第 5 章 处理 PDF 文件,以及用 Python解决问题
只发布 PDF 格式的数据是十分错误的,但有时你也没有其他选择。本章你将学习如何解析 PDF,在学习过程中,你还会学习如何解决在代码中遇到的错误。
我们还会讲到如何编写脚本,从一些基本概念(例如导入模块)讲起,逐步过渡到一些更复杂的内容。学完本章,你将学会在代码中思考问题与解决问题的许多方法。
5.1 尽量不要用PDF
本章用到的数据与上一章相同,只不过是 PDF 格式的。一般来说,我们不会去寻找难以解析的数据格式,但我们在本书中之所以这么做,是因为你要处理的数据可能并不总是理想中的格式。你可以在本书的 GitHub 仓库(https://github.com/jackiekazil/datawrangling)中找到本章所用的 PDF 文件。
在开始解析 PDF 数据之前,你需要考虑以下几件事情。
你是否尝试寻找其他格式的数据?如果在网上找不到,试试打电话(见 6.4.1 节)或发邮件求助。
你是否尝试过从文档中直接复制粘贴数据?有时你可以很方便地在 PDF 文件里选择并复制数据,然后粘贴到电子表格中。但这种做法不一定每次都能奏效,而且也无法规模化(如果有大量文件或页面,你就没法快速完成了)。
如果你不得不处理 PDF 文件的话,需要学习如何用 Python 解析其中的数据。我们来开始学习。
5.2 解析PDF的编程方法
处理 PDF 要比 Excel 文件更加困难,因为每一个 PDF 文件的格式都不可预知。(如果你有一系列 PDF 文件,那么就可以对文件进行解析了,因为这些文档的格式很可能是一致的。)
PDF 工具处理文档的方法有很多种,其中一种方法是将 PDF 转换成文本。在我们写作本书的同时,Danielle Cervantes 在 NICAR 上做了一个关于 PDF 工具的演讲,NICAR 是一个针对记者的 listserv1。这个演讲汇总了下列 PDF 解析工具:
1listserv 是一个用来管理电子邮件列表的软件。——译者注
ABBYY's Transformer
Able2ExtractPro
Acrobat Professional
Adobe Reader
Apache Tika
Cogniview's PDF to Excel
CometDocs
Docsplit
Nitro Pro
PDF XChange Viewer
pdfminer
pdftk
pdftotext
Poppler
Tabula
Tesseract
xPDF
Zamzar
除了上面这些工具,你还可以用许多编程语言来解析 PDF,其中包括 Python。
仅因为你知道类似 Python 这样的工具,并不意味着它总是解决问题的最佳工具。考虑到可用的工具有很多种,你可能会发现用另一个工具来完成部分任务(比如数据提取)更加容易。保持开放的心态,事先对各种可用的工具进行调研。
在 4.1 节中提到过,PyPI 网站是查找 Python 包的好地方。如果搜索“PDF”(https://pypi.python.org/pypi?:action=search&term=pdf&submit=search),你会得到一堆结果,类似图 5-1 给出的那些。

图 5-1:PyPI 网站上的 PDF 包
浏览这些 Python 包,了解一下每个库的详细信息,但分辨不出哪一个库是解析 PDF 的最佳选择。如果你尝试更多的搜索,比如“parse pdf”(解析 pdf),会出现更多的库供你选择,但还是没有明显的最佳选择(搜索结果见 https://pypi.python.org/pypi?:action=search&term=parse+pdf&submit=search)。所以我们用搜索引擎查看一下大家都在用什么库来解析 PDF。
在搜索库或者答案时,注意观察你找到资料的发布日期。帖子或问题的年代越久远,它过时且不再适用的可能性就越大。先试着将搜索范围限定在过去的两年内,然后仅在需要时再扩大搜索的时间范围。
在阅读了许多教程、文档、博客文章和几篇有用的文章(例如这一篇:http://www.binpress.com/tutorial/manipulating-pdfs-with-python/167)之后,我们决定使用 slate 库(https://pypi.python.orgpypislate)。

slate能够满足我们的需求,但并非总是如此。放弃并从头开始也是可以的。如果有很多库可供选择的话,选择你认为最合适的那一个,即使有人告诉你它不是“最好的”工具。究竟哪一个工具最好,大家见仁见智。在你学习编程的过程中,“最好的”工具就是你凭直觉选择的那一个。
5.2.1 利用slate库打开并读取PDF
我们决定用 slate 库来解决这个问题,下面我们来安装这个库。在命令行中运行:
pip install slate
现在你已经安装了 slate,你可以创建一个名为 parse_pdf.py 的脚本,将下面的代码保存其中。一定要确保脚本文件和 PDF 文件位于同一文件夹下,或者修改代码中的文件路径。这段代码会打印出文件的前两行内容:
import slate ➊pdf = 'EN-FINAL Table 9.pdf' ➋with open(pdf) as f: ➌doc = slate.PDF(f) ➍for page in doc[:2]: ➎print page
❶ 导入 slate 库。
❷ 创建字符串变量,用于保存文件路径,一定要确保空格和大小写都正确。
❸ 将文件名字符串传入 Python 的 open 函数,这样 Python 就可以打开该文件。Python 将打开的文件保存为变量 f。
❹ 将打开的文件 f 传递给 slate.PDF(f),slate 可以将 PDF 文件解析成可用的格式。
❺ 遍历文档 doc 的前两页并输出,这样我们可以知道程序运行正常。
slate库或其他库时,如果你得到ImportError,你应该仔细阅读下一行错误信息,看一下哪个库没有安装。运行代码时如果得到如下错误信息:ImportError: No module named pdfminer.pdfparser,说明安装slate时没有正确安装pdfminer,即使它是必需的库。你需要运行pip install --upgrade --ignore-installed slate==0.3 pdfminer==20110515来安装pdfminer(参见slate仓库的这个 issue,https://github.com/timClicks/slate/issues/5)。
运行脚本,然后将输出内容与 PDF 中的内容对比一下。
下面是第一页的内容:
TABLE 9Afghanistan 10 11 10 15 40 37 - - - - 90 74 75 74Albania12 14 9 0 10 99 - - - 36 30 75 78 71Algeria 5 y 6 y 4 y 0 2 99- - - - 68 88 89 87Andorra - - - - - 100 v - - - - - - --Angola 24 x 22 x 25 x - - 36 x - - - - - - - -Antigua and Barbuda- - - - - - - - - - - - - -Argentina 7 y 8 y 5 y - - 99 y- - - - - - - -Armenia 4 5 3 0 7 100 - - - 20 9 70 7267Australia - - - - - 100 v - - - - - - - -Austria - -- - - 100 v - - - - - - - -Azerbaijan 7 y 8 y 5 y 1 12 94 - -- 58 49 75 79 71Bahamas - - - - - - - - - - - - --Bahrain 5 x 6 x 3 x - - - - - - - - - - -Bangladesh 13 188 29 65 31 - - - - 33 y - - -Barbados - - - - - - - -- - - - - -Belarus 1 1 2 0 3 100 y - - - 4 4 65 y 67 y 62yBelgium - - - - - 100 v - - - - - - - -Belize 6 7 53 26 95 - - - - 9 71 71 70Benin 46 47 45 8 34 80 13 2 y1 14 47 - - -Bhutan 3 3 3 6 26 100 - - - - 68 - - -Bolivia (Plurinational State of) 26 y 28 y 24 y 3 