第 8 章 并行与大规模科学计算
本章主要介绍在Python中使用并行和大规模计算的重要概念,或者说是用IPython解决科学计算问题,还会介绍大规模科学计算和大数据处理的发展趋势。本章通过程序示例帮助你更好地理解这些概念。
本章将介绍的主题如下:
IPython并行计算基础
IPython并行计算的组成部分
IPython的任务接口和数据库
IPython的直接运行接口
IPython并行计算详述
IPython的MPI编程
在Python中使用Hadoop和Spark进行大数据处理
IPython通过启动多个进程,让用户使用并行计算。IPython的第一个进程是IPython引擎,它是一个Python解释器,可以执行用户提交的任务。用户可以启动多个引擎来执行并行计算。第二个进程是IPython集线器,它监控引擎和调度器,跟踪用户任务的状态。集线器进程监控来自引擎和客户端的注册请求,它会持续地监控与调度器关联的连接。第三个进程是IPython调度器。这是一组进程,在客户端和引擎之间传送命令和结果。通常,调度器进程在已运行控制器进程的机器上,与集线器进程连接。最后一个进程是IPython客户端,是一个IPython会话,协调引擎完成计算任务。
以上介绍的所有进程组合起来称为IPython集群。这些进程之间通过ZeroMQ进行通信。ZeroMQ支持多种通信协议,包括Infiband、IPC、PGM、TCP等。IPython控制器是由集线器和调度器构成的,通过网络套接字(socket)监听客户端请求。当用户开启一个引擎之后,它会连接一个集线器并完成注册。集线器首先将调度器连接信息传递给引擎。之后,引擎会连接调度器。这些连接会在一个引擎的整个生命周期中存在。每个IPython客户端都会使用许多socket对象连接控制器。通常,客户端连接每个调度器用一个连接,连接每个集线器用三个连接。这些连接会在客户端的生命周期中持续存在。
8.1 用IPython做并行计算
IPython可以让用户以交互的方式完成并行与高性能计算。可以用IPython自带的并行计算方法,由上面四个部分(集线器、引擎、调度器和客户端)组成,能满足绝大多数并行需求。具体说来,IPython支持以下四类并行方式。
单程序,多数据并行(single program, multiple data parallelism,SPMD):这是最常见的并行编程方式,属于多指令多数据( Multiple Instruction and Multiple Data,MIMD)的子集。在这个模型中,每个任务会单独执行同一程序的复制版本。每个任务处理不同的数据集以实现更高的性能。
多程序,多数据并行(multiple program, multiple data parallelism,MPMD):在这种并行方式中,每个任务会在每个计算节点上运行不同的程序,处理不同的数据。
使用消息传递接口进行通信(message passing using MPI):消息传递接口(Message Passing Interface,MPI)是开发者设计消息传递程序库的设计规则。它是一种与编程语言无关的设计规则,可以让用户写出基于消息传递的并行程序。目前,它支持分布式内存共享模式和它们的混合模式。
任务并行:任务并行方式是在不同的计算节点之间分配任务。任务可以是线程,消息传递的组成部分,或者其他编程模式的组成部分,例如MapReduce。
数据并行:数据并行方式是在不同的计算节点之间分配数据。数据并行与任务并行最大的区别在于,数据并行是在计算节点之间分配和并行化数据。
以上类型的混合模式:IPython也支持前面不同并行方式的混合体。
用户自定义的并行方式:IPython被设计得十分简单灵活,用户可以按照自己的需求定义新的并行方式。
IPython可以在程序整个生命周期中的各个阶段使用交互式并行,例如开发、运行、调试与监控阶段。
IPython配合matplotlib可以让用户分析并可视化远程或分布式大型数据库。也支持用户在远程集群计算,然后将数据拉回本机再进行分析和可视化。用户可以通过IPython客户端将一个MPI应用推送到高性能的计算机上。它还可以对运行在一组CPU上的任务进行动态的负载均衡。另外,IPython还可以让用户通过两三行代码就写出一个简单的并行程序。用户可以交互式地开发、运行、测试、调试自定义并行程序。IPython允许用户将运行在不同计算节点上的MPI资源,组合成一个较大的分布式/并行系统。
8.2 IPython并行计算架构
IPython并行计算架构有三个主要组成部分。这些组成部分是IPython并行程序包的部件。IPython并行计算架构如下图所示。
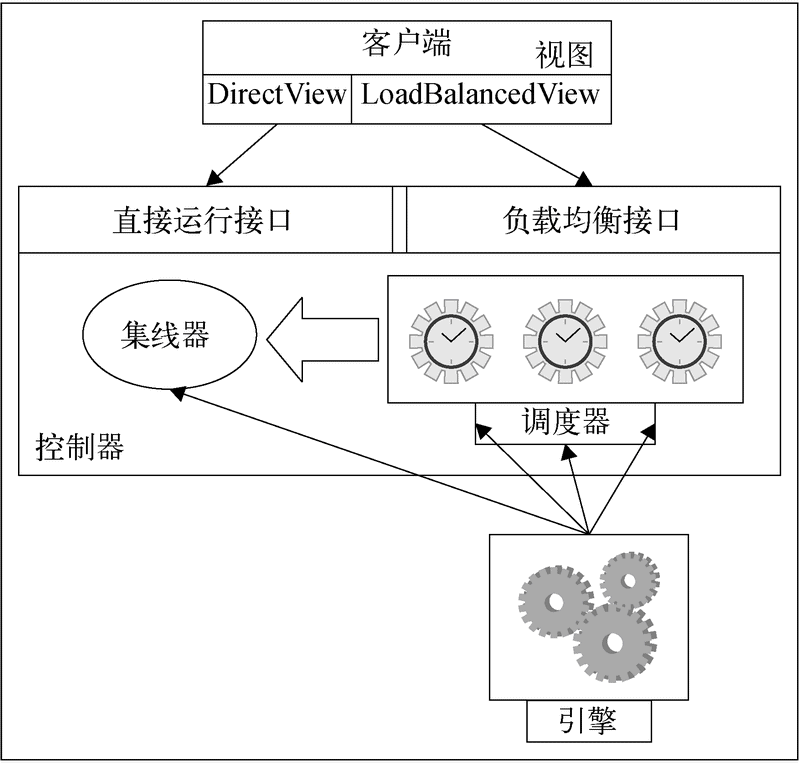
IPython并行计算的三个主要部分是客户端、控制器和引擎。控制器由两部分组成:集线器和调度器。客户端与引擎的交互可以通过两种方式实现:直接运行接口和负载均衡接口。
并行计算的组成部分
IPython并行计算架构的组件和内容将在下面介绍。这些组件包括IPython引擎、IPython控制器(集线器和调度器)、IPython客户端与IPython视图。
1. IPython引擎
这个核心组件以网络请求的形式接受要执行的Python代码。引擎是一个普通Python解释器的实例,最终将会演变成一个功能健全的IPython解释器。用户可以通过启动多个引擎来实现分布式计算与并行计算。用户输入的代码在IPython中以阻断模式运行。
2. IPython控制器
IPython控制器是由一个集线器和若干个调度器构成的。IPython控制器绑定了客户端与引擎通信的多个进程。它是连接运行Python进程的用户与IPython引擎的枢纽。通常情况下,调度器都是运行集线器的计算机上的独立进程。有时,调度器也可以运行在远程计算机上。
集线器:集线器是最重要的组件。它会持续跟踪调度器与客户端以及与引擎的连接信息。它会处理客户端与引擎的所有连接以及整个网络的通信需求。它还会用数据库保存所有的请求和计算结果,以备后面的程序使用。集线器还提供了查询集群状态的功能,并为用户隐藏客户端与引擎连接的大量细节。
调度器:提交给引擎处理的Python代码,都是通过调度器传递的。调度器还解决了引擎执行用户代码时造成的阻塞问题。调度器为用户隐藏这些细节,并通过完全异步的连接方式连接IPython引擎。
3. IPython视图与接口
控制器提供了两种接口模式与引擎通信。第一种是Direct(直接运行)接口。在这种模式下引擎会把任务直接分配到固定地址运行。另一种是LoadBalanced(负载均衡)接口,适当地分配任务到空闲的调度器。IPython的灵活设计可以让我们对视图进行扩展,以实现更加复杂的接口机制。
不同的模式连接到控制器时,会产生一个view对象。两种模式通过控制器与机器进行交互的方法如下。
DirectView类支持直接分配地址。它可以让用户代码在所有引擎上运行。LoadBalancedView类会帮助用户以负载均衡的方式对任务进行分配。它可以让用户程序运行在调度器指定的任意一个引擎上。
4. IPython客户端
客户端是一种用于连接IPython计算集群的对象。创建客户端对象的时候,用户可以选择前面介绍的任意一种视图。一旦客户端创建之后,只要任务在运行,它就会一直存在。当客户端运行达到规定时限,或者用户通过kill命令中止客户端进程,它就会被销毁。
8.3 并行计算示例
下面的例子是演示IPython并行计算的简单程序。它将对比单引擎与多引擎并行计算指数函数(a的b次方)的效率。运行代码之前,建议你检查一下zmq软件包是否已经安装,它是必需的。
要在IPython里启动并行程序,首先需要执行ipcluster start --n=4 --profile= testprofile命令。首先需要在/.ipython/profile_testprofile/security目录下创建ipcontroller-engine. json和ipcontroller-client.json文件。创建客户端时加上profile='testprofile'参数,就会搜索这些文件。如果我们用parallel.Client()命令创建客户端,就会在profile_default文件夹里搜索JSON文件。
