第 11 章 网页抓取:获取并存储网络数据
网页抓取是当今世界数据挖掘中必不可少的一部分,因为你几乎可以在网络上找到任何事物。有了网页抓取,你可以使用 Python 库来探索 Web 页面、搜索信息并收集它们以撰写报告。网页抓取让你爬取站点,发现在没有机器人协助的情况下不容易获取的信息。
这项技术使你能够获取 API 或文档之外的数据。想象一个脚本登录你的 E-mail 账户,下载文件,运行分析,并且发送一个整合的报告。想象一下不用使用浏览器就可以测试站点,以确定它具备完整的功能。想象一下从一个定期更新的网站的一系列表格中抓取数据。这些示例展示了网页抓取如何能帮助你完成数据处理的需求。
根据爬取内容的不同——本地或公开站点,XML 文档——你可以使用很多相同的工具完成这些任务。大多数网站在 HTML 代码中包含数据。HTML 是一种标记语言,使用括号(类似于第 3 章中的 XML 示例)来包含数据。在这一章,我们会使用一些能够解析和读取 HTML 和 XML 等标记语言的库。
很多站点使用内部的 API 和嵌入的 JavaScript 脚本来控制页面上的内容。由于这些构建站点的新方式,并不是所有的信息都能够使用读页面的抓取器找到。我们还会学习如何使用一些读屏幕的 Web 抓取器,应对拥有多个数据源的站点。根据站点的组成,你可能同样可以连接 API;在第 13 章你会了解更多有关 API 的信息。
11.1 抓取什么和如何抓取
网页抓取为数据收集带来了无限可能。在互联网上有成千上万的站点,拥有可能会在项目中使用的各种各样的内容和数据。为了构建一个认真负责的网页抓取器,要熟悉每一个站点,以及可抓取的内容。
版权、商标和抓取
当在网络上抓取时,对于你找到的所有媒体(来自报纸、杂志、书籍或博客),你应该考虑收集的数据和它们的使用方式。你是否会下载其他人的照片并且将它当作自己的照片发布?不,这是不道德的,而且在一些情况下是非法的。
学习像版权(http://www.dmlp.org/legal-guide/copyright)和商标(http://www.dmlp.org/legal-guide/trademark)这样的媒体法会影响你的决定,尤其是要抓取的数据属于某人的知识产权(http://www.dmlp.org/legal-guide/intellectual-property)时。
研究域名并查阅法律允许内容和禁止内容的有关提示,还要熟读robots 文件(http://www.robotstxt.org/robotstxt.html)来更好地理解网站所有者的意愿。如果你不确定数据能否被抓取,可联系律师或网站本身。取决于你的住址和使用数据的目的,如果你对本国法律和判例存有疑问,可能需要联系一家数字媒体法定组织。
对于大多数的网络抓取,抓取文本会比抓取链接、图片或图表更合理。如果你还需要保存链接、图片或文件,这其中的大多数都可以使用简单的 bash 命令(例如
wget或curl,http://www.thegeekstuff.com/2012/07/wget-curl/)下载,而这不需要 Python。你可以直接保存一个 URL 列表到文件中并且写一个脚本来下载文件。
我们从简单的文本抓取开始。大多数网页的构建都基于适当的 HTML 标准,结构相似。大多数的网站有一个头部,大多数的 JavaScript 和页面样式文件在这里定义,同时还有其他额外信息,比如类似 Facebook、Pinterest 这样的服务的元标签,以及搜索引擎用法的描述信息。
头部之后是主体。主体是站点的主要部分。大多数的站点使用容器(类似 XML 节点的标记节点)来组织站点,并且允许站点内容管理系统加载内容到页面中。图 11-1 展示了一个典型的网页是如何组织的。
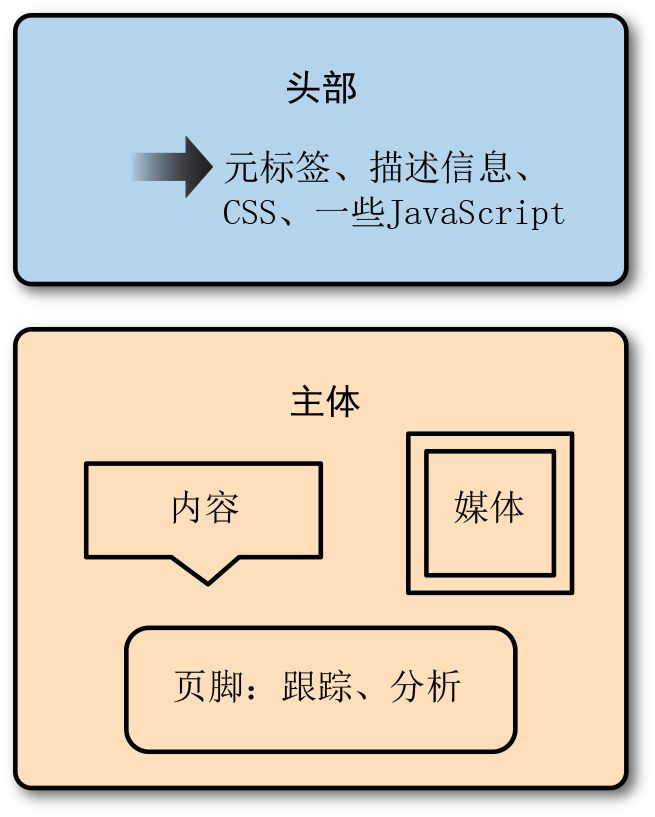
图 11-1:网页解剖
对于很多站点来说,页面的顶部部分包含到站点主要部分或者相关主题的导航和链接。链接或者广告通常出现在页面两边向下延展的位置。页面的中间部分通常包含你想要抓取的内容。
一旦知道了在页面上寻找什么,并且通过学习页面源代码的结构分析了页面的组成,你就可以确定如何收集页面中的重要的部分。许多网页在第一次页面加载的时候提供内容,或者提供一个已加载好内容的缓存页面。对于这些页面,可以使用简单的 XML 或 HTML 解析器(我们会在本章学习它们),并且从第一个 HTTP 响应(在你请求一个 URL 时浏览器加载的内容)中直接读取内容。这与读取文档类似,只是需要一个初始的页面请求。
如果你需要首先同页面交互来获取数据(也就是输入数据和点击按钮),并且它不仅仅是一个简单的 URL 的改变,你需要使用一个基于浏览器的抓取器,在浏览器中打开页面同它交互。
如果需要遍历整个网站来收集数据,你会想要一个爬虫:一个机器人,它爬取网页,并且根据规则识别好的内容或跟踪更多页面。我们在爬取中使用的库非常地快速、灵活,让编写这些类型的脚本变得十分简单。
在开始编写抓取器代码之前,我们会查看一些网站,习惯于分析要使用那个类型的抓取器(页面读取器、浏览器读取器或爬虫),以及抓取数据会多难或多简单。有时,确定数据值得付出多少努力是很重要的。我们会介绍一些工具来确定为抓取数据需要付出多少努力,以及值得为这项工作投入多少时间。
11.2 分析网页
网络抓取的大多数时间会花费在观察浏览器标记语言和搞清楚如何同它交互上。了解你最爱的浏览器的调试或开发工具是成为一名高级网页抓取者的必要环节。
根据浏览器的不同,工具可能有不同的名称和功能,但是概念是相同的。你需要自学最喜欢的浏览器工具,不管是 IE(https://msdn.microsoft.com/library/bg182326(v=vs.85))、Safari(https://developer.apple.com/safari/tools/)、Chrome(https://developer.chrome.com/devtools)或 Firefox(https://developer.mozilla.org/en-US/docs/Tools/GCLI)。
每个浏览器的调试器都是类似的。你会在一个区域看到请求和页面加载数据(通常叫网络或者其他类似的东西);在另外一个区域分析页面的标记信息,看到每个标签中的内容和样式(通常叫作检视、元素或 DOM)。在第三个区域,你可以看到 JavaScript 错误,并同页面中的 JavaScript 交互;这个区域通常叫作控制台。
