第 5 章 多视图几何
本章讲解如何处理多个视图,以及如何利用多个视图的几何关系来恢复照相机位置信息和三维结构。通过在不同视点拍摄的图像,我们可以利用特征匹配来计算出三维场景点以及照相机位置。本章会介绍一些基本的方法,展示一个三维重建的完整例子;本章最后将介绍如何由立体图像进行致密深度重建。
5.1 外极几何
多视图几何是利用在不同视点所拍摄图像间的关系,来研究照相机之间或者特征之间关系的一门科学。图像的特征通常是兴趣点,本章使用的也是兴趣点特征。多视图几何中最重要的内容是双视图几何。
如果有一个场景的两个视图以及视图中的对应图像点,那么根据照相机间的空间相对位置关系、照相机的性质以及三维场景点的位置,可以得到对这些图像点的一些几何关系约束。我们通过外极几何来描述这些几何关系。本节简要介绍外极几何的基本内容。关于外极几何的更多内容,参阅文献 [13]。
没有关于照相机的先验知识,会出现固有二义性,因为三维场景点 X 经过 4×4 的 单应性矩阵 H 变换为 H X 后,则 H X 在照相机 PH-1 里得到的图像点和 X 在照相机 P 里得到的图像点相同。利用照相机方程,可以将上述问题描述为:

因此,当我们分析双视图几何关系时,总是可以将照相机间的相对位置关系用单应性矩阵加以简化。这里的单应性矩阵通常只做刚体变换,即只通过单应矩阵变换了坐标系。一个比较好的做法是,将原点和坐标轴与第一个照相机对齐,则:
P1 = K1[I|0]和P2 = K2[R|t]
为了方便读者阅读,我们在这里采取第 4 章的符号,其中 K1 和 K2 是标定矩阵,R 是第二个照相机的旋转矩阵,t 是第二个照相机的平移向量。利用这些照相机参数矩阵,我们可以找到点 X 的投影点 x1 和 x2(分别对应于投影矩阵 P1 和 P2)的关系。这样,我们可以从寻找对应的图像出发,恢复照相机参数矩阵。
同一个图像点经过不同的投影矩阵产生的不同投影点必须满足:
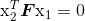 (5.1)
(5.1)
其中:
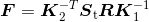
矩阵 St 为反对称矩阵:
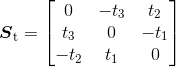 (5.2)
(5.2)
公式(5.1)为外极约束条件。矩阵 F 为基础矩阵。基础矩阵可以由两照相机的参数矩阵(相对旋转 R 和平移 t)表示。由于 det(F)=0,所以基础矩阵的秩小于等于 2。 我们将在估计 F 的算法中用到这些性质。
上面的公式表明,我们可以借助 F 来恢复出照相机参数,而 F 可以从对应的投影图像点计算出来。在不知道照相机内参数(K1 和 K2)的情况下,仅能恢复照相机的投影变换矩阵。在知道照相机内参数的情况下,重建是基于度量的。所谓度量重建,即能够在三维重建中正确地表示距离和角度 1。
1重建的绝对尺度不能恢复,但在实际中,这并不是个问题。
利用上面的理论处理一些图像数据前,我们还需要了解一些几何学知识。给定图像中的一个点,例如第二个视图中的图像点 x2,利用公式(5.1),我们找到对应第一幅图像的一条直线:
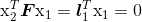
其中 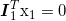 是第一幅图像中的一条直线。这条线称为对应于点 x2 的外极线,也就是说,点 x2 在第一幅图像中的对应点一定在这条线上。所以,基础矩阵可以将对应点的搜索限制在外极线上。
是第一幅图像中的一条直线。这条线称为对应于点 x2 的外极线,也就是说,点 x2 在第一幅图像中的对应点一定在这条线上。所以,基础矩阵可以将对应点的搜索限制在外极线上。
外极线都经过一点 e,称为外极点。实际上,外极点是另一个照相机光心对应的图像点。外极点可以在我们看到的图像外,这取决于照相机间的相对方向。因为外极点在所有的外极线上,所以 F e1=0。因此,我们可以通过计算 F的零向量来计算出外极点。同理,另一个外极点可以通过计算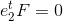 得到。外极点和外极线如图 5-1 所示。
得到。外极点和外极线如图 5-1 所示。
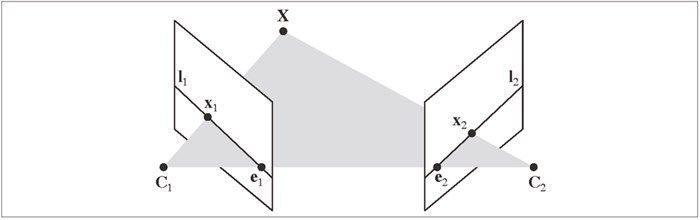
图 5-1:外极几何示意图。在这两个视图中,分别将三维点 X 投影为 x1 和 x2。两个照相机中 心之间的基线 C1 和 C2 与图像平面相交于外极点 e1 和 e2。线 I1 和 I2 称为外极线
5.1.1 一个简单的数据集
在接下来的几节中,我们需要一个带有图像点、三维点和照相机参数矩阵的数据集。我们这里使用一个牛津多视图数据集;从 http://www.robots.ox.ac.uk/~vgg/data/data-mview.html 可以下载 Merton1 数据的压缩文件。下面的脚本可以加载 Merton1 的数据:
import camera# 载入一些图像im1 = array(Image.open('images/001.jpg'))im2 = array(Image.open('images/002.jpg'))# 载入每个视图的二维点到列表中points2D = [loadtxt('2D/00'+str(i+1)+'.corners').T for i in range(3)]# 载入三维点points3D = loadtxt('3D/p3d').T# 载入对应corr = genfromtxt('2D/nview-corners',dtype='int',missing='*')# 载入照相机矩阵到Camera 对象列表中P = [camera.Camera(loadtxt('2D/00'+str(i+1)+'.P')) for i in range(3)]
上面的程序会加载前两个图像(共三个)、三个视图中的所有图像特征点 2、对应不同视图图像点重建后的三维点以及照相机参数矩阵(使用上一章的 Camera 类)。这里我们使用 loadtxt() 函数读取文本文件到 NumPy 数组中。因为并不是所有的点都可见,或都能够成功匹配到所有的视图,所以对应数据里包含了缺失的数据。加载对应数据时需要考虑这一点。genfromtxt() 函数通过将缺失的数值(在文件中用 * 表示)填充为 -1 来解决这个问题。
2事实上,这些特征点是 2.1 节中的 Harris 角点。
将上面的代码保存到一个文件,例如 load_vggdata.py,然后使用命令 execfile() 可以很方便地运行上面的脚本,从而获取所有的数据:
execfile('load_vggdata.py')
下面来可视化这些数据。将三维的点投影到一个视图,然后和观测到的图像点比较:
# 将三维点转换成齐次坐标表示,并投影X = vstack( (points3D,ones(points3D.shape[1])) )x = P[0].project(X)# 在视图1 中绘制点figure()imshow(im1)plot(points2D[0][0],points2D[0][1],'*')axis('off')figure()imshow(im1)plot(x[0],x[1],'r.')axis('off')show()
上面的代码绘制出第一个视图以及该视图中的图像点。为比较方便,投影后的点绘制在另一张图上,如图 5-2 所示。如果仔细观察,你会发现第二幅图比第一幅图多一些点。这些多出的点是从视图 2 和视图 3 重建出来的,而不在视图 1 中。

图 5-2:牛津 multiview 数据集中的 Merton1 数据集:视图 1 与图像点(左);视图 1 与投影的三维点(右)
5.1.2 用Matplotlib绘制三维数据
为了可视化三维重建结果,我们需要绘制出三维图像。Matplotlib 中的 mplot3d 工具包可以方便地绘制出三维点、线、等轮廓线、表面以及其他基本图形组件,还可以通过图像窗口控件实现三维旋转和缩放。
可以通过在 axes 对象中加上 projection="3d" 关键字实现三维绘图,如下:
from mpl_toolkits.mplot3d import axes3dfig = figure()ax = fig.gca(projection="3d")# 生成三维样本点X,Y,Z = axes3d.get_test_data(0.25)# 在三维中绘制点ax.plot(X.flatten(),Y.flatten(),Z.flatten(),'o')show()
get_test_data() 函数在 x, y 空间按照设定的空间间隔参数来产生均匀的采样点。压平这些网格,会产生三列数据点,然后我们可以将其输入 plot() 函数。这样,我们就可以在立体表面上画出三维点。
现在通过画出 Merton 样本数据来观察三维点的效果:
# 绘制三维点from mpl_toolkits.mplot3d import axes3dfig = figure()ax = fig.gca(projection='3d')ax.plot(points3D[0],points3D[1],points3D[2],'k.')
图 5-3 是三个不同视图中的三维图像点。图像窗口和控制界面外观效果像加上三维旋转工具的标准画图窗口。
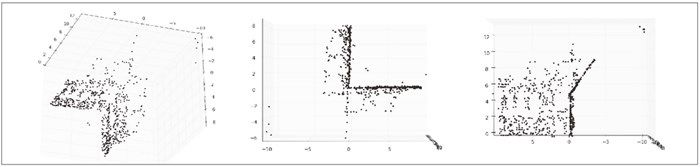
图 5-3:使用 Matplottib 工具包绘制的,牛津 multiview 数据库中 Mertoln1 数据集的三维点:从上面和侧边观测的视图(左);俯视的视图,展示了建筑墙体和屋顶上的点(中);侧视图,展示了一面墙的轮廓,以及另一面墙上点的主视图(右)
5.1.3 计算F:八点法
八点法是通过对应点来计算基础矩阵的算法。下面给出概述,更多内容参阅文献 [13] 和文献 [14]。
外极约束(5.1)可以写成线性系统的形式:
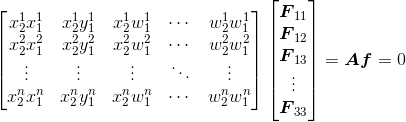
其中,f 包含 F 的元素,![\text{x}^i_1=[x^i_1,y^i_1,w^i_1]](https://i.sou.st/uploads/projects/python10/images/00372.gif) 和
和 ![\text{x}^i_2=[x^i_2,y^i_2,w^i_2]](https://i.sou.st/uploads/projects/python10/images/00414.gif) 是一对图像点,共有 n 对对应点。基础矩阵中有 9 个元素,由于尺度是任意的,所以只需要 8 个方程。因为算法中需要 8 个对应点来计算基础矩阵 F,所以该算法叫做八点法。
是一对图像点,共有 n 对对应点。基础矩阵中有 9 个元素,由于尺度是任意的,所以只需要 8 个方程。因为算法中需要 8 个对应点来计算基础矩阵 F,所以该算法叫做八点法。
新建一个文件 sfm.py,写入下面八点法中最小化 ||Af||的函数:
def compute_fundamental(x1,x2):""" 使用归一化的八点算法,从对应点(x1,x2 3×n 的数组)中计算基础矩阵每行由如下构成:[x'*x,x'y' x', y'x, y'y, y', x, y, 1]"""n = x1.shape[1]if x2.shape[1] != n:raise ValueError("Number of points don't match.")# 创建方程对应的矩阵A = zeros((n,9))for i in range(n):A[i] = [x1[0,i]x2[0,i], x1[0,i]*x2[1,i], x1[0,i]*x2[2,i],x1[1,i]*x2[0,i], x1[1,i]*x2[1,i], x1[1,i]*x2[2,i],x1[2,i]*x2[0,i], x1[2,i]*x2[1,i], x1[2,i]*x2[2,i] ]# 计算线性最小二乘解U,S,V = linalg.svd(A)F = V[-1].reshape(3,3)# 受限F# 通过将最后一个奇异值置0,使秩为2U,S,V = linalg.svd(F)S[2] = 0F = dot(U,dot(diag(S),V))return F
我们通常用 SVD 算法来计算最小二乘解。由于上面算法得出的解可能秩不为 2(基础矩阵的秩小于等于 2),所以我们通过将最后一个奇异值置 0 来得到秩最接近 2 的基础矩阵。这是个很有用的技巧。上面的函数忽略了一个重要的步骤:对图像坐标进行归一化,这可能会带来数值问题。我们会在后面加以解决。
5.1.4 外极点和外极线
本节开始提到过,外极点满足 Fe1=0,因此可以通过计算 F 的零空间来得到。把下面的函数添加到 sfm.py 中:
def compute_epipole(F):""" 从基础矩阵F 中计算右极点(可以使用F.T 获得左极点)"""# 返回F 的零空间(Fx=0)U,S,V = linalg.svd(F)e = V[-1]return e/e[2]
如果想获得另一幅图像的外极点(对应左零空间的外极点),只需将 F 转置后输入上述函数即可。
我们可以在之前样本数据集的前两个视图上运行这两个函数:
import sfm# 在前两个视图中点的索引ndx = (corr[:,0]>=0) & (corr[:,1]>=0)# 获得坐标,并将其用齐次坐标表示x1 = points2D[0][:,corr[ndx,0]]x1 = vstack( (x1,ones(x1.shape[1])) )x2 = points2D[1][:,corr[ndx,1]]x2 = vstack( (x2,ones(x2.shape[1])) )# 计算FF = sfm.compute_fundamental(x1,x2)# 计算极点e = sfm.compute_epipole(F)# 绘制图像figure()imshow(im1)# 分别绘制每条线,这样会绘制出很漂亮的颜色for i in range(5):sfm.plot_epipolar_line(im1,F,x2[:,i],e,False)axis('off')figure()imshow(im2)# 分别绘制每个点,这样会绘制出和线同样的颜色for i in range(5):plot(x2[0,i],x2[1,i],'o')axis('off')show()
首先,选择两幅图像的对应点,然后将它们转换为齐次坐标。这里的对应点是从一个文本文件中读取得到的;而实际上,我们可以按照第 2 章的方法提取图像特征,然后通过匹配来找到它们。由于缺失的数据在对应列表 corr 中为 -1,所以程序中有可能 选取这些点。因此,上面的程序通过数组操作符 & 只选取了索引大于等于 0 的点。
最后,我们在第一个视图中画出了前 5 个外极线,在第二个视图中画出了对应匹配点。这里我们主要借助 plot() 函数:
def plot_epipolar_line(im,F,x,epipole=None,show_epipole=True):""" 在图像中,绘制外极点和外极线 F×x=0。F 是基础矩阵,x 是另一幅图像中的点"""m,n = im.shape[:2]line = dot(F,x)# 外极线参数和值t = linspace(0,n,100)lt = array([(line[2]+line[0]*tt)/(-line[1]) for tt in t])# 仅仅处理位于图像内部的点和线ndx = (lt>=0) & (lt<m)plot(t[ndx],lt[ndx],linewidth=2)if show_epipole:if epipole is None:epipole = compute_epipole(F)plot(epipole[0]/epipole[2],epipole[1]/epipole[2],'r*')
上面的函数将 x 轴的范围作为直线的参数,因此直线超出图像边界的部分会被截断。如果 show_epipole 为真,外极点也会被画出来(如果输入参数中没有外极点,外极点会在程序中计算获得)。程序结果如图 5-4 所示。在两幅图中,用不同的颜色将点和相应的外极线对应起来。

图 5-4:视图 1 中的外极线示为 Merton1 数据视图 2 中 5 个点对应的外极线。下面一行为这些点附近的特写。可以看到,这些线在图像外左侧位置将相交于一点。这些线表明点之间的对应可以在另外一幅图像中找到(线和点之间的颜色编码匹配)
5.2 照相机和三维结构的计算
上一节讲述了视图和基础矩阵、外极线计算方法的关系。这一节我们将简单地介绍计算照相机参数和三维结构的工具。
5.2.1 三角剖分
给定照相机参数模型,图像点可以通过三角剖分来恢复出这些点的三维位置。基本的算法思想如下。
对于两个照相机 P1 和 P2 的视图,三维实物点 X 的投影点为 x1 和 x2(这里用齐次坐标表示),照相机方程(4.1)定义了下列关系:
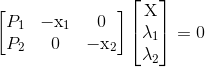
由于图像噪声、照相机参数误差和其他系统误差,上面的方程可能没有精确解。我们可以通过 SVD 算法来得到三维点的最小二乘估值。
下面的函数用于计算一个点对的最小二乘三角剖分,把它添加到 sfm.py 中:
def triangulate_point(x1,x2,P1,P2):""" 使用最小二乘解,绘制点对的三角剖分"""M = zeros((6,6))M[:3,:4] = P1M[3:,:4] = P2M[:3,4] = -x1M[3:,5] = -x2U,S,V = linalg.svd(M)X = V[-1,:4]return X / X[3]
最后一个特征向量的前 4 个值就是齐次坐标系下的对应三维坐标。我们可以增加下面的函数来实现多个点的三角剖分:
def triangulate(x1,x2,P1,P2):""" x1 和x2(3×n 的齐次坐标表示)中点的二视图三角剖分"""n = x1.shape[1]if x2.shape[1] != n:raise ValueError("Number of points don't match.")X = [ triangulate_point(x1[:,i],x2[:,i],P1,P2) for i in range(n)]return array(X).T
这个函数的输入是两个图像点数组,输出为一个三维坐标数组。
我们可以利用下面的代码来实现 Merton1 数据集上的三角剖分:
import sfm# 前两个视图中点的索引ndx = (corr[:,0]>=0) & (corr[:,1]>=0)# 获取坐标,并用齐次坐标表示x1 = points2D[0][:,corr[ndx,0]]x1 = vstack( (x1,ones(x1.shape[1])) )x2 = points2D[1][:,corr[ndx,1]]x2 = vstack( (x2,ones(x2.shape[1])) )Xtrue = points3D[:,ndx]Xtrue = vstack( (Xtrue,ones(Xtrue.shape[1])) )# 检查前三个点Xest = sfm.triangulate(x1,x2,P[0].P,P[1].P)print Xest[:,:3]print Xtrue[:,:3]# 绘制图像from mpl_toolkits.mplot3d import axes3dfig = figure()ax = fig.gca(projection='3d')ax.plot(Xest[0],Xest[1],Xest[2],'ko')ax.plot(Xtrue[0],Xtrue[1],Xtrue[2],'r.')axis('equal')show()
上面的代码首先利用前两个视图的信息来对图像点进行三角剖分,然后把前三个图像点的齐次坐标输出到控制台,最后绘制出恢复的最接近三维图像点。输出到控制台的信息如下:
[[ 1.03743725 1.56125273 1.40720017][-0.57574987 -0.55504127 -0.46523952][ 3.44173797 3.44249282 7.53176488][ 1. 1. 1. ]][[ 1.0378863 1.5606923 1.4071907 ][-0.54627892 -0.5211711 -0.46371818][ 3.4601538 3.4636809 7.5323397 ][ 1. 1. 1. ]]
算法估计出的三维图像点和实际图像点很接近。如图 5-5 所示,估计点和实际点可以很好地匹配。
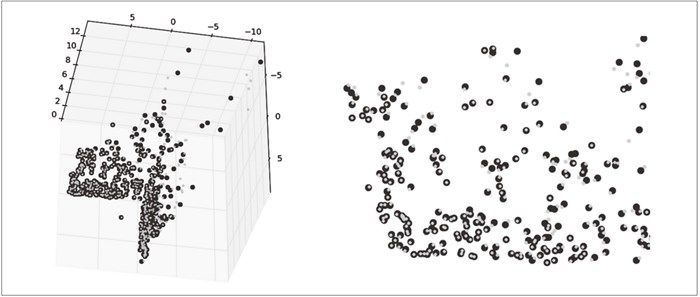
图 5-5:使用照相机矩阵和点的对应关系来三角剖分这些数据点。黑色的圆圈表示估计的点,灰色的点表示真实点。上方一侧的视图(左)。一个坐标平面观看这些数据点的近景图像(右)
5.2.2 由三维点计算照相机矩阵
如果已经知道了一些三维点及其图像投影,我们可以使用直接线性变换的方法来计算照相机矩阵 P。本质上,这是三角剖分方法的逆问题,有时我们将其称为照相机反切法。利用该方法恢复照相机矩阵同样也是一个最小二乘问题。
我们从照相机方程(4.1)可以得出,每个三维点 Xi(齐次坐标系下)按照 λixi = P Xi 投影到图像点 xi=[xi, yi,1],相应的点满足下面的关系:
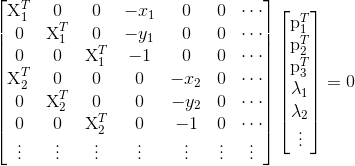
其中 p1、p2 和 p3 是矩阵 P 的三行。上面的式子可以写得更紧凑,如下所示:
M v=0
然后,我们可以使用 SVD 分解估计出照相机矩阵。利用上面讲述的矩阵操作,我们可以直接写出相应的代码。将下面的函数添加到 sfm.py 文件中:
def compute_P(x,X):""" 由二维-三维对应对(齐次坐标表示)计算照相机矩阵"""n = x.shape[1]if X.shape[1] != n:raise ValueError("Number of points don't match.")# 创建用于计算DLT 解的矩阵M = zeros((3*n,12+n))for i in range(n):M[3*i,0:4] = X[:,i]M[3*i+1,4:8] = X[:,i]M[3*i+2,8:12] = X[:,i]M[3*i:3*i+3,i+12] = -x[:,i]U,S,V = linalg.svd(M)return V[-1,:12].reshape((3,4))
该函数的输入参数为图像点和三维点,构造出上述所示的 M 矩阵。最后一个特征向量的前 12 个元素是照相机矩阵的元素,经过重新排列成矩阵形状后返回。
下面,在我们的样本数据集上测试算法的性能。下面的代码会选出第一个视图中的一些可见点(使用对应列表中缺失的数值),将它们转换为齐次坐标表示,然后估计照相机矩阵:
import sfm, cameracorr = corr[:,0] # 视图1ndx3D = where(corr>=0)[0] # 丢失的数值为-1ndx2D = corr[ndx3D]# 选取可见点,并用齐次坐标表示x = points2D[0][:,ndx2D] # 视图1x = vstack( (x,ones(x.shape[1])) )X = points3D[:,ndx3D]X = vstack( (X,ones(X.shape[1])) )# 估计PPest = camera.Camera(sfm.compute_P(x,X))# 比较!print Pest.P Pest.P[2,3]print P[0].P P[0].P[2,3]xest = Pest.project(X)# 绘制图像figure()imshow(im1)plot(x[0],x[1],'bo')plot(xest[0],xest[1],'r.')axis('off')show()
为了检查照相机矩阵的正确性,将它们以归一化的格式(除以最后一个元素)打印到控制台。输出如下所示:
[[ 1.06520794e+00 -5.23431275e+01 2.06902749e+01 5.08729305e+02][ -5.05773115e+01 -1.33243276e+01 -1.47388537e+01 4.79178838e+02][ 3.05121915e-03 -3.19264684e-02 -3.43703738e-02 1.00000000e+00]][[ 1.06774679e+00 -5.23448212e+01 2.06926980e+01 5.08764487e+02][ -5.05834364e+01 -1.33201976e+01 -1.47406641e+01 4.79228998e+02][ 3.06792659e-03 -3.19008054e-02 -3.43665129e-02 1.00000000e+00]]
上面是估计出的照相机矩阵,下面是数据集的创建者计算出的照相机矩阵。可以看到,它们的元素几乎完全相同。最后,使用估计出的照相机矩阵投影这些三维点,然后绘制出投影后的结果。结果如图 5-6 所示,真实点用圆圈表示,估计出的照相机投影点用点表示。

图 5-6:使用估计出的照相机矩阵来计算视图 1 中的投影点
5.2.3 由基础矩阵计算照相机矩阵
在两个视图的场景中,照相机矩阵可以由基础矩阵恢复出来。假设第一个照相机矩阵归一化为 P1=[I|0],现在我们需要计算出第二个照相机矩阵 P2。研究分为两类,未标定的情况和已标定的情况。
- 未标定的情况——投影重建
在没有任何照相机内参数知识的情况下,照相机矩阵只能通过射影变换恢复出来。也就是说,如果利用照相机的信息来重建三维点,那么该重建只能由射影变换计算出来(你可以得到整个投影场景中无畸变的重建点)。在这里,我们不考虑角度和距离。
因此,在无标定的情况下,第二个照相机矩阵可以使用一个(3×3)的射影变换得出。一个简单的方法是:
P2=[SeF|e]
其中,e 是左极点,满足 eTF=0,Se 是如公式(5.2)所示的反对称矩阵。请注意,使用该矩阵做出的三角形剖分很有可能会发生畸变,如倾斜的重建。
下面是具体的代码:
def compute_P_from_fundamental(F):""" 从基础矩阵中计算第二个照相机矩阵(假设 P1 = [I 0])"""e = compute_epipole(F.T) # 左极点Te = skew(e)return vstack((dot(Te,F.T).T,e)).T