22 76 y - - - - 16 - --Bosnia and Herzegovina 5 7 4 0 4 100 - - - 6 5 55 6050Botswana 9 y 11 y 7 y - - 72 - - - - - - - -Brazil 9 y 11 y 6 y11 36 93 y - - - - - - - -Brunei Darussalam - - - - - - -- - - - - - -Bulgaria - - - - - 100 v - - - - - - --Burkina Faso 39 42 36 10 52 77 76 13 9 34 44 83 84 82Burundi26 26 27 3 20 75 - - - 44 73 - - -Cabo Verde 3 x,y 4 x,y 3x,y 3 18 91 - - - 16 y 17 - - -Cambodia 36 y 36 y 36 y 2 18 62 -- - 22 y 46 y - - -Cameroon 42 43 40 13 38 61 1 1 y 7 3947 93 93 93Canada - - - - - 100 v - - - - - - - -CentralAfrican Republic 29 27 30 29 68 61 24 1 11 80 y 80 92 9292Chad 26 25 28 29 68 16 44 18 y 38 - 62 84 85 84Chile 3 x 3x 2 x - - 100 y - - - - - - - -China - - - - - - - - -- - - - -Colombia 13 y 17 y 9 y 6 23 97 - - - - - - - -Comoros27 x 26 x 28 x - - 88 x - - - - - - - -Congo 25 24 25 7 3391 - - - - 76 - - -TABLE 9 CHILD PROTECTIONCountries andareasChild labour (%)+ 2005-2012*Child marriage (%) 2005-2012*Birthregistration (%)+ 2005-2012*totalFemale genital mutilation/cutting (%)+2002-2012*Justification of wife beating (%) 2005-2012*Violent discipline (%)+2005-2012*prevalenceattitudestotalmalefemalemarried by 15married by18womenagirlsbsupport for the practicecmalefemaletotalmalefemale78 THESTATE OF THE WORLD'S CHILDREN 2014 IN NUMBERS
如果你查看一下 PDF 文件,很容易发现页面中每一行的格式。我们来看一下 page 的数据类型是什么:
for page in doc[:2]:print type(page) ➊
❶ 将代码中的 print page 修改为 print type(page)。
运行代码,输出如下:
<type 'str'><type 'str'>
这样我们知道 slate 中的 page 是一个长字符串。这一点很有用,因为现在我们就可以使用字符串方法(想复习字符串方法,可以回看第 2 章)。
总的来说,读取这个 PDF 文件并不难。由于这个文件中只包含表格,几乎没有任何文本,slate 可以很好地解析。在某些情况下,表格被包围在文本中,你可能需要跳过一些行才能获取你想要的数据。如果你需要跳过一些行的话,可以采用上一章 Excel 例子中的方法,创建一个每行递增的计数器,用来找到数据所在的位置,然后利用 4.3 节“什么是索引”中的方法将我们需要的数据提取出来。
我们的最终目标是从 PDF 文件中提取出数据,数据格式与 Excel 文件的输出格式相同。想要做到这一点,我们需要分割字符串,找出每一行的内容。其背后的思考过程是寻找规律,找到每一个新行开始的标志。这听起来可能很简单,但可能会非常复杂。
在处理大型字符串时,人们通常会使用正则表达式(RegEx)。如果你不熟悉正则表达式和如何编写正则表达式的话,这个方法有点困难。如果你准备挑战一下自己,想学习 Python 中正则表达式的更多内容,可以查看 7.2.6 节。对于我们的目标而言,我们将采用一种更简单的方法来提取数据。
5.2.2 将PDF转换成文本
首先我们希望将 PDF 转换成文本,然后再对文本进行解析。如果文件很大或数量很多,这种方法更好。(使用 slate 库的话,每次运行脚本都要对 PDF 进行解析。如果文件很大或很多的话,这种方法既浪费时间又浪费内存。)
我们要用 pdfminer 将 PDF 转换成文本。首先安装这个库:
pip install pdfminer
安装好 pdfminer,你就可以使用一个叫作 pdf2txt.py 的命令,将 PDF 文件转换成文本。现在我们来试一下。运行下面的命令,将 PDF 转换成同一文件夹下的文本文件,这样所有的数据都在同一文件夹下:
pdf2txt.py -o en-final-table9.txt EN-FINAL\ Table\ 9.pdf
第一个参数(-o en-final-table9.txt)是我们想要创建的文本文件。第二个参数(EN-FINAL\ TABLE\ 9.pdf)是我们的 PDF 文件。确保大小写和文件名中的空格正确。空格前面需要加一个反斜线(\)。这叫转义(escaping)。转义是告诉计算机,空格是输入内容的一部分。
利用 Tab 自动补全
给你介绍一位终端里的新朋友:Tab 键。对于上面命令的第二个参数,你可以先输入 EN,然后按两下 Tab 键。如果只有一种备选的话,计算机会自动补全文件名。如果有多种备选,计算机会发出警告音,并返回一系列备选。在输入又长又奇怪的文件夹或文件名时,这种方法极为有用。
试试这个。切换到 home 目录(在基于 Unix 的系统是
cd ~/,在 Windows 上是cd %cd%)。现在,假设你想进入 Documents 目录。试着输入cd D,然后按两下 Tab 键。发生了什么?home 目录里还有哪些文件或文件夹以字母 D 开头?(可能是 Downloads 文件夹?)现在试一下
cd Doc,然后按两下 Tab 键。你应该会看到自动补全成 Documents 文件夹。
运行完这个命令之后,我们创建了这个 PDF 文件的文本格式文件,叫作 en-final-table9.txt。
我们将新文件读入 Python。创建一个新脚本,与前面的脚本保存在同一文件夹下。脚本名叫作 parse_pdf_text.py,或者你认为合适的其他名字。在脚本中写入下列代码:
pdf_txt = 'en-final-table9.txt'openfile = open(pdf_txt, 'r')for line in openfile:print line
我们可以逐行读取文本,然后打印出每一行,将表格内容以文本格式呈现。
5.3 利用pdfminer解析PDF
众所周知,处理 PDF 文件十分困难,我们将学习如何解决在代码中遇到的问题,并掌握一些解决问题的基本方法。
我们希望首先采集国家名称,因为国家名称是最终数据集的键。打开文本文件,你会发现国家出现之前有 8 行。第 8 行的内容是 and areas:
5 TABLE 9 CHILD PROTECTION67 Countries8 and areas9 Afghanistan10 Albania11 Algeria12 Andorra
浏览一下整个文本文档,你会发现相同的规律。因此,我们要创建一个开关变量,在遇到 and areas 这一行时控制采集过程的开始和结束。
为了完成这个任务,我们需要修改 for 循环,添加一个布尔变量,即 True/False 变量。在遇到 and areas 那一行时将布尔变量设置为 True:
country_line = False ➊for line in openfile:if line.startswith('and areas'): ➋country_line = True ➌
❶ 将 country_line 设置为 False,因为默认行里不包含国家。
❷ 搜索以 and area 开头的行。
❸ 将 country_line 设置为 True。
我们要解决的下一个问题是何时将布尔变量再次设置为 False。花点时间查看文本文件,试着找到其中的规律。你怎么能知道国家列表的结尾在哪里呢?
