套完整的解决方案。
B.3.1 提取、转换、加载
数据就像一座冰山,复杂的操作都埋藏在水下。其中占最大部分的、同时也是最重要的是关于获取数据的操作。企业中对于处理数据常用的术语是提取、转换、加载(Extracting,Transforming,Loading),也就是所谓的 ETL。类似的同义词还有 data munging 或 data wrangling,给人一种驯服凶猛野兽的感觉 2,比喻得还算恰当。现在看来,这似乎只是一个解决了的工程问题,但其实如何优雅巧妙地处理海量数据还是需要一定艺术灵感的。附录 C 会涉及更多关于数据科学的内容,这是许多开发者需要花费大部分时间挣扎的地方。
2munging 和 wrangling 有争吵、斗争的意思。——译者注
如果你看过《绿野仙踪》,可能还记得(除了飞天猴外)快结尾的部分:善良的巫师告诉多萝西,其实她只要敲敲她的红鞋子就可以回到堪萨斯的家了。尽管当时我还小,但还是有一种“拖了这么久,她终于告诉多萝西了!”的感觉。事后回顾,我意识到,如果女巫早点就把这个诀窍告诉多萝西的话,那这电影就没法拍了。
但在这里我们讨论的不是电影,而是商业。在商业,能把任务尽快完成是一件好事。所以,我想要在这里告诉你们一些窍门。你每天工作中用来处理数据的大多数工具都在这本书的前面有所涉及,包括高度抽象的数据结构,例如字典、对象,成千上万个标准库和第三方库以及一个满是高手的社区,离你只有 Google 一下的距离。
如果你是一个从事商务的程序员,那你每天的工作流程几乎都逃不开下面这些步骤:
(1) 从奇怪格式的文件和数据库中抽取出目标数据;
(2) 清洗数据,包括各种苦差事,你需要和各种各样的对象打交道;
(3) 进行转换工作,例如日期的转换、时间的转换以及字符集的转换;
(4) 真正开始处理数据;
(5) 将结果数据存储在文件或者数据库中;
(6) 回到第一步重新继续;给数据抹上肥皂,清洗,一遍又一遍。
举个例子:设想你需要将电子表格中的一些数据挪到数据库里。一种可行的方式是将电子表格存储为 CSV 格式,然后用第 8 章介绍过的 Python 库进行处理。或者也可以搜索看看有没有可以直接读取二进制电子表格文件的 Python 模块。你的手会自然而然地在 Google 里敲入 python excel,找到像 Working with Excel files in Python(http://www.python-excel.org/)这样的网站。接着你可以使用 pip 安装你感兴趣的包,然后定位 Python 的数据库驱动为后续工作做好准备。第 8 章也提到过 SQLAlchemy 以及直接与底层数据库打交道的驱动。准备工作就绪,现在我们可以在这两者之间编写点代码了,这里才是 Python 的数据结构以及库真正开始帮你节省时间的地方。
首先来看一个例子,之后我们会尝试使用一些库来简化其中某些步骤。我们需要读取一个 CSV 文件,然后以某一列的值作为键,将具有相同键的数据进行聚合(这里使用加法聚合)。如果在 SQL 中进行这些操作的话,会用到 SELECT、JOIN、GROUP BY 等命令。
首先关于待处理文件,zoo.csv,包含以下几列内容:动物种类、咬伤游客的次数、处理咬伤需要缝合的针数以及为了防止游客告知当地媒体所支付的赔偿金。
animal,bites,stitches,hushbear,1,35,300marmoset,1,2,250bear,2,42,500elk,1,30,100weasel,4,7,50duck,2,0,10
我们想要了解到底哪种动物给我们带来的损失最多,因此需要计算在每一种动物身上花费的总的封口费数目(至于如何处理咬伤和如何缝针就交给实习医生了,不是我们程序员能力所及)。我们需要使用 8.2.1 节介绍过的 csv 模块以及 5.5.2 节介绍过的 Counter。将下面的代码存储为 zoo_counts.py:
import csvfrom collections import Countercounts = Counter()with open('zoo.csv', 'rt') as fin:cin = csv.reader(fin)for num, row in enumerate(cin):if num > 0:counts[row[0]] += int(row[-1])for animal, hush in counts.items():print("%10s %10s" % (animal, hush))
我们直接跳过第一行,因为第一行仅仅提供了每列的名称,没有任何有实际价值的数据。counts 是一个 Counter 对象,它首先会将每一种动物对应的值(封口费)初始化为 0。此外还对输出结果进行了右对齐调整。看一下输出结果:
$ python zoo_counts.pyduck 10elk 100bear 800weasel 50marmoset 250
最让我们操心的果然是熊!它一直就是我们主要怀疑的对象,这下有数据为证了。
现在试着使用一个数据处理工具 Bubbles(http://bubbles.databrewery.org/)来重复上面的工作。你可以通过下面这条命令来安装它:
$ pip install bubbles