首先程序创建一个计算指数的函数,然后创建一个单引擎的客户端。要在引擎中调用Python函数,可以使用客户端或视图的apply方法。Python的map函数可以对序列对象进行映射计算。DirectView和LoadBalancedView里的map函数可以对序列进行并行计算。我们可以用阻塞和非阻塞两种模式运行。在阻塞模式下,我们将参数block设置为true,默认值是false:
from IPython import paralleldef pow(a, b):return a ** bclients = parallel.Client(profile='testprofile')print clients.idsclients.block = Trueclients[0].apply(pow, 2, 4)clients[:].apply(pow, 2, 4)map(pow, [2, 3, 4, 5], [2, 3, 4, 5])view = clients.load_balanced_view()view.map(pow, [2, 3, 4, 5], [2, 3, 4, 5])
8.3.1 并行装饰器
在DirectView里有一个装饰器可以创建parallel并行函数。这个函数在序列上运行,首先会打破原有的次序,之后并行计算每个元素的函数值,最后再把结果按顺序重组。LoadBalancedView的装饰器也可以把Python程序转换成parallel函数:
from IPython import parallelclients = parallel.Client(profile='testprofile')lbview = clients.load_balanced_view()lbview.block = Trueserial_computation = map(lambda i:i**5, range(26))parallel_computation = lbview.map(lambda i: i**5, range(26))@lbview.parallel()def func_turned_as_parallel(x):return x**8func_turned_as_parallel.map(range(26))
8.3.2 IPython的魔法函数
IPython有许多魔法函数,用户可以像命令一样使用它们。IPython有两种魔法函数,分别是行魔法函数(line magic,单行语句)和单元魔法函数(cell magic,多行语句)。行魔法函数是在前面加%,功能如同操作系统命令。单元魔法函数是在前面加%%,它们会把这一行和后面的代码看成一体,与其他代码区别对待。
当用户创建了客户端之后,就可以使用魔法函数了。部分行魔法函数介绍如下。
%px:可以让指定的引擎运行一个Python命令。用户可以通过设置视图实例的target属性来选择引擎。%pxconfig:即使我们没有任何激活的视图,也可以用pxconfig魔法函数加--targets、--block和--noblock参数选择引擎。%autopx:这是一个有弹性的魔法函数,可以自动选择并行和非并行模式。第一次调用时,它会把终端切换成一种能够让所有命令和函数以并行模式运行的状态,直到用户再次调用autopx函数才结束。%pxresult:在非阻塞模式下,%px函数不会返回计算结果。可以用pxresult魔法函数看到最新的结果。
在单元魔法函数模式下,px(%%px)魔法函数可以通过--targets选项设置目标引擎,--block或--noblock选项设置阻塞或非阻塞执行模式。当我们没有启动视图实例时,这些参数非常有用。另外还有--group-output选项,可以管理多个引擎的输出结果。
下面的程序将演示px与pxresult作为行魔法函数和单元魔法函数的用法。还演示了autopx和pxconfig行魔法函数,以及为这些行魔法函数创建具体后缀的方法。程序第二行和第三行向IPython会话以及所有引擎导入了模块numpy。第二行语句后面导入的所有模块都会在引擎上运行:
from IPython import paralleldrctview = clients[:]with drctview.sync_imports():import numpyclients = parallel.Client(profile='testprofile')drctview.activate()drctview.block=True%px dummymatrix = numpy.random.rand(4,4)%px eigenvalue = numpy.linalg.eigvals(dummymatrix)drctview['eigenvalue']%pxconfig --noblock%autopxmaximum_egnvals = []for idx in range(50):arr = numpy.random.rand(10,10)egnvals = numpy.linalg.eigvals(arr)maximum_egnvals.append(egnvals[0].real)%autopx%pxconfig --block%px answer= "The average maximum eigenvalue is: %f"%(sum(maximum_\egnvals)/len(maximum_egnvals))dv['answer']%%px --block --group-outputs=engineimport numpy as nparr = np.random.random (4,4)egnvals = numpy.linalg.eigvals(arr)print egnvalsegnvals.max()egnvals.min()odd_view = clients[1::2]odd_view.activate("odd")%px print "Test Message"oddview.block = True%px print "Test Message"clients.activate()%px print "Test Message"%px_odd print "Test Message"
1. 激活视图
默认情况下,魔法函数与DirectView对象有对应关系(一个对象使用一类魔法函数)。用户可以在任意一个视图中调用activate()方法改变DirectView对象。激活视图时,我们可以添加一个新后缀名,比如定义成odd_view.activate("_odd")。对于这个视图,在原始的魔法函数基础上就生成了一个新的魔法函数,例如%px_odd,在前面程序的最后一行使用。
2. 引擎与Qt终端
px魔法函数可以让用户把Qt终端连接到引擎上,方便代码调试。下面的程序演示了利用bind_kernel将Qt终端与引擎连接,监听一个连接的信息:
%px from IPython.parallel import bind_kernel; bind_kernel()%px %qtconsole%px %connect_info
8.4 IPython的高级特性
下面将介绍IPython的一些高级特性。
8.4.1 容错执行
默认情况下,IPython的引擎是可以容错并动态负载均衡的集群系统。在任务接口里的客户端不会直接连接到引擎。任务都是通过调度器分配的,这样可以保证接口设计得简单、灵活、强大。
在IPython中如果一个任务失败了,就会重新排队并尝试再次启动。用户可以设置任务失败重新启动的次数,以及设置重新提交任务给其他引擎。
如果有需要,可以显式地重新提交任务。也可以为任务重试次数设置一个标示——设置一个视图或调度器标示即可。
如果用户确信任务失败不是代码问题,那么重试次数可以设置为1到引擎数量之间的任意整数值。
之所以将最大重试次数限制为引擎数量,是因为任务不会被再次提交给已经运行失败的引擎。
设置重新提交标示的方法有两种。一种是用LoadBalancedView对象(假设名称是lbvw)设置重试次数,如下所示:
lbvw.retries = 4
另一种方法是用with …temp_flags代码块设置,像这样:
with lbvw.temp_flags(retries=4):lbview.apply(task_tobe_retried)