观察下面的文本片段,你会注意到其中有一个空行:
45 China46 Colombia47 Comoros48 Congo4950 total51 1052 12
但 Python 怎么识别空行呢?在脚本中添加一行代码,打印出每一行的 Python 表示(查阅 7.2.2 节,可以了解关于字符串格式化的更多内容):
country_line = Falsefor line in openfile:if country_line: ➊print '%r' % line ➋if line.startswith('and areas'):country_line = True
❶ 在经历了 for 循环的前一次迭代后,如果 country_line 的值为 True,那么……
❷ ……打印出该行的 Python 表示。
观察输出,你会注意到现在所有行的结尾都多出一些字符:
45 'China \n'46 'Colombia \n'47 'Comoros \n'48 'Congo \n'49 '\n'50 'total\n'51 '10 \n'52 '12 \n'
\n 是一行结束的标志,或者叫换行符。我们现在用它作为修改 country_line 变量的标志(marker)。如果 country_line 的值为 True,而 line 的值为 \n,我们就应该将 country_line 设置为 False,因为这一行标志着国名的结束:
country_line = Falsefor line in openfile:if country_line: ➊print lineif line.startswith('and areas'):country_line = Trueelif country_line:if line == '\n': ➋country_line = False
❶ 如果 country_line 的值为 True,打印出该行,我们可以查看国家名称。这段代码在前,是因为我们不希望它出现在 and areas 测试的后面。我们只想打印出实际的国名,而不想打印出 and areas 这一行。
❷ 如果 country_line 的值为 True,且 line 的值为换行符,则将 country_line 设置为 False,因为国家列表已经结束了。
现在运行代码,返回的似乎是包含国家的所有行。我们最后会将其转换成国家列表。现在,对于我们想要采集的数据,我们要寻找相应的标志,然后重复上面的做法。我们想要的是童工数据和童婚数据。首先来看童工数据,我们需要总数、男童数和女童数。我们先来看总数。
我们将利用相同的方法找出童工总数。
(1) 创建一个 True/False 的开关变量。
(2) 寻找开始标志,将开关变量设置为真。
(3) 寻找结束标志,将开关变量设置为假。
查看一下文本,你会发现数据的开始标志是 total。看一下你所创建文本文件的第 50 行,这里出现了第一个标志 2:
2你的文本编辑器很可能可以选择显示行编号,甚至可能可以直接“跳转”到某一行。可以用谷歌搜索一下这些功能的使用方法。
45 China46 Colombia47 Comoros48 Congo4950 total51 1052 12
结束标志还是换行符或 \n,你可以在 71 行看到:
68 669 4670 37172 26 y73 5
我们将这个逻辑添加到代码中,然后用 print 查看结果:
country_line = total_line = False ➊for line in openfile:if country_line or total_line: ➋print lineif line.startswith('and areas'):country_line = Trueelif country_line:if line == '\n':country_line = Falseif line.startswith('total'): ➌total_line = Trueelif total_line:if line == '\n':total_line = False
❶ 将 total_line 设置为 False。
❷ 如果 country_line 或 total_line 的值为 True,输出该行的内容,方便我们查看数据。
❸ 找到 total_line 的起始点,将 total_line 设置为 True。本行下面的代码与前面 country_line 的代码逻辑相同。
现在我们的代码有一些冗余。我们在重复一些相同的代码,只是开关变量有所不同。这就引出了如何创建非冗余代码的话题。在 Python 中,我们可以用函数来执行重复操作。也就是说,我们可以将这些操作放到一个函数里,然后调用函数执行操作,而不必每次输入全部代码手动执行这些操作。如果我们想测试 PDF 的每一行,可以使用函数。
我们将函数命名为 turn_on_off,设置它最多接收 4 个参数。
line是我们目前所在的行。status是一个布尔变量(True或False),代表函数的开或关。start是我们要寻找的开始标志——它会触发开或True状态。end是我们要寻找的结束标志——它会触发关或False状态。
修改代码,将函数框架添加到 for 循环之前。不要忘记添加函数功能的说明——当日后查看这个函数时,你不会一头雾水。这些说明文字叫作文档字符串(docstring):
def turn_on_off(line, status, start, end='\n'): ➊"""这个函数用于检查该行是否以特定值开始/结束。 ➋如果该行确实以特定值开始/结束,则状态设为开/关(真/假)。"""return status ➌country_line = total_line = Falsefor line in openfile:.....
❶ 本行代码是函数的开始,函数最多接收 4 个参数。前三个参数 line、status 和 start 是必需(required)参数,也就是说,由于它们没有默认值,一定要对它们赋值。最后一个参数 end,默认值是换行符,因为这是我们文件的规律。在调用函数时,我们可以传入其他值来替换默认值。
❷ 一定要写函数说明(或文档字符串),这样你才能清楚它的功能。函数说明不必追求完美,只要有就行。以后你可以随时更新。
❸ return 语句是退出函数的正确方法。这个函数返回的是 status,值为 True 或 False。
有默认值的参数要放在最后
在编写函数时,没有默认值的参数一定要放在有默认值的参数前面。这也是上面的例子中
end='\n'是最后一个参数的原因。我们可以看到,有默认值的参数像是一个键值对(即value_name=value),=后面即为默认值(在上面的例子中默认值为\n)。在函数被调用时,Python 会计算参数的值。如果我们想调用前面关于国家的函数,调用方法是这样的:
turn_on_off(line, country_line, 'and areas')这里利用了
end的默认值。如果你想将默认值替换为两个换行符,可以这样调用:
turn_on_off(line, country_line, 'and areas', end='\n\n')假设我们将
status的默认值设置为False。我们要如何修改代码?这是修改前函数的第一行:
def turn_on_off(line, status, start, end='\n'):下面给出两种修改方法:
def turn_on_off(line, start, end='\n', status=False):def turn_on_off(line, start, status=False, end='\n'):
status参数要放在必需参数之后。在调用新函数时,我们可以使用end和status的默认值,也可以用其他值替换:
turn_on_off(line, 'and areas')turn_on_off(line, 'and areas', end='\n\n', status=country_line)如果你不小心把有默认值的参数放在必需参数之前,Python 会报错:
SyntaxError: non-default argument follows default argument。你不必记住这句话,但要注意的是,如果你遇到这个错误,要知道它指的是什么意思。
现在把代码从 for 循环中移到函数中。我们想在新的 turn_on_off 函数中复制前面 country_line 的逻辑:
def turn_on_off(line, status, start, end='\n'):"""这个函数用于检查该行是否以特定值开始/结束。如果该行确实以特定值开始/结束,则状态设为开/关(真/假)。"""if line.startswith(start): ➊status = Trueelif status:if line == end: ➋status = Falsereturn status ➌
❶ 将寻找开始行的标志替换为 start 变量。
❷ 将我们用的结束文字替换为 end 变量。
❸ 基于相同的逻辑,返回 status 变量(end 表示 False,start 表示 True)。
现在我们在 for 循环中调用这个函数,将前面所有代码放在一起之后,脚本是这个样子的:
pdf_txt = 'en-final-table9.txt'openfile = open(pdf_txt, "r")def turn_on_off(line, status, start, end='\n'):"""这个函数用于检查该行是否以特定值开始/结束。如果该行确实以特定值开始/结束,则状态设为开/关(真/假)。"""if line.startswith(start):status = Trueelif status:if line == end:status = Falsereturn statuscountry_line = total_line = False ➊for line in openfile:if country_line or total_line: ➋print '%r' % linecountry_line = turn_on_off(line, country_line, 'and areas') ➌total_line = turn_on_off(line, total_line, 'total') ➍
❶ 根据 Python 的语法,一连串 = 符号的意思是,我们将最后一个值赋值给前面每一个变量。本行代码将 False 同时赋值给 country_line 和 total_line。
❷ 我们仍然想要记录在开状态下每一行包含的数据。因此我们使用了 or。Python 中 or 的意思是,如果二者之一为真,执行下面的命令。本行代码的意思是,如果 country_line 和 total_line 有一个值为 True,打印出该行的内容。
❸ 对国家调用函数。将函数返回的状态保存到 country_line 变量中,用于下一次 for 循环。
❹ 对总数调用函数。这一行代码与上一行对国名的用法是相同的。
下面将国家和总数保存成列表。然后将这些列表转换成一个字典,字典的键是国名,字典的值是童工总数。这样我们就可以判断是否需要清洗数据。
创建两个列表的代码如下:
countries = [] ➊totals = [] ➋country_line = total_line = Falsefor line in openfile:if country_line: ➌countries.append(line) ➍elif total_line:totals.append(line) ➎country_line = turn_on_off(line, country_line, 'and areas')total_line = turn_on_off(line, total_line, 'total')
❶ 创建空的国家列表。
❷ 创建空的总数列表。
❸ 注意我们删除了 if country_line or total_line 语句。下面我们将这条语句分开来写。
❹ 如果该行包含国家,将国家添加到国家列表中。
❺ 这一行采集的是总数,与上一行的采集国家的用法相同。
我们将采用“拉链方法”(zipping)将国家和总数两个数据集合并。zip 函数从每一个列表中取出一个元素,然后将其配对,直到所有的元素全部配对完成。我们可以将合并后的列表传递给 dict 函数,从而将其转换成字典。
在脚本最后添加以下代码:
import pprint ➊test_data = dict(zip(countries, totals)) ➋pprint.pprint(test_data) ➌
❶ 导入 pprint 库。对于复杂的数据结构,这个库的打印格式可读性更好。
❷ 将国家和总数合并到一起,然后转换成一个字典,将字典保存到一个叫作 test_data 的变量中。
❸ 将 test_data 传递给 pprint.pprint() 函数,以美观的格式打印出数据。
现在运行脚本,你会得到类似这样的一个字典:
{'\n': '49 \n',' \n': '\xe2\x80\x93 \n',' Republic of Korea \n': '70 \n',' Republic of) \n': '\xe2\x80\x93 \n',' State of) \n': '37 \n',' of the Congo \n': '\xe2\x80\x93 \n',' the Grenadines \n': '60 \n','Afghanistan \n': '10 \n','Albania \n': '12 \n','Algeria \n': '5 y \n','Andorra \n': '\xe2\x80\x93 \n','Angola \n': '24 x \n','Antigua and Barbuda \n': '\xe2\x80\x93 \n','Argentina \n': '7 y \n','Armenia \n': '4 \n','Australia \n': '\xe2\x80\x93 \n',......
现在我们需要做一些数据清洗工作。更详细的内容将会在第 7 章中介绍。现在我们需要做的是清洗字符串,因为它们的可读性很差。我们将创建一个函数来清洗每一行的内容。将这个函数放在 for 循环前面,与另一个函数放在一起:
def clean(line):"""清洗代码中的换行符、空格以及其他特殊符号。"""line = line.strip('\n').strip() ➊line = line.replace('\xe2\x80\x93', '-') ➋line = line.replace('\xe2\x80\x99', '\'')return line ➌
❶ 删除该行中的 \n,然后重新赋值给 line,现在 line 中保存的是清洗后的数据。
❷ 替换特殊字符编码。
❸ 返回清洗后的新字符串。
在上面的数据清洗中,我们可以把方法调用合并在一起,像这样:
line = line.strip('\n').strip().replace('\xe2\x80\x93', '-').replace('\xe2\x80\x99s', '\'')然而,想要格式美观,每一行 Python 代码的长度不应超过 80 个字符。这只是一个建议,并不是规定,但控制每行代码的长度可以提高代码的可读性。
下面我们将 clean_line 函数应用到 for 循环中:
for line in openfile:if country_line:countries.append(clean(line))elif total_line:totals.append(clean(line))
现在运行脚本,我们得到的输出更加接近我们的目标:
{'Afghanistan': '10','Albania': '12','Algeria': '5 y','Andorra': '-','Angola': '24 x','Antigua and Barbuda': '-','Argentina': '7 y','Armenia': '4','Australia': '-','Austria': '-','Azerbaijan': '7 y',...