它依赖 SQLAlchemy,如果你没有安装过的话可以通过 pip install sqlalchemy 安装。下面是我们根据文档(http://pythonhosted.org/bubbles/install.html#quickstart)改写的测试程序(命名为 bubbles1.py):
import bubblesp = bubbles.Pipeline()p.source(bubbles.data_object('csv_source', 'zoo.csv', infer_fields=True))p.aggregate('animal', 'hush')p.pretty_print()
真相只有一个!接下来就是见证真相的时刻了:
$ python bubbles1.py2014-03-11 19:46:36,806 DEBUG calling aggregate(rows)2014-03-11 19:46:36,807 INFO called aggregate(rows)2014-03-11 19:46:36,807 DEBUG calling pretty_print(records)+--------+--------+------------+|animal |hush_sum|record_count|+--------+--------+------------+|duck | 10| 1||weasel | 50| 1||bear | 800| 2||elk | 100| 1||marmoset| 250| 1|+--------+--------+------------+2014-03-11 19:46:36,807 INFO called pretty_print(records)
Bubbles 的文档中提供了将调试信息隐藏掉的方法,甚至还包括改变输出表格格式的方法。
对比这两个例子,我们发现 bubbles 例子中我们仅仅使用了一个函数调用(aggregate)就完成了之前手动读取、计数 CSV 文件的全部工作。根据需求的不同,数据处理工具有时能为你节省出大量时间。
更现实的例子中,zoo 文件可能包含几千行记录(这个动物园还真是危险),甚至包含拼写错误(例如把 bear 写成了 bare),或者数字中无意添加了分隔符,等等。如果你想要更多关于如何使用 Python 和 Java 进行实际数据处理的例子,我推荐 Greg Wilson 的 Data Crunching: Solve Everyday Problems Using Java, Python, and More(Pragmatic Bookshelf,http://shop.oreilly.com/product/9780974514079.do)。
数据清理工具可以节省你许多时间,而 Python 中恰好就有许多这样的工具。再举个例子,PETL(http://petl.readthedocs.org/en/latest/)可以对表格中的数据进行行列提取以及重命名。它的相关产品(http://petl.readthedocs.org/en/latest/related_work.html)网页列出了许多有用的模块和产品。附录 C 里有一些关于常用的数据处理工具的讨论,例如 Pandas、NumPy 以及 IPython。尽管这些工具现在仍主要被科学研究者所熟知,但它们在金融工作者以及数据处理员之间也开始愈加流行。2012 年 Pydata 会议上,AppData(http://www.computerworld.com/article/2492915/big-data/python—big-data-s-secret-power-tool.html)介绍了上述三款工具以及其他的一些 Python 工具是如何帮助我们每日处理 15TB 的数据的。毫无疑问,Python 有足够的能力处理海量的实际数据。
B.3.2 额外信息源
有时你可能需要使用一些来源于企业之外的数据。下面是一些可以使用的商业和政府提供的数据源。
- data.gov(https://www.data.gov/)
数千个数据集和数据处理工具的门户。它的 API(https://www.data.gov/developers/apis)是搭建在一套 Python 数据管理系统——CKAN(http://ckan.org/)上的。
- Opening government with Python(http://sunlightfoundation.com/)
从这里获取相关视频(https://www.youtube.com/watch?v=FTwjUL6Gq4A)及幻灯片(http://goo.gl/8Yh3s)。
- python-sunlight(http://python-sunlight.readthedocs.org/en/latest/)
用于访问 Sunlight API(http://sunlightfoundation.com/api/)的库。
- froide(http://stefanw.github.io/froide/)
一个基于 Django 的管理信息自由请求(Freedom of Information Request)的工具。
- 30 个寻找公开数据的网址(http://blog.visual.ly/data-sources/)
一些有用的链接。
B.4 金融中的Python