你的浏览器开发者工具可能还有其他的标签,但是我们真的只需要这 3 个标签来理解页面是如何构建的,以及如何简单地抓取内容。
11.2.1 检视:标记结构
当你想要抓取一个站点的时候,首先分析站点结构和标记语言。像在第 3 章学到的那样, XML 的结构由节点和内容以及键和值组成。HTML 非常相似。如果打开浏览器的开发者工具,浏览检视(Inspection)、元素(Elements)或 DOM 标签,你会看到一系列的节点和它们的值。节点和其包含的数据同我们在 XML 示例中看到的有一些不同——它们是 HTML 标签(表 11-1 列出了一些基本的标签)。HTML 标签用来告诉你内容信息。如果你想找到页面上的所有图片,查找 img 标签。
表11-1:基本的HTML标签
| 标签 | 描述 | 示例 |
|---|---|---|
head
| 用来存储元数据和文档的其他必需信息 |
|
body
| 用来存储页面大部分内容 |
|
meta
| 用来存储元数据,例如站点简短的描述或关键词 |
|
h1,h2,h3 …
| 用来存储头部信息;数字越小,头部越大 |
|
p
| 用来存储文本段落 |
|
ul,ol
|
用来存储无序表(ul:圆点)和有序表(ol:数字)
|
|
li
|
用来存储列表对象;应该始终位于一个列表(ul 或 ol)中
|
|
div
| 用于分节或划分内容 |
|
a
| 用于链接内容,被称作“锚标签” |
Best Ever
|
img
| 用于插入一张图片 |
|

关于 HTML 标签和其使用方式的完整介绍,请查看 Mozilla 开发者网络的 HTML 参考、指南和介绍(https://developer.mozilla.org/en-US/docs/Web/HTML)。
除了使用的标签和内容结构,每个标签之间放置的位置很重要。类似于 XML,HTML 也有父元素和子元素。在结构中存在层次关系。父节点拥有子节点,而学习如何遍历家族树结构会帮助你得到想要的内容。了解元素之间的关系,无论它们是双亲节点、子节点还是同级节点,会帮助你编写更高效、快速和易于更新的抓取器。
让我们仔细地查看在 HTML 页面中这些关系意味着什么。下面是一个基本的 HTML 站点的结构。
<!DOCTYPE html><html><head><title>My Awesome Site</title><link rel="stylesheet" href="css/main.css" ><head><body><header><div id="header">I'm ahead!</div></header><section class="main"><div id="main_content"><p>This site is super awesome! Here are some reasons it's so awesome:</p><h3>List of Awesome:</h3><ul><li>Reason one: see title</li><li>Reason two: see reason one</li></ul></div></section><footer><div id="bottom_nav"><ul><li><a href="about">About<a></li><li><a href="blog">Blog<a></li><li><a href="careers">Careers<a></li></ul></div><script src="js/myjs.js"></script></footer></body></html>
如果从这个页面的第一个标签开始(文档类型声明下),可以看到整个页面的所有内容都在 html 标签下。html 标签是整个页面的根标签。
在 html 标签内,有标签 head 和 body。页面的大部分内容在标签 body 内,但是 head 也有一些内容。标签 head 和 body 是 html 元素的子标签。反过来,这些标签有着他们自己的子标签和后继标签。head 和 body 标签是同级关系。
查看主 body 标签的内部,可以看到其他一些家族关系。所有这些列表对象(li 标签)是无序列表(ul 标签)的子标签。header、section 和 footer 标签是同级关系。script 是 footer 的子标签,是 footer 中 div 标签的邻居,用来存储链接。还有很多复杂的关系,这只是一个简单的页面!
为了更深入地研究,下面的代码展示了一个有着更复杂关系的页面(处理网页抓取时,几乎很难有一个所有元素组织合理且关系完整的完美页面):
<!DOCTYPE html><html><head><title>test</title><link ref="stylesheet" href="style.css"></head><body><div id="container"><div id="content" class="clearfix"><div id="header"><h1>Header</h1> ➊</div><div id="nav"> ➋<div class="navblock"> ➌<h2>Our Philosophy</h2><ul><li>foo</li><li>bar</li></ul></div><div class="navblock"> ➍<h2>About Us</h2> ➎<ul><li>more foo</li> ➏<li>more bar</li></ul></div></div><div id="maincontent"> ➐<div class="contentblock"><p>Lorem ipsum dolor sit amet...</p></div><div class="contentblock"><p>Nunc porttitor ut ipsum quis facilisis.</p></div></div></div></div><style>...</style></body></html>
❶ 当前元素父元素的前面的邻居的第一个子元素。
❷ 当前元素的父级 / 祖先。
❸ 当前元素的邻居。
❹ 当前元素。
❺ 当前元素的第一个子元素 / 后代。
❻ 当前元素的子元素 / 后代。
❼ 当前元素父元素的下一个邻居。