8.4.2 动态负载均衡
调度器可以按照不同的调度策略进行配置。在动态负载均衡时,IPython可以使用许多调度机制对任务进行分配,同时也可以对调度机制进行自定义。选择一种调度机制的方法有两种。一是设置config对象的taskSchedulerscheme_name属性,二是通过ipcontroller的参数进行配置:
ipcontroller --scheme=<schemename>
示例如下:
ipcontroller --scheme=lru
这里的
lru:最近用过的(Least Recently Used,LRU)是一种将任务分配给刚刚使用过的引擎的调度方式。plainrandom:这种方式是随机选择一个引擎运行任务。twobin:这种方式是用NumPy函数分配任务。它是plainrandom和lru的组合形式,首先随机选择两个引擎,然后选择两者中最近用过的引擎。leastload:这是调度器的默认调度机制。它会选择负载最小的引擎(即当前运行任务数量最少的引擎)运行任务。weighted:这是twobin调度机制的加权版本。首先随机选择两个引擎,然后以引擎负载数量或未完成的任务数量作为权重,再选择权重低(即负载数量较少)的引擎。
8.4.3 在客户端与引擎之间推拉对象
除了在引擎上调用函数并运行代码,IPython还允许用户在引擎和客户端之间移动Python对象。push方法是客户端向引擎推送对象,pull方法是客户端逆向从引擎拉回对象。在非阻塞模式下,push和pull方法都会返回AsyncResult对象。要在非阻塞模式下返回结果,可以这样拉回对象1:rslt = drctview.pull(('a','b','c'))。可以调用rslt.get()方法显示拉取对象的值。有时,把输入数据序列分割成几块,然后推送给不同的引擎是非常有效的做法。这种分割方法可以用scatter和gather函数来实现,类似于MPI的方式。scatter操作是从客户端(IPython会话)把分割序列推送给引擎,gather操作是把分割对象从引擎拉回到客户端。
1IPython结果是在引擎中计算出来的。——译者注
这些功能全部通过下面的程序进行演示。在程序最后,通过scatter和gather函数来实现并行计算两个矩阵的点乘运算。
import numpy as npfrom IPython import parallelclients = parallel.Client(profile='testprofile')drctview = clients[:]drctview.block = Truedrctview.push(dict(a=1.03234,b=3453))drctview.pull('a')drctview.pull('b', targets=0)drctview.pull(('a','b'))drctview.push(dict(c='speed'))drctview.pull(('a','b','c'))drctview.block = Falserslt = drctview.pull(('a','b','c'))rslt.get()drctview.scatter('a',range(16))drctview['a']drctview.gather('a')def paralleldot(vw, mat1, mat2):vw['mat2'] = mat2vw.scatter('mat1', mat1)vw.execute('mat3=mat1.dot(mat2)')return vw.gather('mat3', block=True)a = np.matrix('1 2 3; 4 5 6; 7 8 9')b = np.matrix('4 5 6; 7 8 9; 10 11 12')paralleldot(drctview, a,b)
下面的程序演示了首先从客户端向引擎推送对象,然后从引擎拉回结果到客户端。程序在所有引擎上计算两个矩阵的点乘,再收集结果。同时,程序还通过allclose()方法证明结果都是一样的,如果都一样就会返回True。在程序的execute命令中,添加print mat3语句是为了后面用display_outputs()函数在屏幕上显示所有引擎的输出结果:
import numpy as npfrom IPython.parallel import Clientndim = 5mat1 = np.random.randn(ndim, ndim)mat2 = np.random.randn(ndim, ndim)mat3 = np.dot(mat1,mat2)clnt = Client(profile='testprofile')clnt.idsdvw = clnt[:]dvw.execute('import numpy as np', block=True)dvw.push(dict(a=mat1, b=mat2), block=True)rslt = dvw.execute('mat3 = np.dot(a,b); print mat3', block=True)rslt.display_outputs()dot_product = dvw.pull('mat3', block=True)print dot_productnp.allclose(mat3, dot_product[0])np.allclose(dot_product[0], dot_product[1])np.allclose(dot_product[1], dot_product[2])np.allclose(dot_product[2], dot_product[3])
8.4.4 支持数据库存储请求与结果
IPython集线器会存储任务请求与结果给后面的程序使用。默认情况下,它都使用SQLite数据库,现在还支持MongoDB数据库和一种叫DictDB的内存数据库。用户可以在配置文件里设置数据库类型。在配置文件夹里,有一个ipcontroller_config.py文件。可以通过ipcluster命令启动配置文件。文件里有c.HubFactory.db_class选项,用户可以设置自己想用的数据库,如下所示:
# 配置dictdb,字典形式内存数据库c.HubFactory.db_class = 'IPython.parallel.controller.dictdb.DictDB'# 配置MongoDB:c.HubFactory.db_class = 'IPython.parallel.controller.mongodb.MongoDB'# 配置SQLite:c.HubFactory.db_class = 'IPython.parallel.controller.sqlitedb.SQLiteDB'
默认属性值是NoDB,表示没使用任何数据库。如果用户想获取任何已执行任务的结果,可以在客户端对象上调用get_result函数。不过客户端对象还有一个更好的函数db_query()。这个方法是按照MongoDB查询方式设计的,它通过一个词典对象查询,词典的键就是带准确值的TaskRecord键,或者MongoDB的查询。这些参数的语法是按照{'operator' : 'argument (s)'}这类形式。还有一个可选的参数,名字是keys。这个参数用于指定需要获取的键。它会返回一个TaskRecord词典列表。默认情况下,会返回所有的键,除了引擎缓存中的请求和结果。与MongoDB类似,msg_id键也会出现在里面。一些TaskRecord键的含义解释如下。