最近,金融界对于 Python 的兴趣愈发浓烈。数据分析专家们(quant)正在搭建新一代的金融工具,他们或在附录 C 中提到的 Python 工具的基础上进行改写,或另起炉灶从头编写。
- Quantitative economics(http://quant-econ.net/)
这是一个用于建立经济模型的工具,包含许多数学公式和 Python 代码。
- Python for finance(http://www.pythonfor-finance.com)
以 Yves Hilpisch 的书 Derivatives Analytics with Python: Data Analytics, Models, Simulation, Calibration, and Hedging(Wiley)为代表,介绍 Python 在金融中的应用。
- Quantopian(https://www.quantopian.com/)
Quantopian 是一个交互式网站,你可以在上面编写自己的 Python 代码来整理股票的历史数据,进行后验测试。
- PyAlgoTrade(http://gbeced.github.io/pyalgotrade/)
这也是一个对股票进行后验测试的工具,只不过 PyAlgoTrade 运行在你自己的计算机上,无需联网。
- Quandl(http://www.quandl.com/)
你可以使用 Quandl 在数百万金融数据集中进行搜索。
- Ultra-finance(https://code.google.com/p/ultra-finance/)
实时的股票信息库。
- Python for Finance(O'Reilly,http://shop.oreilly.com/product/0636920032441.do)
Yves Hilpisch 的一本关于如何使用 Python 进行金融建模的书。
B.5 商业数据安全性
在商业中,安全性永远是一个重要的问题。关于这方面的内容可以写整整一本书,事实上也确实有许多关于此的书,因此在这里我们不多涉及,仅仅提几个与 Python 有关的小贴士。
11.2.6 节中介绍了 scapy,一款用 Python 编写的网络包内容查看器。它经常用于网络攻击分析中。
Python Security(http://www.pythonsecurity.org/)网站上有许多关于安全性的话题,包括 Python 中一些与安全加密相关的模块以及使用技巧。
TJ O'Connor 的书 Violent Python: A Cookbook for Hackers, Forensic Analysts, Penetration Testers and Security Engineers(http://shop.oreilly.com/product/9781597499576.do,Syngress)中广泛介绍了 Python 及计算机安全方面的内容。
B.6 地图
地图具有很高的商业价值,而 Python 又非常善于绘制地图,所以我们会在这方面多花点篇幅介绍。高层们都喜欢图表,如果你能迅速为你们企业的官网绘制出一张漂亮的展示地图,他们一定会对你有所好感。
在互联网发展初期,我就曾访问过 Xerox 旗下的一个地图制作网站,当时还处于试验阶段。而随后像 Google Maps 这样的大网站的上线带来了一场新的革命(同经典的那句“为什么我就没有想到这个点子挣上几百万呢?”)。再到现在,处处可见地图和基于地理位置 服务(location-based service),它们在移动设备中尤为有用。
关于地图的许多术语的意思都有所重叠,例如地图绘制(mapping)、制图学(cartography)、GIS(地理信息系统,Geographic Information System)、GPS(全球定位系统,Global Positioning System)、地理空间分析(geospatial analysis),等等。Geospatial Python(http://geospatialpython.com/2013_11_01_archive.html)上的博客中有一张描述“无所不能(800-pound gorilla)”的系统——GDAL/OGR、GEOS 以及 PROJ.4(projections)——以及它周边系统的图片(图中用猩猩来表示这个系统 3)。它们大多提供了 Python 接口。我们会对其中的一些进行讲解,就从最简单的地图格式讲起。
3前文 800-pound gorilla 在英文中有无所不能、强大的意思,图片使了双关。——译者注
B.6.1 格式
地图的世界中有许多不同的表示格式:向量(线)、栅格(图片)、元数据(词)以及它们之间的不同组合。
Esri 是开发地理系统的先驱,在 20 年前发明了 shapefile 格式。一个 shapefile 格式的文件通常包含了多个子文件,其中至少需要包含下面这些:
- .shp
“形状”(向量)信息
- .shx
形状索引
- .dbf
属性数据库
下面列出了一些 Python 中用于处理 shapefile 文件的有用的模块:
pyshp(https://code.google.com/p/pyshp/)是一个纯 Python 编写的 shapefile 库;shapely(http://toblerity.org/shapely/)可以处理与地理位置相关的问题,例如:“这座小镇里哪些房子位于 50 年洪水线上?”fiona(https://github.com/Toblerity/Fiona)包含了用于处理 shapefile 以及其他向量格式文件的 OGR 库;kartograph(http://kartograph.org/)可以将 shapefile 格式的文件转化为便于在服务器端或客户端上使用的 SVG 格式;basemap(http://matplotlib.org/basemap/)使用matplotlib在地图上绘制 2-D 数据;cartopy(http://scitools.org.uk/cartopy/docs/latest/)使用matplotlib和shapely绘制地图。
为了便于之后讲解示例,我们需要先获取一个 shapefile 格式的文件。访问 Natural Earth 上的 1:110m Cultural Vectors page(http://www.naturalearthdata.com/downloads/110m-cultural-vectors/),在“Admin 1 - States and Provinces”一栏下,点击绿色的 download states and provinces(http://www.naturalearthdata.com/http/www.naturalearthdata.com/download/110m/cultural/ne_110m_admin_1_states_provinces.zip)框可以下载得到一个压缩文件。下载完成后将它解压,你应该可以看到下面列出的这些文件:
ne_110m_admin_1_states_provinces_shp.README.htmlne_110m_admin_1_states_provinces_shp.sbnne_110m_admin_1_states_provinces_shp.VERSION.txtne_110m_admin_1_states_provinces_shp.sbxne_110m_admin_1_states_provinces_shp.dbfne_110m_admin_1_states_provinces_shp.shpne_110m_admin_1_states_provinces_shp.prjne_110m_admin_1_states_provinces_shp.shx
后面的例子会使用到这些文件。
B.6.2 绘制地图
你需要安装下面这个库来读取 shapefile 文件:
$ pip install pyshp
现在该看看程序了。下面是我根据 Geospatial Python 博客(http://geospatialpython.com/2010/12/rasterizing-shapefiles.html)修改得到的代码,map1.py:
def display_shapefile(name, iwidth=500, iheight=500):import shapefilefrom PIL import Image, ImageDrawr = shapefile.Reader(name)mleft, mbottom, mright, mtop = r.bbox# map unitsmwidth = mright - mleftmheight = mtop - mbottom# scale map units to image unitshscale = iwidth/mwidthvscale = iheight/mheightimg = Image.new("RGB", (iwidth, iheight), "white")draw = ImageDraw.Draw(img)for shape in r.shapes():pixels = [(int(iwidth - ((mright - x) hscale)), int((mtop - y) vscale))for x, y in shape.points]if shape.shapeType == shapefile.POLYGON:draw.polygon(pixels, outline='black')elif shape.shapeType == shapefile.POLYLINE:draw.line(pixels, fill='black')img.show()if __name__ == '__main__':import sysdisplay_shapefile(sys.argv[1], 700, 700)
上面的代码读取了 shapefile 文件,并遍历了其中的图形库。我们只关注其中两种图形类型:首尾相连的多边形和首尾不相连的折线。上面的代码仅仅是我简单看了一眼 pyshp 的文档一遍编写出来的,所以我并不百分百保证它能正常运行。但往往万事开头难,不要怕出错,出错了慢慢修改即可。
好了,运行一下上面的代码。需要传入的参数是 shapefile 文件的原始文件名,不添加任何扩展名:
$ python map1.py ne_110m_admin_1_states_provinces_shp
你应该会看到类似下面图 B-1 所示的结果。
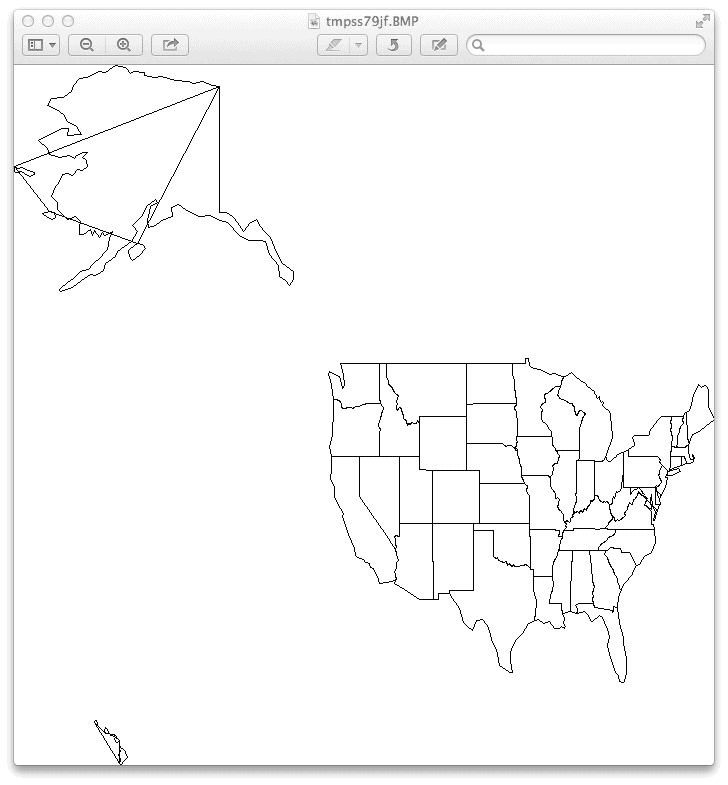
图 B-1:原始地图
恩,它确实成功画出了一幅类似美国地图的图,但似乎存在些问题:
阿拉斯加和夏威夷的地图像是被顽皮的猫拽了一条线缠绕了起来,这显然是个 bug;
地图被压扁了,我们需要对原始图做映射(projection)处理;
图片不太美观,我们需要做些样式(style)修改。
关于上述第一点:显然是因为我草草编写的代码逻辑出现了问题,应该怎么改呢?第 12 章曾介绍了一些开发建议,包括如何调试 bug,但这里我们可以考虑一些其他途径。比如可以不断添加一些测试代码直到定位并解决问题,或者可以干脆使用别的绘图库试试。也许有些抽象能力更高的库可以一口气解决上面所有问题(零散杂乱的线、压缩的外观以及原始丑陋的样式)。
下面是其他一些可选的 Python 绘图软件。
- basemap(http://matplotlib.org/basemap/)
基于 matplotlib,可以一层一层地绘图以及添加数据。
- mapnik(http://mapnik.org/)
以 C++ 编写的库,提供了 Python 接口,便于快速开发。可以绘制矢量地图(线)和栅格地图(图片)。
- tilemill(https://www.mapbox.com/tilemill/)
一个基于 mapnik 的地图设计平台。
一个从 Python 到 Vega(一款 JavaScript 可视化工具)的翻译器。你可以阅读 Mapping data in Python with pandas and vicent(http://wrobstory.github.io/2013/10/mapping-data-python.html)这篇博客学习如何使用。
- Python for ArcGIS(http://resources.arcgis.com/en/communities/python/)
链接到 Esri 的商业产品 ArcGIS 中包含的 Python 资源。
- 使用 Python 进行空间分析(https://complex.luxbulb.org/howto/spatial-analysis-python)
链接到相关的教程、包以及视频。
- 使用 Python 处理地理空间数据(https://conference.scipy.org/scipy2013/tutorial_detail.php?id=110)
链接到相关视频展示。
使用 pandas、matplotlib、shapely 以及其他 Python 模块绘制历史性地标的地图。
- Python Geospatial Development(http://shop.oreilly.com/product/9781782161523.do)
Eric Westra 的一本书,介绍了如何使用 mapnik 以及其他工具。
- Learning Geospatial Analysis with Python(http://shop.oreilly.com/product/9781783281138.do)
Joel Lawhead 的一本书,回顾了与地理空间相关的算法、格式以及库。
上面提到的模块都能绘制出精美的地图,但它们的安装、学习难度都比较大。有些模块甚至依赖于你没有见过的库,例如 numpy 和 pandas。使用它们带来的收益能否大于付出?作为开发者,我们总是不得不在掌握的信息不完整的情况下被迫做出取舍。如果你对于绘制地图感兴趣,不妨下载其中的一些库看看能做出点什么。或者你可以试着连接到某些远程网络服务的 API 以免去安装软件的烦恼;第 9 章介绍了如何连接到网络服务器并解析服务器做出的 JSON 响应。
B.6.3 应用和数据
目前为止,我们已经讨论了许多关于绘制地图的内容,但其实我们可以使用地图数据做更多事情而不是仅仅停留在绘图。地理编码(Geocoding)指在地址信息和地理坐标之间进行转化。你可以找到许多与地理编码相关的 API(http://www.programmableweb.com/apitag/geocoding),详见 ProgrammableWeb's comparison(http://www.programmableweb.com/news/7-free-geocoding-apis-google-bing-yahoo-and-mapquest/2012/06/21)及 Python 库,例如 geopy(https://code.google.com/p/geopy/)、pygeocoder(https://pypi.python.org/pypi/pygeocoder)以及 googlemaps(http://py-googlemaps.sourceforge.net/)。如果你注册了 Google 或其他平台并获得了相应的 API 密钥,你还可以获取这些平台提供的一些其他服务,例如两位置间详细步骤的旅行路线、某一位置附近搜索,等等。
下面是一些可用的地图数据源:
美国人口统计局发布的地图文件总览
大量的地理地图数据以及人口地图数据
全球地图资源
三种比例尺下的矢量图以及栅格地图数据
我们还应该在这里讨论一下相关的数据科学工具(Data Science Toolkit,http://www.datasciencetoolkit.org/),包括免费的双向地理编码工具、政治版图边界的坐标信息以及统计信息,等等。你可以将所有的数据和软件统一下载到虚拟机(VM)中,从而让它们独立运行在你的电脑里不受其他软件和数据的影响。