为便于讨论,“当前元素”是第二个为 navblock 类的 div。可以看到它有两个子元素,一个是标题(h2),另一个是无序列表(ul),同时还有列表对象(li)位于列表中。它们是后代(取决于你想使用的库,它可能被包含在“all children”中)。当前元素有一个邻居,即第一个为 navblock 类的 div。
ID 为 nav 的 div 是当前元素的父元素,但是我们的元素有其他的祖先。如何从当前元素移动到 ID 为 header 的 div ?我们的父元素是 header 元素的邻居。为了得到 header 元素的内容,可以找到父元素的前面的邻居。父元素同样有另外一个邻居,即 ID 为 maincontent 的 div。
所有这些关系被描述为文档对象模型(DOM)结构。HTML 用规则和标准来组织页面上的内容(也被称作文档)。HTML 元素节点是“对象”,并且为了正确地展示,它们必需遵循一个模型 / 标准。
花费在理解节点之间的关系上的时间越多,使用代码快速有效地遍历 DOM 树就越容易。在本章之后的部分,我们会介绍 XPath,它使用家族关系选择内容。现在,进一步理解了 HTML 结构和 DOM 元素之间的关系之后,我们可以更仔细地研究定位和分析在选择的站点上想要抓取的内容。
我们会在示例中使用 Chrome,但是你可以使用自己最喜欢的浏览器。当研究非洲的童工时,我们发现了将童工与冲突相联系的数据。这促使我们找到致力于阻止非洲冲突地带和冲突矿产的组织。打开其中一个组织的页面:Enough 项目的 Take Action 页面(http://www.enoughproject.org/take_action)
当第一次打开开发者工具时——在 Chrome 中选择工具→开发者工具,在 IE 中敲击 F12,在 Firefox 中选择工具→网页开发者→检视器,或者在 Safari 高级设置中启用开发者菜单——我们会在一个面板中看到标记信息,在另外一个小的面板中看到 CSS 规则和样式,在工具上方的一个面板中看到真正的页面。对于不同的浏览器,布局可能会不同,但是用这些工具查看这些特性时应该会很相似(见图 11-2)。
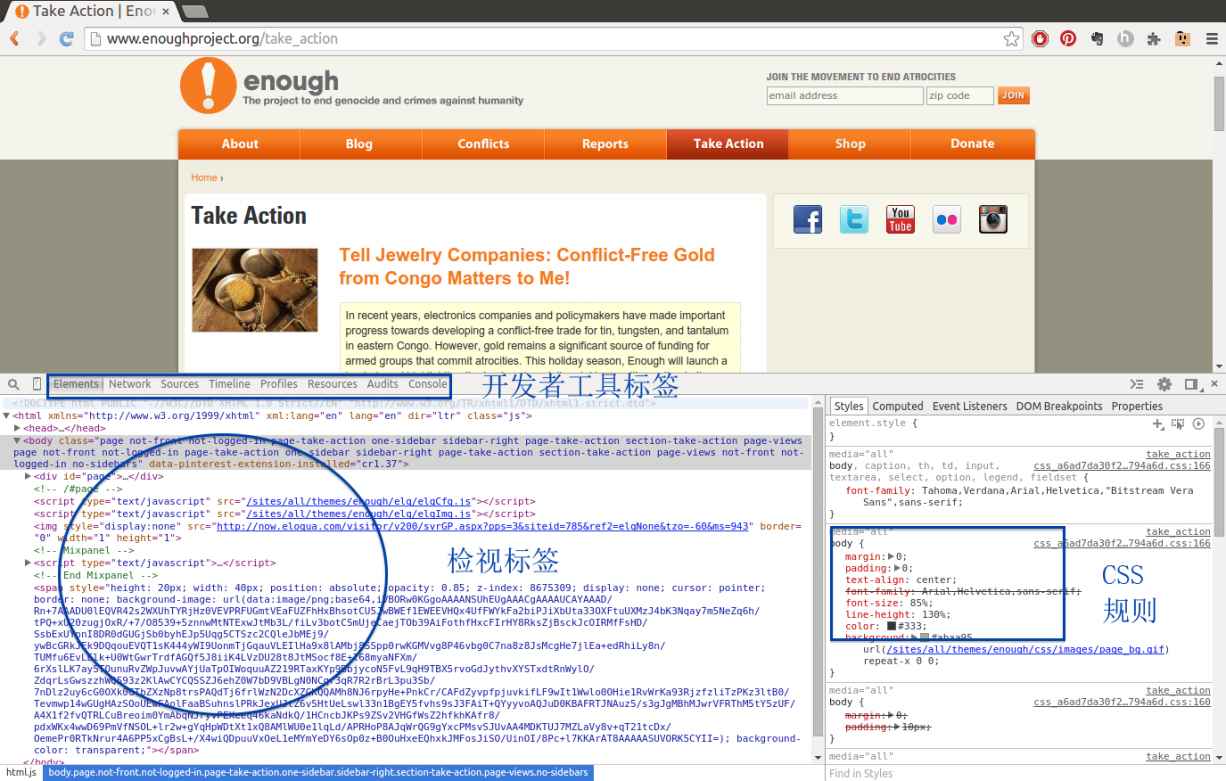
图 11-2:Enough 项目的 Take Action 页面
如果点击与 div 和页面主元素相邻的箭头,你可以看到位于其中的元素(子元素)。举个例子,在 Enough 项目主页上,可以通过点击右边栏(在图 11-3 中圈出),打开 main-inner-tse div 和其他内部的 div。
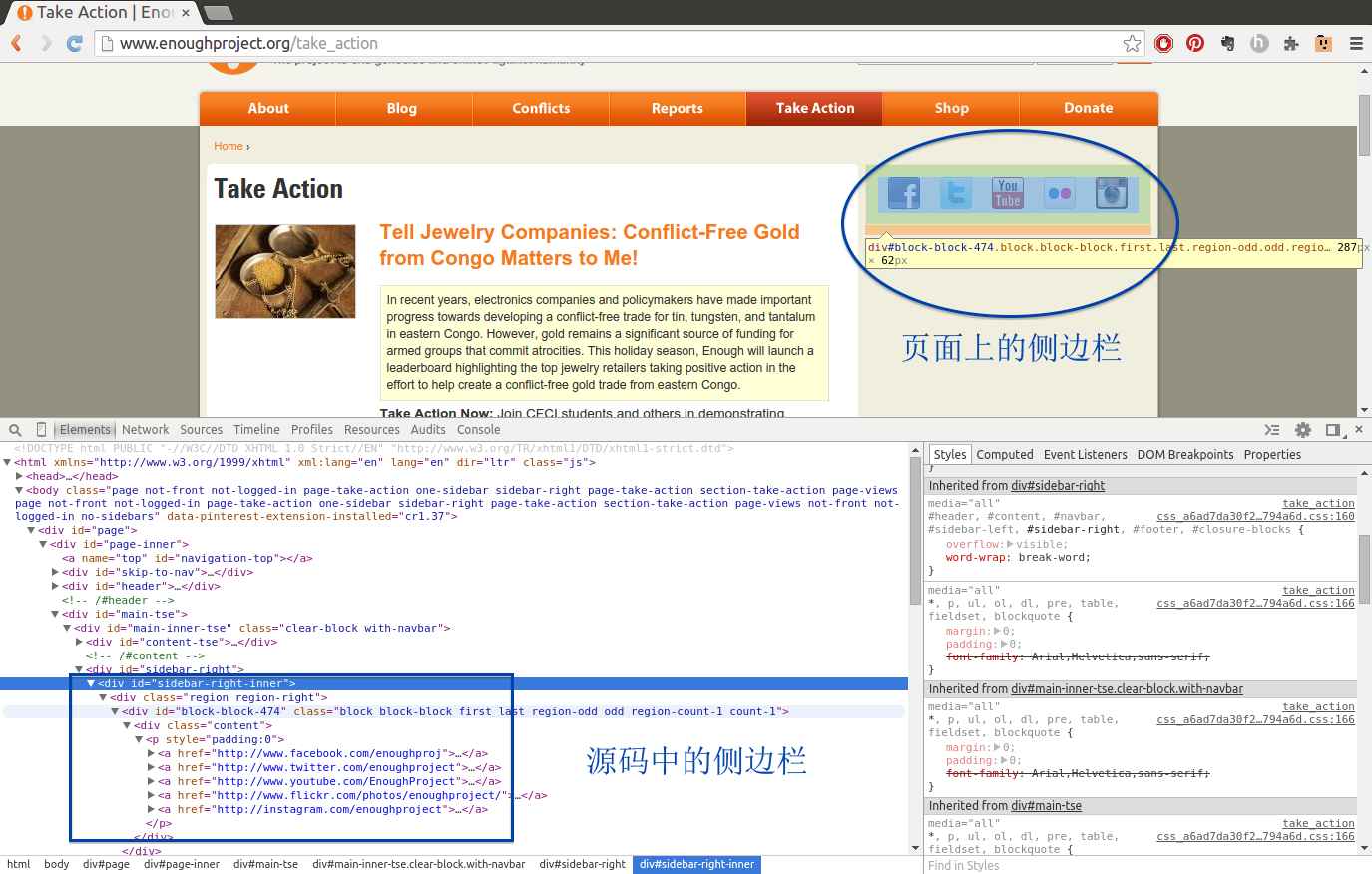
图 11-3:探索侧边栏
可以看到侧边栏图片在链接之内,链接位于一个段落之中,而段落在 div 中——这个列表很长。理解什么时候图片在链接中(或不在),确定哪个内容位于段落标签中,以及找到其他页面结构元素是定位和抓取页面内容所必需的。
开发者工具的另外一个非常棒的用处是研究元素。如果右击页面的一部分,你应该会看到一个包括了一些有用的用于网页抓取的工具的菜单。图 11-4 展示了一个菜单的实例。
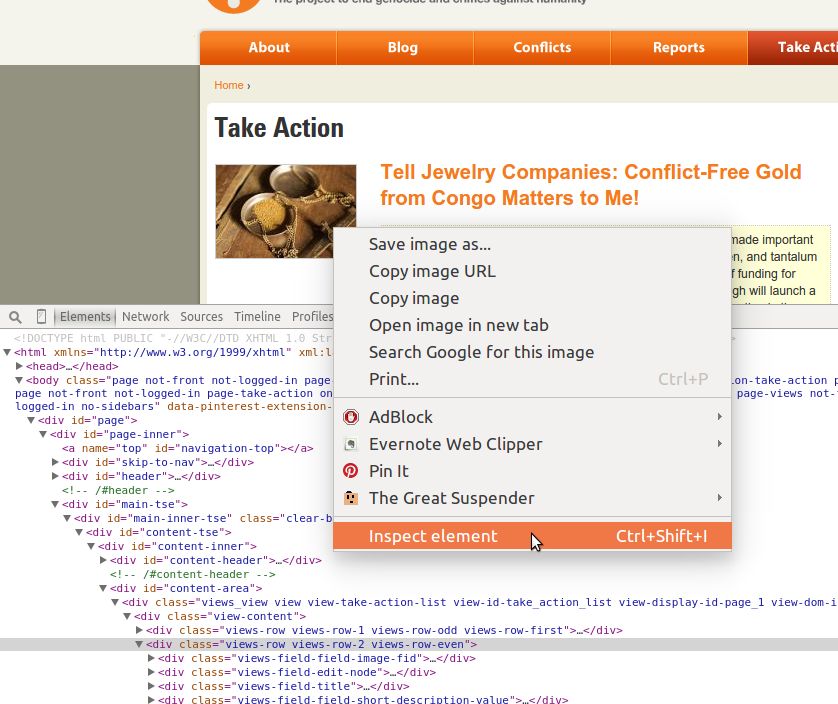
图 11-4:检视元素
如果点击“检视元素”选项,开发者工具应该会在源代码中打开那个元素。这是一个非常有用的特性,可用于与内容交互,以及查看其在代码中的位置。
除了能够在浏览器中同元素交互之外,你还可以在源代码部分同元素交互。图 11-5 展示了通过在标记结构区域右击一个元素得到的菜单类型。可以看到复制 CSS 选择器或 XPath 选择器(我们会在本章中使用这两者定位和抽取网站内容)的选项。
图 11-5:元素选项
除了找到元素和内容之外,开发者工具展示了大量有关页面上节点结构和家族关系的信息。在开发者工具中,通常会有一个检视标签,展示当前元素的父元素列表。该列表中的元素通常可以被点击或者选择,所以你可以通过一个简单的点击遍历 DOM。在 Chrome 中,这个列表在开发者工具和上方页面之间的灰色部分。
我们已经查看了 Web 页面的组织结构,以及如何同它们交互来更好地理解内容的位置。现在来研究浏览器中让网页抓取更加简单的其他强大工具。
11.2.2 网络/时间线:页面是如何加载的
分析开发者工具中的时间线(Timeline)/ 网络(Network)标签将让你深刻理解页面内容是如何加载的以及加载的顺序。页面加载的时间和方式可以极大地影响你决定抓取页面的方式。有时,理解内容来源是抓取所需内容的“快捷方式”。
网络或时间线标签展示了已加载的 URL、加载顺序和加载所需时间。图 11-6 展示了 Enough 项目页面在 Chrome 中网络标签的样子。对于不同的浏览器,你可能需要重新加载页面,来查看网络标签页面的内容。
图 11-6:一个页面的网络标签
由于在网络标签中只有一个请求,可以看到整个页面在一次调用中加载完成。这对于网页抓取器来说是很棒的消息,因为这意味着通过一个请求可以获得一切。
如果点击这个请求,可以看到更多的选项,包括响应的源代码(见图 11-7)。当页面通过许多不同的请求加载时,查看每个请求的内容对于定位所需内容很重要。如果你需要额外的数据来加载站点,可以通过点击网络标签中的头部标签来研究头部和 cookie。
图 11-7:网络响应
来查看一个有着复杂网络标签的相似组织的页面。打开你的网络标签,使用浏览器访问 Fair phone 倡议站点上的#WeAreFairphone 页面(http://www.fairphone.com/we-are-fairphone/,图 11-8)。
图 11-8:有很多页面的网络标签
你可以立即看到这个页面正在处理更多的请求。点击每一个请求,你可以看到每一个请求加载的内容。请求顺序显示在网络标签中的时间线上。这可以帮助你理解如何抓取和处理页面,来得到需要的内容。
通过点击每一个请求,可以看到初始页面加载后再加载大部分内容。点击初始页面的请求,会发现并没有什么内容。我们想要问的第一个问题是:这里是否有一个 JavaScript 请求或其他的请求使用 JSON 加载内容?如果有的话,对于我们的脚本来说,这可能是一个恰当的“快捷方式”。
如果这里没有简单的 JSON URL 匹配你需要的信息,或者信息散落在几个不同的的请求中,需要人工整合它们到一起,那么可以确定,你需要使用一个基于浏览器的方法来抓取站点。基于浏览器的网页抓取允许你读取看到的页面,而不仅是每一个请求。如果你需要在正确抓取内容之前同一个下拉菜单交互,或执行一系列基于浏览器的操作,这可以很有用。