msg_id:这个值是uuid(字节)类型, 表示消息的ID。header:这个值是dict类型,存放请求头信息。content:这个值是dict类型,存放请求内容,通常为空。buffers:这个值是list(字节)类型, 请求对象的缓存列表。Submitted:这个值是datetime类型,存放任务的时间戳。client_uuid:客户端的uuid值(universally unique identifier,通用唯一标识符)。engine_uuid:这个值是uuid(字节)类型,计算引擎套接字的uuid值。started:这个值是datetime类型,存放引擎开始计算的时间。completed:这个值是datetime类型,存放引擎完成计算的时间。resubmitted:这个值是datetime类型,存放引擎(异常中断后)恢复计算的时间。result_header:这个值是dict类型,存放计算结果的请求头。result_content:这个值是dict类型,存放计算结果的内容。result_buffers:这个值是list(字节)类型,计算结果对象的缓存列表。queue:这个值是bytes类型,任务队列的名称。stdout:标准输出(standard output)数据流。stderr:标准错误(standard error)数据流。
下面的程序演示了db_query()和get_result()获取结果的用法。
from IPython import parallelfrom datetime import datetime, timedeltaclients = parallel.Client(profile='testprofile')incomplete_task = clients.db_query({'complete' : None}, keys=['msg_\id', 'started'])one_hourago = datetime.now() - timedelta(1./24)tasks_started_hourago = clients.db_query({'started' : {'$gte' : one_\hourago },'client_uuid' : clients.session.session})tasks_started_hourago_other_client = clients.db_query({'started': {'$le' : hourago }, 'client_uuid' : {'$ne' : clients.session.session}})uuids_of_3_n_4 = map(clients._engines.get, (3,4))headers_of_3_n_4 = clients.db_query({'engine_uuid' : {'$in' : uuids_\of_3_n_4 }}, keys='result_header')
下面是db_query方法里可用的关系运算符,与MongoDB一样。
'$in':元素在列表/序列中。'$nin':元素不在列表/序列中。'$eq':表示等于(==)。'$ne':表示不等于(!=)。'$gt':表示大于(>)。'$gte':表示大于等于(>=)。'$lt':表示小于(<)。'$lte':表示小于等于(<=)。
8.4.5 在IPython里使用MPI
通常,多引擎的并行算法都需要在引擎之间进行数据交换。我们在前面已经介绍了IPython数据交换的方法。然而,因为那不是引擎与客户端的直接数据交换方式,数据都需要经过控制器的调度,所以速度比较慢。另一种高性能的数据交互方式是通过MPI。IPython并行计算架构可以完美支持MPI。要在IPython用MPI实现并行计算,需要安装OpenMPI或MPICH2/MPICH和mpi4py软件包。安装之后,可以通过mpiexec和mpirun命令检测是否安装成功。
安装测试完成之后,在运行真正的MPI程序之前,用户需要创建一个配置文件:
ipython profile create --parallel --profile=mpi
配置文件创建之后,把下面这行代码加入profile_mpi文件夹的ipcluster_config.py文件中:
c.IPClusterEngines.engine_launcher_class = 'MPIEngineSetLauncher'
现在系统已经可以在IPython上运行MPI程序了。用户可以通过下面的命令启动计算集群:
ipcluster start -n 4 --profile=mpi
上面的命令会启动IPython控制器,并通过mpiexec命令启动四个引擎。
下面的程序定义了一个函数,分布式计算一个数组的和。把程序命名为parallelsum.py,它将在后面程序中使用:
from mpi4py import MPIimport numpy as npdef parallelsum(arr):localsum = np.sum(arr)receiveBuffer = np.array(0.0,'d')MPI.COMM_WORLD.Allreduce([localsum, MPI.DOUBLE],[receiveBuffer, MPI.DOUBLE],op=MPI.SUM)return receiveBuffer
在下面的程序中使用前面定义的函数,在多个引擎上计算。下面就是并行数组求和的程序:
from IPython.parallel import Clientclients = Client(profile='mpi')drctview = clients[:]drctview.activate()# 将程序的文件名作为参数运行计算drctview.run(parallelsum.py.py')drctview.scatter('arr',np.arange(20,dtype='float'))drctview['arr']# 调用函数%px sum_of_array = parallelsum(arr)drctview['sum_of_array']
8.4.6 管理任务之间的依赖关系
IPython对任务之间依赖关系的管理有着强有力的支持。在大多数科学与商业计算领域,仅仅负载均衡不足以解决计算的复杂性。应用还需要管理任务之间的依赖关系。这些依赖包括计算过程中需要的软件、Python模块、操作系统、硬件,在一群任务中执行单个任务所需的运行顺序、时间、空间。IPython支持两种依赖关系管理方式:函数依赖(functional dependency)和图依赖(graph dependency)。
1. 函数依赖关系
函数依赖用于确定一个引擎是否有能力运行一个任务。这个概念通过IPython.parallel.error里的一个UnmetDependency异常实现。如果任务运行失败并触发UnmetDependency异常,调度器不会把异常发送到客户端,而是自动处理异常并把失败任务提交到其他引擎上。调度器会重复这个过程直到找出适合的引擎。另外,调度器不会向同一个引擎提交两次。
函数依赖装饰器
虽然用户也可以手动触发UnmetDependency异常,但是IPython还是提供了两个装饰器来管理依赖关系。
@require:这个装饰器管理那些当被装饰函数被调用时,需要在引擎里使用特殊的Python模块、局部函数或局部对象的任务的依赖关系。函数将通过名称推送到引擎里,对象可以通过arg关键词传递。我们可以传递执行任务需要的所有Python模块的名称。通过这个装饰器,用户可以自定义一个函数,只在那些装饰器里的模块名称是可用的、可导入的引擎上运行。
例如,下面代码中的函数依赖NumPy和pandas模块,里面需要使用NumPy的randn和pandas的Series。假如有个任务需要调用该函数,那么该函数会在已经导入这两个模块的机器上运行。一旦函数被调用,NumPy和pandas模块就会导入:
from IPython.parallel import depend, require# 下面函数用randn和Series@require('pandas', 'numpy')def func_uses_functions_from_numpy_pandas():return performactivity()
@depend:这个装饰器让用户可以定义一个与其他函数有依赖关系的函数。它可以判定依赖关系是否满足。在任务运行之前,依赖函数先被调用。如果函数返回true,那么任务的执行过程就会开始。如果依赖函数返回false,说明依赖关系未得到满足,于是任务将被分配给其他引擎。
下面的代码块创建了一个依赖函数,检查引擎的操作系统是否匹配当前操作系统。这么做是因为用户想写两个不同的函数,分别在Linux和Windows操作系统上完成不同的任务:
from IPython.parallel import depend, requiredef find_operating_system(plat):import sysreturn sys.platform.startswith(plat)@depend(find_operating_system, 'linux')def linux_specific_task():perform_activity_on_linux()@depend(find_operating_system, 'win')def linux_specific_windows():perform_activity_on_windows()
2. 图依赖关系
这是另一种重要的依赖关系,任务彼此之间相互依赖,当若干或所有任务都已经成功运行后,一个任务才运行。还有一种依赖关系是:一个任务必须在指定的若干依赖已经得到满足时才执行。一般情况下,用户在执行任务之前,需要设置具体的时间和位置,也作为其他任务的时间、位置和结果的函数。Dependency类是IPython管理图依赖关系的专用类,Dependency是Set类的子类。它包括任务的信息ID号和一些属性。这些属性可以帮助用户检查依赖关系是否得到满足。
any|all:这些属性决定每个依赖是否都需要满足。所有依赖设置的默认值都是True。success:这个属性的默认值是True,表示如果指定的任务成功地运行,就认为依赖关系得到了满足。failure:这个属性的默认值是False,表示如果指定的任务运行失败,就认为依赖关系得到了满足。after:这个属性表示指定的任务运行之后,应执行相关任务。follow:follow属性表示指定的任务应该与依赖任务一样,在同一位置运行。timeout:这个属性表示调度器等待依赖被满足的时限要求。默认是0,表示任务可以无限等待依赖。当超过时限要求之后,会触发DependencyTimeout异常,对应的任务运行失败。
有一些任务的功能是清理失败任务。只有指定任务运行失败时,它们才会启动。用户需要用failure=True,success=False来启动这些任务。对于一些有依赖关系的任务,需要那些依赖关系都完全得到满足。在这种情况下,用户需要把函数设置成success=True和failure=False。有时用户也需要有依赖关系的任务可以独立地运行,不去考虑依赖任务运行的成功与失败。这时,用户需要设置函数为success=failure=True。
3. 不可能满足的依赖关系
有一些依赖关系不可能满足。如果调度器搞不定这些依赖关系,它就会一直傻傻地等啊等,期待着依赖关系被满足,这显然不合理。为了解决这个问题,调度器会提前分析图依赖关系,评估依赖关系可以满足的可能性。如果调度器经过评估发现依赖关系不可能得到满足,就会触发ImpossibleDependency错误。下面的程序演示了如何管理任务之间的图依赖关系:
from IPython.parallel importclients = ipp.Client(profile='testprofile')lbview = clients.load_balanced_view()task_fail = lbview.apply_async(lambda : 1/0)task_success = lbview.apply_async(lambda : 'success')clients.wait()print("Fail task executed on %i" % task_fail.engine_id)print("Success task executed on %i" % task_success.engine_id)with lbview.temp_flags(after=task_success):print(lbview.apply_sync(lambda : 'Perfect'))with lbview.temp_flags(follow=pl.Dependency([task_fail, task_success], failure=True)):lbview.apply_sync(lambda : "impossible")with lbview.temp_flags(after=Dependency([task_fail, task_success], failure=True, success=False)):lbview.apply_sync(lambda : "impossible")def execute_print_engine(*flags):for idx in range(4):with lbview.temp_flags(**flags):task = lbview.apply_async(lambda : 'Perfect')task.get()print("Task Executed on %i" % task.engine_id)execute_print_engine(follow=Dependency([task_fail, task_success], all=False))execute_print_engine(after=Dependency([task_fail, task_success], all=False))execute_print_engine(follow=Dependency([task_fail, task_success], all=False, failure=True, success=False))execute_print_engine(follow=Dependency([task_fail, task_success], all=False, failure=True))
4. DAG依赖关系与NetworkX函数库
一般情况下,用有向无环图(Directed Acyclic Graph,DAG)表示并行工作流更合适。Python的知名画图程序库是NetworkX。有向无环图是由节点和有向边组成的。边连接不同的节点,每条边都有方向。我们可以用这个概念表示依赖关系。例如,edge(task1, task2)是从任务1到任务2的边,表示任务2依赖于任务1。而edge(task2, task1)表示任务1依赖于任务2。这个图里不能有环,所以称为无环图。
下面让我们看看一个六节点DAG。任务0不依赖于任何任务,所以它可以立即执行。但是,任务1和任务2依赖于任务0,因此它们会在任务0完成之后运行。而任务3依赖于任务1和任务2,因此它在任务1和任务2运行结束之后才会运行。同理可得,任务4和任务5在任务3运行结束之后才会运行。任务6仅仅依赖任务4,因此它会在任务4运行完成后运行。
下面的程序是上面DAG的描述。程序中,任务用数字表示,任务0用0表示,任务1用1表示,以此类推:
import networkx as ntwrkximport matplotlib.pyplot as pltdemoDAG = ntwrkx.DiGraph()map(demoDAG.add_node, range(6))demoDAG.add_edge(0,1)demoDAG.add_edge(0,2)demoDAG.add_edge(1,3)demoDAG.add_edge(2,3)demoDAG.add_edge(3,4)demoDAG.add_edge(3,5)demoDAG.add_edge(4,6)pos = { 0 : (0,0), 1 : (-1,1), 2 : (1,1), 3 : (0,2), 4 : (-1,3), 5 : (1, 3), 6 : (-1, 4)}labels={}labels[0]=r'$0$'labels[1]=r'$1$'labels[2]=r'$2$'labels[3]=r'$3$'labels[4]=r'$4$'labels[5]=r'$5$'labels[6]=r'$6$'ntwrkx.draw(demoDAG, pos, edge_color='r')ntwrkx.draw_networkx_labels(demoDAG, pos, labels, font_size=16)plt.show()
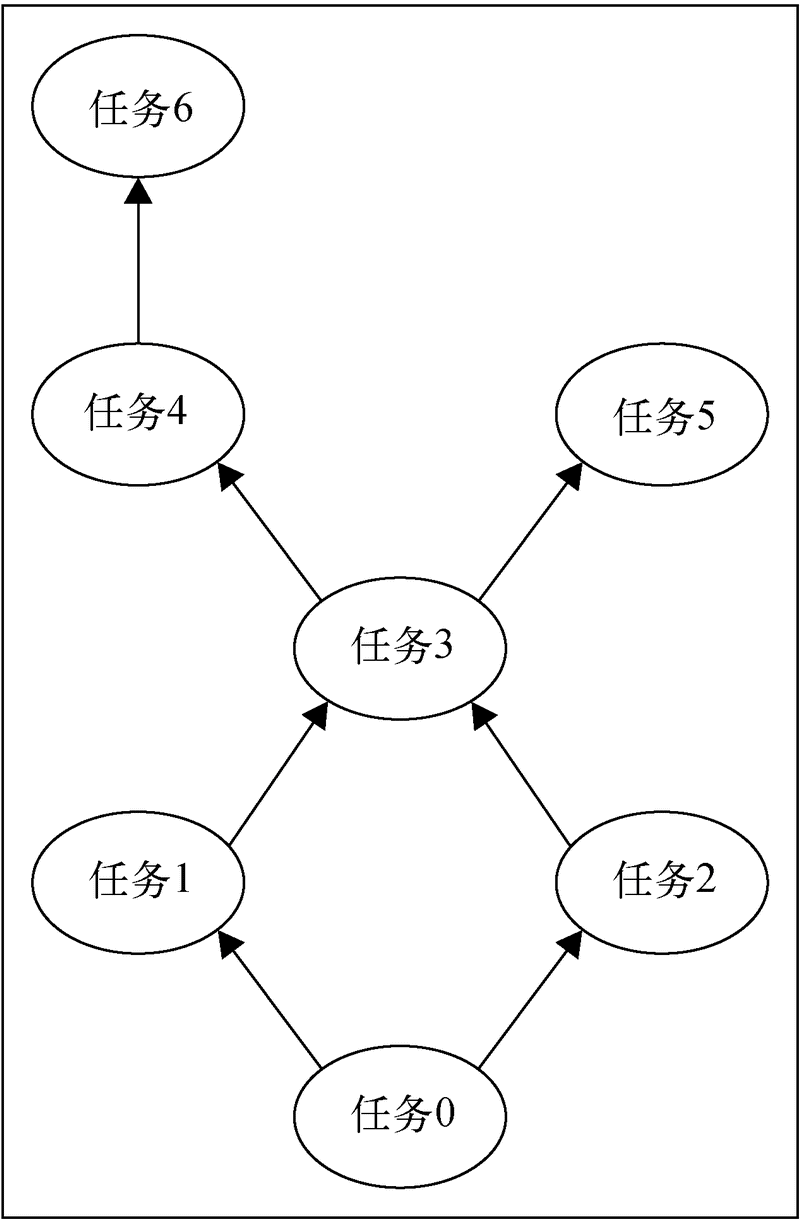
下面的程序创建了带颜色的DAG,顶点会显示任务的名称:
import networkx as ntwrkximport matplotlib.pyplot as pltdemoDAG = ntwrkx.DiGraph()map(demoDAG.add_node, range(6))pos = {0: (0, 0), 1: (-1, 1), 2: (1, 1), 3: (0, 2), 4: (-1, 3),5: (1, 3), 6: (-1, 4)}ntwrkx.draw(demoDAG, pos)ntwrkx.draw_networkx_edges(demoDAG, pos, edgelist=[(0, 1), (0, 2),(1, 3), (2, 3), (3, 4)], edge_color='r')ntwrkx.draw_networkx_edges( \demoDAG, pos, edgelist=[(3, 5), (4, 6)], edge_color='b')ntwrkx.draw_networkx_nodes(demoDAG, pos, nodelist=[0, 1, 2, 3, 4],node_color='r', nodesize=500, alpha=0.8)ntwrkx.draw_networkx_nodes(G, pos, nodelist=[5, 6], node_color='b', node_size=500, alpha=0.8)labels = {}labels[0] = r'$0$'labels[1] = r'$1$'labels[2] = r'$2$'labels[3] = r'$3$'labels[4] = r'$4$'labels[5] = r'$5$'labels[6] = r'$6$'ntwrkx.draw_networkx_labels(demoDAG, pos, labels, font_size=16)plt.show()
8.4.7 用Amazon EC2的StarCluster启动IPython
Amazon的StarCluster可以在Amazon的弹性计算云(Elastic Compute Cloud,EC2)上非常方便地使用虚拟机计算集群。StarCluster是一个开源工具箱,用于在Amazon EC2上进行集群计算。除了自动配置集群计算之外,StarCluster还可以自定义Amazon机器镜像(Amazon Machine Images,AMIs),支持安装科学计算和软件开发的工具和程序库。这些AMI可以由ATLAS、IPython、NumPy、OpenMPI、SciPy等软件组成。用户可以在安装了StarCluster的机器上通过下面的命令获取AMI列表:
starcluster listpublic
StarCluster的操作界面十分简单直观,方便管理计算集群和存储空间。安装完之后,用户需要更新配置文件,加入Amazon EC2的账户信息,包括IP地址、地区、证书、公私密钥对。
安装配置完成之后,用户可以通过下面的命令控制Amazon EC2安装IPython:
starcluster shell --ipcluster=clusterName
如果安装过程出现任何错误,上面的命令都会提示。如果配置正确,命令就会启动StarCluster命令行并在Amazon EC2的远程集群上创建并行会话任务。StarCluster会根据ipclient变量内容作为名称,创建并行客户端,并以ipview变量内容为名称创建整个计算集群的视图。用户可以通过这些变量(ipclient和ipview)在Amazon EC2集群上运行并行任务。下面的程序用ipclient显示引擎的ID号,并用ipview执行了一个简单的并行任务:
ipclient.idsresult = ipview.map_async(lambda i: i**5, range(26))print result.get()
用户还可以通过StarCluster运行IPython并行脚本。如果用户想通过本地的IPython会话运行Amazon EC2远程集群上的并行脚本,那么创建并行客户端时需要在本地进行一些配置:
from IPython.parallel import Clientremoteclients = Client('<userhome>/.starcluster/ipcluster/<clustername>-<yourregion>.json', sshkey='pathto/cluster/keypair.rsa')
举例说明,假如集群名称是packtcluster,地区名称是us-west-2,密钥keypair的名称是packtKey,文件路径为homeuser/.ssh/packtKey.rsa。那么上面的代码将改为如下形式:
from IPython.parallel import Clientremoteclients = Client('homeuser/.starcluster/ipcluster/packtcluster-us-west-2.json', sshkey='homeuser/.ssh/packtKey.rsa')
这三行代码运行之后,其他代码就可以在Amazon EC2的远程集群上运行了。
8.5 IPython数据安全措施
在设计IPython架构时,也十分重视网络安全问题。客户端认证模型是通过SSH加密的TCP/IP连接,可以管理大部分的安全问题,方便用户在公网使用IPython计算集群。
由于ZeroMQ没有提供网络安全功能,因此使用SSH加密隧道保证安全连接。Client对象通过ipcontroller-client.json文件获取与控制器的连接,然后通过OpenSSH/Paramiko创建加密连接隧道。
它还使用了HMAC签名信息的概念,通过共享键保护用户在共享机器上的数据。有一个专门的会话对象处理签名信息的协议。会话对象通过唯一键验证消息的有效性。默认情况下,键使用128位伪随机数,类似于uuid.uuid4()生成的数据。一般情况下,IPython客户端在并行计算过程中,会向IPython引擎发送Python函数、命令和数据。IPython可以保证只有认证的客户端可以接入并使用引擎。引擎的能力和权限也完全是启动它的用户授予的。
为了阻止未经授权的接入,认证和键相关信息都是JSON文件格式,让IPython客户端接入控制器。用户可以限制键的接入数量,以控制授权用户的数量。
8.5.1 常用并行编程方法
随着计算机软硬件性价比的不断提升,并行程序可以通过多种形式设计、开发与实现。我们可以通过并发、并行和分布式三种方式实现。前面提到的任何一种技术都可以实现高效运行的高性能程序。下面将介绍这些模式以及与它们相关的共同问题。
1. 并行编程经典问题
所有模式都是在不同的计算单元(CPU与计算节点)中执行程序的不同部分。一般情况下,这些模式都是把程序分成多个worker进程,每个worker进程都在不同的计算单元上运行。如果不考虑这些模式的性能,这种使用多个worker进程的程序执行方式会造成不同任务间通信困难。这个问题就是典型的进程间通信(Inter-process Communication,IPC)问题。
一些经典的IPC问题需要开发者时刻注意,如死锁(deadlock)、饥饿(starvation)和竞争状态(race condition)。
- 死锁
死锁是指两个或多个worker进程处于无限制的等待状态,等待其他worker进程释放正在占用的资源。死锁有四个充分必要条件,分别是相互排斥(mutual exclusion)、持有等待(hold and wait)、非抢占式(no pre-emption)以及循环等待(circular wait)。如果程序在运行过程中出现了以上四种条件,就会被阻塞,不能继续运行。
相互排斥是指资源是不能共享的,只能一个worker进程使用。
持有等待是指死锁的worker进程持有部分资源,并请求其他资源到来。
非抢占式是指已经分配给一个worker进程的资源不能再分配给其他worker进程使用。
循环等待是指程序中等待资源的worker进程形成了一个链或循环列表,其中每一个worker进程都在等待前一个worker进程释放资源。
- 饥饿