浏览一下输出,你会发现我们的方法没能充分解析所有的数据。我们需要找出问题的原因。
名字超过一行的国家似乎被分成了两条数据记录。从玻利维亚(Bolivia)的数据可以发现这一点:我们有两条记录,一条是 'Bolivia (Plurinational': '',,另一条是 'State of)': '26 y',。
在 PDF 文件里可以查看数据的组织结构。你可以在 PDF 中看到图 5-2 中的这几行。
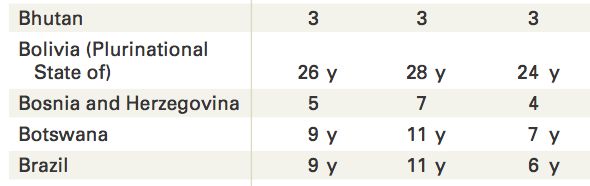
图 5-2:PDF 文件中的玻利维亚数据
解决这个问题有两种方法。我们可以创建一个占位符,找到总数里面的空白行,然后将空白行与后面的数据行合并。另一种方法是找出那些国名长度不止一行的国家。由于我们的数据集不是很大,所以我们将尝试第二种方法。
我们将创建一个列表,里面包含每一个跨行国家的第一行内容,然后在脚本中用这个列表来检查每一行。你需要将这个列表放在 for 循环之前。参考元素通常会放在脚本的开头,在必要时方便找到并修改。
将 Bolivia (Plurinational 添加到双行国家组成的列表中:
double_lined_countries = ['Bolivia (Plurinational',]
现在我们需要修改 for 循环,检查上一行内容是否包含在 double_lined_countries 列表中,如果是的话,将上一行与这一行合并。为此我们需要创建一个 previous_line 变量。然后在 for 循环的结尾对 previous_line 变量赋值。只有这样,在代码进行到循环的下一次迭代时,我们才能将两行合并:
countries = []totals = []country_line = total_line = Falseprevious_line = '' ➊for line in openfile:if country_line:countries.append(clean(line))elif total_line:totals.append(clean(line))country_line = turn_on_off(line, country_line, 'and areas')total_line = turn_on_off(line, total_line, 'total')previous_line = line ➋
❶ 创建 previous_line 变量,值为空字符串。
❷ 在 for 循环的结尾,将 previous_line 的值修改为当前行的内容。
现在有了 previous_line 变量,我们可以检查 previous_line 是否在 double_lined_countries 列表中,这样我们就知道何时将当前行与上一行合并。另外,我们还要将新合并的一行添加到国家列表中。如果国名的前半部分在 double_lined_countries 列表中的话,一定不要将第一行添加到国名列表中。
根据上面的描述,对代码做如下修改:
if country_line: ➊if previous_line in double_lined_countries:line = ' '.join([clean(previous_line), clean(line)]) ➋countries.append(line)elif line not in double_lined_countries: ➌countries.append(clean(line))
❶ 我们需要 if country_line 的逻辑,因为它只与国名相关。
❷ 如果 previous_line 在 double_lined_countries 列表中,那么将 previous_line 与当前行合并,并将合并后的内容赋值给 line 变量。你可以看到,join 的作用是利用最前面的字符串将一个字符串列表合并在一起。本行代码使用空格作为连接字符。
❸ 如果该行不在 double_lined_countries 列表中,那么将该行内容添加到国家列表中。这里我们用的是 elif,在 Python 中的意思是 else if。如果你想使用一种不同于 if - else 的逻辑流,这是一个很好用的工具。
重新运行脚本,我们发现 'Bolivia (Plurinational State of)' 已经合在一起了。现在我们需要检查结果中是否包含了所有国家。由于数据集比较小,我们可以手动检查,但如果数据集较大的话,你需要将检查过程自动化。
数据检查自动化
何时手动检查数据,何时用 Python 自动化完成,怎么选择?下面给出几点建议。
如果要定期反复解析数据,选择自动化。
如果你的数据集比较大,你很可能应该选择自动化。
如果你的数据集可控,而且你只需要解析一次,那么你选哪种方式都可以。在我们的例子中,数据集很小,所以我们没有选择自动化。
用 PDF 阅读器查看 PDF 文件,找出所有占两行的国家名称:
Bolivia (Plurinational State of)Democratic People's Republic of KoreaDemocratic Republic of the CongoLao People's Democratic RepublicMicronesia (Federated States of)Saint Vincent and the GrenadinesThe former Yugoslav Republic of MacedoniaUnited Republic of TanzaniaVenezuela (Bolivarian Republic of)
我们知道,这些国名的 Python 表示可能不是这样的,所以我们需要将国家打印出来,看看它们的 Python 表示是什么样子,然后将其添加到列表中:
if country_line:print '%r' % line ➊if previous_line in double_lined_countries:
❶ 添加 print '%r' 语句,输出国名的 Python 表示。
运行脚本,将双行国名的 Python 表示添加到 double_lined_countries 列表中:
double_lined_countries = ['Bolivia (Plurinational \n','Democratic People\xe2\x80\x99s \n','Democratic Republic \n','Micronesia (Federated \n',#... 糟糕!]
我们的输出中漏掉了 Lao People's Democratic Republic(老挝人民民主共和国),但它在 PDF 中占了两行。我们打开 PDF 的文本文件,看看问题出在哪里。
看完文本文件,你能发现问题所在吗?再看一下 turn_on_off 函数。这个函数的原理与文本的书写方式有什么关系?
问题在于,and areas 之后紧跟着一个空行(\n),这正是我们要寻找的标志。查看我们创建的文本文件,你会发现在 1345 行出现了意料之外的空行:
...1343 Countries1344 and areas13451346 Iceland1347 India1348 Indonesia1349 Iran (Islamic Republic of)...
这说明我们的函数没有正常运行。解决这个问题有好几种方法。对于这个例子来说,我们可以加入更多的代码逻辑,保证开 / 关代码的运行符合预期。开始采集国名时,在结束采集之前应该采集到了至少一个国家。如果一个国家都没有采集到的话,那么我们不应该结束采集过程。我们还可以使用上一行来解决这个问题。我们可以在开 / 关函数中检查上一行代码,确保它不属于某些特殊行。
我们采用增加特殊行的方法,以防遇到其他异常:
def turn_on_off(line, status, start, prev_line, end='\n'):"""该函数用于检查该行会是否开始/结束于特定值。如果是,且上一行不是特殊行,则状态设为开/关(真/假)。"""if line.startswith(start):status = Trueelif status:if line == end and prev_line != 'and areas': ➊status = Falsereturn status
❶ 如果当前行的值等于 end,而且上一行的值不等于 and areas,那么我们可以结束数据采集。这里我们用的是 !=,这是 Python 用来测试“不相等”的方法。与 == 类似,!= 返回的也是布尔值。
你还需要修改调用函数的代码,将 previous_line 传入函数:
country_line = turn_on_off(line, country_line, 'and areas', previous_line)total_line = turn_on_off(line, total_line, 'total', previous_line)
回到我们最开始的任务——创建双行国家的列表,确保采集到所有双行国家。我们前面进行到了这一步:
double_lined_countries = ['Bolivia (Plurinational \n','Democratic People\xe2\x80\x99s \n','Democratic Republic \n',]
查看 PDF 文件,我们看到下一个双行国家是 Lao People's Democratic Republic(老挝人民民主共和国)。我们继续将脚本输出的其他双行国家添加到这个列表中:
double_lined_countries = ['Bolivia (Plurinational \n','Democratic People\xe2\x80\x99s \n','Democratic Republic \n','Lao People\xe2\x80\x99s Democratic \n','Micronesia (Federated \n','Saint Vincent and \n','The former Yugoslav \n','United Republic \n','Venezuela (Bolivarian \n',]
如果你的列表看起来和上面的列表相似的话,运行脚本,你的输出应该找出了所有占两行的国名。一定要在脚本结尾添加 print 语句来查看国家列表:
import pprintpprint.pprint(countries)
前面我们在国家列表上花了不少时间,你能想出解决这个问题的其他方法吗?看一下几个双行国家的第二行:
' Republic of Korea \n'' Republic \n'' of the Congo \n'
它们有什么共同点?都以空格开头。用代码检查每一行开头是否有三个空格,这是一种更有效的做法。但是采用前面第一种方法,可以在采集数据的过程中发现数据集的部分缺失。随着你编程水平的不断提高,你将学会解决同一问题的各种方法,然后找出最佳方法。
下面我们看一下童工总数和国家的对应情况。修改 pprint 语句,如下所示:
import pprintdata = dict(zip(countries, totals)) ➊pprint.pprint(data) ➋
