第 10 章 人脸识别
在这一章,我们将介绍以下主题:
从网络摄像头采集和处理视频信息
用Haar级联创建一个人脸识别器
创建一个眼睛和鼻子检测器
做主成分分析
做核主成分分析
做盲源分离
用局部二值模式直方图创建一个人脸识别器
10.1 简介
人脸识别是指在给定图像中识别某个人的工作,它不同于从给定图像中定位人脸位置的人脸检测。在人脸检测中,我们不关心这个人是谁,只需要识别包含脸部的图像区域。因此,在一个典型的生物人脸识别系统中,需要在识别脸部之前确定脸部的位置。
人脸识别对人类来说非常容易,毫不费力就可以做到,并且我们一直都在这样做,但是如何才能让机器做同样的事情呢?我们需要了解会利用脸部的哪个部分来识别一个人。人类的大脑有一个内部结构,它似乎可以对特定的特征做出相应的反应,例如边、角度、情绪等。人类的视觉皮层将这些特征综合起来,做出一个连贯性推断。如果希望机器也能同样精确地识别人脸,那就需要用同样的方式模拟这个问题。下面需要从输入的图像中提取相关特征,并把它转换成一个有意义的表示形式。
10.2 从网络摄像头采集和处理视频信息
本节将用网络摄像头采集视频数据。下面来看如何用OpenCV-Python从网络摄像头采集视频信息。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import cv2
(2) OpenCV提供了一个视频采集对象,可以利用该对象从网络摄像头采集图像。0输入参数指定网络摄像头的ID。如果连接的是USB摄像头,将有一个不同的ID:
# 初始化网络摄像头cap = cv2.VideoCapture(0)
(3) 定义网络摄像头采集的帧的比例系数:
# 定义网络摄像头采集图像的比例系数scaling_factor = 0.5
(4) 启动一个无限循环来采集帧,直到按下Esc键。从网络摄像头读取帧:
# 循环采集直到按下Esc键while True:# 采集当前画面ret, frame = cap.read()
(5) 调整帧的大小不是必须的,但是这在编写代码中很重要:
# 调整帧的大小frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor,interpolation=cv2.INTER_AREA)
(6) 显示帧:
# 显示帧cv2.imshow('Webcam', frame)
(7) 等待1 ms,然后采集下一帧:
# 检查是否按了Esc键c = cv2.waitKey(1)if c == 27:break
(8) 释放视频采集对象:
# 释放视频采集对象cap.release()
(9) 在结束代码之前关闭所有活动窗体:
# 关闭所有活动窗体cv2.destroyAllWindows()
(10) 全部代码已经包含在video_capture.py文件中。运行该代码,可以从网络摄像头中看到类似如图10-1所示的图像。

图 10-1
10.3 用Haar级联创建一个人脸识别器
正如前面讨论过的,人脸检测是确定输入图像中人脸位置的过程。我们将用Haar级联来做人脸检测。Haar级联通过在多个尺度上从图像中提取大量的简单特征来实现。简单特征主要指边、线、矩形特征等,这些特征都非常易于计算,然后通过创建一系列简单的分类器来做训练。使用自适应增强技术可以使得这个过程更健壮,更多细节可以查看http://docs.opencv.org/3.1.0/d7/d8b/tutorial_py_face_detection.html#gsc.tab=0。下面来看如何在网络摄像头采集的视频帧中确定人脸位置。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import cv2import numpy as np
(2) 加载人脸检测级联文件。这是可以用作检测器的训练模型:
# 导入人脸检测级联文件face_cascade = cv2.CascadeClassifier('cascade_files/haarcascade_frontalface_alt.xml')
(3) 确定级联文件是否正确地加载:
# 确定级联文件是否正确地加载if face_cascade.empty():raise IOError('Unable to load the face cascade classifier xml file')
(4) 生成一个视频采集对象:
# 初始化视频采集对象cap = cv2.VideoCapture(0)
(5) 定义图像向下采样的比例系数:
# 定义图像向下采样的比例系数scaling_factor = 0.5
(6) 循环采集直到按下Esc键:
# 循环采集直到按下Esc键while True:# 采集当前帧并进行调整ret, frame = cap.read()
(7) 调整帧的大小:
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor,interpolation=cv2.INTER_AREA)
(8) 将图像转为灰度图。这里需要灰度图像来运行人脸检测器:
# 将图像转为灰度图gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
(9) 在灰度图像上运行人脸检测器。参数1.3是指每个阶段的乘积系数。参数5是指每个候选矩形应该拥有的最小近邻数量,这样我们可以维持这一数量。候选矩形是指人脸可能被检测到的候选区域:
# 在灰度图像上运行人脸检测器face_rects = face_cascade.detectMultiScale(gray, 1.3, 5)
(10) 对于每个检测到的人脸区域,在其周围画出矩形:
# 在脸部画出矩形for (x,y,w,h) in face_rects:cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
(11) 展示输出图像:
# 展示输出图像cv2.imshow('Face Detector', frame)
(12) 在下一次迭代之前等待1 ms,如果用户按下Esc键,就跳出循环:
# 检查是否按下Esc键c = cv2.waitKey(1)if c == 27:break
(13) 在结束代码之前,释放并销毁所有对象:
# 释放视频采样对象并关闭窗口cap.release()cv2.destroyAllWindows()
(14) 全部代码已经包含在face_detector.py文件中。运行该代码,可以看到从网络摄像视频文件中人脸被检测出来了,如图10-2所示。
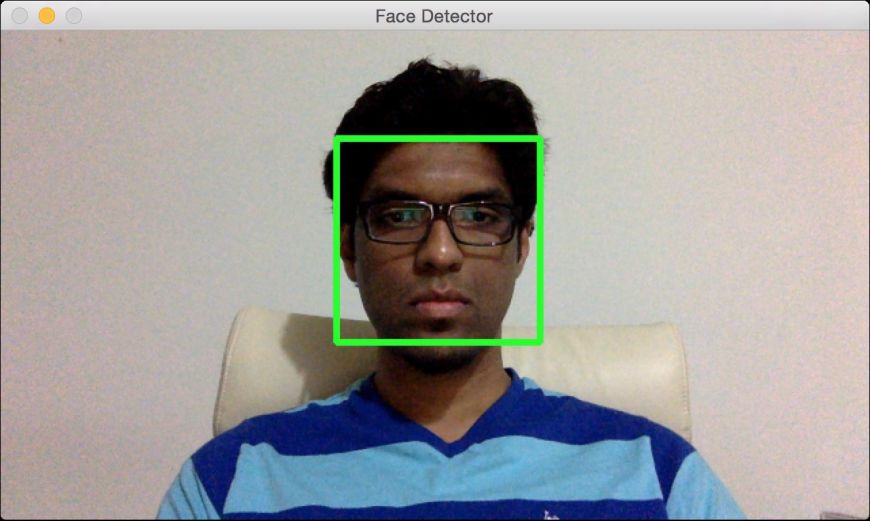
图 10-2
10.4 创建一个眼睛和鼻子检测器
Haar级联方法可以被扩展应用于各种对象的检测。接下来看看如何利用该方法检测输入视频文件中的眼睛和鼻子。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import cv2import numpy as np
(2) 加载人脸、眼睛和鼻子级联文件:
# 加载人脸、眼睛和鼻子级联文件face_cascade = cv2.CascadeClassifier('cascade_files/haarcascade_frontalface_alt.xml')eye_cascade = cv2.CascadeClassifier('cascade_files/haarcascade_eye.xml')nose_cascade = cv2.CascadeClassifier('cascade_files/haarcascade_mcs_nose.xml')
(3) 确定级联文件是否正确地加载:
# 检查脸部级联文件是否加载if face_cascade.empty():raise IOError('Unable to load the face cascade classifier xml file')# 检查眼睛级联文件是否加载if eye_cascade.empty():raise IOError('Unable to load the eye cascade classifier xml file')# 检查鼻子级联文件是否加载if nose_cascade.empty():raise IOError('Unable to load the nose cascade classifier xml file')
(4) 初始化视频采集对象:
# 初始化视频采集对象并定义比例系数cap = cv2.VideoCapture(0)
(5) 定义比例系数:
scaling_factor = 0.5
(6) 重复循环直至用户按下Esc键:
while True:# 读取当前帧画面,调整大小,转为灰度图ret, frame = cap.read()
(7) 调整帧的大小:
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor,interpolation=cv2.INTER_AREA)
(8) 将图像转为灰度图:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
(9) 在灰度图像上运行人脸检测器:
# 在灰度图像上运行人脸检测器faces = face_cascade.detectMultiScale(gray, 1.3, 5)
(10) 因为眼睛和鼻子总是位于脸部区域,所以这里仅在脸部区域运行检测器:
# 在每张脸的矩形区域运行眼睛和鼻子检测器for (x,y,w,h) in faces:
(11) 提取人脸ROI信息:
# 从彩色与灰度图中提取人脸ROI信息roi_gray = gray[y:y+h, x:x+w]roi_color = frame[y:y+h, x:x+w]
(12) 运行眼睛检测器:
# 在灰度图ROI信息中检测眼睛eye_rects = eye_cascade.detectMultiScale(roi_gray)
(13) 运行鼻子检测器:
# 在灰度图ROI信息中检测鼻子nose_rects = nose_cascade.detectMultiScale(roi_gray, 1.3, 5)
(14) 在眼睛周围画圈:
# 在眼睛周围画绿色的圈for (x_eye, y_eye, w_eye, h_eye) in eye_rects:center = (int(x_eye + 0.5*w_eye), int(y_eye + 0.5*h_eye))radius = int(0.3 * (w_eye + h_eye))color = (0, 255, 0)thickness = 3cv2.circle(roi_color, center, radius, color, thickness)
(15) 在鼻子周围画矩形:
for (x_nose, y_nose, w_nose, h_nose) in nose_rects:cv2.rectangle(roi_color, (x_nose, y_nose), (x_nose+w_nose,y_nose+h_nose), (0,255,0), 3)break
(16) 展示该图像:
# 展示图像cv2.imshow('Eye and nose detector', frame)
(17) 在下一次迭代之前等待1 ms,如果用户按下Esc键,就跳出循环:
# 检查是否按了Esc键c = cv2.waitKey(1)if c == 27:break
(18) 在结束代码之前,释放并销毁所有对象:
# 释放视频采样对象并关闭窗口cap.release()cv2.destroyAllWindows()
(19) 全部代码已经包含在eye_nose_detector.py文件中。运行该代码,可以看到网络摄像视频文件中的眼睛和鼻子被检测出来了,如图10-3所示。
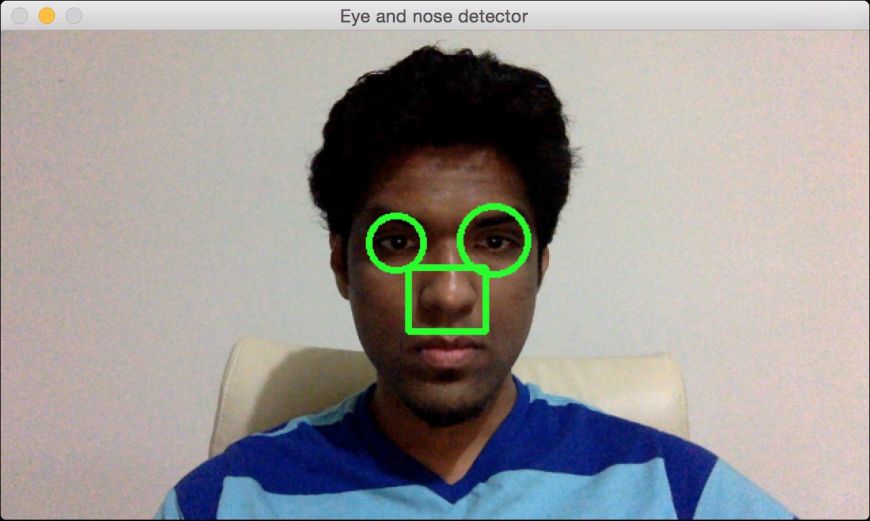
图 10-3
10.5 做主成分分析
主成分分析(Principal Components Analysis,PCA)是一个降低维度的技术,常用于计算机视觉和机器学习中。当需要处理很大的特征维度时,训练机器学习系统变得异常昂贵,因此需要在训练系统之前降低数据的维度。但是,降低维度时,我们并不想损失数据中的重要信息,此时PCA便是最佳选择。PCA识别数据中的重要成分,并将其按照重要程度排序。你可以在http://dai.fmph.uniba.sk/courses/ml/sl/PCA.pdf中了解更多细节。PCA 也常用于人脸识别系统。接下来看看如何对输入数据做主成分分析。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npfrom sklearn import decomposition
