第 6 章 使用朴素贝叶斯进行社会媒体挖掘
不论是书、历史文档、社会媒体、电子邮件还是其他以文字为主的通信方式,都包含大量信息。从文本数据集抽取特征,用于分类不是件容易事。然而,人们还是总结出了文本挖掘的通用方法。
本章介绍如何用强大却出奇简单的朴素贝叶斯算法消除社会媒体用语的歧义。朴素贝叶斯算法在计算用于分类的概率时,为简化计算,假定各特征之间是相互独立的,因此名字中含有朴素二字。它稍经扩展就能用于对其他类型数据集进行分类,且不依赖于数值特征。本章创建的模型在多种数据集上表现还不错,可作为很多文本挖掘研究的基准。
本章主要涉及如下内容。
用社交网络的API下载数据
用于处理文本的转换器
朴素贝叶斯分类器
用JSON保存和加载数据集
用NLTK库从文本中抽取特征
用F值评估分类效果
6.1 消歧
文本通常被称为无结构格式,虽然它包含很多信息,但是却没有标题、特定格式,句法松散,以及其他问题,导致难以从中提取有用信息。数据间联系紧密,行文中经常相互提及,交叉引用现象也很常见——从这种格式中提取信息难度很大!
我们通过比较书中的信息和大型数据库中的信息,来看下两者都有哪些方面的不同。书中有角色、主题、场所等大量信息。然而,只有去读书,并且光读还不行,更重要的是理解后才能获得书中的信息。而位于服务器数据库的数据,每一列都有名字,都有指定的数据类型。所有的信息都在数据库中,解释起来很容易。描述数据类型、含义的信息叫作元数据,文本中缺乏这类数据。书中的目录和索引虽含有部分元数据,但是比起数据库对于数据精确的定义和描述,这点元数据实在微不足道。
文本挖掘的一个难点来自于歧义,消除歧义常被简称为消歧。当人们使用bank1这个词时,他透露的是金融相关的信息还是环境相关的(比如河岸)?在很多情况下,对我们自己来说,消除歧义比较容易(有时也不简单),但是对计算机来说难度要大得多。
1在英语中,bank既可以指银行,也可以指河岸。——译者注
本章将探讨如何区别Twitter消息中Python的意思。Twitter网站上的一条消息叫作tweet,它最多不能超过140个字符。这也就表明上下文信息较少。此外,没有多少元数据,虽然“#”号经常用来表示消息的主题。
当人们提及Python时,他们谈论的可能是:
编程语言Python
经典喜剧剧团Monty Python2
蟒蛇
鞋子品牌Python
2编程语言Python的名字正是来自于这个英国喜剧剧团的名字,Guido van Rossum很喜欢该剧团的演出,于是把他创立的编程语言命名为Python。——译者注
可能还有很多其他东西也叫Python。我们实验的目的是根据消息的内容,判断消息中的Python是不是指编程语言。
6.1.1 从社交网站下载数据
接下来,从Twitter网站下载一些语料,从中剔除垃圾信息后,用于分类任务。Twitter提供了从他们服务器采集信息的强大API,小规模使用免费,但如果你打算将Twitter数据用于商业用途,请了解下相关规定。
首先,你需要一个Twitter账号(免费)。如果没有的话,请访问http://twitter.com进行注册。
每分钟的请求数不能超过Twitter所规定的上限。写作本书时,上限为每小时180次。这个规定不好遵照执行,因此,强烈建议使用现成的库与Twitter的API进行通信。
访问Twitter数据时需要提供密钥。打开http://twitter.com,登录Twitter。
登录后,访问https://apps.twitter.com/,点击Create New App(创建新应用)。
指定新应用的名称,填好描述及要在哪个网站中使用。如果不打算在网站中使用,请在Website文本框中随意输入些内容,确保提交时表单能通过验证。Callback URL文本框空着不填——我们用不到。在下面的开发者协议处选中Yes, I agree前面的复选框(如果你确实同意),点击Create your Twitter application。
创建新应用后,先别急着关掉当前页面——后面会用到页面上的access keys(访问密钥)。接下来,需要找一个与Twitter通信的Python第三方库。选择有很多,我喜欢用Twitter官方提供的twitter库。
如果你习惯用
pip安装第三方包,可以使用pip3 install twitter安装
创建新的IPython笔记本文件来编写下载Twitter消息的代码。本章将创建几个不同的笔记本文件,用于不同的处理任务,所以最好是新建一个文件夹,把它们放到一起。第一个笔记本文件ch6_get_twitter专门用来下载新的Twitter语料。
首先,导入twitter库,设置授权令牌。刚才没让你关闭的那一页的Keys and Access Tokens (密钥和访问令牌)选项卡下,有consumer key(用户密钥)和consumer secret(请求令牌)。点击在同一页的Create my access token(创建我的访问令牌)按钮,获取访问令牌。用你得到的密钥和令牌替换下面代码中的占位符。
import twitterconsumer_key = "<Your Consumer Key Here>"consumer_secret = "<Your Consumer Secret Here>"access_token = "<Your Access Token Here>"access_token_secret = "<Your Access Token Secret Here>"authorization = twitter.OAuth(access_token, access_token_secret,consumer_key, consumer_secret)
