第 12 章 高级网页抓取:屏幕抓取器与爬虫
在第 11 章你已经开始培养网页抓取技能,学习了如何确定要抓取的内容,以及用什么方式去哪里抓取。在这一章,我们会学习用更高级的抓取器来收集内容,比如基于浏览器的抓取器和爬虫。
我们还会学习使用高级网页抓取工具调试常见问题,并介绍在抓取网页时会遇到的一些道德问题。首先,我们会研究基于浏览器的网页抓取:通过 Python 直接使用浏览器从网页上抓取内容。
12.1 基于浏览器的解析
有时,站点使用大量的 JavaScript 或其他页面加载后执行的代码来给页面填充内容。在这些情况中,使用一个普通的网页抓取器来分析站点几乎是不可能的。你最后得到的是一个空白的页面。如果你想要同页面进行交互(即,如果你需要点击按钮或者输入一些搜索文本),也会碰到相同的问题。无论哪一种情况,你需要找出屏幕阅读(screen read)页面的方法。屏幕读取器使用浏览器打开页面,在浏览器中加载页面之后读取并同它交互。
屏幕读取器很擅长执行通过一系列操作来获取信息才能完成的任务。出于这个原因,屏幕读取器脚本也是自动化常规网页任务的简单方式。
在 Python 中最常用的屏幕读取库是 Selenium(http://selenium.googlecode.com/svn/trunk/docs/api/py/index.html)。Selenium 是一个 Java 程序,用来打开浏览器,并且通过读取页面同页面交互。如果你已经了解 Java,可以使用 Java IDE 来与浏览器交互。我们会通过 Python 使用 Python 包(Python binding)与 Selenium 交互。
12.1.1 使用Selenium进行屏幕读取
Selenium 是一个强大的基于 Java 的引擎,可通过支持 Selenium 的浏览器直接与网站交互。它是一个非常流行的用于用户测试的框架,让公司可以为它们的网站构建测试。对于我们的目标,我们会使用 Selenium 来抓取一个我们需要交互或不是所有内容都在第一次请求中加载(例如图 11-6 中的示例,大多数的内容在第一次请求完成后加载)的站点。让我们查看页面,看看是否可以通过 Selenium 读取它。
首先,需要使用 pip install 安装 Selenium(http://selenium-python.readthedocs.io/en/latest/installation.html):
pip install selenium
现在,开始编写 Selenium 代码。首先,需要打开浏览器。Selenium 支持许多不同的浏览器,但是附带了一个 Firefox 的内置驱动。如果你没有安装 Firefox,可以安装它,或者为 Chrome(https://code.google.com/p/selenium/wiki/ChromeDriver)、IE(https://code.google.com/p/selenium/wiki/InternetExplorerDriver)或 Safari(https://code.google.com/p/selenium/wiki/SafariDriver)安装 Selenium 驱动。让我们看一下是否能够使用 Selenium 打开网页(在例子中,我们会使用 Firefox,但是切换和使用不同的驱动器是很简单的):
from selenium import webdriver ➊browser = webdriver.Firefox() ➋browser.get('http://www.fairphone.com/we-are-fairphone/') ➌browser.maximize_window() ➍
❶ 导入来自 Selenium 的 webdriver 模块。这个模块用来调用任何已经安装的驱动器。
❷ 通过使用 webdriver 模块的 Firefox 类初始化 Firefox 浏览器对象。这会在计算机上打开一个新的浏览器窗口。
❸ 通过 get 方法和一个 URL 参数,访问想要抓取的 URL。打开的浏览器应该开始加载页面了。
❹ 使用 maximize_browser 方法最大化打开的浏览器。这会帮助 Selenium“看到”更多的内容。
现在已经有了一个页面加载完的浏览器对象(browser 变量)。让我们看一下是否能够同页面上的元素交互。如果你使用浏览器的检视标签,会看到社交媒介内容在一个类名称为 content 的 div 中。让我们看一下是否可以使用新的 browser 对象看到全部内容:
content = browser.find_element_by_css_selector('div.content') ➊print content.text ➋all_bubbles = browser.find_elements_by_css_selector('div.content') ➌print len(all_bubbles)for bubble in all_bubbles: ➍print bubble.text
❶ browser 对象有一个函数 find_element_by_css_selector,使用 CSS 选择器来选择 HTML 对象。这行代码选择了第一个类名称为 content 的 div,这会返回第一个匹配的对象(一个 HTMLElement 对象)。
❷ 这行代码会打印第一个匹配对象的文本内容。我们期待看到第一个聊天气泡。
❸ 这行代码使用 find_elements_by_css_selector 方法,传递一个 CSS 选择器,找到所有匹配的对象。这个方法返回一个 HTMLElement 对象列表。
❹ 遍历列表,并且打印每一个对象的内容。
嗯,有些奇怪。看起来只有两个匹配我们想要查找的对象(因为在打印 all_bubbles 的长度时,看到输出为 2),但是我们在页面上看到了大量的内容气泡。让我们更深入地查看页面上的 HTML 对象,看是否可以弄明白为什么没有匹配出更多的对象(见图 12-1)。
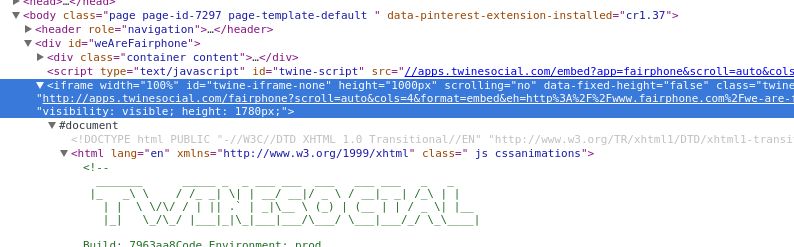
图 12-1:iframe
啊!当查看内容的父元素时,我们看到这是一个 iframe(https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe),位于页面的中部。iframe(内联框架)是一个 HTML 标签,它将另外一个 DOM 结构嵌入到页面中,允许一个页面在它自身中加载另外一个页面。我们的代码可能不能解析它,因为解析器希望只遍历一个 DOM 对象。让我们看一下是否可以让 iframe 在一个新的窗口中加载,这样就不需要遍历两个 DOM。
iframe = browser.find_element_by_xpath('//iframe') ➊new_url = iframe.get_attribute('src') ➋browser.get(new_url) ➌
❶ 使用 find_element_by_xpath 方法,返回第一个匹配 iframe 标签的元素。
❷ 得到 src 属性,这包含在 iframe 中加载的页面的 URL。
❸ 在浏览器中加载 iframe 的 URL。
我们找到了如何加载想要的内容的方法。现在看一下是否可以加载所有的内容气泡:
all_bubbles = browser.find_elements_by_css_selector('div.content')for elem in all_bubbles:print elem.text
现在有了气泡内容——很棒!让我们收集一些信息:想要提取人的姓名、他们分享的内容、照片(如果有的话),以及到原始内容的链接。
在浏览页面 HTML 代码的过程中,看起来每一个内容元素都有 fullname 和 name 元素来标识个人,还有一个有文本内容的 twine-description 元素。我们看到这里有一个 picture 元素,还有一个 when 元素,其中保存着时间数据。when 元素还包含一个原始链接。具体讲解如下。
from selenium.common.exceptions import NoSuchElementException ➊all_data = []for elem in all_bubbles: ➋elem_dict = {}elem_dict['full_name'] = \elem.find_element_by_css_selector('div.fullname').text ➌elem_dict['short_name'] = \elem.find_element_by_css_selector('div.name').textelem_dict['text_content'] = \elem.find_element_by_css_selector('div.twine-description').textelem_dict['timestamp'] = elem.find_element_by_css_selector('div.when').textelem_dict['original_link'] = \elem.find_element_by_css_selector('div.when a').get_attribute('href') ➍try:elem_dict['picture'] = elem.find_element_by_css_selector('div.picture img').get_attribute('src') ➎except NoSuchElementException:elem_dict['picture'] = None ➏all_data.append(elem_dict)
❶ 这行代码导入来自 Selenium 的 NoSuchElementException 异常类。当在 try…except 代码块中使用异常类时,确保你导入和使用了库异常,以便正确地处理预期误差。我们知道,不是每一个对象都有照片,并且 Selenium 会在找不到我们想要的 picture HTML 元素的时候抛出这个异常,所以我们可以使用这个异常来对有和没有图片的气泡区别处理。
❷ 在 for 循环中,遍历了内容气泡。对于这其中的每一个 elem 对象,通过更深入地遍历树,可以找到其中包含的元素。
❸ 对于每一个文本对象,这行代码调用了 HTMLElement 的 text 属性,这会抛弃文本中的标签,只返回元素的文本内容。
❹ HTMLElement 的 get_attribute 方法期待得到一个嵌套的属性,并且返回属性的值。这行代码使用 href 属性来得到 URL,使用嵌套的 CSS 在 when 类中的 div 元素中查找锚标签。
❺ 在 try 代码块中,这段代码在 div 中查找照片。如果没有照片,下一行会捕获 Selenium 抛出的 NoSuchElementException 异常,因为没有匹配的元素。
❻ 如果没有找到匹配的元素,这行代码添加一个 None 值。这确保新列表中的所有对象有一个 picture 值。
我们的脚本很早就遇到了问题,你应该会看到一个包含下面文本信息的异常:
Message: Unable to locate element:{"method":"css selector","selector":"div.when"}
这告诉我们在查找 when 元素时碰到了问题。让我们通过检视标签仔细查看发生了什么(见图 12-2)。
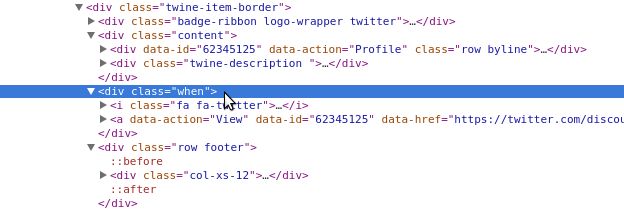
图 12-2:相邻 div
通过更仔细地观察,可以看到 content div 和 when div 实际上是相邻的,而不是在 DOM 结构中的父子关系。这暴露了一个问题,因为只遍历了 content div,而不是父 div。如果仔细地观察,可以看到 twine-item-border 是 content 和 when 元素的共同父元素。你需要通过加载父元素,修改为 all_bubbles 使用的元素:
all_bubbles = browser.find_elements_by_css_selector('div.twine-item-border')
做出这个改变后重新运行之前的代码。发生了什么?你会看到更多的 NoSuchElementException 错误。因为不确定每一个元素有相同的属性,所以我们假设它们都不相同,并且重新编写代码来对异常做出解释:
from selenium.common.exceptions import NoSuchElementExceptionall_data = []all_bubbles = browser.find_elements_by_css_selector('div.twine-item-border')for elem in all_bubbles:elem_dict = {'full_name': None,'short_name': None,'text_content': None,'picture': None,'timestamp': None,'original_link': None,} ➊content = elem.find_element_by_css_selector('div.content') ➋try:elem_dict['full_name'] = \content.find_element_by_css_selector('div.fullname').textexcept NoSuchElementException:pass ➌try:elem_dict['short_name'] = \content.find_element_by_css_selector('div.name').textexcept NoSuchElementException:passtry:elem_dict['text_content'] = \content.find_element_by_css_selector('div.twine-description').textexcept NoSuchElementException:passtry:elem_dict['timestamp'] = elem.find_element_by_css_selector('div.when').textexcept NoSuchElementException:passtry:elem_dict['original_link'] = \elem.find_element_by_css_selector('div.when a').get_attribute('href')except NoSuchElementException:passtry:elem_dict['picture'] = elem.find_element_by_css_selector('div.picture img').get_attribute('src')except NoSuchElementException:passall_data.append(elem_dict)
❶ 对于对象的每一次迭代,这行代码添加一个新的字典,设置所有的键为 None。这给了我们一个干净的字典设置,这样每一个对象都有相同的键,我们可以在发现数据的时候添加它到键中。
❷ 拉取 content div,这样可以在这个 div 中选择。这让代码更加明确,以防有其他的 div 有相似的名称。
❸ 使用 Python 的 pass(https://docs.python.org/2/tutorial/controlflow.html#pass-statements)来略过异常。因为所有的键都已经设置为 None,所以我们在这里不需要做任何事。Python 的 pass 让代码略过异常,所以程序会继续执行下一个代码块。
一旦将数据收集到 all_data 中,你可以打印它,看一下收集到的内容。下面是一些样例输出(这是一个社交媒体时间线,所以你的时间线会和下面展示的有所不同):
[{'full_name': u'Stefan Brand','original_link': None,'picture': u'https://pbs.twimg.com/media/COZlle9WoAE5pVL.jpg:large','short_name': u'','text_content': u'Simply @Fairphone :) #WeAreFairphone http://t.co/vUvKzjX2Bw','timestamp': u'POSTED ABOUT 14 HOURS AGO'},{'full_name': None,'original_link': None,'picture': None,'short_name': u'','text_content': None,'timestamp': None},{'full_name': u'Sietse/MFR/Orphax','original_link': None,'picture': None,'short_name': u'','text_content': u'Me with my (temporary) Fairphone 2 test phone.# happytester #wearefairphone @ Fairphone instagram.com/p/7X-KXDQzXG/','timestamp': u'POSTED ABOUT 17 HOURS AGO'},...]
我们的数据看起来有一些混乱。for 循环很晦涩,很难阅读和理解。同样,看起来我们可以改进一些数据收集方式——我们的日期对象只是一个字符串,但是它更应该是一个日期。我们还需要实验 Selenium 的能力来与页面交互,这可能会帮助我们加载更多的内容。
还需要调试看到的错误。我们找不到正确的短名称;代码看起来返回了一个空字符串。在研究了页面之后,看起来 name div 是隐藏的。在 Selenium 中,隐藏的元素通常是不能阅读到的,所以需要使用该元素的 innerHTML 属性,这会返回标签中的内容。我们也注意到,时间戳数据存储在 title 属性中,并且 URL 事实上存储在 data-href 中,而不是 href 属性中。
随着时间推移,编写首次运行就可成功抓取的代码会变得更简单。预期可能出现的问题也变得更简单。通过研究浏览器的开发者工具,并使用 IPython 进行调试,你可以操作变量,测试可能有效的方法。
在找到所有数据的基础上,要确保正确地格式化脚本。我们想要创建函数,更好地抽象数据提取。相对于从初始页面直接解析 URL,应该简化代码,直接加载页面。通过在浏览器中反复试错发现,可以移除 iframe URL 中的长查询字符串(即,?scroll=auto&cols=4&format=embed&eh=…),并且仍然使用来自社交媒体的嵌入内容加载整个页面。让我们看一下整理和简化后的脚本:
from selenium.common.exceptions import NoSuchElementException, \WebDriverExceptionfrom selenium import webdriverdef find_text_element(html_element, element_css): ➊try:return html_element.find_element_by_css_selector(element_css).text ➋except NoSuchElementException:passreturn Nonedef find_attr_element(html_element, element_css, attr): ➌try:return html_element.find_element_by_css_selector(element_css).get_attribute(attr) ➍except NoSuchElementException:passreturn Nonedef get_browser():browser = webdriver.Firefox()return browserdef main():browser = get_browser()browser.get('http://apps.twinesocial.com/fairphone')all_data = []browser.implicitly_wait(10) ➎try:all_bubbles = browser.find_elements_by_css_selector('div.twine-item-border')except WebDriverException:browser.implicitly_wait(5)all_bubbles = browser.find_elements_by_css_selector('div.twine-item-border')for elem in all_bubbles:elem_dict = {}content = elem.find_element_by_css_selector('div.content')elem_dict['full_name'] = find_text_element(content, 'div.fullname')elem_dict['short_name'] = find_attr_element(content, 'div.name', 'innerHTML')elem_dict['text_content'] = find_text_element(content, 'div.twine-description')elem_dict['timestamp'] = find_attr_element(elem, 'div.when a abbr.timeago', 'title') ➏elem_dict['original_link'] = find_attr_element(elem, 'div.when a', 'data-href')elem_dict['picture'] = find_attr_element(content, 'div.picture img', 'src')all_data.append(elem_dict)browser.quit() ➐return all_data ➑if __name__ == '__main__':all_data = main()print all_data
❶ 创建一个函数,接受 HTML 元素和 CSS 选择器,返回文本元素。在上一个代码实例中,需要一次又一次地重复代码;现在我们想要创建一个函数,这样可以重复使用它,而不需要在脚本中重新编写代码。
❷ 使用抽象函数变量,返回 HTML 元素的文本。如果没有找到匹配,返回 None。
❸ 创建一个函数来找到和返回属性,类似于我们的文本元素函数。这需要 HTML 元素、CSS 选择器,以及我们想要从选择器中拉取的属性,并且为这个选择器返回值或者 None。
❹ 使用抽象函数变量找到 HTML 元素,并且返回属性。
❺ 使用 Seleniumbrowser 类的 implicitly_wait 方法,它接受一个希望浏览器在执行下一行代码前隐式等待的秒数为参数。如果不确定页面是否会立即加载完成,这是个很棒的方法。关于隐式和显式等待有很多很棒的 Selenium 文档(http://selenium-python.readthedocs.io/en/latest/waits.html)。
❻ 传递 CSS 选择器,来获取 when div 中一个锚标签的 abbr 元素的 title 属性,以获取时间戳数据。
❼ 抓取数据结束后,使用 quit 方法关闭浏览器。
❽ 返回收集的数据。 __name__ == '__main__' 代码块允许从命令行执行代码时打印数据,或者我们可以导入函数到 IPython 中,并且运行 main 函数返回数据。
尝试从命令行中运行脚本,或者将其导入到 IPython,之后运行 main 函数。这次数据看起来更加完整了吗?你还会发现添加了另外一个 try…except 代码块。我们注意到,有些时候 Selenium 使用的交互会与页面上的 JavaScript 冲突,使 Selenium 抛出一个 WebDriverException 异常。允许页面加载更长的时间,再一次尝试后,可以解决这个问题。
如果在浏览器中访问 URL,你可以看到,随着下拉页面能够加载更多的数据。有了 Selenium,我们同样可以做这件事!让我们看一下 Selenium 可以做的其他漂亮的事。可以尝试在 Google 中搜索 Python 网页抓取库,并且使用 Selenium 与搜索结果交互:
from selenium import webdriverfrom time import sleepbrowser = webdriver.Firefox()browser.get('http://google.com')inputs = browser.find_elements_by_css_selector('form input') ➊for i in inputs:if i.is_displayed(): ➋search_bar = i ➌breaksearch_bar.send_keys('web scraping with python') ➍search_button = browser.find_element_by_css_selector('form button')search_button.click() ➎browser.implicitly_wait(10)results = browser.find_elements_by_css_selector('div h3 a') ➏for r in results:action = webdriver.ActionChains(browser) ➐action.move_to_element(r) ➑action.perform() ➒sleep(2)browser.quit()
❶ 需要找到一个输入。Google 和其他的站点一样,在页面的很多地方都有输入框,但是通常来说,只有一个大的可见搜索框。这行代码定位所有的输入表单,这样我们有了一个好的起点。
❷ 这行代码遍历每一个输入,看它们是隐藏的还是显示的。如果 is_displayed 返回 True,那么有了一个可见的元素。反之,这个循环会继续遍历。
❸ 找到一个显示出来的输入时,将它赋值给变量 search_bar,终止循环。这会找到第一个可见的输入,这可能是我们想找的那一个。
❹ 这行代码通过使用 send_keys 方法发送键和字符串到选定的元素(在这个例子中,它发送键到搜索框)。这类似于在键盘上输入,但是是用 Python !