这里,我们使用的 skew() 函数定义如下:
def skew(a):""" 反对称矩阵A,使得对于每个v 有a×v=Av """return array([[0,-a[2],a[1]],[a[2],0,-a[0]],[-a[1],a[0],0]])
将上面的两个函数添加到 sfm.py 文件中。
- 已标定的情况——度量重建
在已经标定的情况下,重建会保持欧式空间中的一些度量特性(除了全局的尺度参数)。在重建三维场景中,已标定的例子更为有趣。
给定标定矩阵 K,我们可以将它的逆 K-1 作用于图像点 xK=K-1x,因此,在新的图像
坐标系下,照相机方程变为:
xK = K-1K[R|t]X = [R|t]X
在新的图像坐标系下,点同样满足之前的基础矩阵方程:
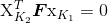
在标定归一化的坐标系下,基础矩阵称为本质矩阵。为了区别为标定后的情况,以及归一化了的图像坐标,我们通常将其记为 E,而非 F。
从本质矩阵恢复出的照相机矩阵中存在度量关系,但有四个可能解。因为只有一个解产生位于两个照相机前的场景,所以我们可以轻松地从中选出来。
下面是计算这 4 个解的算法(参阅文献 [13] 获取更多细节)。将该函数添加到 sfm.py 文件中:
def compute_P_from_essential(E):""" 从本质矩阵中计算第二个照相机矩阵(假设 P1 = [I 0])输出为4 个可能的照相机矩阵列表"""# 保证E 的秩为2U,S,V = svd(E)if det(dot(U,V))<0:V = -VE = dot(U,dot(diag([1,1,0]),V))# 创建矩阵(Hartley)Z = skew([0,0,-1])W = array([[0,-1,0],[1,0,0],[0,0,1]])# 返回所有(4 个)解P2 = [vstack((dot(U,dot(W,V)).T,U[:,2])).T,vstack((dot(U,dot(W,V)).T,-U[:,2])).T,vstack((dot(U,dot(W.T,V)).T,U[:,2])).T,vstack((dot(U,dot(W.T,V)).T,-U[:,2])).T]return P2
首先,该函数确保本质矩阵的秩为 2(本质矩阵有两个相等的非零奇异值)。然后,按照文献 [13] 中的方法,计算出这 4 个解。关于如何挑选正确的解,我们将在后面的例子中讲解。
本节涵盖了从图像集计算出三维重建所需的所有理论。
5.3 多视图重建
下面让我们来看,如何使用上面的理论从多幅图像中计算出真实的三维重建。由于照相机的运动给我们提供了三维结构,所以这样计算三维重建的方法通常称为 SfM(Structure from Motion,从运动中恢复结构)。
假设照相机已经标定,计算重建可以分为下面 4 个步骤:
检测特征点,然后在两幅图像间匹配;
由匹配计算基础矩阵;
由基础矩阵计算照相机矩阵;
三角剖分这些三维点。
我们已经具备了完成上面 4 个步骤所需的所有工具。但是当图像间的点对应包含不正确的匹配时,我们需要一个稳健的方法来计算基础矩阵。
5.3.1 稳健估计基础矩阵
类似于稳健计算单应性矩阵(3.3 节),当存在噪声和不正确的匹配时,我们需要估计基础矩阵。和前面的方法一样,我们使用 RANSAC 方法,只不过这次结合了八点算法。注意,八点算法在平面场景中会失效,所以,如果场景点都位于平面上,就不能使用该算法。
将下面的类添加到 sfm.py 文件中:
class RansacModel(object):""" 用从http://www.scipy.org/Cookbook/RANSAC 下载的ransac.py 计算基础矩阵的类"""def __init__(self,debug=False):self.debug = debugdef fit(self,data):""" 使用选择的8 个对应计算基础矩阵"""# 转置,并将数据分成两个点集data = data.Tx1 = data[:3,:8]x2 = data[3:,:8]# 估计基础矩阵,并返回F = compute_fundamental_normalized(x1,x2)return Fdef get_error(self,data,F):""" 计算所有对应的x^T F x,并返回每个变换后点的误差"""# 转置,并将数据分成两个点集data = data.Tx1 = data[:3]x2 = data[3:]# 将Sampson 距离用作误差度量Fx1 = dot(F,x1)Fx2 = dot(F,x2)denom = Fx1[0]**2 + Fx1[1]**2 + Fx2[0]**2 + Fx2[1]**2err = ( diag(dot(x1.T,dot(F,x2))) )**2 / denom# 返回每个点的误差return err
和之前一样,我们需要 fit() 和 get_error() 方法。这里采用的错误衡量方法是 Sampson 距离(参阅文献 [13])。fit() 方法会选择 8 个点,然后使用归一化的八点算法:
def compute_fundamental_normalized(x1,x2):""" 使用归一化的八点算法,由对应点(x1,x2 3×n 的数组)计算基础矩阵"""n = x1.shape[1]if x2.shape[1] != n:raise ValueError("Number of points don't match.")# 归一化图像坐标x1 = x1 / x1[2]mean_1 = mean(x1[:2],axis=1)S1 = sqrt(2) / std(x1[:2])T1 = array([[S1,0,-S1*mean_1[0]],[0,S1,-S1*mean_1[1]],[0,0,1]])x1 = dot(T1,x1)x2 = x2 x2[2]mean_2 = mean(x2[:2],axis=1)S2 = sqrt(2) std(x2[:2])T2 = array([[S2,0,-S2*mean_2[0]],[0,S2,-S2*mean_2[1]],[0,0,1]])x2 = dot(T2,x2)# 使用归一化的坐标计算FF = compute_fundamental(x1,x2)# 反归一化F = dot(T1.T,dot(F,T2))return F/F[2,2]
该函数将图像点归一化为零均值固定方差。
接下来,我们在函数中使用该类。将下面的函数添加到 sfm.py 文件中:
def F_from_ransac(x1,x2,model,maxiter=5000,match_theshold=1e-6):""" 使用RANSAN 方法(ransac.py,来自http://www.scipy.org/Cookbook/RANSAC),从点对应中稳健地估计基础矩阵F输入:使用齐次坐标表示的点x1,x2(3×n 的数组)"""import ransacdata = vstack((x1,x2))# 计算F ,并返回正确点索引F,ransac_data = ransac.ransac(data.T,model,8,maxiter,match_theshold,20,return_all=True)return F, ransac_data['inliers']
这里,我们返回最佳基础矩阵 F,以及正确点的索引,这样可以知道哪些匹配和 F 矩阵是一致的。与单应性矩阵估计相比,我们增加了默认的最大迭代次数,改变了匹配的阈值(之前使用像素,现在使用 Sampson 距离来衡量)。
5.3.2 三维重建示例
在本节中,我们将观察一个重建三维场景的完整例子。我们使用由已知标定矩阵的照相机拍摄的两幅图像。该图像是著名的恶魔岛监狱,如图 5-7 所示。3
3图像由 Carl Olsson 提供(参见 http://www.maths.lth.se/matematiklth/personal/calle/)。

图 5-7:在一个场景中使用不同视角拍摄图像对
我们将该处理代码分成若干块,使得代码更容易理解。首先,提取、匹配特征,然后估计基础矩阵和照相机矩阵:
import homographyimport sfmimport sift# 标定矩阵K = array([[2394,0,932],[0,2398,628],[0,0,1]])# 载入图像,并计算特征im1 = array(Image.open('alcatraz1.jpg'))sift.process_image('alcatraz1.jpg','im1.sift')l1,d1 = sift.read_features_from_file('im1.sift')im2 = array(Image.open('alcatraz2.jpg'))sift.process_image('alcatraz2.jpg','im2.sift')l2,d2 = sift.read_features_from_file('im2.sift')# 匹配特征matches = sift.match_twosided(d1,d2)ndx = matches.nonzero()[0]# 使用齐次坐标表示,并使用inv(K) 归一化x1 = homography.make_homog(l1[ndx,:2].T)ndx2 = [int(matches[i]) for i in ndx]x2 = homography.make_homog(l2[ndx2,:2].T)x1n = dot(inv(K),x1)x2n = dot(inv(K),x2)# 使用RANSAC 方法估计Emodel = sfm.RansacModel()E,inliers = sfm.F_from_ransac(x1n,x2n,model)# 计算照相机矩阵(P2 是4 个解的列表)P1 = array([[1,0,0,0],[0,1,0,0],[0,0,1,0]])P2 = sfm.compute_P_from_essential(E)
现在,我们已经获得了标定矩阵,所以只对矩阵 K 进行硬编码。与之前的例子一样,我们挑选属于匹配关系的特定点。然后使用 K-1 来对其进行归一化,并使用归一化的八点算法来运行 RANSAC 估计。因为该点已经归一化,所以这里会返回一个本质矩阵。因为我们将会使用到的正确的匹配点,所以需要保存正确匹配点的索引。从本质矩阵出发,我们可以计算出第二个照相机矩阵的四个可能解。
从照相机矩阵的列表中,挑选出经过三角剖分后,在两个照相机前均含有最多场景点的照相机矩阵:
# 选取点在照相机前的解ind = 0maxres = 0for i in range(4):# 三角剖分正确点,并计算每个照相机的深度X = sfm.triangulate(x1n[:,inliers],x2n[:,inliers],P1,P2[i])d1 = dot(P1,X)[2]d2 = dot(P2[i],X)[2]if sum(d1>0)+sum(d2>0) > maxres:maxres = sum(d1>0)+sum(d2>0)ind = iinfront = (d1>0) & (d2>0)# 三角剖分正确点,并移除不在所有照相机前面的点X = sfm.triangulate(x1n[:,inliers],x2n[:,inliers],P1,P2[ind])X = X[:,infront]
循环遍历这 4 个解,每次对对应于正确点的三维点进行三角剖分。将三角剖分后的图像投影回图像后,深度的符号由每个图像点的第三个数值给出。我们保存了正向最大深度的索引;对于和最优解一致的点,用相应的布尔量保存了信息,这样可以取出真正在照相机前面的点。因为所有估计中都存在噪声和误差,所以即便使用正确的照相机矩阵,也存在一些点仍位于某个照相机后面的风险。首先获得正确的解,然后对这些正确的点进行三角剖分,最后保留位于照相机前方的点。
现在可以绘制出该三维重建:
# 绘制三维图像from mpl_toolkits.mplot3d import axes3dfig = figure()ax = fig.gca(projection='3d')ax.plot(-X[0],X[1],X[2],'k.')axis('off')
和我们的坐标系相比,使用 mplot3d 绘制三维图像需要将第一个坐标值取相反数,所以这里改变其符号。
然后,可以在每个视图中绘制出二次投影:
# 绘制X 的投影import camera# 绘制三维点cam1 = camera.Camera(P1)cam2 = camera.Camera(P2[ind])x1p = cam1.project(X)x2p = cam2.project(X)# 反K 归一化x1p = dot(K,x1p)x2p = dot(K,x2p)figure()imshow(im1)gray()plot(x1p[0],x1p[1],'o')plot(x1[0],x1[1],'r.')axis('off')figure()imshow(im2)gray()plot(x2p[0],x2p[1],'o')plot(x2[0],x2[1],'r.')axis('off')show()
将这些三维点投影后,可以通过乘以标定矩阵的方式来弥补初始归一化对点的影响。