(2) 为输入数据定义5个维度。前两个维度是独立的,但是后3个维度将依赖于前两个维度。也就是说,可以去掉后3个维度,因为它们并没有提供任何新信息:
# 定义特征x1 = np.random.normal(size=250)x2 = np.random.normal(size=250)x3 = 2*x1 + 3*x2x4 = 4*x1 - x2x5 = x3 + 2*x4
(3) 创建一个带这些特征的数据集:
# 创建特征数据集X = np.c_[x1, x3, x2, x5, x4]
(4) 创建一个PCA对象:
# 创建一个PCApca = decomposition.PCA()
(5) 对输入数据做主成分分析(PCA):
pca.fit(X)
(6) 打印维度的方差:
# 打印方差variances = pca.explained_variance_print '\nVariances in decreasing order:\n', variances
(7) 如果一个特定的维度是有用的,那么它应该有一个有意义的方差值。设置一个阈值并确定重要的维度:
# 找出有用的维度数量thresh_variance = 0.8num_useful_dims = len(np.where(variances > thresh_variance)[0])print '\nNumber of useful dimensions:', num_useful_dims
(8) 正如之前提到的,PCA识别只有两个维度在这个数据集中很重要:
# 只有两个维度是有效的pca.n_components = num_useful_dims
(9) 将数据集从5维转换为二维:
X_new = pca.fit_transform(X)print '\nShape before:', X.shapeprint 'Shape after:', X_new.shape
(10) 全部代码已经包含在pca.py文件中。运行该代码,可以在终端看到如图10-4所示的结果。
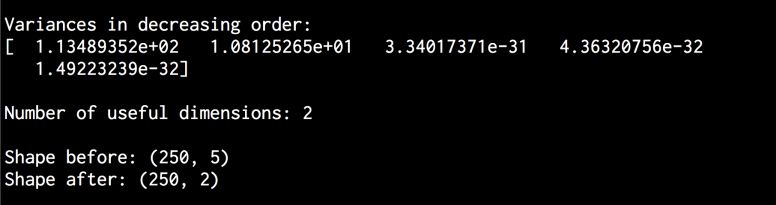
图 10-4
10.6 做核主成分分析
PCA能很好地降低维度,但PCA是以线性方式工作的,如果数据集不是以线性方式组织的,那么PCA并不能实现其功能。但是核主成分分析可以很好地解决这个问题,关于核主成分分析的细节介绍可参考http://www.ics.uci.edu/~welling/classnotes/papers_class/KernelPCA.pdf。接下来看看如何对输入数据做核主成分分析,同时将其与主成分分析进行对比。
详细步骤
(1) 创建一个Python文件,并且导入以下程序包:
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.decomposition import PCA, KernelPCAfrom sklearn.datasets import make_circles
(2) 定义随机数发生器的种子值,以便产生用于分析的数据示例:
# 定义随机数发生器的种子值np.random.seed(7)
(3) 生成以同心圆分布的数据,以演示PCA在这种情况下是如何工作的:
# 生成样本X, y = make_circles(n_samples=500, factor=0.2, noise=0.04)
(4) 对这组数据做主成分分析:
# 做主成分分析pca = PCA()X_pca = pca.fit_transform(X)
(5) 对输入数据做核主成分分析:
# 做核主成分分析kernel_pca = KernelPCA(kernel="rbf", fit_inverse_transform=True, gamma=10)X_kernel_pca = kernel_pca.fit_transform(X)X_inverse = kernel_pca.inverse_transform(X_kernel_pca)
(6) 画出原始输入数据:
# 画出原始输入数据class_0 = np.where(y == 0)class_1 = np.where(y == 1)plt.figure()plt.title("Original data")plt.plot(X[class_0, 0], X[class_0, 1], "ko", mfc='none')plt.plot(X[class_1, 0], X[class_1, 1], "kx")plt.xlabel("1st dimension")plt.ylabel("2nd dimension")
(7) 画出主成分分析后的数据:
# 画出主成分分析后的数据plt.figure()plt.plot(X_pca[class_0, 0], X_pca[class_0, 1], "ko", mfc='none')plt.plot(X_pca[class_1, 0], X_pca[class_1, 1], "kx")plt.title("Data transformed using PCA")plt.xlabel("1st principal component")plt.ylabel("2nd principal component")
(8) 画出核主成分分析后的数据:
# 画出核主成分分析后的数据plt.figure()plt.plot(X_kernel_pca[class_0, 0], X_kernel_pca[class_0, 1], "ko", mfc='none')plt.plot(X_kernel_pca[class_1, 0], X_kernel_pca[class_1, 1], "kx")plt.title("Data transformed using Kernel PCA")plt.xlabel("1st principal component")plt.ylabel("2nd principal component")
(9) 用核方法将数据转换回原始空间,查看是否存在这样的可逆关系:
# 用核方法将数据转换回原始空间plt.figure()plt.plot(X_inverse[class_0, 0], X_inverse[class_0, 1], "ko", mfc='none')plt.plot(X_inverse[class_1, 0], X_inverse[class_1, 1], "kx")plt.title("Inverse transform")plt.xlabel("1st dimension")plt.ylabel("2nd dimension")plt.show()
(10) 全部代码已经包含在kpca.py文件中。运行该代码,可以看到4幅图像。第一幅图像是原始数据,如图10-5所示。
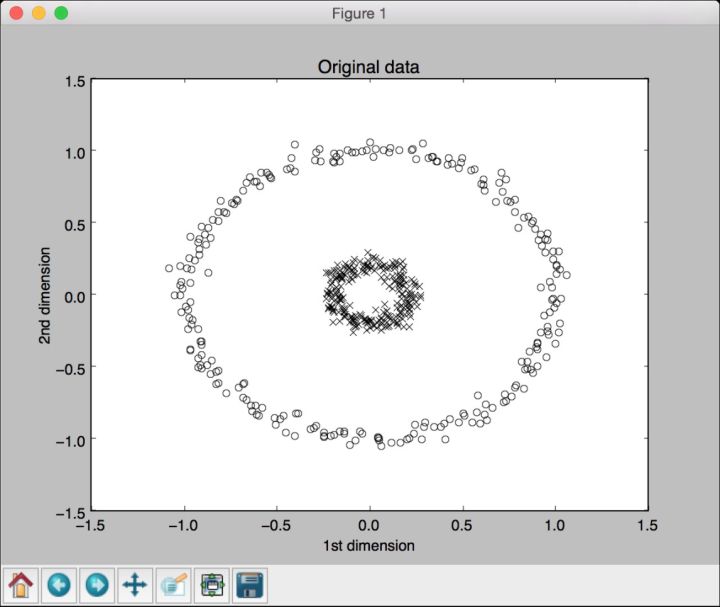
图 10-5
第二幅图像是运行主成分分析后的数据,如图10-6所示。
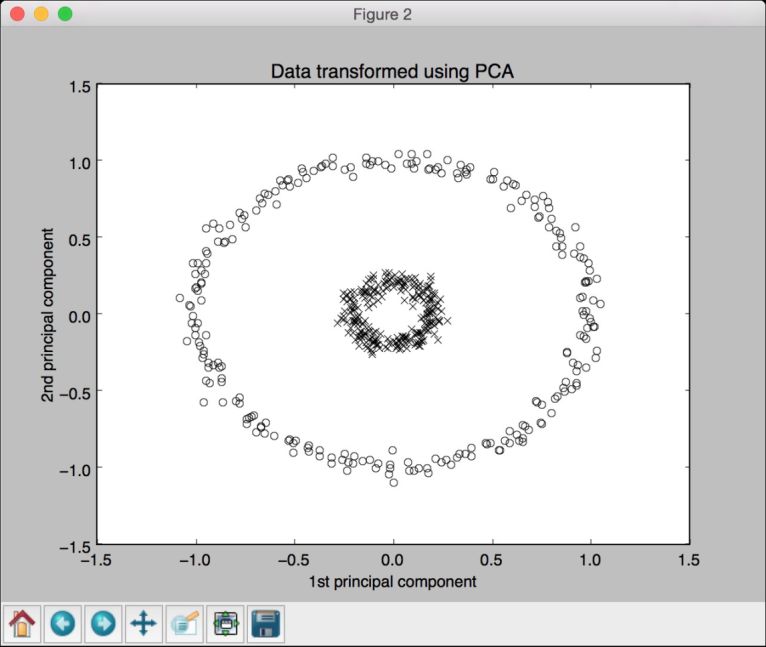
图 10-6
第三幅图像是运行核主成分分析后的数据,如图10-7所示。注意,点都聚集到图像的右半部分。
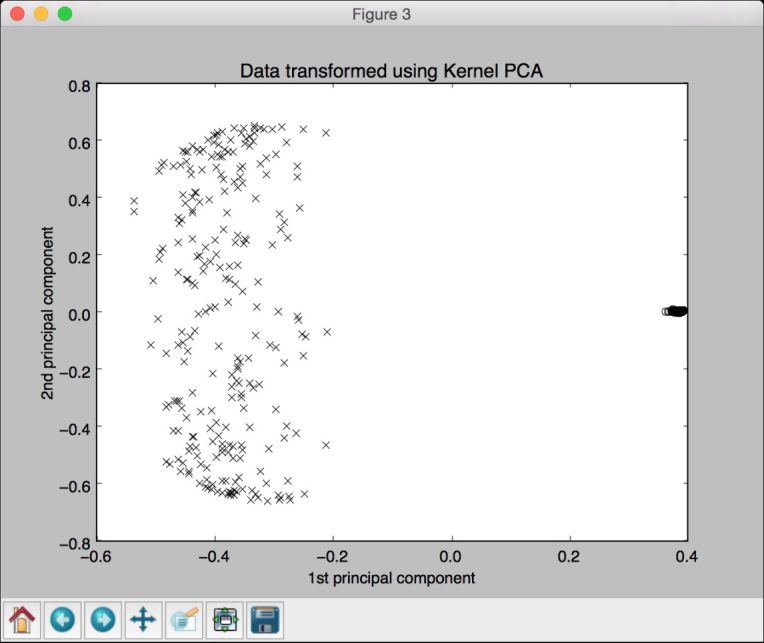
图 10-7
第四幅图像展示了将数据逆变换回其原始空间,如图10-8所示。
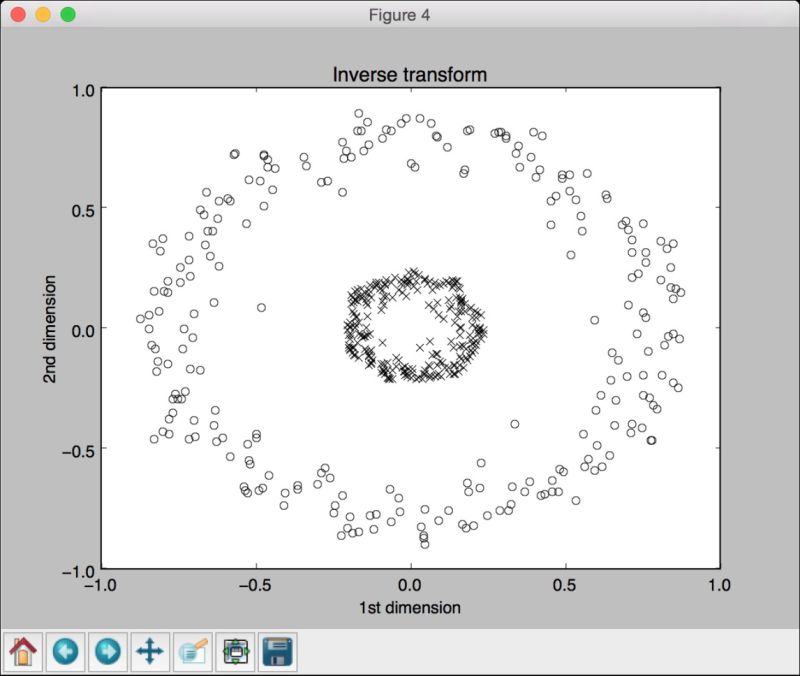
图 10-8
10.7 做盲源分离
盲源分离是指将信号从混合体中分离出来的过程。假设一组不同的信号发生器生成了不同的信号,而一个公共接收机接收到了所有这些信号。现在,我们的工作是利用这些信号的性质将这些信号从混合体中分离出来。我们将用独立成分分析(Independent Components Analysis,ICA)算法来实现。关于独立成分分析的细节可查看http://www.mit.edu/~gari/teaching/6.555/LECTURE_NOTES/ch15_bss.pdf。接下来看看如何实现。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import numpy as npimport matplotlib.pyplot as pltfrom scipy import signalfrom sklearn.decomposition import PCA, FastICA