我们将用twitter库提供的搜索函数(search)查找包含单词“Python”的消息。创建阅读器对象,提供授权信息连接到Twitter,然后使用阅读器对象进行搜索。在笔记本文件中,指定消息的存储位置。
import osoutput_filename = os.path.join(os.path.expanduser("~"),"Data", "twitter", "python_tweets.json")
保存数据时要用到json库。
import json
接着,创建用来从Twitter网站读取数据的对象,指定授权信息,需要用到前面创建的授权对象。
t = twitter.Twitter(auth=authorization)
打开输出文件,等待写入数据,写入模式指定为“a”,这样每次在文件末尾追加新数据。使用建立好的连接,搜索单词“Python”,对于search方法返回的数据,我们只需要“statuses”部分。下面代码获取到Twitter消息,使用json库的dump函数将其转换为字符串形式后,写入到输出文件中。写完每条消息后,再写一行空行,便于把每条消息区分开来。
with open(output_filename, 'a') as output_file:search_results = t.search.tweets(q="python", count=100)['statuses']for tweet in search_results:if 'text' in tweet:output_file.write(json.dumps(tweet))output_file.write("\n\n")
上述循环中,还检测了消息是否包括“text”键。并不是Twitter返回的所有对象都是消息(有些可能是用来删除消息或其他内容的动作)。消息对象与其他对象的关键不同在于消息对象中含有键“text”,这也正是我们用if语句进行检测的。
上述代码运行几分钟后,输出文件中就能有100条消息。
6.1.2 加载数据集并对其分类
完成消息采集后,我们拿到了原始数据集,对它里面的消息逐条标注后,才能用于分类任务。在笔记本文件中创建一个表单,方便标注。
消息存储格式近似于JSON。JSON格式不会对数据强加过多用于表示结构的信息,可以直接用JavaScript(JSON名字也就是这么来的,JavaScript Object Notation,JavaScript对象表示法)语言读取。JSON定义了诸如数字、字符串、数组、字典等基本对象,适合存储包含非数值类型的数据。如果数据集全都是数值类型,为了节省空间和时间,最好使用类似于numpy矩阵这样的格式来存储。
我们的数据集格式和真正的JSON对象的关键区别在于,每两条消息之间有一行空行。这样做的目的是,防止新追加的消息和前面的消息混在一起(在真正的JSON格式中,追加数据没这么简单)。我们的数据集中,每两条用JSON字符串表示的消息之间有一行空行。
我们可以使用json库解析数据集,但是要先根据空行把读进来的文件拆分(split方法)成一个列表,得到真正的消息对象。
新建一个笔记本文件(我把它命名为ch6_label_twitter),指定数据集的名称。该名称即为上节指定的输出文件的名字。我们还指定用于存放每条消息所属类别的文件名。代码如下:
import osinput_filename = os.path.join(os.path.expanduser("~"), "Data","twitter", "python_tweets.json")labels_filename = os.path.join(os.path.expanduser("~"), "Data","twitter", "python_classes.json")
上面已经提到过,我们要使用json库,先来导入它。
import json
创建列表,用于存储从文件中读进来的每条消息。
tweets = []
遍历文件中的每一行数据。我们对不包含消息的空行(它们用于分隔消息)不感兴趣,因此,检测当前行(去除任意空白字符后的)长度是否为0。如果为0,忽略当前行,继续判断下一行。如果不为0,使用json.loads(将JSON字符串转换为Python对象)方法加载消息,将它添加到tweets列表中。代码如下:
with open(input_filename) as inf:for line in inf:if len(line.strip()) == 0:continuetweets.append(json.loads(line))
我们现在想知道一条消息是否和我们相关(在这里,相关表示指的是编程语言Python)。接下来,在笔记本文件中嵌入HTML代码,实现JavaScript和Python之间的通信,用网页形式展示消息,便于标注。
我们要实现以下功能,向用户(你)展示一条消息,要求用户输入类别:相关还是不相关。程序保存输入结果,继续展示下一条待标注的消息。