结果输出如图 5-8 所示。可以看到,二次投影后的点和原始特征位置不完全匹配,但是相当接近。当然,可以进一步调整照相机矩阵来提高重建和二次投影的性能,但是这超出了这个简单例子的范畴。

图 5-8:使用图像匹配从一对图像中计算三维重建:带有特征点(黑色)和二次投影重建的三维点(白色)的两幅图像(上);三维重建(下)
5.3.3 多视图的扩展示例
多视图重建有一些步骤和进一步的扩展,但是不能在本书中全部介绍。为了方便读者进一步阅读,下面提供关于一些有关内容及其参考文献。
- 多视图
当我们有同一场景的多个视图时,三维重建会变得更准确,包括更多的细节信息。因为基础矩阵只和一对视图相关,所以该过程带有很多图像,和之前的处理有些不同。
对于视频序列,我们可以使用时序关系,在连续的帧对中匹配特征。相对方位需要从每个帧对增量地加入下一个帧对,(与图 3-12 中我们在全景图例子中加入单应性矩阵相同)。该方法非常有效,同时可以使用跟踪有效地找到对应点(关于跟踪的更多知识,参阅 10.4 节)。一个问题是误差会在加入的视图中积累。该问题可以由最后的优化步骤来解决,参见下文。
对于静止的图像,一个办法是找到一个中央参考视图,然后计算与之有关的所有其他照相机矩阵。另一个办法是计算一个图像对的照相机矩阵和三维重建,然后增量地加入新的图像和三维点,参见参考文献 [34]。另外,还有一些方法可以同时由三个视图计算三维重建和照相机位置(参阅参考文献 [13]);但除此之外,我们还需要使用增量的方法。
- 光束法平差
从图 5-8 简单三维重建的例子,我们可以清楚地看出,恢复出的点的位置和由估计的基础矩阵计算出的照相机矩阵都存在误差。在多个视图的计算中,这些误差会进一步累积。因此,多视图重建的最后一步,通常是通过优化三维点的位置和照相机参数来减少二次投影误差。该过程称为光束法平差。更多内容参阅参考文献 [13] 和 [35],或者可以从 http://en.wikipedia.org/wiki/Bundle_adjustment 参阅该方法的概述。
- 自标定
在未标定照相机的情形中,有时可以从图像特征来计算标定矩阵。该过程称为自标定。根据在照相机标定矩阵参数上做出的假设,以及可用的图像数据的类型(特征匹配、平行线、平面等),我们有很多不同的自标定算法。感兴趣的读者可以参阅参考文献 [13] 及参考文献 [26] 第 6 章的内容。
作为标定的附注,值得一提的是一个叫做 extract_focal.pl 的有用脚本,它是 SfM 系统(http://phototour.cs.washington.edu/bundler/)的一部分。对于常见的照相机,该脚本基于图像 EXIF 数据,使用一个查找表来估计焦距。
5.4 立体图像
一个多视图成像的特殊例子是立体视觉(或者立体成像),即使用两台只有水平(向一侧)偏移的照相机观测同一场景。当照相机的位置如上设置,两幅图像具有相同的图像平面,图像的行是垂直对齐的,那么称图像对是经过矫正的。该设置在机器人学中很常见,常被称为立体平台。
通过将图像扭曲到公共的平面上,使外极线位于图像行上,任何立体照相机设置都能得到矫正(我们通常构建立体平台来产生经过矫正的图像对)。这超出了本章节的范围,感兴趣的读者可以参阅参考文献 [13] 第 303 页,或者参考文献 [3] 第 430 页。
假设两幅图像经过了矫正,那么对应点的寻找限制在图像的同一行上。一旦找到对应点,由于深度是和偏移成正比的,那么深度(Z 坐标)可以直接由水平偏移来计算,
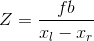
其中,f 是经过矫正图像的焦距,b 是两个照相机中心之间的距离,xl 和 xr 是左右两幅图像中对应点的 x 坐标。分开照相机中心的距离称为基线。矫正后的立体照相机设置如图 5-9 所示。
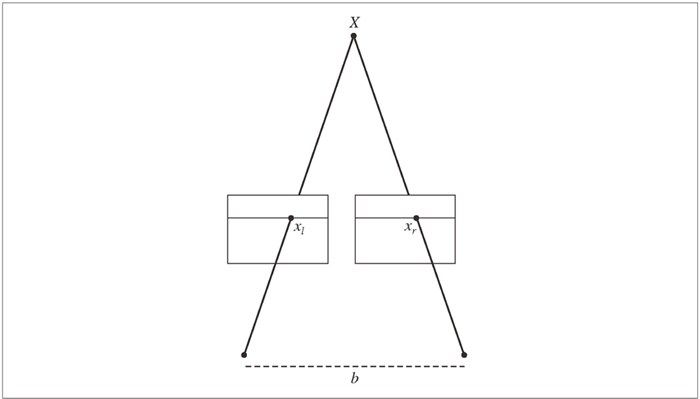
图 5-9:矫正后立体照相机设置的示意图,其中对应点位于两幅图像的同一行
立体重建(有时称为致密深度重建)就是恢复深度图(或者相反,视差图),图像中每个像素的深度(或者视差)都需要计算出来。这是计算机视觉中的经典问题,有很多算法可以解决该问题。米德尔伯里学院立体视觉网页(http://vision.middlebury.edu/stereo/)保持更新最佳算法的评估,以及该算法的代码和许多细节描述。在下一节中,我们会讲解基于归一化互相关的立体重建算法。
计算视差图
在该立体重建算法中,我们将对于每个像素尝试不同的偏移,并按照局部图像周围归一化的互相关值,选择具有最好分数的偏移,然后记录下该最佳偏移。因为每个偏移在某种程度上对应于一个平面,所以该过程有时称为扫平面法。虽然该方法并不是立体重建中最好的方法,但是非常简单,通常会得出令人满意的结果。
当密集地应用在图像中时,归一化的互相关值可以很快地计算出来。这和我们在第2章中应用于稀疏点对应的不同。我们使用每个像素周围的图像块(根本上说,是局部周边图像)来计算归一化的互相关。对于这里的情形,我们可以在像素周围重新写出公式(2.3)中的 NCC,如下所示
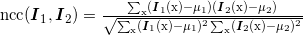
我们在前面跳过了归一化常数(这里不需要),然后对该像素周围局部像素块中的像素求和。
现在,我们要将图像中的每个像素进行该操作。这三个求和操作是在局部图像块区域上进行的,我们可以使用图像滤波器来快速计算,这与我们在模糊和求导操作中使用的技巧一样。ndimage.filters 模块中的 uniform_filter() 函数可以在一个矩形图像块中计算相加。
下面是扫平面法的具体实现代码,该函数返回每个像素的最佳视差。创建 stereo.py 文件,将下面的代码添加进去:
def plane_sweep_ncc(im_l,im_r,start,steps,wid):""" 使用归一化的互相关计算视差图像"""m,n = im_l.shape# 保存不同求和值的数组mean_l = zeros((m,n))mean_r = zeros((m,n))s = zeros((m,n))s_l = zeros((m,n))s_r = zeros((m,n))# 保存深度平面的数组dmaps = zeros((m,n,steps))# 计算图像块的平均值filters.uniform_filter(im_l,wid,mean_l)filters.uniform_filter(im_r,wid,mean_r)# 归一化图像norm_l = im_l - mean_lnorm_r = im_r - mean_r# 尝试不同的视差for displ in range(steps):# 将左边图像移动到右边,计算加和filters.uniform_filter(roll(norm_l,-displ-start)*norm_r,wid,s) # 和归一化filters.uniform_filter(roll(norm_l,-displ-start)*roll(norm_l,-displ-start),wid,s_l)filters.uniform_filter(norm_r*norm_r,wid,s_r) # 和反归一化# 保存ncc 的分数dmaps[:,:,displ] = s/sqrt(s_l*s_r)# 为每个像素选取最佳深度return argmax(dmaps,axis=2)