(2) 本例将用到mixture_of_signals.txt文件提供的数据。加载该数据:
# 加载数据input_file = 'mixture_of_signals.txt'X = np.loadtxt(input_file)
(3) 创建ICA对象:
# 计算ICAica = FastICA(n_components=4)
(4) 基于ICA重构信号:
# 重构信号signals_ica = ica.fit_transform(X)
(5) 提取混合矩阵:
# 提取混合矩阵mixing_mat = ica.mixing_
(6) 执行PCA做对比:
# 执行PCApca = PCA(n_components=4)signals_pca = pca.fit_transform(X) # 基于正交成分重构信号
(7) 定义信号列表来将其画出:
# 定义画图参数models = [X, signals_ica, signals_pca]
(8) 指定颜色:
colors = ['blue', 'red', 'black', 'green']
(9) 画出输入信号:
# 画出输入信号plt.figure()plt.title('Input signal (mixture)')for i, (sig, color) in enumerate(zip(X.T, colors), 1):plt.plot(sig, color=color)
(10) 画出利用ICA分离的信号:
# 画出利用ICA分离的信号plt.figure()plt.title('ICA separated signals')plt.subplots_adjust(left=0.1, bottom=0.05, right=0.94,top=0.94, wspace=0.25, hspace=0.45)
(11) 用不同的颜色画出子图:
for i, (sig, color) in enumerate(zip(signals_ica.T, colors), 1):plt.subplot(4, 1, i)plt.title('Signal ' + str(i))plt.plot(sig, color=color)
(12) 画出用PCA分离的信号:
# 画出PCA信号plt.figure()plt.title('PCA separated signals')plt.subplots_adjust(left=0.1, bottom=0.05, right=0.94,top=0.94, wspace=0.25, hspace=0.45)
(13) 用不同的颜色画出各子图:
for i, (sig, color) in enumerate(zip(signals_pca.T, colors), 1):plt.subplot(4, 1, i)plt.title('Signal ' + str(i))plt.plot(sig, color=color)plt.show()
(14) 全部代码已经包含在blind_source_separation.py文件中。运行该代码,可以看到3幅图像。第一幅图像是原始数据,也就是信号的混合体,如图10-9所示。
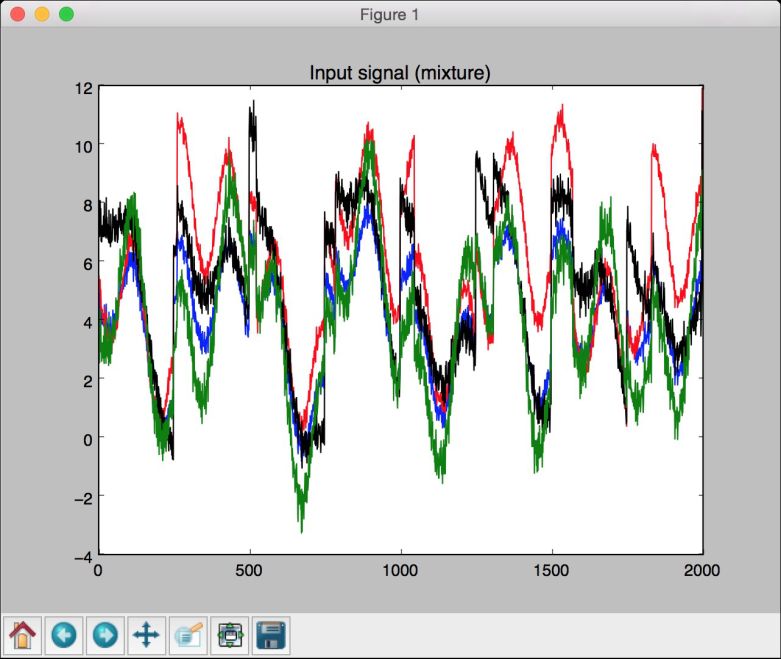
图 10-9
第二幅图像是用ICA分离的信号,如图10-10所示。
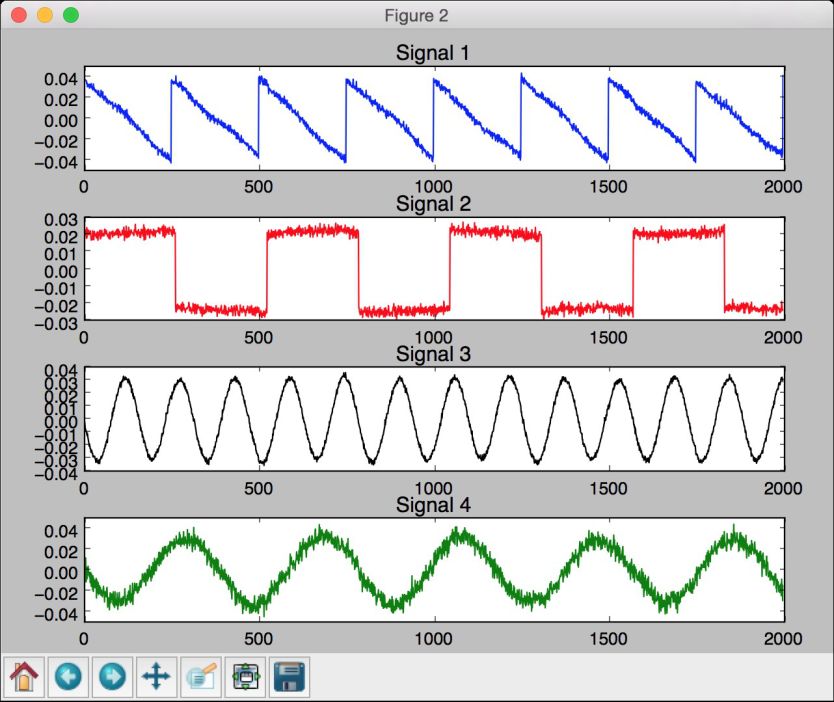
图 10-10
第三幅图像是用PCA分离的信号,如图10-11所示。
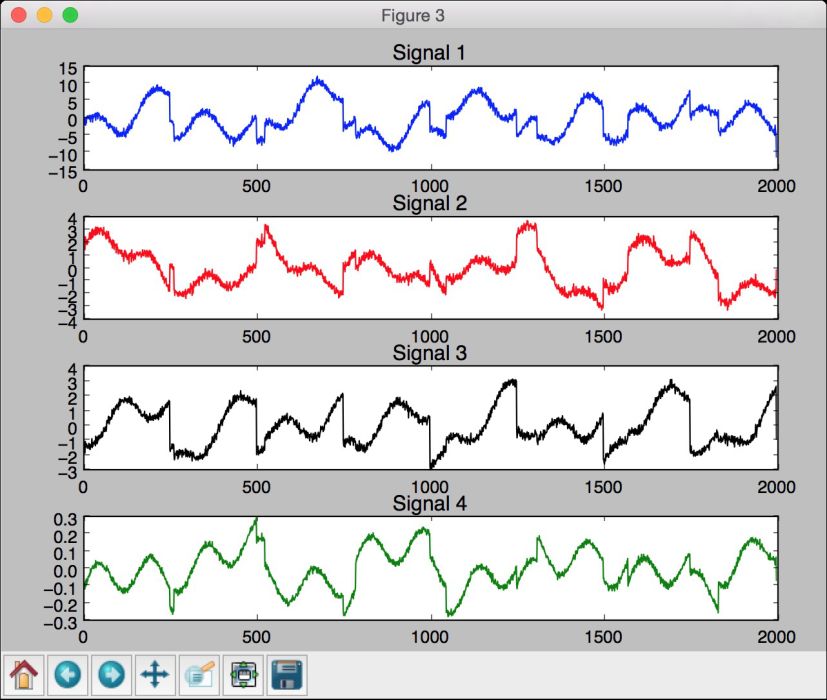
图 10-11
10.8 用局部二值模式直方图创建一个人脸识别器