当多个worker进程争抢一个资源时就会发生饥饿(游戏)状态。这时,每个worker进程都被配置了一个获取资源的优先级。有时,优先级分配得不合理,就会导致一些worker进程等待时间非常长。在这种情况下共有两种worker进程在竞争:高优先级的worker进程和低优先级的worker进程。如果高优先级的worker进程连续地请求资源,就会导致低优先级的worker进程陷入无限漫长的等待。
- 竞争状态
当多个worker进程同时对一块数据进行读/写操作时,每个worker进程的操作之间没有同步,就会出现竞争状态。例如,两个worker进程同时读取数据库的一块数据,修改数据值,然后再写回数据库。如果没有合理的同步顺序,那么数据库就会出现前后不一致的状态。
有一些方法可以解决这些问题,不过那些方法的具体内容超出了本书的介绍范围。如果感兴趣的话,可以看看其他相关的多核编程书籍。下面来介绍并行计算的各个类型。
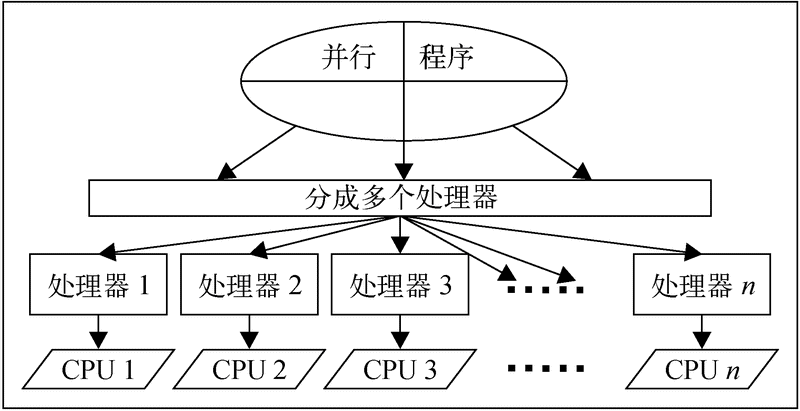
2. 并行编程
在并行程序的开发模式中,程序被分成多个worker进程运行在多个独立的CPU上,无需竞争一个CPU的资源,如下图所示。这些CPU可以是一台计算机的多核处理器,也可以是在多台单独的计算机上,通过消息传递接口连接。
3. 并发编程
在并发编程模式中,用户程序的多个worker进程运行在一个CPU或者数量少于worker进程数量的CPU上(如下图所示)。这些worker进程会在CPU调度器的管理下争抢CPU资源。CPU调度器会用不同的调度机制分配worker进程给CPU。CPU调度器机制会创建worker进程的级别,worker进程将按照级别的次序运行。
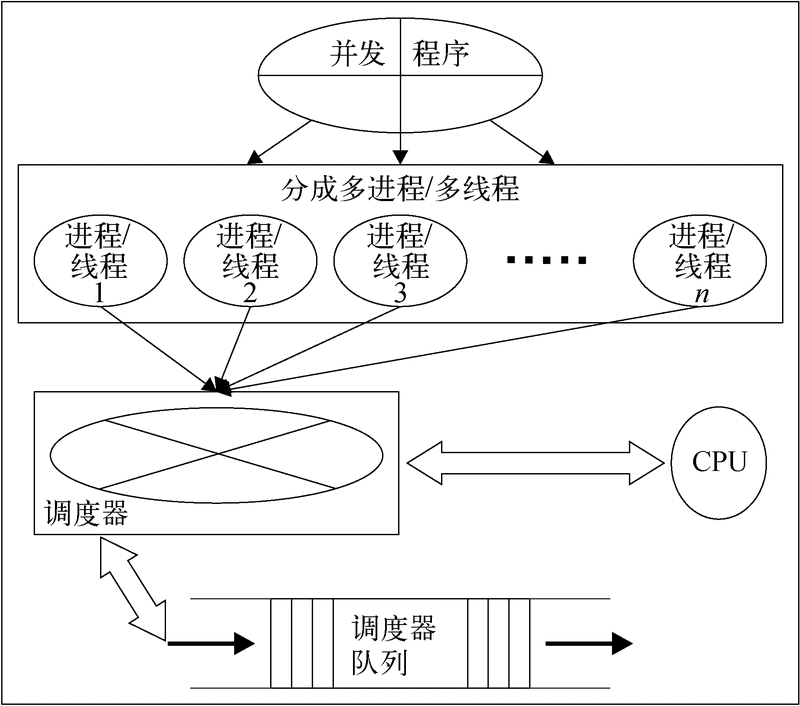
并发编程模式中的worker进程,一般都用多进程或多线程来实现。进程或线程都并发地完成主程序的一部分。线程与进程的主要区别在于:线程是内存共享的,占用资源少,一个进程可以生成多个线程。因此,线程也被称为轻量级进程。
4. 分布式编程
在分布式编程模式中,worker进程通过网络在不同的机器上运行。有不同的框架执行这类程序。网络还会用不同的拓扑结构,在有些情景中,调度机制数据和处理过程都是分布式的。这种并行计算模式越来越受欢迎,因为它优点明显,比如单个节点成本低、容错效果好、高度扩展性,等等。在分布式计算模式中,每个节点都有独立的内存和处理器资源,而在并行编程模式中,处理器/CPU共享同样的内存资源。
分布式程序的运行
5. Python多进程
Python多进程可以在多核电脑的多个CPU上创建和运行多个独立运行的进程。Python提供了两个重要的模型支持多进程:一种是基于Process类,另一种是基于Pool类。
下面的程序演示了用Process类实现多进程:
import multiprocessing as mpcsimport randomimport stringoutput_queue = mpcs.Queue()def strings_random(len, output_queue):generated_string = ''.join(random.choice(string.ascii_lowercase +string.ascii_uppercase + string.digits)for i in range(len))output_queue.put(generated_string)procs = [mpcs.Process(target=strings_random, args=(8, output_queue))for i in range(7)]for proc in procs:proc.start()for proc in procs:proc.join()results = [output_queue.get() for pro in procs]print(results)
基于Process类的多进程按照进程完成的先后顺序返回结果。如果用户需要结果按照既定的顺序生成,那么需要费一番功夫,如下面的程序所示。为了获取有序的结果,必须在函数中增加一个参数,最后再输出到结果中。这个参数表示进程的位置或顺序,最后结果被存储在参数中。下面的程序基于Process类演示了这种思路,结果会带一个位置参数:
import multiprocessing as mpcsimport randomimport stringoutput_queue = mpcs.Queue()def strings_random(len, position, output_queue):generated_string = ''.join(random.choice(string.ascii_lowercase +string.ascii_uppercase + string.digits)for i in range(len))output_queue.put((position, generated_string))procs = [mpcs.Process(target=strings_random, args=(5, pos, output))for pos in range(4)]for proc in procs:proc.start()for proc in procs:proc.join()results = [output_queue.get() for pro in procs]results.sort()results = [rslt[1] for rslt in results]print(results)
Pool类为并行计算提供了map和view方法,它还支持这些方法的异步版本。它将会在进程完成之前对主程序加锁,这样就可以保证程序输出的结果是按照顺序排列的。
6. Python多线程
Python多线程允许用户在一个进程中创建多个线程完成并发计算。一个进程的所有线程会和主进程/线程共享同样的数据存储空间,这样可以共享数据,方便互相通信。线程也称为轻量级进程,因为它们所需的内存比进程少。
下面的程序演示如何创建和启动线程:
import threadingimport timeclass demoThread (threading.Thread):def __init__(self, threadID, name, ctr):threading.Thread.__init__(self)self.threadID = threadIDself.name = nameself.ctr = ctrdef run(self):print "Start of The Thread: " + self.nameprint_time(self.name, self.ctr, 8)print "Thread about to Exit:" + self.namedef print_time(threadName, delay, counter):while counter:time.sleep(delay)print "%s: %s" % (threadName, time.ctime(time.time()))counter -= 1thrd1 = demoThread(1, "FirstThread", 4)thrd2 = demoThread(2, "SecondThread", 5)thrd1.start()thrd2.start()print "Main Thread Exits"
这个程序创建了两个线程。如果你观察输出结果,会发现结果的输出顺序混乱。Main Thread Exits语句会先显示,随后Thread about to Exit: ThreadName语句会随机显示。
我们可以通过线程同步方法来控制输出结果,保证线程按照需要的顺序完成。下面的程序首先运行第一条线程,结束后才运行第二条线程,最后主线程才退出。保证线程结束顺序的方法是,线程启动前先获取线程锁,线程结束后释放线程锁,这样新线程就可以获取。主线程通过join方法调用所有线程对象。这个方法会在其他线程结束之前阻塞主线程:
import threadingimport timeclass demoThread (threading.Thread):def __init__(self, threadID, name, ctr):threading.Thread.__init__(self)self.threadID = threadIDself.name = nameself.ctr = ctrdef run(self):print "Start of The Thread: " + self.namethreadLock.acquire()print_time(self.name, self.ctr, 8)print "Thread about to Exit:" + self.namethreadLock.release()def print_time(threadName, delay, counter):while counter:time.sleep(delay)print "%s: %s" % (threadName, time.ctime(time.time()))counter -= 1threadLock = threading.Lock()thrds = []thrd1 = demoThread(1, "FirstThread", 4)thrd2 = demoThread(2, "SecondThread", 5)thrd1.start()thrd2.start()thrds.append(thrd1)thrds.append(thrd2)for thrd in threads:thrd.join()print "Main Thread Exits"
8.5.2 在Python中演示基于Hadoop的MapReduce
Hadoop是一种在计算集群上对大数据进行分布式存储与处理的开源框架。Hadoop由三部分组成:负责数据处理的MapReduce,Hadoop分布式文件系统(Hadoop Distributed File System,HDFS),负责数据存储的大型数据库HBase。HDFS可以存储非常大的数据集文件。它可以把数据文件分割成多个文件块,然后保存文件块与计算节点对应关系的索引信息。HBase是一种支持大数据、基于HDFS开发的数据库。它是一种开源、列导向、非关系型分布式数据库。
MapReduce是一种在计算集群上对大数据进行分布式处理的开源框架。Hadoop是对MapReduce计算框架的开源实现。MapReduce程序由两部分组成:map和reduce。map函数对输入数据文件进行过滤,然后把它的计算结果写到文件系统。之后,再用reduce函数进行汇总,最后再把计算结果输出到文件系统。MapReduce框架是一种单程序多数据模式(Single Program, Multiple Data,SPMD),在多个数据集上做同样的数据处理。
在Hadoop系统中,完整的功能被分成多个组件。有两个主节点。一个是任务跟踪器(Job Tracker),主要功能是跟踪从动节点的map和reduce过程,从动节点称为任务跟踪节点(task tracker node)。另一个是名称节点(namenode),主要功能是管理分割文件集的文件块与从动节点(称为数据节点)的关联关系。为了防止单节点发生异常导致任务失败,用户通常还会安装备份名称节点。建议在运行实际的map和reduce数据处理时,使用大量既作为任务跟踪节点又作为数据节点的从动节点。每一个从动节点既是任务跟踪节点,又是数据节点。MapReduce应用的性能与从动节点的数量成正比。Hadoop系统还可以自动宕机恢复:如果一个任务跟踪节点在数据处理过程中宕机了,Hadoop会自动把任务分配到其他任务节点上,数据处理过程不会中断。
下面的程序是在Python中演示基于Hadoop的MapReduce的开发过程。它对一个普通的爬虫数据集进行处理。这些数据集包括长期抓取的若干PB网络数据。里面包括网页数据、抽取的元数据以及苹果系统文件(Web ARChive,WARC)格式的文本数据。这些数据存储在Amazon S3云存储里,作为Amazon公开数据集程序的一部分。关于这个数据集的更多信息可以在http://commoncrawl.org/the-data/get-started/上看到。
import sysfor line in sys.stdin:try:line = line.strip()# 把一长分割成单词words = line.split()# 增加计数器if words[0] == "WARC-Target-URI:" :uri = words[1].split("")print '%s %s' % (uri[0]+"/"+uri[2], 1)except Exception:print "There is some Error"
上面的程序就是map部分,下面的程序是reduce部分:
from operator import itemgetterimport syscurrent_word = Nonecurrent_count = 0word = Nonefor line in sys.stdin:line = line.strip()word, count = line.split('\t', 1)try:count = int(count)except ValueError:continueif current_word == word:current_count += countelse:if current_word:print '%s\t%s' % (current_word, current_count)current_count = countcurrent_word = wordif current_word == word:print '%s\t%s' % (current_word, current_count)
运行前面的程序之前,用户需要先把输入数据集文件web-crawl.txt放到HDFS home文件夹中。用下面的命令可以执行两个程序:
#hadoop jar usrlocal/apache/hadoop2/share/hadoop/tools/lib/hadoop-streaming- 2.6.0.jar -file mapper.py -mapper mapper.py -file reducer.py -reducer reducer.py -input sample_crawl_data.txt -output output
8.5.3 在Python中运行Spark
Spark是一个多用途的集群计算系统。它的高级API可以支持Java、Python和Scala语言。这样可以非常轻松地写出并行程序。它的设计与Hadoop两阶段、来回在硬盘倒文件的MapReduce相反。Spark是一种内存模型,在一些应用场景中可以实现最多100%的性能提升。它非常适合实现机器学习的应用与算法。
Spark需要集群管理和一个分布式存储系统。它为许多分布式存储系统都提供了简单的接口, 如Amazon S3、Cassandra和HDFS,等等。另外,它还可以单机运行,即可以对Spark原生集群(Spark native cluster)、Hadoop、YARN和Apache Mesos进行集群管理。
Spark的Python API称为PySpark,通过它就可以用Python进行Spark编程。可以在用PySpark打开的命令行中用Python编写Spark程序,也可以在IPython会话中进行。还可以先开发程序,然后通过pyspark命令运行程序。
8.6 小结
本章介绍了用IPython进行高性能科学计算的相关概念。首先介绍了并行计算的基本概念,然后介绍了IPython并行计算的具体结构。之后,演示了简单并行程序的开发、IPython魔法函数以及并行装饰器。
本章还介绍了IPython的高级特性:容错机制,动态负载均衡,任务之间的依赖关系管理,客户端与引擎之间对象的移动,IPython的数据库支持,在IPython中使用MPI,用StarCluster通过IPython管理Amazon EC2远程集群。随后,还介绍了Python的多进程和多线程编程。最后,简单介绍了使用Hadoop和Spark在Python中开发分布式应用的方法。
下一章将介绍一些用Python的科学计算工具和API解决真实问题的案例,还将介绍不同基础与高级科学领域中的若干应用。