首先,因为 uniform_filter() 函数的输入参数为数组,我们需要创建用于保存滤波结果的一些数组。然后,我们创建一个数组来保存每个平面,从而能够在最后一个纬度上使用 argmax() 函数找到对于每个像素的最佳深度。该函数从 start 偏移出发,在所有的 steps 偏移上迭代。使用 roll() 函数平移一幅图像,然后使用滤波计算 NCC 的三个求和操作。
下面是载入图像,并使用该函数计算偏移图的完整例子:
import stereoim_l = array(Image.open('scene1.row3.col3.ppm').convert('L'),'f')im_r = array(Image.open('scene1.row3.col4.ppm').convert('L'),'f')# 开始偏移,并设置步长steps = 12start = 4# ncc 的宽度wid = 9res = stereo.plane_sweep_ncc(im_l,im_r,start,steps,wid)import scipy.miscscipy.misc.imsave('depth.png',res)
这里首先从经典“tsukuba”数据集中载入一对图像,然后将其灰度化。接下来,设置扫平面函数所需的参数,包括尝试偏移的数目、初始值和 NCC 路径的宽度。你会发现,该方法非常快,至少快于使用 NCC 进行特征匹配。这也是使用滤波器来计算的原因。
该方法同样适用于其他滤波器。均匀滤波器给定正方形图像块中所有像素相同的权值。但是,在一些例子中,其他滤波器对 NCC 的计算可能更为适用。下面是使用高斯滤波器替换均匀滤波器,产生更加平滑视差图的例子。将其添加到 stereo.py 文件中:
def plane_sweep_gauss(im_l,im_r,start,steps,wid):""" 使用带有高斯加权周边的归一化互相关计算视差图像"""m,n = im_l.shape# 保存不同加和的数组mean_l = zeros((m,n))mean_r = zeros((m,n))s = zeros((m,n))s_l = zeros((m,n))s_r = zeros((m,n))# 保存深度平面的数组dmaps = zeros((m,n,steps))# 计算平均值filters.gaussian_filter(im_l,wid,0,mean_l)filters.gaussian_filter(im_r,wid,0,mean_r)# 归一化图像norm_l = im_l - mean_lnorm_r = im_r - mean_r# 尝试不同的视差for displ in range(steps):# 将左边图像移动到右边,计算加和filters.gaussian_filter(roll(norm_l,-displ-start)*norm_r,wid,0,s) # 和归一化filters.gaussian_filter(roll(norm_l,-displ-start)*roll(norm_l,-displ-start),wid,0,s_l)filters.gaussian_filter(norm_r*norm_r,wid,0,s_r) # 和反归一化# 保存ncc 的分数dmaps[:,:,displ] = s/sqrt(s_l*s_r)# 为每个像素选取最佳深度return argmax(dmaps,axis=2)
除了在滤波中使用了额外的参数,该代码和均匀滤波的代码相同。我们需要在 gaussian_filter() 函数中传入零参数来表示我们使用的是标准高斯函数,而不是其他任何导数(详见 1.4.2 节)。
你可以像前面的扫平面函数一样来使用该函数。图 5-10 和图 5-11 所示为这两个扫平面实现操作在一些标准立体基准图像上的结果。这些图像来自于参考文献 [29] 和 [30],可以从 http://vision.middlebury.edu/stereo/data/ 下载。这里我们使用“tsukuba”和“cones”图像,在标准版本中设置 wid 为 9,高斯版本中设置 wid 为 3。上面一行图像所示为图像对,左下方图像是标准的 NCC 扫平面法重建的视差 图,右下方是高斯版本的视差图。可以看到,与标准版本相比,高斯版本具有较少的噪声,但缺少很多细节信息。

图 5-10:使用归一化互相关从一对立体图像中计算视差图

图 5-11:使用归一化互相关从一对立体图像中计算视差图
练习
使用本章介绍的技术来验证 2.3.2 节中白宫例子的匹配(使用自己的例子更好),试看能否提高结果的性能。
计算图像对的特征匹配,并估计基础矩阵。使用外极线作为第二个输入,通过在外极线上对每个特征点寻找最佳的匹配来找到更多的匹配。
制作一个包含三幅或更多图像的数据集。挑选一对图像,计算三维点和照相机矩阵。匹配特征到剩下的图像中以获得对应。然后利用这些对应的三维点使用后方交汇法,计算其他图像的照相机矩阵。绘制这些三维点和照相机的位置。你可以使用自己的数据集,也可以使用牛津多视图数据集的数据集。
以 NCC 例子中相同的方式使用滤波器,来实现使用 SSD(squared differences,平方差)而不是 NCC 的立体视差图算法版本。
尝试使用 1.5 节中的 ROF 去噪来对立体深度图进行去噪。对产生锋利边缘噪声的互相关图像块大小进行实验,使用平滑去除产生的噪声。
一个提高视差图效果的方法是,比较从左图到右图计算出的视差图和从右图到左图计算出的视差图,然后仅保留一致的部分。该操作会清除视差图中闭塞的部分。实现该想法,然后将结果和一个方向的扫平面的结果比较。
纽约公共图书馆有很多历史悠久的立体照片。打开 http://stereo.nypl.org/gallery 并下载你喜欢的照片(点击右键,保存为 JPEG 格式的文件)。这些图像应该进行了矫正。将照片切成两部分,在该图像上运行致密深度重建代码,然后查看输出结果。