网络标签帮助你找到包含所需内容的请求,以及是否有优秀的备选数据源。我们接下来会查看 JavaScript,看看这是否也会提供一些关于抓取器的想法。
11.2.3 控制台:同JavaScript交互
现在已经分析了页面的标记和结构,以及页面加载和网络请求的时间线,让我们转到 JavaScript 控制台,来看一下通过和运行在页面上的 JavaScript 交互,可以学到什么。
如果你已经对 JavaScript 很熟悉,使用起来应该相当简单;如果你从未同 JavaScript 交互过,花一些时间查看关于 JavaScript 课程的介绍(http://www.codecademy.com/en/tracks/javascript)会很有用。你只需要理解 JavaScript 的基本语法,能够通过控制台同页面上的元素交互。我们会从学习 JavaScript 和基本的样式开始,学习如何使用控制台界面。
- 样式基础
每一个网页都会使用一些样式元素来帮助它组织内容、控制内容的大小和颜色,并在视觉上修改内容。当浏览器开始开发 HTML 标准,样式标准也就诞生了。样式标准的产物是级联样式表,即 CSS,这为我们提供了给页面添加样式的标准方式。举个例子,如果想要所有的标题使用不同的字体,或所有的照片在页面居中显示,你需要在 CSS 中编写这些规则。
CSS 允许样式级联,或者从父样式和样式表中继承。如果我们为整个站点定义一个样式集合,内容管理系统将很容易让每个页面看起来相似。即使我们有一个复杂站点,它有很多不同的页面类型,我们也可以定义一个主要的 CSS 文档和几个次要的文档,在页面需要额外的样式时加载次要文档。
CSS 有效,因为它定义了允许通过标签中的属性组合 DOM 元素的规则。是否记得在第 3 章研究 XML 时,讨论过嵌套属性? CSS 同样使用这些嵌套的属性。让我们学习使用元素检视工具。因为你很可能仍然在 Fairphone 站点,所以让我们看一些页面上的 CSS 属性。当在底部工具栏高亮一个元素时,会看到一些与页面中元素相关的文本展示在旁边(图 11-9)。

图 11-9:CSS 简介
在这个例子中,我们已经了解了 div 的含义,但是什么是 contont-block ?使用检视技术看一下 HTML 代码(右击页面上的元素,选择“检视元素”)。
我们看到 contentblock 是 CSS 类(在图 11-10 中的嵌套属性 class="contentblock"中)。它定义在一个起始 div 标签中,同时这个 div 保存着所有其他子标签。说到 CSS 类,在页面的这个部分中,你能看到多少个类?有好多啊!
图 11-10:CSS 类
像类一样,同样有 CSS ID。让我们找一个(见图 11-11),看看它与类有什么不同。

图 11-11:CSS ID
HTML 看起来很类似,但是在导航栏的符号中使用了一个哈希或英镑符号。#是一个适用于 ID 的 CSS 选择器。对于类,我们使用 .(如同在 div.contentblock 中展示的)。
id必需是唯一的,但是你可以有很多的元素有相同的class。尽管页面不总是符合这一结构,但是这也值得注意。一个 CSSid相对于一个class有更大的特异性。一些元素不只有一个class,所以它们可以应用多个样式。
使用右击菜单,在页面上复制 CSS 选择器相当简单。如果你已经了解了 CSS,这些知识会帮助你进行网页抓取。如果你不是太了解 CSS,但是希望更深入地探索它,可以查看 Codecademy 关于 CSS 课程的介绍(https://www.codecademy.com/courses/web-beginner-en-TlhFi/0/1)或查看 Mozilla 开发者网络的参考和指南(https://developer.mozilla.org/en-US/docs/Web/CSS)。
现在我们进一步了解了 CSS,了解了它是如何样式化页面的;但是你可能会问,在浏览器终端中 CSS 需要做什么?好问题!让我们回顾一下 jQuery 和 JavaScript 的基础知识,这样可以看到 CSS 是如何同页面上的内容交互的。
- jQuery和JavaScript
JavaScript 和 jQuery 的演化历史要比 HTML 和 CSS 悠久得多,一部分原因是 JavaScript 的开发在很长一段时间里没有一整套的标准。从某种意义上来讲,JavaScript 是(在某种程度上仍然是)网站版图上一片荒芜的西部风光。
JavaScript 不是标记语言,而是一门脚本语言。因为 Python 也是一门脚本语言,所以你可以将一些已经学过的东西——函数、对象、类、方法——应用到对 JavaScript 的理解中去。同 Python 一样,有其他的库和包帮助你编写清晰、简单和高效的 JavaScript 代码,以便于浏览器和人们理解。
jQuery(https://jquery.com/)是一个 JavaScript 库,很多大型的网站使用它以期让 JavaScript 更易读、编写更简单,同时仍然允许浏览器(和它们不同的 JavaScript 引擎)来解析脚本。
自从 jQuery 被开发之后,JavaScript 和 CSS 的关系便更加紧密了,并且很多新的 JavaScript 框架都基于这个面向对象的方法。如果一个站点正在运行 jQuery,使用 CSS 标识符同页面上的元素交互很简单。假如我们想要从#WeAreFairphone 页面(图 11-12)上正在查看的 contentblock 类抓取内容,通过 JavaScript 控制台该如何实现呢?
图 11-12:jQuery 控制台
由于网站正在运行 jQuery,直接在控制台标签第一行中输入下面的代码:
$('div.contentblock');
敲击回车键,控制台会响应那个元素。点击控制台中的响应,你会看到子元素,以及该元素的子元素。可以同一些基本的 jQuery(例如,$(elem);)一起使用 CSS 选择器,来选择其他页面上的元素。使用 $ 和括号会告诉 jQuery 我们正在寻找一个与括号中的字符串传递的选择器相匹配的元素。
你能使用控制台来选择 ID 为 weAreFairphone 的 div 吗?你是否只能选择页面上的锚标记(a)?在控制台中尝试一下。命令行和 jQuery 提供了一个简单的方式来使用 CSS 选择器或标签名称同页面上实际的元素交互,并从这些元素中拉取内容。但是这与 Python 有什么关系呢?