❺ Selenium 还可以 click 页面上可见的元素。这行代码告诉 Selenium 点击搜索表单的提交按钮,来查看搜索结果。
❻ 为了查看所有的搜索结果,这行代码选择 div 中有链接的标题元素,这是谷歌搜索结果页面的结构。
❼ 这段代码遍历每一个结果,利用 Selenium 的 ActionChains 定义一系列的操作,并告诉浏览器执行这些操作。
❽ 这行代码使用 ActionChain 的 move_to_element 方法,传递给这个方法想要浏览器访问的元素。
❾ 这行代码调用 perform,这意味着浏览器会高亮每一个搜索结果。我们使用一个 sleep 函数,这告诉 Python 在执行下一行代码前等待特定的秒数(这里是 2),这样,浏览器不会执行得过快,以免你失去很多乐趣。
喔!现在我们可以找到一个站点,填充一个表单,提交它,并且使用 Selenium ActionChains 来遍历结果。正如你看到的,ActionChains 是在浏览器中执行一系列操作的有效方式。你可以在 Selenium 的 Python 附带文档(http://selenium-python.readthedocs.org/)中探索很多很棒的特性,包括显式的等待(http://selenium-python.readthedocs.io/waits.html#explicit-waits,浏览器可以等待,直到一个特定的元素被加载,而不只是整个页面加载完成)、处理警告(http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.common.alert)和保存截图(http://selenium-python.readthedocs.io/api.html#selenium.webdriver.remote.webdriver.WebDriver.save_screenshot),这些对于调试来说很有用处。
现在已经看到 Selenium 的一些能力,你能不能重写我们已经为#WeAreFairphone 站点编写的代码,并且遍历前 100 个记录? [ 提示:如果你不想使用 ActionChains 遍历每一个元素,你总是可以使用 JavaScript ! Selenium 驱动器的 execute_script 方法允许你执行 JavaScript,就像在浏览器控制台中执行 JavaScript 一样。你可以使用 JavaScript 的 scroll 方法(https://developer.mozilla.org/en-US/docs/Web/API/Window/scroll)。Selenium 元素对象同样有一个 location 属性,它会返回页面上元素的 x 和 y 坐标值。]
我们已经学习了如何利用 Selenium 操作和使用浏览器来进行网页抓取,但是,还没有结束!让我们看一下如何使用 Selenium 和无头浏览器。
Selenium和无头浏览器
最流行的无头浏览器工具之一是 PhantomJS(http://phantomjs.org/)。如果你是一个熟练的 JavaScript 开发者,可以直接在 PhantomJS 中构建抓取器。然而,如果你想要使用 Python 尝试一下,可以使用 Selenium 和 PhantomJS。PhantomJS 同 GhostDriver(https://github.com/detro/ghostdriver)一起工作,打开 Web 页面并导航。
为什么使用无头浏览器?无头浏览器(http://en.wikipedia.org/wiki/Headless_browser)可以在服务器上运行。相对于普通的浏览器,它们可以更快地运行和解析页面,并且可以在更多的平台上使用。如果最终想要在服务器上运行基于浏览器的网页抓取脚本,你会想要使用无头浏览器。在 10 分钟之内就可安装并运行一个无头浏览器,而大多数其他浏览器需要更长的时间来正确加载和运行(取决于你使用的功能和部署的方式)。
12.1.2 使用Ghost.py进行屏幕读取
Ghost.py(http://jeanphix.me/Ghost.py/)是一个用于屏幕读取的 WebKit 实现,用来直接与 Qt WebKit(http://doc.qt.io/qt-5/qtwebkit-index.html)交互。Qt WebKit 是一个基于 Qt(https://en.wikipedia.org/wiki/Qt_(software))的 WebKit 实现,而 Qt 是一个用 C++ 实现的跨平台的应用开发框架。
为了开始使用 Ghost.py,你首先需要安装一些很有效的库。如果你能够安装 PySide(https://pypi.python.orgpypiPySide),那效果会是最好的,这会允许 Python 同 Qt 通信,给 Python 访问更广泛程序和交互的能力。这个过程会花一些时间,所以在开始运行安装之后,尽情地去给自己做一个三明治吧 2。
2如果你在安装 PySide 时碰到了问题,查看与操作系统相关的项目文档。你可以选择安装 PyQt(http://pyqt.sourceforge.net/Docs/PyQt5/installation.html)。你也可以通过 GitHub 上的安装文档(https://github.com/jeanphix/Ghost.py#installation)检查更新。
pip install pysidepip install ghost.py --pre
使用 Ghost.py 搜索 Python 主页(http://python.org),找到新的抓取文档。开始一个新的 Ghost.py 实例非常简单:
from ghost import Ghostghost = Ghost() ➊with ghost.start() as session:page, extra_resources = session.open('http://python.org') ➋print pageprint page.urlprint page.headersprint page.http_statusprint page.content ➌print extra_resourcesfor r in extra_resources:print r.url ➍
❶ 这行代码调用 Ghost 类的会话对象,实例化一个 Ghost 对象来同页面交互。
❷ Ghost 类的 open 方法返回两个对象,所以这行代码在两个独立的变量中捕获这些对象。第一个对象是用来同 HTML 元素交互的页面对象。第二个对象是页面加载的其他资源列表(你在网络标签中看到的列表)。
❸ 页面对象有很多属性,比如头部、内容、链接和页面上的内容。这行代码打印页面的内容。
❹ 这行代码遍历页面的其他资源,并且打印它们,来看是否有用。有时,这些 URL 是 API 调用,可以利用它们简化数据的访问。
Ghost.py 让我们能够洞察页面使用的资源(在第一次使用 open 方法打开页面时,通过一个元组给出)和真实页面上的许多特性。同样可以使用 .content 属性来加载页面的内容,这样如果想要使用其中一个页面解析器解析它,比如 LXML,我们可以做得到,并且仍然使用 Ghost.py 进行交互。
由于对于在 Python 主页中搜索抓取库感兴趣,让我们看一下是否可以定位输入框:
print page.content.contains('input') ➊result, resources = session.evaluate('document.getElementsByTagName("input");') ➋print result.keys()print result.get('length') ➌print resources
❶ 测试页面上是否存在一个 input 标签(大多数的搜索框是简单的输入对象)。这会返回一个布尔值。
❷ 使用一些简单的 JavaScript 来找到页面上所有以“input”为标签名称的元素。
❸ 打印来看响应中的 JavaScript 数组的长度。
根据 JavaScript 结果,在页面上,只有两个输入。为了确定使用哪一个,看一下第一个是否合适。
result, resources = session.evaluate('document.getElementsByTagName("input")[0].getAttribute("id");') ➊print result
❶ 索引结果列表,获取 id 属性。JavaScript 直接给出了元素的 CSS 属性,所以这是一个查看选择元素的相关 CSS 的有用方式。
类似于在 Python 中索引结果,也可以在 JavaScript 中索引它们。我们想要第一个输入元素,之后抓取输入的 CSS id。
for循环(https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for)来遍历getElementsByTagName函数返回的列表,通过这种方式来检查属性。如果你希望在浏览器中尝试 JavaScript,可以使用控制台完成这件事(见图 11-12)。
通过 id 的名称(id-search-field),已经定位了搜索字段元素,现在发送一些数据到这个字段:
result, resources = ghost.set_field_value("input", "scraping")
这段代码使用 set_field_value 方法,它需要一个选择器(这里就是 "input"),并且发送给它一个字符串("scraping")。Ghost.py 同样有一个 fill 方法(http://jeanphix.me/Ghost.py/#form),它会发送一个值的字典,来填充一系列匹配的表单字段。这在有多个字段要填充时很有用处。现在填充了检索词;让我们看一下是否能够提交查询。我们看到这在一个表单中,所以可以直接尝试进行一次表单提交:
page, resources = session.fire("form", "submit", expect_loading=True) ➊print page.url
❶ 这行代码调用 Ghost.py 的 fire 方法,这会触发一个 JavaScript 事件。我们想给表单元素发送一个信号,以提交事件,这样它会提交搜索,并导航至下一页。设置 expect_loading 为 True,这样 Ghost.py 知道我们在等待页面加载。
这有效吗?在测试中,当运行这段代码时,收到了超时响应。我们会在本章后文中讨论超时,但是这意味着 Ghost.py 停止等待响应,因为这花费了太长的时间。当你处理抓取器提交数据任务时,找到一个合适的超时时间,对于保证脚本继续工作是必需的。让我们尝试一个不同的提交方式。Ghost.py 可以同页面元素交互并且点击,让我们尝试一下。
result, resources = session.click('button[id=submit]') ➊print resultfor r in resources:print r.url ➋
❶ Ghost.py 的 click 方法使用 JavaScript 选择器点击对象。这行代码点击 id="submit" 的按钮。
❷ 对于大多数通过 Ghost.py 的交互,你会收到一个结果和一个资源列表。这行代码查看代码交互返回的资源。
嗯——点击提交按钮,我们得到了一个看起来像是控制台的 URL。让我们看一下是否可以看到 Qt WebKit 看到的内容。类似于 Selenium 的 save_screenshot 方法,Ghost.py 允许我们查看页面。
可以使用 Ghost.py 的 show 方法来“查看”该页面:
session.show()
你会看到打开了一个新窗口,展示出同抓取器所看到的相同的站点。它应该类似于图 12-3。
图 12-3:Ghost 页面
喔!我们正在页面的中间。尝试向上滚动,从另外的角度看一下。
session.evaluate('window.scrollTo(0, 0);')session.show()
现在它应该看起来类似于图 12-4。
图 12-4:Ghost 页面顶端
这个视图帮助我们理解错误。页面并没有像在普通浏览器中那样完整地打开,搜索和提交输入不可读。一个解决方案是使用更大的视窗重新打开页面,或者为提交设置一个更长的超时时间。
viewport_size和wait_timeout的参数。如果你希望重启浏览器,设置一个更大的视窗或一个更长的超时时间,这些都是合理的修正。
现在,看看是否可以使用一些 JavaScript 来将它提交:
result, resources = session.evaluate('document.getElementsByTagName("input")[0].value = "scraping";') ➊result, resources = session.evaluate('document.getElementsByTagName("form")[0].submit.click()') ➋
❶ 完全使用 JavaScript 设置输入值为“scraping”。
❷ 使用 JavaScript 函数调用表单的提交元素,并主动点击它。
现在如果再一次运行 show,你会看到图 12-5 所示的页面。
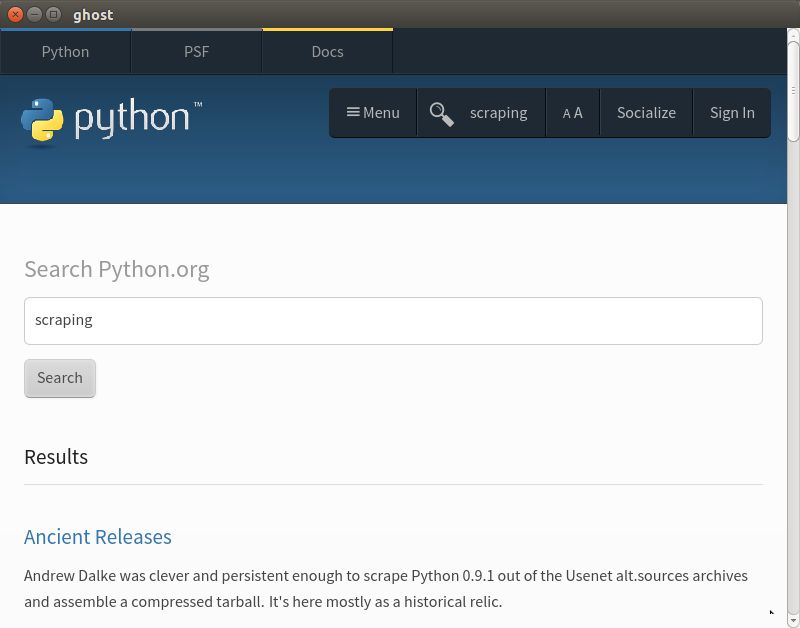
图 12-5:Ghost 搜索
我们使用 Qt 浏览器成功地执行了搜索。一些功能还没有像 Selenium 一样流畅,但是 Ghost.py 仍然是一个相当年轻的项目。
现在,我们已经学习了 Python 中几种与浏览器交互的不同方式,让我们做一些爬取!