❶ 调用 zip(countries, totals),将国家列表和总数列表合并。这样把两个列表变成了元组。然后我们把元组传递给 dict 函数,将其转换成字典。
❷ 打印出我们刚创建的 data 变量。
返回的是一个字典,国家名称是字典的键,童工总数是字典的值。这并不是我们最终的数据格式。我们这样做是为了查看当前的数据。结果应该是像这样的:
{'': '-','Afghanistan': '10','Albania': '12','Algeria': '5 y','Andorra': '-','Angola': '24 x',...}
对比 PDF 再次检查这些数据,你会发现,就在双行国家第一次出现的地方,数据出现了错误。对应的数字来自出生登记(Birth registration)一列:
{...'Bolivia (Plurinational State of)': '','Bosnia and Herzegovina': '37','Botswana': '99','Brazil': '99',...}
如果查看 PDF 的文本文件,你会注意到在双行国家对应的数字那里有一个空行:
646326 y59 y
和采集国名遇到的问题一样,我们要用相同的方法来处理这个数据采集问题。如果我们的数据中有空白行,一定不要把空行采集到数据中,这样我们只采集与国名匹配的数据。修改后的代码如下:
for line in openfile:if country_line:print '%r' % lineif previous_line in double_lined_countries:line = ' '.join([clean(previous_line), clean(line)])countries.append(line)elif line not in double_lined_countries:countries.append(clean(line))elif total_line:if len(line.replace('\n', '').strip()) > 0: ➊totals.append(clean(line))country_line = turn_on_off(line, country_line,'and areas', previous_line)total_line = turn_on_off(line, total_line,'total', previous_line)previous_line = line
❶ 从经验中我们知道,PDF 文件使用换行符作为空行。本行代码用空字符串替代换行符,并删除空格来清洗数据。然后测试字符串的长度是否仍然大于 0。如果是的话,我们认为里面包含数据,并将其添加到童工总数列表中。
运行修改后的代码,在第一个双行国家那里数据又出现了问题。这次第一个双行国家对应的还是出生登记数据。之后的数值也都是错误的。回来看一下文本文件,找到问题出在哪里。如果你查看 PDF 文件里对应的那列数据,会发现 PDF 文本文件中的规律是从 1251 行开始的:
12501251 total1252 -1253 5 x1254 261255 -1266 -
进一步观察发现,出生登记列标题的结尾是 total:
266 Birth267 registration268 (%)+269 2005–2012*270 total271 37272 99
目前搜集童工总数的函数找寻的是 total 这个词,所以在找到下一行国家之前,我们先找到了这一列数据。我们还发现暴力惩戒比例[Violent discipline(%)]列也有一个 total 标签,上面有一个空行。这和我们要采集的 total 具有相同的规律。
接二连三地遇到 bug,说明你的代码逻辑可能存在问题。我们的脚本最开始用的是开 / 关函数,所以想要从根本解决问题,就要重构那里的逻辑。我们想要知道如何找到正确的数据列,或许可以采集列名并排序。我们可能还需要找到一种方法,检查“页码”是否发生了变化。如果我们一直这样头痛医头脚痛医脚,很可能会遇到更多的错误。
这就是编程的过程:写代码,调试,写代码,调试。无论是经验多么丰富的程序员,有时都会在代码中遇到错误。在学习编程的过程中,遇到错误会非常沮丧。你可能会想:“为什么无法运行?一定是我不擅长编程。”但事实并非如此。和其他事情一样,编程也需要练习。
现在看来,我们目前的方法显然是行不通的。根据我们目前对文本文件的了解,可以这么说,在利用文本寻找每一部分数据的开始和结束时,我们选用的标志是错误的。我们还可以用这个文件重新开始,换一个角度来思考;但我们想探索解决问题的其他方法,修正错误并获取想要的数据。
5.4 学习解决问题的方法
本节包含好几个练习,你可以试着解析 PDF 脚本,同时挑战自己写 Python 代码的能力。首先,我们先来回顾一下已经写好的代码:
pdf_txt = 'en-final-table9.txt'openfile = open(pdf_txt, "r")double_lined_countries = ['Bolivia (Plurinational \n','Democratic People\xe2\x80\x99s \n','Democratic Republic \n','Lao People\xe2\x80\x99s Democratic \n','Micronesia (Federated \n','Saint Vincent and \n','The former Yugoslav \n','United Republic \n','Venezuela (Bolivarian \n',]def turn_on_off(line, status, prev_line, start, end='\n', count=0):"""该函数用于检查该行会是否开始/结束于特定值。如果是,且上一行不是特殊行,则状态设为开/关(真/假)。"""if line.startswith(start):status = Trueelif status:if line == end and prev_line != 'and areas':status = Falsereturn statusdef clean(line):"""清洗代码行中的换行符、空格以及特殊符号。"""line = line.strip('\n').strip()line = line.replace('\xe2\x80\x93', '-')line = line.replace('\xe2\x80\x99', '\'')return linecountries = []totals = []country_line = total_line = Falseprevious_line = ''for line in openfile:if country_line:if previous_line in double_lined_countries:line = ' '.join([clean(previous_line), clean(line)])countries.append(line)elif line not in double_lined_countries:countries.append(clean(line))elif total_line:if len(line.replace('\n', '').strip()) > 0:totals.append(clean(line))country_line = turn_on_off(line, country_line,'and areas', previous_line)total_line = turn_on_off(line, total_line,'total', previous_line)previous_line = lineimport pprintdata = dict(zip(countries, totals))pprint.pprint(data)
有好几种方法可以解决我们面临的问题。在接下来的几节中,我们会讲到其中几种解决方法。
5.4.1 练习:使用表格提取,换用另一个库
前面我们对 PDF 转换成文本遇到的困难头痛不已,下面我们寻找其他方法来实现表格提取,不用 pdfminer。我们找到了 pdftables 库(http://pdftables.readthedocs.org/),这个库已经不再更新了(原作者的最后一次更新时间是两年多以前)。
我们需要安装必要的库(http://pdftables.readthedocs.io/en/latest/#installation),只需运行 pip install pdftables 和 pip install requests 即可完成安装。原作者并没有及时更新所有的文档,所以文档和 README.md 中的某些例子明显是错的。尽管如此,我们还是找到了一个“多合一”(all in one)的函数,可以用来获取我们想要的数据:
from pdftables import get_tablesall_tables = get_tables(open('EN-FINAL Table 9.pdf', 'rb'))print all_tables
我们创建一个新的代码文件(pdf_table_data.py)并运行。你应该会看到旋风般滚动的数据,看起来就是我们要提取的数据。你会注意到,标题并不是完全正确,但每一行的内容似乎都包含在 all_tables 变量中。我们来仔细观察一下,看看如何提取我们想要的标题、数据列和注释。
你可能也注意到了,all_tables 是一个由列表组成的列表(或者叫矩阵)。它有很多行,每一行里还包含很多行。这种方法可能很适合表格提取,因为表格本质上就是行和列。 get_tables 函数返回的是每一页内容组成的表格,每个表格都包含一个行列表,每个元素又是由许多列组成的列表。
第一步,找到每一列的标题。我们试着查看输出的前几行,看能否找到列标题:
print all_tables[0][:6]
我们看一下第一页的前六行:
... [u'',u'',u'',u'',u'',u'',u'Birth',u'Female',u'genital mutila',u'tion/cutting (%)+',u'Jus',u'tification of',u'',u'',u'E'],[u'',u'',u'Child labour (%',u')+',u'Child m',u'arriage (%)',u'registration',u'',u'2002\u201320',u'12*',u'wife',u'beating (%)',u'',u'Violent disciplin',u'e (%)+ 9'],[u'Countries and areas',u'total',u'2005\u20132012*male',u'female',u'2005married by 15',u'\u20132012*married by 18',u'(%)+ 2005\u20132012*total',u'prwomena',u'evalencegirlsb',u'attitudessupport for thepracticec',u'2male',u'005\u20132012*female',u'total',u'2005\u20132012*male',u'female'],...