因为 jQuery 改变了人们对 CSS 选择器用处的看法,Python 抓取库现在使用这些选择器来遍历和寻找网页中的元素。就像你可以在浏览器控制台中使用简单的 jQuery 选择器,你也可以在 Python 抓取器代码中使用它。如果想学习更多的 jQuery 知识,建议你访问 jQuery 学习中心(https://learn.jquery.com/),或在 Codecademy(http://www.codecademy.com/en/tracks/jquery)或 Code School(https://www.codeschool.com/courses/try-jquery)上学习课程。
如果碰到一个没有使用 jQuery 的网站,那么 jQuery 在你的控制台中就不会工作。为了只使用 JavaScript 通过类来选择元素,运行:
document.getElementsByClassName('contentblock');
你应该看到相同的 div,并且能够通过相同的方式在控制台中浏览。现在你大致知道了可以利用的工具,所以让我们更仔细地看一下如何确定抓取页面中感兴趣内容的最佳方式。首先,我们会学习如何研究页面中所有的部分。
11.2.4 页面的深入分析
一个开发 Web 抓取器的好方式是先在浏览器中分析内容。首先选择你最感兴趣的内容,并且在浏览器检视或 DOM 标签中观察。数据是如何组成的?哪里是父节点?内容包含在许多元素中,还是少量元素中?
在开始抓取一个页面之前,通过查看内容的限制信息和站点的 robots.txt 文件,来查看自己是否有权利抓取这个页面。你可以输入域名,随后输入 / robots.txt 找到这个文件(例如,http://oreilly.com/robots.txt)。
之后移向网络 / 时间线标签(见图 11-6)。页面的第一次加载看起来是什么样子?页面加载中是否使用了 JSON ?如果是的话,文件看起来什么样子?是否大部分内容在初次请求之后加载?所有的这些答案会帮助你确定要使用哪种类型的抓取器,以及抓取该页面有多困难。
然后,打开控制台标签。尝试使用你检视得到的信息,同包含重要内容的元素交互。对于这个内容,编写一个 jQuery 选择器有多简单?在整个域名下,你的选择器有多可靠?你是否可以打开一个类似的页面,使用该选择器,并得到类似的结果?
不能使用 Python 工具正确解析的网页少之又少。我们会教给你一些技巧,来应对混乱的网页、内联 JavaScript、格式化糟糕的选择器,以及你能在万维网的代码中发现的所有糟糕的选择,同时还会给出一些最佳实践。首先,看看加载和读取网页。
11.3 得到页面:如何通过互联网发出请求
网页抓取器的第一步是……连接到互联网。让我们温习一下连接互联网的一些基础知识。
当你打开浏览器,输入一个站点名称或者搜索词,并且敲击回车键的时候,你正在发出一个请求。大多数情况下,这是一个 HTTP(超文本传输协议)请求(或者 HTTPS——安全版本的 HTTP 协议)。你很可能在创建一个 GET 请求,这是在互联网上使用的众多请求方法之一(https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol#Request_methods)。浏览器会处理这些请求,同时解析输入,以确定你是在请求一个网站还是一个搜索词。根据该分析结果,浏览器会返回搜索结果或你请求的网站。
让我们看一下用于请求 URL 的 Python 内置库:urllib(https://docs.python.org/2/library/urllib.html)和 urllib2(https://docs.python.org/2/library/urllib2.html)。这是用于 URL 请求的两个 Python 标准库。使用 urllib2 是个好的想法,但是在 urllib 中有几个很有用的方法。让我们来看一下:
import urllibimport urllib2google = urllib2.urlopen('http://google.com') ➊google = google.read() ➋print google[:200] ➌url = 'http://google.com?q='url_with_query = url + urllib.quote_plus('python web scraping') ➍web_search = urllib2.urlopen(url_with_query)web_search = web_search.read()print web_search[:200]
❶ 使用 urlopen 方法来开始请求。这会返回一个缓冲区,在这里你可以读取网页的内容。
❷ 读取整个页面的内容到 google 变量中。
❸ 打印前 200 个字符,这样可以看到页面的开端。
❹ 使用 quote_plus 方法来用加号转义字符串。这在处理网站的查询字符串时很有用——我们想要使用 Google 搜索网页结果,同时我们知道 Google 希望得到一个在单词之间使用加号连接的查询字符串。
看到了吗?访问 URL 或服务(例如 Google 搜索)、得到响应,并读取响应都非常简单。 urllib 和 urllib2 都有其他请求方法,也能够添加头部信息、发送基本认证,以及组装更加复杂的请求。
根据请求的复杂度,你还可以使用 requests 库(http://docs.python-requests.org/en/latest/)。 requests 使用 urllib 和 urllib2,让复杂的请求更容易格式化和发送。如果你需要格式化一个复杂的文件 post 请求(http://docs.python-requests.org/en/latest/user/quickstart/#more-complicated-post-requests),或查看 session(http://docs.python-requests.org/en/latest/user/quickstart/#cookies)中还存留了什么 cookie,或者检查响应状态码(http://docs.python-requests.org/en/latest/user/quickstart/#response-status-codes),requests 是一个很棒的选择。
cookies或其他认证方法的页面。你可以使用urllib2、urllib或requests库,同请求一起发送这些特殊字段。
让我们看一些 requests 工具的实际使用:
import requestsgoogle = requests.get('http://google.com') ➊print google.status_code ➋print google.content[:200]print google.headers ➌print google.cookies.items() ➍
❶ 调用 requests 库的 get 方法发送一个 GET 请求到 URL 地址。
❷ 调用 status_code 属性来确保得到了 200 响应(正确地完成请求)。如果没有得到 200,可以以不同方式执行脚本逻辑。
❸ 检查响应的 headers 属性来看 Google 返回了什么头部。可以看到 headers 属性是一个字典。
❹ 使用 cookies 属性读取 Google 在响应中发送的 cookie,并且在返回的字典上调用 items 方法来展示键 / 值对。
使用 requests 库,可以基于响应和它的属性做不同的抉择。它很容易使用,并且有很棒的文档。无论使用 urllib 还是 requests,你可以用简单的几行 Python 代码创建简单和复杂的请求。现在你了解了请求网页的基本知识,可以开始解析响应了。首先学习 Beautiful Soup(https://www.crummy.com/software/BeautifulSoup/bs4/doc/),一个简单的 Python 网页解析器。
11.4 使用Beautiful Soup读取网页
Beautiful Soup 是最流行、最简单的用于网页抓取的 Python 库之一。对于不同的需求,在网页抓取中它可能提供了你所需的一切。它很简单、直接,并且很容易学习。让我们看一下如何使用 Beautiful Soup 解析页面。首先,使用 pip 安装这个库(使用 beautifulsoup4,因为早期的版本已经不再支持和开发了):
pip install beautifulsoup4
让我们重新看一下在早些时候检查过的一个简单的页面,即 Enough 项目的 Take Action 页面(http://www.enoughproject.org/take_action)。我们想要看一下是否可以正确地解析所有的活动调用,并且保存它们。下面是导入页面到 Beautiful Soup 中的实例,这样我们可以开始读取它:
from bs4 import BeautifulSoup ➊import requestspage = requests.get('http://www.enoughproject.org/take_action') ➋bs = BeautifulSoup(page.content) ➌print bs.titleprint bs.find_all('a') ➍print bs.find_all('p')
❶ 首先,直接从 beautifulsoup4 库导入解析器。
❷ 使用 requests 库来抓取页面上的内容,这行代码将响应(和它的内容)赋值给 page 变量。
❸ 为了开始使用 Beautiful Soup 解析,这行代码传递页面内容到 BeautifulSoup 类。可以使用 content 属性获取响应的源页面。
❹ 一旦解析了页面对象,可以使用它的属性和方法。这行代码让 Beautiful Soup 找到页面中所有的 a 标签(或链接)。
可以打开一个页面,读取响应到一个 Beautiful Soup 对象,并且使用这个对象的属性来查看标题、页面中所有的段落,以及页面上所有的链接。
我们已经学习了 HTML 中有关家族关系的知识,下面查看一下页面中的关系:
header_children = [c for c in bs.head.children] ➊print header_childrennavigation_bar = bs.find(id="globalNavigation") ➋for d in navigation_bar.descendants: ➌print dfor s in d.previous_siblings: ➍print s
❶ 使用列表生成式创建一个页面中头部的所有子元素的列表。通过将 Beautiful Soup 页面对象和 .head(调取页面的头部)以及 .children 联系在一起,可以查看所有包含在头部中的节点。如果需要的话,可以解析头部的元内容,包括页面描述。
❷ 如果使用开发者工具观察页面,你会看到导航栏使用一个 CSS 选择器 ID globalNavigation 定义。这行代码使用页面对象的 find 方法,传递一个 ID,并且定位导航栏。
❸ 使用导航栏的 descendants 方法遍历导航栏的后继。
❹ 到导航栏的最后一个后继,这行代码使用 .previous_sibling 来遍历导航元素的邻居。