12.2 爬取网页
如果你需要从网站的多个页面上抓取数据,爬虫可能是最好的解决方案。网络爬虫(或者机器人)很适合跨越整个域名或站点(或一系列的域名或站点)寻找信息。
爬虫可以帮助你了解网站的结构。例如,站点可能包含一个你并不知道的完整的子章节,其中包含一些有趣的数据。使用爬虫遍历域名,你可以找到子域或其他对报告有用的相关内容。
当你构建爬虫时,首先研究感兴趣的站点,然后创建页面读取的代码来识别和读取内容。一旦爬虫构建完毕,你可以创建一个遵循的规则列表,爬虫会使用它找到其他有趣的页面和内容,同时解析器会使用你创建的页面读取抓取器收集和保存内容。
我们会使用 Scrapy 开始创建第一个爬虫。
12.2.1 使用Scrapy创建一个爬虫
Scrapy(http://scrapy.org/)是最强大的 Python 网络爬虫。它赋予你在 Python 异步网络引擎 Twisted(http://twistedmatrix.com/trac/)之上使用 LXML(见 11.5 节)的能力。如果你需要一个特别快的爬虫,并能够同时处理大量的任务,我们强烈推荐 Scrapy。
Scrapy 有一些很棒的内置特性,包括导出不同格式的结果(CSV、JSON 等),一个易用的可运行满足不同需求的多个抓取器的服务端部署结构,以及其他一系列优雅的特性,比如使用中间件来处理代理请求或重试状态码失败的请求。Scrapy 会将遇到的错误打印到日志,这样你可以更新和修改代码。
为了恰当地使用 Scrapy,你需要学习 Scrapy 类系统。Scrapy 使用几个不同的 Python 类来解析网页并且返回好的内容。当定义一个爬虫类时,你也定义了规则和其他的类属性。这些规则和属性在爬虫开始抓取网页时使用。当定义一个新的爬虫的时候,你正在使用一个叫继承(inheritance)的东西。
继承
继承让你能够将一个类作为基类,在其基础上构建额外的属性或方法。
通过 Scrapy,当继承一个爬虫类时,同样继承了有用的内置方法与属性。之后通过改变一些方法和属性,它们就是专属于你的爬虫了。
Python 的继承是显而易见的:你开始定义一个类,并且将另外的类名称放置在类定义的括号内(例如,
class NewAwesomeRobot(Old Robot):)。新的类(这里是NewAwesomeRobot)继承自括号内的类(这里是OldRobot)。Python 让我们得以使用这种直接继承,这样当编写新的类时,可以积极地复用代码。继承允许我们使用 Scrapy 库中丰富的抓取知识,只需要重新定义一些方法和一些初始化爬虫属性。
Scrapy 使用继承来定义在页面上抓取的内容。对于每一个 Scrapy 项目,你会收集一系列的对象,并且可能会创建一些不同的爬虫。爬虫会抓取页面,使用在设置中定义的任何格式返回对象(即数据)。
相比我们使用过的其他抓取网页的库,使用 Scrapy 爬虫需要更多的组织,但是它相当直观。组织 Scrapy 抓取器便于复用、共享和更新项目。
有一些不同类型的 Scrapy 爬虫,让我们研究一下它们的主要相似点和不同处。表 12-1 提供了一个总结。
表12-1:爬虫类型
| 爬虫名称 | 主要目的 | 文档 |
|---|---|---|
Spider
| 用来解析特定数量的站点和页面 | http://doc.scrapy.org/en/latest/topics/spiders.html#scrapy.spider.Spider |
Crawl Spider
| 遵循一组关于如何解析链接和识别页面内容的正则表达式规则,解析域名 | http://doc.scrapy.org/en/latest/topics/spiders.html#crawlspider |
XMLFeed Spider
| 用来解析 XML feeds(比如 RSS),从节点中拉取内容 | http://doc.scrapy.org/en/latest/topics/spiders.html#xmlfeedspider |
CSVFeed Spider
| 用来解析 CSV feeds(或 URL),从行中拉取信息 | http://doc.scrapy.org/en/latest/topics/spiders.html#csvfeedspider |
SiteMap Spider
| 根据给定的域名列表,解析站点地图 | http://doc.scrapy.org/en/latest/topics/spiders.html#sitemapspider |
对于通常的网页抓取,你可以使用 Spider 类。对于更高级的、遍历整个域名的抓取,使用 CrawlSpider 类。如果你有 XML 或 CSV 格式的 feeds 或文件,特别是当它们非常大时,使用 XMLFeedSpider 和 CSVFeedSpider 来解析它们。如果你需要查看站点地图(你自己的站点或其他站点),使用 SiteMapSpider。
为了进一步熟悉两个主要的类(Spider 和 CrawlSpider),构建一些不同的爬虫。首先,使用一个 Scrapy 爬虫创建一个抓取器来爬取相同的 emoji 表情页面(http://www.emoji-cheat-sheet.com)。为此,我们使用普通的 Spider 类。首先使用 pip 安装 Scrapy。
pip install scrapy
同样建议你安装 service_identity 模块,这个模块提供了一些好用的特性,在爬取网页时提供安全集成。
pip install service_identity
通过 Scrapy,你可以使用一个简单的命令来启动一个项目。确保你正在想要使用爬虫的目录下,因为这个命令会为爬虫创建一系列的文件夹和子文件夹:
scrapy startproject scrapyspider
如果你列出所有当前文件夹下面的文件,应该会看到一个有很多子文件夹和文件的新的父文件夹。正如 Scrapy 站点(https://doc.scrapy.org/en/latest/intro/tutorial.html#creating-a-project)文档中描述的,有一些不同的配置文件(主文件夹下的 scrapy.cfg 和项目文件夹下的 settings.py,以及一个放置爬虫文件的文件夹和一个用来定义对象的文件)。
在创建抓取器之前,需要定义想要在页面数据中收集的对象。打开 items.py 文件(位于项目文件夹的嵌套文件夹内),并且修改它来保存页面数据。
# -*- coding: utf-8 -*-# 在这里定义为要抓取的对象定义模型## 参见文档:# http://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass EmojiSpiderItem(scrapy.Item): ➊emoji_handle = scrapy.Field() ➋emoji_image = scrapy.Field()section = scrapy.Field()
❶ 通过继承 scrapy.Item 创建了新的类。这意味着我们有了这个类的内置方法和属性。
❷ 为了定义每一个字段或数据值,在类中添加了一个新的行,设置了属性名称,并且通过将其设置为 scrapy.Field() 对象来初始化。这些字段支持任何普通的 Python 数据结构,包括字典、元组、列表、浮点数、小数和字符串。
你可能注意到 items.py 文件主要是事先编辑好的。这是个非常好的功能,让你能够快速开始开发,并确保有合适的项目结构。startproject 命令提供所有这些工具,是开始新 Scrapy 项目的最好方式。你同样可以看到,创建一个新的类来收集数据是很简单的。只需要几行 Python 代码,就可以定义关心的域,并准备好爬虫中使用的对象。
为了从爬虫类开始,在新项目目录结构中的 spiders 文件夹下创建一个新的文件,名为 emo_spider.py:
import scrapyfrom emojispider.items import EmojiSpiderItem ➊class EmoSpider(scrapy.Spider): ➋name = 'emo' ➌allowed_domains = ['emoji-cheat-sheet.com'] ➍start_urls = ['http://www.emoji-cheat-sheet.com/', ➎]def parse(self, response): ➏self.log('A response from %s just arrived!' % response.url) ➐
❶ 所有 Scrapy 导入使用项目根目录作为模块导入起始点,所以需要在导入中包含父文件夹。这行代码从 emojispider.items module 导入了 EmojiSpiderItem 类。
❷ 使用继承定义了 EmoSpider 类,新的类基于简单的 scrapy.Spider 类。这意味着爬虫将需要特定的初始化属性(https://doc.scrapy.org/en/latest/topics/spiders.html#spider),这样它知道去抓取哪一个 URL,以及如何处理抓取的内容。我们在下面的几行中定义了这些属性(start_urls、name 和 allowed_domains)。
❸ 爬虫名称是我们在命令行任务中识别出爬虫时会用到的。
❹ allowed_domains 告诉爬虫爬取哪些域名。如果爬虫遇到一个链接指向的域名不在该列表中,它会忽略这个链接。这个属性在编写爬取抓取器时很有用,这样如果链接不符合规则,抓取器就不会尝试去爬取所有的 Twitter 或 Facebook 网页。你同时也可以传递子域。
❺ Spider 类使用 start_urls 属性来遍历要爬取的 URL 列表。在 CrawlSpider 里,这些是找到更多匹配的 URL 的起点。
❻ 这行代码重新定义了爬虫的 parse 方法,通过在类中使用 def 和方法名称定义该方法执行一些逻辑。为类定义方法时,你总是从传递 self 开始。这是因为调用方法的对象将是第一个参数(即,list.append() 首先传递列表对象本身,然后传递括号中的参数)。 parse 函数的下一个参数是响应。正如在文档(https://doc.scrapy.org/en/latest/topics/spiders.html#scrapy.spiders.Spider.parse)中提及的,parse 方法将需要一个响应对象。最后用冒号终结这一行,正如定义任何其他的函数时所做的。
❼ 为了测试爬虫,Scrapy 入门指南中的这行代码使用爬虫的 log 方法,发送一条信息到日志中。使用响应的 URL 属性来展示响应的地址。
为了运行这个 Scrapy 爬虫,我们要确保正处于恰当的目录中(scrapy spider 和其中的 scrapy.cfg 文件),之后运行命令行参数来解析页面:
scrapy crawl emo
日志会显示爬虫开始运行,并且显示出哪些中间件正在运行。之后,几乎在最后,你应该能看见类似下面的输出:
2015-06-03 15:47:48+0200 [emo] DEBUG: A resp from www.emoji-cheat-sheet.com arrived!2015-06-03 15:47:48+0200 [emo] INFO: Closing spider (finished)2015-06-03 15:47:48+0200 [emo] INFO: Dumping Scrapy stats:{'downloader/request_bytes': 224,'downloader/request_count': 1,'downloader/request_method_count/GET': 1,'downloader/response_bytes': 143742,'downloader/response_count': 1,'downloader/response_status_count/200': 1,'finish_reason': 'finished','finish_time': datetime.datetime(2015, 6, 3, 13, 47, 48, 274872),'log_count/DEBUG': 4,'log_count/INFO': 7,'response_received_count': 1,'scheduler/dequeued': 1,'scheduler/dequeued/memory': 1,'scheduler/enqueued': 1,'scheduler/enqueued/memory': 1,'start_time': datetime.datetime(2015, 6, 3, 13, 47, 47, 817479)}
抓取器大概一秒解析一个页面。同样可以看到来自 parse 方法的日志。酷!我们成功地定义了第一个对象和类,能够创建并且运行它们。