可以看到,标题都包含在前三个列表中,格式混乱。从 print 语句的输出中还可以看出,每行数据还是相当干净的。如果我们对比 PDF 文件手动设置标题(如下所示),可以得到干净的数据集:
headers = ['Country', 'Child Labor 2005-2012 (%) total','Child Labor 2005-2012 (%) male','Child Labor 2005-2012 (%) female','Child Marriage 2005-2012 (%) married by 15','Child Marriage 2005-2012 (%) married by 18','Birth registration 2005-2012 (%)','Female Genital mutilation 2002-2012 (prevalence), women','Female Genital mutilation 2002-2012 (prevalence), girls','Female Genital mutilation 2002-2012 (support)','Justification of wife beating 2005-2012 (%) male','Justification of wife beating 2005-2012 (%) female','Violent discipline 2005-2012 (%) total','Violent discipline 2005-2012 (%) male','Violent discipline 2005-2012 (%) female'] ➊for table in all_tables:for row in table:print zip(headers, row) ➋
❶ 将所有标题添加到一个列表中,其中包括国名。现在我们可以将这个列表与行数据合并,将数据和标题对齐。
❷ 使用 zip 方法将标题与每一行数据合并。
从代码输出中可以看出,有些行我们已经匹配好了,但还有很多行不是国家行(和我们之前的结果类似,之前在表格中发现了多余的空格和空行)。
根据目前所学的内容,我们希望用编程加测试的方法解决这个问题。我们知道有些国家占了不止一行。我们还知道 PDF 文件用破折号(-)表示数据缺失,所以全空的行实际上不是数据行。从上一次 print 输出中我们就知道,每一页的数据从第六行开始。我们还知道,我们关注的最后一行是津巴布韦(Zimbabwe)。将我们已知的内容综合在一起,我们得到:
for table in all_tables:for row in table[5:]: ➊if row[2] == '': ➋print row
❶ 在每一页中找出我们想要的那些行,即索引数为 5 之后的切片。
❷ 如果数据为空,打印查看该行内容。
运行代码,你会发现列表中包含一些随机分布的空白行,其中也不包含国名。这可能就是我们上一段脚本的问题所在。我们尝试将国名合并在一起,跳过其他空白行。我们还加上对津巴布韦(Zimbabwe)的测试:
first_name = ''for table in all_tables:for row in table[5:]:if row[0] == '': ➊continueif row[2] == '':first_name = row[0] ➋continueif row[0].startswith(' '): ➌row[0] = '{} {}'.format(first_name, row[0])print zip(headers, row) ➍if row[0] == 'Zimbabwe':break ➎
❶ 如果数据行索引数为 0 的值缺失,说明这一行不包含国名,是一个空行。下一行代码用 continue 跳过这一行,continue 是一个 Python 关键字,作用是转到 for 循环的下一次迭代。
❷ 如果数据行索引数为 2 的值缺失,我们知道这可能是国名的前半部分。本行代码将国名的前半部分保存为变量 first_name。下一行代码跳转到下一行数据。
❸ 如果数据行以空格开头,我们知道这是国名的后半部分。我们希望将国名的两部分重新合并在一起。
❹ 如果我们的假设正确,观察打印出的结果,数据应该是匹配好的。本行代码打印出每次迭代的内容,便于我们观察。
❺ 遇到津巴布韦(Zimbabwe)时,本行代码跳出 for 循环。
大部分数据看起来都是正确的,但我们还会发现一些异常数据。看下面这个例子:
[('Country', u'80 THE STATE OF T'),('Child Labor 2005-2012 (%) total', u'HE WOR'),('Child Labor 2005-2012 (%) male', u'LD\u2019S CHILDRE'),('Child Labor 2005-2012 (%) female', u'N 2014'),('Child Marriage 2005-2012 (%) married by 15', u'IN NUMBER'),('Child Marriage 2005-2012 (%) married by 18', u'S'),('Birth registration 2005-2012 (%)', u''),.....
可以看到,开头的页码被误以为是国名。你知道哪些国家名称里有数字吗?我们当然不知道!我们添加一个对数字的测试,看是否能剔除坏数据。我们还注意到双行国家的对应并不正确。从输出来看,pdftables 在导入数据时会自动修正行首的空格。太好了!现在我们应该添加一个测试,测试上一行数据有没有 first_name:
from pdftables import get_tablesimport pprintheaders = ['Country', 'Child Labor 2005-2012 (%) total','Child Labor 2005-2012 (%) male','Child Labor 2005-2012 (%) female','Child Marriage 2005-2012 (%) married by 15','Child Marriage 2005-2012 (%) married by 18','Birth registration 2005-2012 (%)','Female Genital mutilation 2002-2012 (prevalence), women','Female Genital mutilation 2002-2012 (prevalence), girls','Female Genital mutilation 2002-2012 (support)','Justification of wife beating 2005-2012 (%) male','Justification of wife beating 2005-2012 (%) female','Violent discipline 2005-2012 (%) total','Violent discipline 2005-2012 (%) male','Violent discipline 2005-2012 (%) female']all_tables = get_tables(open('EN-FINAL Table 9.pdf', 'rb'))first_name = Falsefinal_data = []for table in all_tables:for row in table[5:]:if row[0] == '' or row[0][0].isdigit():continueelif row[2] == '':first_name = row[0]continueif first_name: ➊row[0] = u'{} {}'.format(first_name, row[0])first_name = False ➋final_data.append(dict(zip(headers, row)))if row[0] == 'Zimbabwe':breakpprint.pprint(final_data)
❶ 如果这一行有 first_name,那么在该行内将国名合并。
❷ 将 first_name 重新设置为 False,这样下一次迭代可以正常运行。