家族树让我们通过 Beautiful Soup 库 page 类中的内置属性和方法导航。正如可以从头部和导航栏示例中看到的那样,从页面中选择一个区域,并遍历孩子、后代或邻居是很容易的。Beautiful Soup 的语法非常简单,并且将元素和它们的属性链式绑定到一起(像 .head.children)。对此有了了解之后,让我们专注于页面的主要部分,看一下是否可以拉取一些可能感兴趣的内容。
如果通过开发者工具观察页面,会注意到一些事情。首先,看起来每一个动作对象都位于一个 views-row div 中。这些 divs 有许多不同的类,但是它们都有一个 views-row 类。这是开始解析的好起点。标题位于一个 h2 标签中,同时链接也在该 h2 标签中,位于一个锚标签中。对于动作的调用位于 views-row div 的子 div 中的段落里面。现在可以使用 Beautiful Soup 解析页面。
首先,我们想要利用已掌握的 Beautiful Soup 知识,以及对页面结构和导航结构方式的理解,找到内容。下面是完成这件事的代码:
from bs4 import BeautifulSoupimport requestspage = requests.get('http://www.enoughproject.org/take_action')bs = BeautifulSoup(page.content)ta_divs = bs.find_all("div", class_="views-row") ➊print len(ta_divs) ➋for ta in ta_divs:title = ta.h2 ➌link = ta.aabout = ta.find_all('p') ➍print title, link, about
❶ 使用 Beautiful Soup 找到并返回类中包含字符串 views-row 的所有 divs。
❷ 打印来检查数字是否是可以在网站上看到的故事行数,预示着正确地匹配了行数据。
❸ 遍历这些行数据,并基于页面的研究获取想要的标签。标题位于一个 h2 标签中,并且是行中唯一的 h2 标签。链接是第一个锚标签。
❹ 因为不确定在每行数据中有多少个段落标签,所以匹配所有的段落标签来得到文本。由于使用了 .find_all 方法,Beautiful Soup 返回一个列表,而不是第一个匹配的元素。
你应该会看到类似于下面的输出:
<h2><a href="https://ssl1.americanprogress.org/o/507/p/dia/action3/common/public/?action_KEY=391">South Sudan: On August 17th, Implement "Plan B" </a></h2> <ahref="https://ssl1.americanprogress.org/o/507/p/dia/action3/common/public/?action_KEY=391">South Sudan: On August 17th, Implement "Plan B" </a>[<p>During President Obama's recent trip to Africa, the international communityset a deadline of August 17 for a peace deal to be signed by South Sudan'swarring parties....]
这些内容可能随着站点更新而改变,但是你应该会看到一个 h2 元素,之后是一个锚(a)元素,然后是每个节点段落的列表。当下的输出是混乱的,不仅因为我们正在使用一个 print,还因为 Beautiful Soup 打印了完整的元素和它的内容。相对于完整的元素,我们更想要关注于必需的部分,也就是标题文本、链接 hrefs 和段落文本。可以使用 Beautiful Soup 来仔细地查看这部分数据:
all_data = []for ta in ta_divs:data_dict = {}data_dict['title'] = ta.h2.get_text() ➊data_dict['link'] = ta.a.get('href') ➋data_dict['about'] = [p.get_text() for p in ta.find_all('p')] ➌all_data.append(data_dict)print all_data
❶ 使用 get_text 方法抽取所有来自 HTML 元素的字符串。这样会获得标题文本。
❷ 为了得到一个元素的属性,使用 get 方法。当看到 Foo,并想提取链接时,可以调用 .get("href") 来返回 href 值(即,foo.com)。
❸ 为了抽取段落文本,使用 get_text 方法,遍历 find_all 方法返回的段落。这行代码使用列表生成式来编译一个有着动作内容调用的字符串列表。
现在数据和输出呈现了一个更加有组织的格式。在变量 all_data 中,保存了一个所有数据的列表。现在每一个数据输入都和匹配键保存在其字典中。我们用一种整洁的方式,使用一些新的方法(get 和 get_text)从页面抓取了数据,并且数据现在存放在数据字典中。代码更加清晰和精确,可以通过添加辅助函数让它更加清晰(像第 8 章介绍的)。
除此之外,可以自动化脚本来检查是否有新的动作调用。如果保存数据到 SQLite,并且将其用于每月检查刚果的劳工实践,可以自动化报告。在每一个新报告中,可以抽取这些数据,并且对对抗冲突矿产和童工激起更多的兴趣。
Beautiful Soup 是一个易于使用的工具,并且其文档(https://www.crummy.com/software/BeautifulSoup/bs4/doc/)中介绍了很多其他可用方法的实例。这个库对于初学者来说很棒,并且有很多简单的函数;然而,跟一些其他的 Python 库相比,它太简单了。
由于 Beautiful Soup 的解析是基于正则表达式的,用在缺乏正确标签结构的破损网页上很有效。但是如果想要遍历更加复杂的页面,或者想要抓取器运行得更快并且快速地浏览页面,有很多更加高级的 Python 库可用。让我们看一下许多天才网页抓取器开发者最爱的库:lxml。
11.5 使用lxml读取网页
一个更高级的网页抓取器(其他的高级工具把它作为解析器来使用)是 lxml(http://lxml.de/)。它非常强大而快速,而且有很多很棒的特性,包括生成 HTML 和 XML 以及清洗编写糟糕的网页的能力。除此之外,它有很多用于遍历 DOM 和网页家族关系的工具。
安装
lxml
lxml有许多不同的 C 依赖,这使得安装它要比安装大多数 Python 库更复杂一点(http://lxml.de/installation.html)。对于 Windows 用户,可查看开源二进制构建版本的lxml(http://lxml.de/FAQ.html#where-are-the-binary-builds)。对于 Mac 用户,建议安装 Homebrew(http://brew.sh/),这样你可以使用brew install lxml安装它。有关高级安装的更多细节,请查看附录 D。
让我们快速地看一下要使用的主要 lxml 特性,先重写 Beautiful Soup 的代码来使用 lxml:
from lxml import htmlpage = html.parse('http://www.enoughproject.org/take_action') ➊root = page.getroot() ➋ta_divs = root.cssselect('div.views-row') ➌print ta_divsall_data = []for ta in ta_divs:data_dict = {}title = ta.cssselect('h2')[0] ➍data_dict['title'] = title.text_content() ➎data_dict['link'] = title.find('a').get('href') ➏data_dict['about'] = [p.text_content() for p in ta.cssselect('p')] ➐all_data.append(data_dict)print all_data
❶ 这里使用 lxml 的解析方法,它可以从一个文件名、一个打开的缓冲区或一个合法的 URL 解析。它返回一个 etree 对象。
❷ 因为 etree 对象的方法和属性比 HTML 元素对象少很多,所以这行代码访问根(页面和 HTML 的顶部)元素。根包含所有可能的能够访问的主干(孩子)和细枝(后代)。从根可以向下解析每一个链接或者段落,并且可以返回整个页面的 head 和 body 标签。
❸ 使用根元素,这行代码找到所有的类名称为 views-row 的 div。它使用 cssselect 方法和一个 CSS 选择器字符串,返回一个匹配元素的列表。
❹ 为了抓取标题,使用 cssselect 方法找到 h2 标签。这行代码选择了列表中的第一个元素。cssselect 返回一个所有匹配项的列表,但是我们只想要第一个匹配的元素。
❺ 同 Beautiful Soup 的 get_text 方法类似,text_content 为 lxml HTML 元素对象返回标签(和任何子标签)内的文本。
❻ 这里使用链式方法来从 title 元素中获得锚标签,并且拉取锚标签中的 href 属性。这只返回这一属性的值,类似于 Beautiful Soup 的 get 方法。
❼ 使用列表生成式来从 Take Action div 中的每一个段落中拉取文本,组成完整的文本。
你应该看到与我们使用 Beautiful Soup 时相同的提取数据。不同的是语法和页面加载的方式。Beautiful Soup 使用正则表达式把文档作为一个长字符串解析。lxml 使用 Python 和 C 库来识别页面结构,并且用更加面向对象的方式遍历它。lxml 查看所有标签的结构,(取决于你的计算机和安装它方式的不同)使用最快的方法解析树,并且在一个 etree 对象中返回数据。
我们可以使用 etree 对象本身,或者调用 getroot,这个函数会返回树最顶部的元素——通常为 html。有了这个元素,可以使用很多不同的方法和属性读取和解析页面剩余的部分。我们的解决方案强调了一点:使用 cssselect 方法。这个方法使用 CSS 选择器字符串(类似于 jQuery 示例),并且使用这些字符串来识别 DOM 元素。
lxml 也有 find 和 findall 方法。find 和 cssselect 之间有什么主要区别呢?来看一些示例:
print root.find('div') ➊print root.find('head')print root.find('head').findall('script') ➋print root.cssselect('div') ➌print root.cssselect('head script') ➍
❶ 在根元素上使用 find 方法来找到 div,这返回空。从浏览器的检视来看,我们知道页面充满了 divs !