下一步是真正地解析页面,拉取内容。让我们尝试另外一个内置的特性,Scrapy shell。它类似于 Python 或命令行 shell,但是附带所有可用的爬虫命令。有了该 shell,研究页面和确定如何得到页面内容变得非常简单。为了启动 Scrapy shell,只需运行:
scrapy shell
你应该看到了一个可用选项或可以调用的函数的列表。其中一个为 fetch。让我们测试一下这个函数:
fetch('http://www.emoji-cheat-sheet.com/')
你现在应该看到了一些类似于抓取输出的输出结果。其中一些信息显示已爬取 URL,之后返回一个新的可用对象列表。其中一个是 response 对象。响应对象和你在 parse 方法中使用的相同。让我们看一下是否可以找到一些同响应对象交互的方式:
response.urlresponse.statusresponse.headers
这其中的每一项都应该返回一些数据。url 与我们编写日志信息时使用的 URL 相同。 status 告诉我们 HTTP 响应的状态码。headers 应该提供一个服务器返回的头部字典。
response,点击 Tab,你会看到一个完整的可用的方法与属性列表,以及响应对象。你同样可以在 IPython 终端中对任何其他的 Python 对象做这件事。3
3如果你安装了 IPython,就会在使用的大多数 Python shell 中看到该 tab 实现。如果没有看到它,你可以添加一个 .pythonrc 文件到计算机(http://stackoverflow.com/questions/246725/how-do-i-add-tab-completion-to-the-python-shell),并且将它赋值给 PYTHONSTARTUP 环境变量。
每一个响应对象同样会有一个 xpath 和 css 方法。这些方法类似于贯穿本章和第 11 章的选择器。正如你已经猜到的,xpath 希望你发送一个 XPath 字符串,而 css 希望得到一个 CSS 选择器。让我们看一下使用已经为这个页面写好的 XPath 选择页面上的一些对象:
response.xpath('//h2|//h3')
运行该命令,你会看到一个类似于下面的列表:
[<Selector xpath='//h2|//h3' data=u'<h2>People</h2>'>,<Selector xpath='//h2|//h3' data=u'<h2>Nature</h2>'>,<Selector xpath='//h2|//h3' data=u'<h2>Objects</h2>'>,<Selector xpath='//h2|//h3' data=u'<h2>Places</h2>'>,<Selector xpath='//h2|//h3' data=u'<h2>Symbols</h2>'>,<Selector xpath='//h2|//h3' data=u'<h3>Campfire also supports a few sounds<'>]
现在让我们看一下,是否可以只读取这些头部中的文本内容。在使用 Scrapy 时,你会想要精确地抽取出正在寻找的元素;(在编写本书时)没有 get 或 text_content 方法。让我们看一下是否可以使用 XPath 知识来从头部中选择文本:
for header in response.xpath('//h2|//h3'):print header.xpath('text()').extract()
你应该会得到类似下面的输出:
[u'People'][u'Nature'][u'Objects'][u'Places'][u'Symbols'][u'Campfire also supports a few sounds']
可以看到 extract 方法会返回一个匹配元素的列表。可以使用 @ 符号来表示属性,用 text() 方法来拉取文本。我们需要重写一些代码,但现在可以使用在 11.5.1 节中所写的许多 LXML 逻辑:
import scrapyfrom scrapyspider.items import EmojiSpiderItemclass EmoSpider(scrapy.Spider):name = 'emo'allowed_domains = ['emoji-cheat-sheet.com']start_urls = ['http://www.emoji-cheat-sheet.com/',]def parse(self, response):headers = response.xpath('//h2|//h3')lists = response.xpath('//ul')all_items = [] ➊for header, list_cont in zip(headers, lists):section = header.xpath('text()').extract()[0] ➋for li in list_cont.xpath('li'):item = EmojiSpiderItem() ➌item['section'] = sectionspans = li.xpath('div/span')if len(spans):link = spans[0].xpath('@data-src').extract() ➍if link:item['emoji_link'] = response.url + link[0] ➎handle_code = spans[1].xpath('text()').extract()else:handle_code = li.xpath('div/text()').extract()if handle_code:item['emoji_handle'] = handle_code[0] ➏all_items.append(item) ➐return all_items ➑
❶ 由于每个页面使用多个对象,这行代码在 parse 方法的开始使用了一个列表,并在遍历页面的过程中,保存一个找到的对象的列表。
❷ 不同于在 LXML 脚本中调用 header.text,这行代码定位到文本小节(.xpath("text()")),并且使用 extract 函数抽取它。因为我们知道这个方法会返回一个列表,所以这段代码选择每个列表中第一个并且唯一的对象,将其赋值给 section。
❸ 这行代码定义对象。对于每一个列表对象,通过调用类名称与一对空括号创建了一个新的 EmojiSpiderItem 对象。
❹ 为了抽取数据属性,这行代码使用 XPath @ 选择器。这段代码选择第一个 span,并且抽取 @data-src 属性,这会返回一个列表。
❺ 为了创建完整的 emoji_link 属性,这行代码使用响应 URL 并且添加 @data-src 属性中第一个列表对象。为了设置对象的字段,使用字典语法,将键(即字段名称)赋值。如果前面代码没有找到 @data-src,那么这行代码不会执行。
❻ 为了组合一些代码,并且不重复我们自己的代码,这段代码找到 emoji 和声音的处理字符串,赋值给 emoji_handle 字段。
❼ 在列表元素每个循环的最后,这行代码追加新的对象到 all_items 列表。
❽ 在 parse 方法的最后,这行代码返回了所有找到的对象的列表。Scrapy 会在抓取中使用一个返回的对象或对象列表(通常通过保存、清洗或者以我们可以阅读和使用的格式输出数据)。
现在添加了 extract 方法调用,并且更具体地识别出了要从页面中抓取的文本与属性。我们移除了其中的一些 None 逻辑,因为 Scrapy 对象会自动了解拥有哪一个字段,不拥有哪个字段。出于这个原因,如果导出输出到 CSV 或 JSON,它会同时显示空(null)行和找到的值。现在已经更新了同 Scrapy 工作的代码,再一次调用 crawl 方法运行它。
scrapy crawl emo
你应该看到一些类似于第一个抓取的输出,只是多出了几行! Scrapy 会在解析网页时打印每一个找到的对象到日志。在最后,你会看到相同的总结输出,显示错误、调试信息和抓取对象的数量。
2015-06-03 18:13:51+0200 [emo] DEBUG: Scraped from<200 http://www.emoji-cheat-sheet.com/>{'emoji_handle': u'play butts','section': u'Campfire also supports a few sounds'}2015-06-03 18:13:51+0200 [emo] INFO: Closing spider (finished)2015-06-03 18:13:51+0200 [emo] INFO: Dumping Scrapy stats:{'downloaderrequest_bytes': 224,'downloader/request_count': 1,'downloader/request_method_count/GET': 1,'downloader/response_bytes': 143742,'downloader/response_count': 1,'downloader/response_status_count/200': 1,'finish_reason': 'finished','finish_time': datetime.datetime(2015, 6, 3, 16, 13, 51, 803765),'item_scraped_count': 924,'log_count/DEBUG': 927,'log_count/INFO': 7,'response_received_count': 1,'scheduler/dequeued': 1,'scheduler/dequeued/memory': 1,'scheduler/enqueued': 1,'scheduler/enqueued/memory': 1,'start_time': datetime.datetime(2015, 6, 3, 16, 13, 50, 857193)}2015-06-03 18:13:51+0200 [emo] INFO: Spider closed (finished)
Scrapy 在大约 1 秒的时间里解析 900 多个对象——令人惊讶!在查看日志时,我们看到所有的对象均被解析和添加。没有出现任何的错误;如果有的话,会在最后的输出中看到一个错误数量,类似于 DEBUG 和 INFO 输出行。
我们还没有通过脚本得到一个真正的文件或输出。可以使用一个内置的命令行参数设置一个。使用一些其他的参数选项尝试重新运行爬虫。
scrapy crawl emo -o items.csv
在抓取的最后,你的项目根目录中应该有一个 item.csv 文件。如果你打开它,应该会看到所有的数据都被导出到了 CSV 格式中。你同样可以导出 .json 和 .xml 文件,所以尽情地通过改变文件名尝试这些选项。
恭喜,你已经搭建了第一个网络爬虫!只需要几个文件和不到 50 行的代码,你就可以在 1 分钟以内解析一整个页面——超过 900 个对象,输出这些发现到一个简单可阅读并且可以轻松分享的格式文件里。正如你看到的那样,Scrapy 是一个非常强大又极其有用的工具。
12.2.2 使用Scrapy爬取整个网站
我们已经探索了使用 Scrapy shell 和 crawl 来爬取普通页面,但是如何利用 Scrapy 的能力和速度来爬取整个站点?为了研究 CrawlSpider 的能力,需要首先确定要爬取的内容。让我们尝试寻找 PyPI 主页(http://pypi.python.org)中与抓取相关的 Python 包。首先,查看一下页面,找出我们想要的数据。快速搜索“scrape”(https://pypi.python.org/pypi?:action=search&term=scrape&submit=search)显示了一整个列表的搜索结果,其中的每一个页面都有更多的信息,包括文档、一个相关包的链接、一个支持的 Python 版本的列表和最近下载的数量。
可以围绕这些数据构建一个对象模型。一般来说,如果不是与相同的数据关联,我们会为每一个抓取器创建一个新的项目;但是为了方便使用,我们使用和 emoji 抓取器相同的文件夹。从修改 items.py 文件开始:
# -*- coding: utf-8 -*-# 在这里定义为要抓取的对象定义模型## 参见文档:# http://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass EmojiSpiderItem(scrapy.Item):emoji_handle = scrapy.Field()emoji_link = scrapy.Field()section = scrapy.Field()class PythonPackageItem(scrapy.Item):package_name = scrapy.Field()version_number = scrapy.Field()package_downloads = scrapy.Field()package_page = scrapy.Field()package_short_description = scrapy.Field()home_page = scrapy.Field()python_versions = scrapy.Field()last_month_downloads = scrapy.Field()
我们在旧的类下面直接定义了新的对象类。在类之间保留几个空行,这样更容易阅读文件和看到类的不同之处。这里,添加了 Python 包页面中我们感兴趣的一些字段,包括过去一个月的下载量、包的主页、支持的 Python 版本以及版本号。
有了对象定义,可以使用 Scrapy shell 来研究 Scrapely 页面上的内容。Scrapely 是 Scrapy 作者的一个项目,使用 Python 来像屏幕一样阅读 HTML。如果还没有安装它,同样建议安装 IPython,这会确保你的输入和输出看起来和本书中的一样,并且提供了一些其他的 shell 工具。在 shell 中(后文指 scrapy shell),需要首先使用下面的命令抓取内容。
fetch('https://pypi.python.orgpypiscrapely/0.12.0')
可以尝试从页面顶端的 breadcrumb 标签中抓取版本号。它们在 ID 为 breadcrumb 的 div 中,我们可以编写一些 XPath 来找到它。
In [2]: response.xpath('//div[@id="breadcrumb"]')Out[2]: [<Selector xpath='//div[@id="breadcrumb"]'data=u'<div id="breadcrumb">\n <a h'>]
IPython 的 Out 信息显示我们已经正确地找到了 breadcrumb div。通过在浏览器的检视标签中检查元素,我们看到文本位于 div 中的一个锚标签中。我们需要使用 XPath 特化,告诉它通过下面这些行代码去查找子锚标签中的文本:
In [3]: response.xpath('//div[@id="breadcrumb"]/a/text()')Out[3]:[<Selector xpath='//div[@id="breadcrumb"]/a/text()' data=u'Package Index'>,<Selector xpath='//div[@id="breadcrumb"]/a/text()' data=u'scrapely'>,<Selector xpath='//div[@id="breadcrumb"]/a/text()' data=u'0.12.0'>]
现在可以在最后的 div 中看到版本号,在抽取的时候处理最后一个 div。使用正则表达式做一些测试,确保版本数据是一个数字(见 7.2.6 节),或者使用 Python 的 is_digit(见 7.2.3 节)。
现在看一下如何获取页面中略微复杂的部分:最近一个月的下载量。如果在浏览器中检查了这个元素,你会看到它位于一个 span 中的列表项中的无序列表中。你会注意到,其中没有任何一个元素有 CSS ID 或类。你还会注意到 span 不包括实际上的单词“month”(为了便于搜索)。让我们看一下是否可以得到一个有用的选择器。
In [4]: response.xpath('//li[contains(text(), "month")]')Out[4]: []
喔,使用 XPath 文本搜索寻找元素是不容易的。然而,在 XPath 中,一个好的技巧是如果你轻微地改变查询,解析相似的对象,有些时候会表现得完全不同。尝试运行这个命令:
In [5]: response.xpath('//li/text()[contains(., "month")]')Out[5]: [<Selector xpath='//li/text()[contains(., "month")]'data=u' downloads in the last month\n '>]
看到没?为什么一个有效,而其他的却没用呢?因为元素是位于 li 元素的 span,而其他文本位于 span 之后,这迷惑了 XPath 模式搜索的层次。页面结构越复杂,编写一个完美的选择器就越难。我们想要在第二个模式中做的有一点不同——我们说“给我位于 li 中且其中包含 month 的文本”,而不是“给我一个拥有 month 文本的 li 元素”。这里差别很小,但是处理混乱的 HTML 时,通过尝试不同的选择器处理困难的小节是有用处的。
但是我们真正需要的是包含下载数量的 span。可以使用 XPath 关系的魔力在链路上浏览并且定位 span。尝试下面的代码。
In [6]: response.xpath('//li/text()[contains(., "month")]/..')Out[6]: [<Selector xpath='//li/text()[contains(., "month")]/..' data=u'<li>\n<span>668</span> downloads in t'>]
通过使用 .. 操作符,回退到父节点,这样现在同时有了 span 后的文本和 span 本身。最后一步是选择 span,这样不需要担心剥离文本。
In [7]: response.xpath('//li/text()[contains(., "month")]/../span/text()')Out[7]: [<Selector xpath='//li/text()[contains(., "month")]/../span/text()'data=u'668'>]
棒!现在有了想要找到的数字,并且它应该在所有的页面上工作,因为它基于页面层次编写,并且没有尝试去“猜测”内容可能位于哪里。
首先编写一个能够使用 Spider 类正确解析 Scrapely 页面的抓取器,之后将它转换为使用 CrawlSpider 类的版本。循序渐进地解决一个有两三个因素的问题是个好方法,在完成一部分任务后再完成下一个部分。因为需要使用 CrawlSpider 调试两部分代码(抓取规则以找到匹配的页面和抓取页面本身),所以首先确认其中的一部分有效是比较好的做法。建议从构建一个抓取器(可以在一两个匹配的页面上工作)开始,之后编写抓取规则来测试爬取逻辑。
下面,看一下 Python 包页面的完整的 Spider。将它作为一个新的文件包含在 spiders 文件夹中,同 emo_spider.py 文件一起。我们称它为 package_spider.py。
import scrapyfrom scrapyspider.items import PythonPackageItemclass PackageSpider(scrapy.Spider):name = 'package'allowed_domains = ['pypi.python.org']start_urls = ['https://pypi.python.orgpypiscrapely/0.12.0','https://pypi.python.orgpypidc-campaign-finance-scrapers/0.5.1', ➊]def parse(self, response):item = PythonPackageItem() ➋item['package_page'] = response.urlitem['package_name'] = response.xpath('//div[@class="section"]/h1/text()').extract()item['package_short_description'] = response.xpath('//meta[@name="description"]/@content').extract() ➌item['home_page'] = response.xpath('//li[contains(strong, "Home Page:")]/a/@href').extract() ➍item['python_versions'] = []versions = response.xpath('//li/a[contains(text(), ":: Python ::")]/text()').extract()for v in versions:version_number = v.split("::")[-1] ➎item['python_versions'].append(version_number.strip()) ➏item['last_month_downloads'] = response.xpath('//li/text()[contains(., "month")]/../span/text()').extract()item['package_downloads'] = response.xpath('//table/tr/td/span/a[contains(@href,"pypi.python.org")]/@href' ➐).extract()return item ➑
❶ 这行代码添加一个我们没有研究过的额外的 URL。使用多个 URL 是一种从 Spider 转到 CrawlSpider 时快速检查代码整洁性和复用性的好方法。
❷ 对于这个抓取器,每个页面只需要一个对象。这行代码在 parse 方法的开始创建了这个对象。
❸ 在你解析时,学习一些关于搜索引擎优化(SEO)的知识是获得易读页面描述的一种很好的方式。大多数站点会为 Facebook、Pinterest 和其他共享信息的网站创建简短的描述、关键词、标题和其他元标签。这行代码为数据收集拉取描述。
❹ 包的“Home Page”URL 位于 li 中的一个 strong 标签中。一旦找到这个元素,这行代码只选择锚元素中的链接。
❺ 版本号链接位于一个使用 :: 分隔 Python 和版本号的表单对象中。版本号永远出现在最后,这样这行代码使用 :: 作为分隔符分割字符串,使用最后的元素。
❻ 这行代码追加版本文本(去除额外的空格)到 Python 版本数组。对象的 python_versions 键现在会保存所有的 Python 版本。
❼ 可以看到,在表格中有使用 pypi.python.org 域名的链接,而不是它们的 MD5 校验值。这行代码判断链接是否有正确的域名,并只抓取有正确域名的链接。
❽ 在 parse 方法的最后,Scrapy 希望我们返回一个对象(或一个对象列表)。这行代码返回这些对象。
运行这段代码(scrapy crawl package),你应该会得到两个对象,并且没有错误。然而,你会发现我们得到一些不同的数据。举个例子,对于每一个下载,我们的包数据没有一个好的支持的 Python 版本的列表。如果想要这个列表,可以从表格中的 PyVersion 字段解析,并将它与每一个下载匹配。你会怎样做这件事呢?(提示:这个字段位于每个数据行的第三列,XPath 允许你传递元素索引。)我们同样注意到数据有一些混乱,就像下面的输出(为了匹配页面进行了格式化;你的输出会看起来有一些不同)所展示的一样。
2015-09-10 08:19:34+0200 [package_test] DEBUG: Scraped from<200 https://pypi.python.orgpypiscrapely/0.12.0>{'home_page': [u'http://github.com/scrapy/scrapely'],'last_month_downloads': [u'668'],'package_downloads':[u'https://pypi.python.org/packages/2.7/s/' + \'scrapely/scrapely-0.12.0-py2-none-any.whl',u'https://pypi.python.org/packages/source/s/' + \'scrapely/scrapely-0.12.0.tar.gz'],'package_name': [u'scrapely 0.12.0'],'package_page': 'https://pypi.python.orgpypiscrapely/0.12.0','package_short_description':[u'A pure-python HTML screen-scraping library'],'python_versions': [u'2.6', u'2.7']}