现在已经准备好创建人脸识别器了。接下来需要一个人脸数据集来做训练,所以这里提供了一个faces_dataset文件夹,该文件夹中包含足够的图像可以用来做训练。该数据集是http://www.vision.caltech.edu/Image_Datasets/faces/faces.tar给出的一个子集,包含了一定数量的图像,可以利用这些图像来训练一个人脸识别系统。
我们将用局部二值模式直方图(Local Binary Patterns Histograms)创建人脸识别系统。在数据集中,你可以看到不同的人。接下来的工作是构建一个能将每个人从其他人中区分出来的系统。如果看到从未见过的图像,系统会将其分派到已有的类中。更多关于局部二值模式直方图的细节信息可查看http://docs.opencv.org/2.4/modules/contrib/doc/facerec/facerec_tutorial.html#local-binary-patterns-histograms。下面看看如何创建一个人脸识别器。
详细步骤
(1) 创建一个Python文件,并导入以下程序包:
import osimport cv2import numpy as npfrom sklearn import preprocessing
(2) 定义一个类来处理与类标签编码相关的所有任务:
# 定义一个类来处理与类标签编码相关的所有任务class LabelEncoder(object):
(3) 定义一个方法来为这些标签编码。在输入训练数据中,标签用单词表示,但我们需要数字来训练系统。该方法将定义一个预处理对象,该对象将单词转换成数字,同时保留这种前向后向的映射关系:
# 将单词转换成数字的编码方法def encode_labels(self, label_words):self.le = preprocessing.LabelEncoder()self.le.fit(label_words)
(4) 定义一个将单词转换成数字的方法:
# 将输入单词转换成数字def word_to_num(self, label_word):return int(self.le.transform([label_word])[0])
(5) 定义一个方法,用于将数字转换回其原始单词:
# 将数字转换为单词def num_to_word(self, label_num):return self.le.inverse_transform([label_num])[0]
(6) 定义一个方法,用于从输入文件夹中提取图像和标签:
# 从输入文件夹中提取图像和标签def get_images_and_labels(input_path):label_words = []
(7) 对输入文件夹做递归迭代,提取所有图像的路径:
# 对输入文件夹做递归迭代并追加文件for root, dirs, files in os.walk(input_path):for filename in (x for x in files if x.endswith('.jpg')):filepath = os.path.join(root, filename)label_words.append(filepath.split('/')[-2])
(8) 初始化变量:
# 初始化变量images = []le = LabelEncoder()le.encode_labels(label_words)labels = []
(9) 为训练解析输入目录:
# 解析输入目录for root, dirs, files in os.walk(input_path):for filename in (x for x in files if x.endswith('.jpg')):filepath = os.path.join(root, filename)
(10) 将当前图像读取成灰度格式:
# 将当前图像读取成灰度格式image = cv2.imread(filepath, 0)
(11) 从文件夹路径中提取标签:
# 从文件夹路径中提取标签name = filepath.split('/')[-2]
(12) 对该图像做人脸检测:
# 做人脸检测faces = faceCascade.detectMultiScale(image, 1.1, 2, minSize=(100,100))
(13) 提取ROI属性值,并将这些值和标签编码器返回:
# 循环处理每一张脸for (x, y, w, h) in faces:images.append(image[y:y+h, x:x+w])labels.append(le.word_to_num(name))return images, labels, le
(14) 定义main函数,并定义人脸级联文件的路径:
if __name__=='__main__':cascade_path = "cascade_files/haarcascade_frontalface_alt.xml"path_train = 'faces_dataset/train'path_test = 'faces_dataset/test'
(15) 加载人脸级联文件:
# 加载人脸级联文件faceCascade = cv2.CascadeClassifier(cascade_path)
(16) 生成局部二值模式直方图人脸识别器对象:
# 生成局部二值模式直方图人脸识别器recognizer = cv2.face.createLBPHFaceRecognizer()
(17) 为输入路径提取图像、标签和标签编码器:
# 从训练数据集中提取图像、标签和标签编码器images, labels, le = get_images_and_labels(path_train)
(18) 用提取的数据训练人脸识别器:
# 训练人脸识别器print "\nTraining..."recognizer.train(images, np.array(labels))
(19) 用未知数据测试人脸识别器:
# 用未知数据测试人脸识别器print '\nPerforming prediction on test images...'stop_flag = Falsefor root, dirs, files in os.walk(path_test):for filename in (x for x in files if x.endswith('.jpg')):filepath = os.path.join(root, filename)
(20) 加载图像:
# 读取图像predict_image = cv2.imread(filepath, 0)
(21) 用人脸检测器确定人脸的位置:
# 检测人脸faces = faceCascade.detectMultiScale(predict_image, 1.1,2, minSize=(100,100))
(22) 对于每个人脸ROI,运行人脸识别器:
# 循环处理每一张脸for (x, y, w, h) in faces:# Predict the outputpredicted_index, conf = recognizer.predict(predict_image[y:y+h, x:x+w])
(23) 将标签转换为单词:
# 将标签转换为单词predicted_person = le.num_to_word(predicted_index)
(24) 在输出图像中叠加文字,并将其展示:
# 在输出图像中叠加文字,并显示图像cv2.putText(predict_image, 'Prediction: ' + predicted_person,(10,60), cv2.FONT_HERSHEY_SIMPLEX, 2, (255,255,255), 6)cv2.imshow("Recognizing face", predict_image)
(25) 检查用户是否按下Esc键。如果有,则跳出循环:
c = cv2.waitKey(0)if c == 27:stop_flag = Truebreakif stop_flag:break
(26) 全部代码已经包含在face_recognizer.py文件中。运行该代码,可以得到一个输出窗体,窗体中显示测试图像的预测输出。按下空格键可以继续循环。测试图像中有3个不同的人。第一个人的输出结果如图10-12所示。

图 10-12
第二个人的输出结果如图10-13所示。

图 10-13
第三个人的输出结果如图10-14所示。

图 10-14