❷ 使用 find 方法查看头部标签,使用 findall 方法在头部定位脚本元素。
❸ 使用 cssselect 取代 find 正确地定位文档中所有的 divs,它们作为一个大的列表返回。
❹ 使用 cssselect,通过嵌套 CSS 选择器在头部定位脚本标签。使用 head script 返回与从根对象链式调用 find 命令相同的列表。
所以,find 和 cssselect 的操作方式有很大的不同。find 利用 DOM 来遍历元素,并基于祖先和家族关系找到它们,而 cssselect 方法利用 CSS 选择器来寻找页面中所有可能的匹配,或者元素的后继,非常类似于 jQuery。
find或cssselect可能更加有用。如果页面的 CSS 类、ID 和其他标识符组织得良好,cssselect是一个非常棒的选择。但是如果页面没有组织或不使用这些标识符,遍历 DOM 可以帮助你通过家族关系确定内容。
我们想要探索其他有用的 lxml 方法。作为一名开发者,随着不断学习和成长,你可能想要通过 emoji 表情表达进程。出于这个原因,让我们编写一个快速的 emoji 图表解析器(http://www.emoji-cheat-sheet.com/)来保存一个最新的 emoji 表情列表,你可以在 Basecamp、GitHub 和很多其他的技术相关网站上使用它们。下面是做这件事的代码:
from lxml import htmlimport requestsresp = requests.get('http://www.emoji-cheat-sheet.com/')page = html.document_fromstring(resp.content) ➊body = page.find('body')top_header = body.find('h2') ➋print top_header.textheaders_and_lists = [sib for sib in top_header.itersiblings()] ➌print headers_and_listsproper_headers_and_lists = [s for s in top_header.itersiblings() ifs.tag in ['ul', 'h2', 'h3']] ➍print proper_headers_and_lists
❶ 这段代码使用 requests 库拉取 HTML 文档的主体,之后使用 html 模块的 document_fromstring 方法解析数据为一个 HTML 元素。
❷ 通过查看页面结构,可以看到这是一系列头部的匹配列表。这行代码定位第一个头部,这样我们可以使用家族关系来寻找其他有用的部分。
❸ 这行代码使用列表生成式和 itersiblings 方法(返回一个迭代器)来查看所有的邻居。
❹ 上一个 print 展示了初始的 itersibling 列表生成式返回了远超我们需求的数据,包括一些页面下方带有 div 和 script 元素的部分。使用页面检视,我们确定想要的标签只是 ul、h2 和 h3。这行代码使用列表生成式和一个 if 确保只返回目标内容。
itersiblings 方法和 tag 属性帮助我们轻松地定位想要选择和解析的内容。在这个例子中,我们没有使用任何 CSS 选择器。我们知道,代码不会因为添加一个新部分而损坏,只要页面继续在头部和列表标签中保存内容。
除了 itersiblings 之外,lxml 对象可以迭代孩子、后继和祖先。使用这些方法遍历 DOM,是熟悉页面组织方式和编写持久代码的很好的方式。你同样可以使用家族关系来编写有意义的 XPath——一种结构化的模式,用于基于 XML 的文档(像 HTML)。尽管 XPath 不是解析网页最简单的方式,但它是一种快速、高效且极度简单的方式。
一个XPath案例
虽然使用 CSS 选择器是一种找到页面上元素和内容的简单方式,也建议你学习和使用 XPath(https://en.wikipedia.org/wiki/XPath)。XPath 是一个标记模式选择器,组合了 CSS 选择器和遍历 DOM 的能力。理解 XPath 是学习网页抓取和网站结构的很好的方式。有了 XPath,你可以访问仅仅使用 CSS 选择器不容易阅读的内容。
为了练习 XPath,你只需要查看浏览器的工具。许多浏览器都能够查看和复制 DOM 中的 XPath 元素。微软也有一篇关于 XPath 的很棒的文章(https://msdn.microsoft.com/en-us/library/ms256086(v=vs.110).aspx.aspx)),而且 Mozilla 开发者网络上有很多很棒的工具和示例(https://developer.mozilla.org/en-US/docs/Web/XPath),供你更深入地学习 XPath。
XPath 遵循特定的语法来定义元素的类型、在 DOM 中的位置,以及可能拥有什么属性。表 11-2 回顾了可以在网页抓取代码中使用的一些 XPath 语法模式。
表11-2:XPath语法
| 表达式 | 描述 | 示例 |
|---|---|---|
//node_name
|
在文档中选择所有匹配 node_name 的节点
|
//div(选择文档中的所有 div 对象)
|
/node_name
|
选择当前或前序元素中所有匹配 node_name 的节点
|
//div/ul(选择所有 div 内的 ul 对象)
|
@attr
| 选择一个元素的属性 |
//div/ul/@class(选择所有 div 中 ul 对象的 class 属性)
|
../
| 选择父元素 |
//ul/../(选择所有 ul 元素的父元素)
|
[@attr="attr_value"]
| 选择有特定属性值的元素 |
//div[@id="mylists"](选择 ID 值为“mylists”的 div)
|
text()
| 从节点或元素中选择文本 |
//div[@id="mylists"]/ul/li/text()(选择 ID 为“mylists”的 div 中的列表中元素的文本)
|
contains(@attr, "value")
| 选择属性具有特定值的元素 |
//div[contains(@id, "list")](选择所有 ID 中有“list”的 div)
|
*
| 通配符 |
//div/ul/li/*(选择所有的 div 中 ul 中列表对象的后继)
|
[1,2,3…]、[last()] 或 [first()]
| 根据在节点中出现的顺序选择元素 |
//div/ul/li[3](选择所有 div 中 ul 中的第三个列表对象)
|
还有更多的表达式,但是这些已经足够我们开始了。让我们使用 XPath 和本章早些时候创建的非常漂亮的 HTML 页面,研究如何解析 HTML 元素间的家族关系。为了跟随我们,从本书的代码仓库(https://github.com/jackiekazil/datawrangling)中将其拉取到你的浏览器中(文件:awesome_page.html)。
假设我们想要在页脚部分选择链接。通过使用“检视元素”选项(见图 11-13),可以看到底部栏展示了一个元素列表和它们的祖先。锚链接位于 html 标签内的 body 标签内的 footer 内的一个带有 CSS id 的 div 内的 ul 内的 li 标签里(喔!我觉得快要喘不过来气了!)。
图 11-13:找到页面的元素
怎样编写 XPath 来选择它呢?实际上,有很多种方式。让我们从一个相当明显的方式开始,使用带有 CSS id 的 div 来编写 XPath。用已学到的语法选择 div:
'//div[@id="bottom_nav"]'
可以使用浏览器的 JavaScript 控制台测试这段代码。为了在控制台中测试 XPath,直接将它放在 $x(); 中,这是一个 jQuery 控制台的实现,用于使用 XPath 浏览页面。让我们在控制台中查看一下(见图 11-14)。1
1如果你想要在一个不使用 jQuery 的站点上使用 XPath,需要使用 Mozilla 在文档中描述的不同语法(https://developer.mozilla.org/en-US/docs/Introduction_to_using_XPath_in_JavaScript)。对于这个元素,语法应该是 document.evaluate('//div[@id="bottom_nav"]', document)。
图 11-14:使用控制台编写 XPath
我们有了合法的 XPath 来选择导航栏,因为控制台返回了一个对象(类似于 jQuery 选择器)。但是我们真正想要的是链接。让我们来看一下怎样从这个 div 移到这些链接。我们知道它们是后继,所以编写一个家族关系。
'//div[@id="bottom_nav"]/ul/li/a'
这里我们想要任何具有 id bottom_nav 的 divs,其中包含一个无序列表,然后是匹配项中的列表对象,再然后是这些对象中的锚标签。让我们尝试在控制台中运行它(图 11-15)。
图 11-15:XPath 子元素
可以从控制台的输出看到已经选择了这三个链接。现在,我们只想提取网页地址本身。我们知道每一个锚标签有一个 href 属性。让我们使用 XPath 来为这些属性编写一个选择器:
'//div[@id="bottom_nav"]/ul/li/a/@href'
当在控制台中运行这个选择器时,可以看到我们已经正确地选择了底部链接中的网页地址(见图 11-16)。
图 11-16:寻找 XPath 属性
了解页面结构可以帮助我们得到很难访问的内容,我们可以使用 XPath 表达式取而代之。
contains模式,而不是=。元素可以拥有多个类,而 XPath 会假定包含了整个类字符串;使用contains将帮助你找到任何包含这个子串的元素。
找到你感兴趣的元素的父元素可能会很有用。假如你对页面上的一个对象列表感兴趣,并且你可以使用 CSS 类或列表中包含的文本轻松地定位一个或多个列表对象。你可以使用这些信息来构建一个 XPath 选择器,定位该元素,之后寻找父元素,让你能够访问整个列表。12.2.1 节探索这些 XPath 选择器类型,因为 Scrapy 利用 XPath 进行快速解析。
使用 XPath 的一个原因是,你通过 CSS 选择器找到的 CSS 类可能并不总能正确地选择元素,特别是使用了不同的驱动处理页面时(例如,Selenium 和许多浏览器)。XPath 天生更加明确,因而是正确解析网页的一种更加可靠的方式。
如果你已经抓取了一个站点很长时间,并且想要复用相同的代码,XPath 不太可能会由于小段代码的改变和站点的开发而崩溃。更常见的作法是重写一些 CSS 类或样式,而不是修改整个站点和页面结构。因此,XPath 比使用 CSS 更安全(尽管不是万无一失)。
现在你已经学习了一些 XPath 知识,可以尝试使用 XPath 语法重新编写 emoji 处理器,正确地存储每个部分中所有的 emoji 和头部信息。代码类似下面这样。
from lxml import htmlpage = html.parse('http://www.emoji-cheat-sheet.com/')proper_headers = page.xpath('//h2|//h3') ➊proper_lists = page.xpath('//ul') ➋all_emoji = []for header, list_cont in zip(proper_headers, proper_lists): ➌section = header.textfor li in list_cont.getchildren(): ➍emoji_dict = {}spans = li.xpath('div/span') ➎if len(spans):link = spans[0].get('data-src') ➏if link:emoji_dict['emoji_link'] = li.base_url + link ➐else:emoji_dict['emoji_link'] = Noneemoji_dict['emoji_handle'] = spans[1].text_content() ➑else:emoji_dict['emoji_link'] = Noneemoji_dict['emoji_handle'] = li.xpath('div')[0].text_content() ➒emoji_dict['section'] = sectionall_emoji.append(emoji_dict)print all_emoji
❶ 这行代码寻找与 emoji 内容相关的头部信息。它使用 XPath 抓取所有的 h2 和 h3 元素。
❷ 每一个定位到的头部有一个 ul 元素来匹配。这行代码在整个文档中收集所有的 ul 元素。
❸ 使用 zip 方法来打包头部和与之适合的列表,这返回一个元组列表。这行代码之后解包这些元组,使用一个 for 循环拉取每一个部分(头部与列表内容)到独立的变量中。
❹ 这段代码遍历 ul 元素的子元素(li 元素保存着 emoji 表情信息)。
❺ 通过页面检视,我们知道大多数的 li 元素有一个 div,其中包含两个 span 元素。这些 span 包括 emoji 表情的图片链接,以及用来唤起 emoji 表情的文字。这行代码使用 XPath 的 div/span 返回每个子 div 元素下所有的 span 元素。
❻ 为了找到每个元素的链接,这行代码调用第一个 span 的 data-src 属性。如果 link 变量为 None,代码会在我们的数据字典中设置 emoji_link 属性为 None。
❼ 因为 data-src 保存着一个相对 URL,所以这行代码使用 base_url 属性来创建一个完整的绝对 URL。
❽ 为了得到句柄(handle)或唤起 emoji 表情所需的文字,这行代码抓取第二个 span 的文本。不同于链接的逻辑,我们不需要测试这是否存在,因为每一个 emoji 都拥有一个句柄。
❾ 对于包括 Basecamp 声效的页面,对于每一个列表对象,存在一个 div(你可以通过使用浏览器的开发者工具检视页面,轻松地找到它)。这行代码选择 div,并且抓取其中的文本内容。因为这行代码在 else 代码块中,所以我们知道这些只是声音文件,因为它们不使用 spans。
通过重写 emoji 代码来使用 XPath 关系,我们发现标签最后的代码块是声音,并且其中的数据以不同的方式存储。相对于在 span 中保存一个链接,这里只有一个 div 包含唤醒声音的文本。如果只想要 emoji 链接,可以跳过添加它们到列表对象的迭代。取决于你感兴趣的数据,代码会有很大相同,但是你总是可以轻松地利用 if…else 逻辑来确定需要的内容。
通过不超过 30 行的代码,我们创建了一个抓取器来请求页面,通过 XPath 遍历 DOM 关系解析它,同时使用合适的属性或文本内容抓取出需要的内容。这段代码具有很好的扩展性,如果页面的作者添加了更多的数据节,只要页面结构没有大幅度改变,解析器会继续从页面拉取内容,并且我们会拿到不计其数的 emoji 表情!
还有许多其他有用的 lxml 函数。表 11-3 总结了其中一些以及它们的使用场景。
表11-3:lxml特性
| 方法或属性名称 | 描述 | 文档 |
|---|---|---|
clean_html
| 一个用来清理糟糕格式页面的函数,这样它们可以被正确解析 | http://lxml.de/lxmlhtml.html#cleaning-up-html |
iterlinks
| 一个用来访问页面上每一个锚标签的迭代器 | http://lxml.de/lxmlhtml.html#working-with-links |
[x.tag for x in root]
|
所有的 etree 元素可以作为简单的迭代器使用,支持子元素的遍历
| http://lxml.de/api.html#iteration |
.nsmap
| 提供对命名空间的简单访问,如果你愿意使用它们的话 | http://lxml.de/tutorial.html#namespaces |
现在,当研究页面上的结构化数据和解决如何使用 lxml、Beautiful Soup 和 XPath 从页面中提取内容时,你应该感到很自信。下一章会继续研究其他可以用来做不同类型抓取的库,像基于浏览器的解析和爬虫。
11.6 小结
你已经学习了许多关于网页抓取的知识。在编写不同格式的抓取器时,你应该感到很自信。你已清楚怎样编写 jQuery、CSS 和 XPath 选择器,以及如何轻松地使用浏览器和 Python 匹配内容。
在使用开发者工具分析一个网页是如何构建的时候,你同样会感到很自在。你已经磨练了 CSS 和 JavaScript 技能,学习了如何编写一个合法的 XPath 来与 DOM 树直接交互。
表 11-4 列出了本章介绍的新概念和库。
表11-4:新的Python和编程概念与库
| 概念/库 | 目的 |
|---|---|
| robots.txt 文件使用、版权和商标研究 | 通过站点的 robots.txt 文件、服务条款或页面上发布的其他法律声明,你可以确定是否可以合法和符合道德地抓取站点内容 |
| 开发者工具使用:检视 /DOM | 用于研究内容在页面上的位置,以及如何以最佳方式使用页面层次和 CSS 规则来找到它 |
| 开发者工具使用:网络 | 用于研究为了完全加载页面发起了哪些调用。这其中的一些请求可能指向 API,或其他资源,以便你轻松获取数据。了解页面如何加载可以帮助你确定是使用一个简单的抓取器还是一个基于浏览器的更复杂的抓取器 |
| 开发者工具使用:JavaScript 控制台 | 用于研究如何通过其 CSS 或 XPath 选择器同页面上的元素交互 |
urllib 和 urllib2 标准库
| 帮助你创建简单的 HTTP 请求来访问一个网页,并通过 Python 标准库获取内容 |
requests 库
|
帮助你更容易地创建复杂的页面请求,特别是那些需要额外的头部、复杂的 POST 数据或请求认证
|
BeautifulSoup 库
| 让你轻松读取和解析页面。对于严重破损的页面和初始的网页抓取很有用 |
lxml 库
| 让你更轻松地使用类似 XPath 语法的 DOM 层次结构和工具解析页面 |
| XPath 使用 | 使你能够使用正则表达式和 XPath 语法编写模式和匹配,快速地找到和解析页面内容 |
在下一章,你会学习更多从网页抓取数据的方式。