有几个字段原本希望是字符串或整数值,但是取而代之的是一个字符串数组。让我们在定义爬虫规则之前创建一个辅助方法来清洗数据。
import scrapyfrom scrapyspider.items import PythonPackageItemclass PackageSpider(scrapy.Spider):name = 'package'allowed_domains = ['pypi.python.org']start_urls = ['https://pypi.python.orgpypiscrapely/0.12.0','https://pypi.python.orgpypidc-campaign-finance-scrapers/0.5.1',]def grab_data(self, response, xpath_sel): ➊data = response.xpath(xpath_sel).extract() ➋if len(data) > 1: ➌return dataelif len(data) == 1:if data[0].isdigit():return int(data[0]) ➍return data[0] ➎return [] ➏def parse(self, response):item = PythonPackageItem()item['package_page'] = response.urlitem['package_name'] = self.grab_data(response, '//div[@class="section"]/h1/text()') ➐item['package_short_description'] = self.grab_data(response, '//meta[@name="description"]/@content')item['home_page'] = self.grab_data(response, '//li[contains(strong, "Home Page:")]/a/@href')item['python_versions'] = []versions = self.grab_data(response, '//li/a[contains(text(), ":: Python ::")]/text()')for v in versions:item['python_versions'].append(v.split("::")[-1].strip())item['last_month_downloads'] = self.grab_data(response, '//li/text()[contains(., "month")]/../span/text()')item['package_downloads'] = self.grab_data(response,'//table/tr/td/span/a[contains(@href,"pypi.python.org")]/@href')return item
❶ 这行定义了一个新的方法以使用 self 对象(这样爬虫可以像普通方法一样调用它)、响应对象以及长长的 XPath 选择器来查找内容。
❷ 这行代码使用新的函数变量抽取数据。
❸ 如果数据的长度大于 1,这行代码返回列表。我们可能想要所有的数据,所以原样返回。
❹ 如果数据的长度等于 1,并且数据是一个数字,这行代码返回整数。这可能会是下载数量的情况。
❺ 如果数据的长度等于 1,但是不是一个数字,这行代码只返回这个数据。这会匹配包含链接和简单文本的字符串。
❻ 如果函数没有返回,这行代码返回一个空列表。这里使用一个列表,因为我们希望 extract 在没有找到数据的时候返回空列表。如果使用 None 类型或者空字符串,你可能需要修改其他的代码,来保存它到 CSV。
❼ 这行代码调用新的函数,并且使用下面的参数触发 self.grab_data:响应对象和 XPath 选择字符串。r 使用其他内置输出功能。
现在我们有了相当干净的数据和代码,并且更少地重复自己的代码。我们可以更加深入地优化它,但是为了不让你眼花缭乱,先来定义爬取规则。爬取规则由正则表达式实现,通过定义页面位置和遵循的 URL 类型,告诉爬虫去哪里爬取。(第 7 章介绍了正则表达式,是不是很棒?你现在已经是专业的了!)如果看一下包的链接(https://pypi.python.orgpypidc-campaign-finance-scrapers/0.5.1 和 https://pypi.python.orgpypiscrapely/0.12.0),可以看到以下相似点。
它们都有相同的域名,pypi.python.org,并且它们都使用 https。
在 URL 中,它们都有相同的路径模式:pypi
/ 。 库的名称使用小写字母和破折号,版本号由数字和句点组成。
可以使用这些相似性来定义正则规则。在脚本中编写它们之前,先在 Python 控制台中尝试它们。
import reurls = ['https://pypi.python.orgpypiscrapely/0.12.0','https://pypi.python.orgpypidc-campaign-finance-scrapers/0.5.1',]to_match = 'https://pypi.python.orgpypi[\w-]+/[\d\.]+' ➊for u in urls:if re.match(to_match, u):print re.match(to_match, u).group() ➋
❶ 这行代码找到一个使用 https、域名为 pypi.python.org 并且还有我们研究路径的链接。第一个部分是 pypi,第二个是有着符号“-”的小写文本(使用 [\w-]+ 可以轻松地匹配),最后一部分寻找有或没有句点的数字([\d.]+)。
❷ 这行代码输出了匹配的组。我们正在使用正则表达式的 match 方法,因为这是正则 Scrapy 爬虫所使用的。
我们有了一个匹配(确切地说,是两个!)。现在,最后看一下需要从哪里开始。Scrapy 爬虫会首先使用起始 URL 列表,然后跟随这些网页找到其他 URL。如果再看一下搜索结果页(https://pypi.python.org/pypi?:action=search&term=scrape&submit=search),我们会注意到页面使用相对 URL,这样只需要匹配 URL 路径。我们同样看到所有的链接都位于表格中,这样可以限制 Scrapy 查看以找到用来爬取链接的位置。知道这些后,通过添加爬取规则来更新文件。
from scrapy.contrib.spiders import CrawlSpider, Rule ➊from scrapy.contrib.linkextractors import LinkExtractor ➋from scrapyspider.items import PythonPackageItemclass PackageSpider(CrawlSpider): ➌name = 'package'allowed_domains = ['pypi.python.org']start_urls = ['https://pypi.python.org/pypi?%3A' + \'action=search&term=scrape&submit=search','https://pypi.python.org/pypi?%3A' + \'action=search&term=scraping&submit=search', ➍]rules = (Rule(LinkExtractor(allow=['pypi[\w-]+/[\d\.]+', ], ➎restrict_xpaths=['//table/tr/td', ], ➏),follow=True, ➐callback='parse_package', ➑),)def grab_data(self, response, xpath_sel):data = response.xpath(xpath_sel).extract()if len(data) > 1:return dataelif len(data) == 1:if data[0].isdigit():return int(data[0])return data[0]return []def parse_package(self, response):item = PythonPackageItem()item['package_page'] = response.urlitem['package_name'] = self.grab_data(response, '//div[@class="section"]/h1/text()')item['package_short_description'] = self.grab_data(response, '//meta[@name="description"]/@content')item['home_page'] = self.grab_data(response, '//li[contains(strong, "Home Page:")]/a/@href')item['python_versions'] = []versions = self.grab_data(response, '//li/a[contains(text(), ":: Python ::")]/text()')for v in versions:version = v.split("::")[-1]item['python_versions'].append(version.strip())item['last_month_downloads'] = self.grab_data(response, '//li/text()[contains(., "month")]/../span/text()')item['package_downloads'] = self.grab_data(response,'//table/tr/td/span/a[contains(@href,"pypi.python.org")]/@href')return item
❶ 这行代码同时导入 CrawlSpider 类和 Rule 类,因为在第一个爬虫中,我们需要它们。
❷ 这行代码导入了 LinkExtractor。默认的链接抽取器使用 LXML(我们知道如何编写它!)。
❸ 这行代码重新定义了 Spider,这样它从 CrawlSpider 类继承而来。由于修改了这种继承,需要定义一个 rules 属性。
❹ 包含了检索词为 scrape 和 scraping 的搜索页,以查看是否可以找到更多的 Python 包。如果你有不同的让脚本开始搜索的起始点,可以在这里添加一个长列表。
❺ 这行代码设置了 allow 来使用正则匹配页面上的链接。因为只需要相关的链接,所以只从匹配的链接开始。allow 接受一个列表,所以如果你有不止一个类型的 URL 想要匹配,可以在这里添加多个 allow 规则。
❻ 这行代码限制了爬虫到结果表格中。这意味着爬虫只会去表格列中的数据行寻找匹配链接。
❼ 这行告诉了跟随(即加载)匹配链接的规则。有些时候,对于一些页面你可能只想解析并获取内容,但是不需要跟随它的链接。如果想要让爬虫跟随页面链接,并且打开它们,你需要使用 follow=True。
❽ 赋值给规则一个回调函数,并且重新命名 parse 方法来确认没有与 Scrapy 的 CrawlSpider 类使用的解析方法混淆。现在解析方法叫作 parse_package,并且爬虫在跟随匹配的 URL 拿到我们想要抓取的页面后会调用这个方法。
你可以同运行一个普通的抓取器一样,运行这个爬虫:
scrapy crawl package
你已经正式地完成了第一个爬虫!是否还有待完善的地方?有一个容易修复的 bug 遗留在这段代码中了。你能找到它吗?如何修复它?[提示:查看你的 Python 版本,然后查看返回版本的方式(即永远返回一个列表),与 grab_data 返回数据对比。]看看你是否能够在爬虫脚本中修复这个问题。如果不能,可以参考本书仓库(https://github.com/jackiekazil/datawrangling),得到完整的修复后的代码。
Scrapy 是一个有效、快速、方便配置的工具。还有很多值得探索,你可以阅读该库的很棒的文档(http://doc.scrapy.org/en/latest/)。配置你的脚本来使用数据库和特殊的信息抽取工具,并且在自己的服务器上使用 Scrapyd(http://scrapyd.readthedocs.org/en/latest/)运行它们是很简单的。希望这是你之后众多 Scrapy 项目的第一个!