首先,创建用于存储类别(标注结果)的列表。不管消息是不是与编程语言Python相关,我们都保存它的类别,分类器从这两类数据中学习如何预测一条消息的类别。
我们还要检测是不是有部分消息已经标注过类别了,有的话就加载这些类别。如果你标注到一半,临时有事要关闭笔记本文件,有了该功能,再打开时,代码就会加载已有类别。一般来说,对于类似的任务,考虑如何保存中间结果很有必要。这样即使计算机中途死机,努力一个小时得来的工作成果也不至于全部丢失!代码如下:
labels = []if os.path.exists(labels_filename):with open(labels_filename) as inf:labels = json.load(inf)
接下来,创建一个简单的函数,用来返回下一条需要标注的消息。我们找到并返回第一条没有标注类别的消息即可。代码如下。
def get_next_tweet():return tweet_sample[len(labels)]['text']
接下来,在笔记本中创建JavaScript程序来收集输入。可以借助魔术方法(magic function)在笔记本中直接嵌入HTML和JavaScript代码等。在笔记本的新格子中输入如下代码。
%%javascript
这样就表示下面为JavaScript代码,因此,大括号就要登场了。别担心,我们很快就会再回到Python的。请注意下面JavaScript代码必须与魔术方法%%javascript在同一格子里。
从下面定义的第一个JavaScript函数,就能看到在笔记本中,实现JavaScript和Python之间的通信是多么容易。这个函数的功能是向labels列表(Python代码中)添加一条消息所属的类别。具体做法是先加载IPython内核(kernel)对象,再用它来执行Python命令。代码如下:
function set_label(label){var kernel = IPython.notebook.kernel;kernel.execute("labels.append(" + label + ")");load_next_tweet();}
函数最后调用load_next_tweet函数,加载下一条未标注的消息。load_next_tweet这个JavaScript函数内部执行Python代码的原理跟上面所讲的相同:用加载的IPython内核来执行Python命令(调用前面定义的get_next_tweet函数)。
然而,获取并展示消息有点困难,需要用到回调函数,返回数据时调用该函数。回调函数的定义方法超出了本书的范围。如果你对更高级的JavaScript/Python交互方法感兴趣,请参考IPython文档。
代码如下:
function load_next_tweet(){var code_input = "get_next_tweet()";var kernel = IPython.notebook.kernel;var callbacks = { 'iopub' : {'output' : handle_output}};kernel.execute(code_input, callbacks, {silent:false});}
回调函数叫作handle_output,下面就来创建它。当kernel.execute()调用的Python函数返回结果后,就会调用回调函数。如上所述,回调函数的详细内容不在本书讲解范围之列,我们这里用它来处理返回的纯文本格式数据,把这些数据置于表单的#tweet_text div中展示,我们随后会编写相关HTML代码。回调函数代码如下:
function handle_output(out){var res = out.content.data["text/plain"];$("div#tweet_text").html(res);}
HTML代码中,最外层是id为tweetbox的div,它里面包着id为tweet_text的div元素用于显示下一条待标注的消息。我们还创建文本框,捕获输入的按键(否则,笔记本程序将会捕获它,JavaScript也就无法获得用户的输入)。这样我们就可以用键盘来设置消息的类别为1或0,比起用鼠标点击按钮进行选择要快——假如我们至少需要标注100条消息。
运行JavaScript代码所在的格子,就会在页面中嵌入JavaScript代码,虽然在结果区域看不到任何变化。
接着,我们来使用另一个魔术方法%%html。毫无疑问,它是用来直接在笔记本中嵌入HTML代码。在新格子中输入如下代码。
%%html
接下来,在这个格子中输入HTML代码和几行JavaScript代码。首先,定义一个div元素,用来显示当前要标注的消息。我还添加了几行标注说明。接着,创建id为tweet_text的div元素,用来显示下一条待标注的消息。如前所述,我们还需要创建文本框用来捕获按键。代码如下:
<div name="tweetbox">Instructions: Click in textbox. Enter a 1 if the tweet isrelevant, enter 0 otherwise.<br>Tweet: <div id="tweet_text" value="text"></div><br><input type=text id="capture"></input><br></div>
先不要运行这个格子!