现在数据导入工作已全部完成。如果你希望数据结构与从 Excel 导入的数据完全相同,需要对数据做进一步处理,但我们已经可以将 PDF 中的数据保存成行数据。
pdftables已经不再受到积极的支持,它的开发者现在提供替代的新产品,但却是收费的(https://pdftables.com/)。依赖不受支持的代码是很危险的,我们也不能认为pdftables总是可用 3。但是,开源社区的一部分内容就是回馈,所以我们鼓励你找到好项目,为它做贡献,帮它宣传,希望像pdftables这样的项目能够保持开源,能够继续成长并发展。
3似乎的确有人在维护并支持一些活跃的 GitHub 分支(https://github.com/drj11/pdftables/network)。我们建议你关注这些仓库的动态,以满足 PDF 表格解析的需求。
下面,我们来看一下解析 PDF 数据的其他方法,其中包括手动清洗数据。
5.4.2 练习:手动清洗数据
我们来聊一聊一个大家闭口不谈却确实存在的事实。阅读本章的过程中,你可能一直想知道,我们为什么不修改 PDF 文本文件,这样处理起来会更方便。你可以这么做,这是解决问题的众多方法之一。但我们希望你能挑战一下,用 Python 工具处理这个文件。你也不是每次都能手动修改 PDF 文件。
如果在处理 PDF 或其他文件类型时遇到了困难,一种按部就班的方法是将数据提取到文本文件,然后手动处理数据。在这种情况下,提前预估一下你愿意在手动处理上花费的时间,然后将实际花费的时间控制在这个范围内。
想了解数据清洗自动化的更多内容,请查阅第 8 章。
5.4.3 练习:试用另一种工具
当最开始寻找用来解析 PDF 的 Python 库时,我们在网络上搜索其他人如何完成这个任务,并找到了 slate,它看起来很好用,但需要一些自定义代码。
想了解还有哪些可用的工具,我们试着搜索“extracting tables from pdf”(从 pdf 中提取表格),而不是搜索“parsing pdf python”(解析 pdf python),这样可以找到针对表格问题的解决方法(其中有一篇博客文章对几种工具做了对比,http://www.interhacktives.com/2014/03/12/extract-data-pdf/)。
对于像我们要解析的这种小型 PDF,我们可以使用 Tabula(http://tabula.technology/)。 Tabula 不一定总能解决问题,但它有一些很好的功能。
Tabula 的使用方法如下。
(1) 下载 Tabula(http://tabula.technology/)。
(2) 双击启动应用,这会在浏览器中打开 Tabula 工具。
(3) 上传童工 PDF 文件。
从这里开始,你需要修改 Tabula 选择抓取的内容。跳过标题行可以让 Tabula 找到每一页的数据并自动高亮,方便后续提取。首先,选择你感兴趣的表格(见图 5-3)。
图 5-3:在 Tabula 中选择表格
接下来,下载数据(见图 5-4)。
图 5-4:Tabula 的下载界面
点击“Download CSV”(下载 CSV 文件),你会得到类似图 5-5 中的数据。
图 5-5:提取的 CSV 数据
得到的数据并不完美,但比我们用 pdfminer 得到的数据更干净。
接下来的挑战是,解析 Tabula 创建的 CSV 文件。这与我们解析过的其他 CSV(见第 3 章)有所不同,要更杂乱一些。如果你遇到困难,可以先放在一边,等读完第 7 章再回来解决它。
5.5 不常见的文件类型
目前为止,本书已经讲过 CSV、JSON、XML、Excel 和 PDF 文件。PDF 中的数据很难解析,你可能认为数据解析的世界不能比这更糟了。遗憾的是,还有比这更糟糕的事情。
好消息是,你可能不会遇到前人尚未解决的问题。记住,向 Python 社区或更高一级的开源社区寻求帮助和建议,这永远都是一个好方法,即使你已经认识到应该寻找更容易解析的数据集。
如果数据具有以下特征,你可能会遇到问题。
文件由旧系统生成,使用的是一种不常见的文件类型。
文件由专用系统(proprietary system)生成。
你所有的程序都无法打开该文件。
对于与不常见文件类型相关的问题,仅仅用你之前学过的知识就可以解决。
(1) 确定文件类型。如果从文件扩展名上不容易看出,那么可以用 python-magic 库(https://pypi.python.orgpypipython-magic/0.4.6)。
(2) 在互联网上搜索“how to parse <file extension> in Python”(用 Python 如何解析 < 文件扩展名 >),将“<file extension>”替换为实际的文件扩展名。
(3) 如果找不到显而易见的解决方法,尝试用文本编辑器打开该文件,或者用 Python 的 open 函数读取该文件。
(4) 如果字符看起来很奇怪,读一些关于 Python 编码的内容。如果你是第一次接触 Python 字符编码,可以观看 PyCon 2014 的演讲“Python 中的字符编码和 Unicode”(https://www.youtube.com/watch?v=Mx70n1dL534)。
5.6 小结
PDF 以及其他难以解析的格式,是你会遇到的最糟糕的格式。如果你找到这些格式的数据,应该做的第一件事就是看能否找到其他格式的数据。对于我们的例子来说,我们从 CSV 格式得到的数据更为精确,因为 PDF 表格中的数字是经过四舍五入的。越是原始的数据格式,数据可能就越精确,用代码解析也越容易。
如果找不到其他格式的数据,那你应该尝试以下步骤。
(1) 确定数据类型。
(2) 在互联网上搜索其他人解决问题的方法。有没有帮助导入数据的工具?
(3) 凭直觉选择你要用的工具。如果是 Python,选择你认为最合适的库。
(4) 尝试将数据转换成更容易使用的格式。
表 5-1 列出了我们在本章学过的库和工具。
表5-1:新的Python库和工具
| 库或工具 | 作用 |
|---|---|
slate
| 每次运行脚本时,都将 PDF 解析为内存里的一个字符串 |
pdfminer
| 将 PDF 转换为文本,这样你就可以解析文本文件 |
pdftables
|
首先用 pdfminer 将 PDF 解析成文本,然后尝试寻找表格,并将每一行内容对齐
|
Tabula
| 提供操作界面,可以将 PDF 数据提取成 CSV 格式 |
除了上面这些新工具,我们还学习了 Python 编程的一些新概念,表 5-2 对这些新概念做了汇总。
表5-2:Python编程新概念
| 概念 | 作用 |
|---|---|
| 转义字符(http://learnpythonthehardway.org/book/ex10.html) |
转义字符告诉计算机,文件路径或文件名中有一个空格或特殊字符,告知方式是在其前面加一个反斜线(\)。一种用法是在空格前加 \ 将其转义
|
\n
|
\n 是文件中行尾或新行的标志
|
elif(https://docs.python.org/2/tutorial/controlflow.html)
|
在写 if-else 语句的过程中,我们可以添加额外的条件再次测试:if…elif…elif…else
|
| 函数(https://docs.python.org/2/tutorial/controlflow.html#defining-functions) | Python 函数用来执行一段代码。将可复用的代码写成函数,我们可以避免多次重复 |
zip(https://docs.python.org/2.7/library/functions.html#zip)
|
zip 是 Python 内置函数,将两个可迭代对象转换成由元组构成的列表
|
| 元组(https://docs.python.org/2.7/library/functions.html#tuple) | 元组和列表类似,但是不可更改(immutable),也就是说,不能修改元组。想修改一个元组,需要将其保存为一个新对象 |
dict 转换(https://docs.python.org/2.7/library/functions.html#func-dict)
|
dict 是 Python 内置函数,将输入转换成字典。输入数据应满足键值对的形式,这样函数才能正常运行
|
下一章我们将讨论数据获取与存储。这样我们就能了解关于获取其他数据格式的更多内容。在第 7 章和第 8 章,我们会讲到数据清洗,这也对我们处理复杂的 PDF 有所帮助。