现在你理解了屏幕读取器、浏览器读取器和爬虫。让我们看看构建更加复杂的网页爬虫所需要知道的其他一些事情。
12.3 网络:互联网的工作原理,以及为什么它会让脚本崩溃
取决于运行抓取脚本的频率,以及每个脚本工作的重要性,你可能会碰到网络问题。是的,互联网正在尝试破坏你的脚本。为什么?因为互联网认为如果你真的在乎,你会重试。在网页抓取世界里丢失的连接、代理问题以及超时问题普遍存在。然而,有一些方法可以缓解这些问题。
在浏览器中,如果有页面信息没有正确加载,你就会点击刷新,立即发送另一个请求。对于抓取器,你可以模仿这种行为。如果你正在使用 Selenium,刷新内容会极其简单。 Selenium 的 webdriver 对象有一个 refresh 函数,就像浏览器一样。如果你已经填充了一个表单,需要重新提交表单,前进至下一页(有时这类似于浏览器的行为)。如果你需要同警告或弹出窗口交互,Selenium 提供了接受或拒绝信息所需的工具。
Scrapy 有内置的重试中间件。要启用它,你只需将它添加到项目的 settings.py 文件的中间件列表中。中间件(https://doc.scrapy.org/en/latest/topics/downloadermiddleware.html#module-scrapy.contrib.downloadermiddleware.retry)希望你在设置中设定一些默认值,以便它知道哪些 HTTP 响应码需要重试(例如,它需要只在返回码为 500 的时候重试吗?),以及重试的次数。
如果你正在使用自己的 Python 脚本和 LXML 或 BeautifulSoup,最好是捕获这些错误并确定处理它们的方法。大多数时间里,你会注意到 urllib2.HTTPError(https://docs.python.org/2/library/urllib2.html#urllib2.HTTPError)异常的优势;或者,如果你正在使用 requests,代码不会加载内容,并且失败。在 Python 中使用一个 try…except 代码块,你的代码可能看起来像下面一样。
import requestsimport urllib2resp = requests.get('http://sisinmaru.blog17.fc2.com/')if resp.status_code == 404: ➊print 'Oh no!!! We cannot find Maru!!'elif resp.status_code == 500:print 'Oh no!!! It seems Maru might be overloaded.'elif resp.status_code in [403, 401]:print 'Oh no!! You cannot have any Maru!'try:resp = urllib2.urlopen('http://sisinmaru.blog17.fc2.com/') ➋except urllib2.URLError: ➌print 'Oh no!!! We cannot find Maru!!'except urllib2.HTTPError, err: ➍if err.code == 500: ➎print 'Oh no!!! It seems Maru might be overloaded.'elif err.code in [403, 401]:print 'Oh no!! You cannot have any Maru!'else:print 'No Maru for you! %s' % err.code ➏except Exception as e: ➐print e
❶ 当使用 requests 库来查找网络错误时,检查响应的 status_code。这个属性会返回一个代表在 HTTP 响应中收到的代码的整数。这行代码测试响应是否为 404 错误。
❷ 如果正在使用 urllib2,将请求放在一个 try 语句中(正如这行代码一样)。
❸ 可能会从 urllib2 中看到的一个异常是 URLError。编写一个捕获方法是好的想法。如果它不能解析域名,可能会抛出这个错误。
❹ 可能看到的另外一个异常是 HTTPError。任何有关 HTTP 请求错误的响应都会抛出这个错误。通过添加冒号和 err,捕获了错误,并且将它保存在变量 err 中,这样可以打印错误到日志。
❺ 现在捕捉到了错误,并且将其赋值给前行代码中的 err,这行代码判断 code 属性,来查看 HTTP 错误码。
❻ 对于所有其他的 HTTP 错误,这行代码使用 else 通过格式化它到字符串,来展示错误码。
❼ 这行代码捕获其他所有可能碰到的错误,并且展示错误信息。赋值异常给变量 e,并且打印它,这样可以阅读异常信息。
巧妙地设计脚本,让它尽可能地抗失败,这是一个重要的步骤(第 14 章会更详细地讨论);同时确保在代码中有合适的 try…except 代码块来解释错误,也是进程中重要的一部分。除了 HTTP 错误,有些时候,页面花费过长的时间来加载。如果抓取器响应缓慢或碰到了延迟问题,我们可能会调整超时时间。
当编写和规模化脚本时,考虑延迟是很好的。如果脚本所连接的站点托管在另一个国家,你会经历网络延迟。因此你需要相应地调整超时时间,或者创建一个距离目标端点近的服务器。如果想要添加超时时间到 Selenium 和 Ghost.py 脚本,你可以在抓取工作开始的时候,直接添加到脚本中。对于 Selenium,使用 set_page_load_timeout(http://selenium-python.readthedocs.io/api.html#selenium.webdriver.remote.webdriver.WebDriver.set_page_load_timeout)方法,或使用隐式 / 显式的等待(http://selenium-python.readthedocs.io/waits.html),这样浏览器会等待代码中特定的部分加载。对于 Ghost.py,你可能需要传递 wait_timeout 参数,像 Ghost 类文档中定义的那样(http://ghost-py.readthedocs.io/en/latest/#ghost.Ghost)。
对于 Scrapy,抓取器的异步特性和对特定的 URL 重试若干次的能力,让超时设置变成了一个略微难办的问题。当然,你可以在 Scrapy 设置中使用 DOWNLOAD_TIMEOUT(http://doc.scrapy.org/en/latest/topics/settings.html#download-timeout)直接改变超时时间。
如果你正在编写自己的 Python 脚本,并且使用 LXML 或 BeautifulSoup 来解析页面,添加超时到调用是你的职责。如果使用 requests 或 urllib2,你可以在调用页面的时候直接这样做。在 requests 中,你可以直接将其作为一个参数,添加到 get 请求中(http://docs.python-requests.org/en/latest/user/quickstart/#timeouts)。对于 urllib2,你需要传递超时时间,作为 urlopen 方法(https://docs.python.org/2/library/urllib2.html#urllib2.urlopen)的参数之一。
如果你正经历持续的网络方面的问题,并且脚本需要依据一个稳定的日程运行,建议你创建一些日志,尝试在另外一个网络上运行(即不是你的家庭网络,来判断你的家庭互联网连接是否存在问题),并且测试是否在一个非高峰时间段运行会有帮助。
除了网络问题之外,你可能会找到其他破坏抓取脚本的问题,比如互联网在不停变化这一事实。
12.4 变化的互联网(或脚本为什么崩溃)
正如你知道的,网页的重新设计、更新的内容管理系统和页面结构的改变(一个新的广告系统、一个新的推荐网络等)是互联网中很正常的一部分。互联网成长并且变化着。因此,你的网页抓取脚本会崩溃。好消息是,有很多的站点只是每年更新一次,或几年改变一次。还有些改变不会影响页面结构(有时样式更新或广告更新不会改变代码的内容和结构)。不要彻底失去希望;很可能你的脚本会工作很长一段时间!
无论怎样,我们不想给你虚假的希望。你的脚本最终会崩溃。总有一天,你会继续运行它,然后发现它不再工作了。当发生这些情况时,给自己一个大大的拥抱,为自己冲一杯茶或咖啡,然后重新开始。
现在你知道了更多关于检验网站上的内容和为报告找出最有用的那部分的方法。你已经有了相当多的代码,大部分仍然能够工作。你现在处在一个好的调试阶段,并且有很多工具任你使用,以找到新的 div 或包含所需数据的表。
12.5 几句忠告
当抓取网页时,谨慎是很重要的。你还需要了解所在国家关于网页内容的法律。一般来说,如何做到谨慎是很显然的。不要把别人的内容当作自己的来用。不要使用已经声明不允许分享的内容。不要向别人或网站发送垃圾邮件。不要攻击网站或恶意地爬取站点。最基本地,不要做一个蠢人!如果你不能同母亲或其他亲近的人分享正在做的事情,并且感觉良好,那就不要做。
有几种方式来明确你在互联网上做的事情。许多抓取库允许你发送 User-Agent 字符串。你可以将自己的信息或者公司的信息放到这些字符串中,这样抓取者的信息就很清晰。同时,确保查看站点的 robot.txt 文件(http://www.robotstxt.org/robotstxt.html),它会告诉网页抓取器站点中禁止爬取的内容。
Disallow小节中。如果它们存在其中,你需要找到别的方式来获得数据,或者联系站点的拥有者,看看他们是否会通过其他方式为你提供数据。
在互联网上规规矩矩做好,并且在构建抓取器时做正确的事。这意味着你可以为自己的工作感到骄傲;不要麻烦律师、公司和政府;放心地使用收集的信息。
12.6 小结
现在在为难于解析内容的网页编写抓取器时,你应该感到胸有成竹。你可以使用 Selenium 或 Ghost.py 打开浏览器,读取一个网页,同页面交互,并且抽取数据。你可以使用 Scrapy 来爬取整个域名(或一系列域名),并且抽取大量的数据。你同样可以练习正则表达式语法,编写自己的 Python 类(在 Scrapy 的帮助下)。
掌握这些后,Python 代码就会顺其自然地完成了。你探索了一些 bash 命令。你积累了一些非常棒的与 shell 脚本交互的经验,正在成为一名专业的数据处理者。表 12-2 列出了本章中引入的新概念和工具。
表12-2:新的Python编程概念与库
| 概念/库 | 目的 |
|---|---|
| Selenium 库 | 该库用于直接同网页和它们的元素交互,你可以使用所选的浏览器,也可以使用无头浏览器。在你需要点击元素、在表单中输入信息,并且同需要几个请求来加载内容的页面交互时,表现良好 |
| PhantomJS 库 | JavaScript 库,作为无头浏览器,用于在服务器或无浏览器机器上进行网页抓取。还可用来只使用 JavaScript 编写抓取器 |
| Ghost.py 库 | 通过 Qt WebKit 而不是通过传统的浏览器来与网页交互的库。可以在需要浏览器等相似条件下使用,有编写原生 JavaScript 的能力 |
| Scrapy 库 | 用于跨越一个域名或多个不同域名爬取大量网页。在你需要研究多个域名或多种页面类型来收集数据时很有用处 |
| Scrapy 爬取规则 | 爬取规则告诉你的爬虫匹配 URL 结构,并识别出可能存在该 URL 的页面位置。这使得爬虫可以浏览并找到更多信息 |
最后,对于抓取器,确保你遵循一些基本的逻辑(见表 12-3)。
表12-3:使用哪一个抓取器
| 抓取器类型 | 库 | 使用场景 |
|---|---|---|
| 页面读取抓取器 | BeautifulSoup、LXML | 简单页面抓取,你想要的所有数据在一次请求后全部加载于页面上 |
| 基于浏览器的抓取器 | Selenium、PhantomJS、Ghost.py | 基于浏览器的抓取,你需要同页面上的元素交互,或这个页面需要不同的请求加载 |
| Web 爬虫 | Scrapy | 用快速和异步的方式跨越多个页面跟随链接或解析相似的页面。如果你需要跨越整个域名或一系列域名的多个匹配,这会很有用 |
后面几章关注如何拓展使用 API 的 Web 技巧,以及规模化和自动化数据。这些是将学到的所有知识整合为一系列可复用、可执行的脚本的最后几步——其中一些脚本不需要做任何事情就可运行。还记得你在开始阅读本书时想到的那些死记硬背的任务吗?以后再也不必死记硬背它们了——继续阅读!