创建完表单后,我们来编写捕获键盘按键的JavaScript代码,这段脚本须写到上面HTML代码的后面,因为#tweet_text元素在HTML代码运行前在页面上还不存在。这里要用到jQuery库(IPython笔记本文件使用了该库,无需再次引入)的一个函数,当在#capture文本框元素上发生按键事件时,调用指定的函数。然而,请注意,这个格子使用的魔术方法是%%html,在这里面写JavaScript代码,需要将其放到标签中。
我们只关注按键0或1,因为消息只可能属于这两个类别。通过检测存储在e.which中的ASCII码值,就能确定到底是哪个键被按下了。如果用户按下0或1,我们把类别添加到labels列表中,然后清空文本框的值。代码如下:
<script>$("input#capture").keypress(function(e) {if(e.which == 48) {set_label(0);$("input#capture").val("");}else if (e.which == 49){set_label(1);$("input#capture").val("");}});
忽略其他按键。
下面是本章最后几行JavaScript代码(我向你保证),我们调用load_next_tweet()函数。设置第一条待标注的消息,闭合script标签。代码如下:
load_next_tweet();</script>
在笔记本中,运行该格子,页面上会出现HTML文本框,旁边就是第一条消息。点击文本框,如果该消息与我们相关(消息中的Python指的是编程语言),输入1;反之,输入0。完成后,加载下一条消息。输入类别,接着加载下一条。重复以上过程,直到标注完所有数据。
完成标注后,把所有的类别信息输出到前面定义好的类别文件中。
with open(labels_filename, 'w') as outf:json.dump(labels, outf)
即使没有完成标注,也可以运行上述代码,保存标注过的类别。再次运行笔记本将会加载你没有标注的消息,这样你就能继续标注。
标注消息要花点时间!消息很多的话,更是如此。如果你为了赶时间,可以下载我标注好的数据集。
6.1.3 Twitter数据集重建
数据挖掘过程会用到很多变量,它们不仅出现在挖掘算法里,数据采集等过程中也少不了它们的身影。重现实验结果很重要,因为它有助于验证或改善实验效果。3
3这一段话,照直翻译过来,总觉得缺了点什么,推测作者想要表达的意思是控制每次实验中变量的取值,确保实验结果的可比较性。——译者注
算法X在一个数据集上取得80%的正确率,算法Y在另一个数据集上取得90%的正确率,不能说明算法Y优于X。只有在相同的测试集上,且在相同的条件下进行测试,才能比较算法的优劣。
你用上面的代码采集到的数据集与我的不同。主要原因在于,采集时间不同,Twitter返回的搜索结果也就不同。此外,标注结果也可能会有所差异。虽然有些消息显然是与编程语言Python有关,但也不乏模棱两可的情况,比如用我不懂的外语发布的消息,我给出的标注结果就可能有误。对于这种情况,Twitter提供了设置语言种类的接口,但即使使用该接口,返回的消息也不一定全都是你预先指定的语言。
出于这么多原因,对于从社交网站采集到的数据集重复进行相同的实验困难重重,Twitter也不例外。此外,Twitter明确禁止直接分享数据集。
解决方法之一是只分享消息编号,它是可以自由传播的。本节首先创建可以自由分享的消息编号数据集。然后,再来看下如何根据编号下载消息,重建先前的数据集。
首先,我们得把现有消息的编号及其类别保存下来。创建一个新的笔记本文件,指定接下来要用到的几个文件名。代码跟之前类似,只不过多了一个用来保存消息编号及其类别的文件。代码如下:
import osinput_filename = os.path.join(os.path.expanduser("~"), "Data","twitter", "python_tweets.json")labels_filename = os.path.join(os.path.expanduser(""), "Data","twitter", "python_classes.json")replicable_dataset = os.path.join(os.path.expanduser(""),"Data", "twitter", "replicable_dataset.json")
加载消息和类别,就跟我们在上一个笔记本文件中做的那样。
import jsontweets = []with open(input_filename) as inf:for line in inf:if len(line.strip()) == 0:continuetweets.append(json.loads(line))if os.path.exists(labels_filename):with open(classes_filename) as inf:labels = json.load(inf)
同时遍历所有的消息及消息所属的类别,创建新数据集,将其保存到列表中。
dataset = [(tweet['id'], label) for tweet, label in zip(tweets,labels)]
最后,把结果保存到文件中。
with open(replicable_dataset, 'w') as outf:json.dump(dataset, outf)
有了消息的编号和类别,我们就可以重建数据集。如果你想重建我在本章使用的数据集,所需代码请见本书配套代码包。
加载之前的数据集不难,但是要花些时间。新建一个笔记本文件,像之前那样指定好用于存储数据集、消息类别和消息编号的文件。我调整了下文件名,防止你覆盖掉之前采集的数据集,文件名你可以随意起,不必跟我的一样。代码如下:
import ostweet_filename = os.path.join(os.path.expanduser(""), "Data","twitter", "replicable_python_tweets.json")labels_filename = os.path.join(os.path.expanduser(""), "Data","twitter", "replicable_python_classes.json")replicable_dataset = os.path.join(os.path.expanduser("~"),"Data", "twitter", "replicable_dataset.json")
使用JSON从文件中加载消息编号及类别数据。
import jsonwith open(replicable_dataset) as inf:tweet_ids = json.load(inf)
保存所有消息的类别很容易。遍历数据集,抽取编号,用两行代码就能搞定(打开文件和保存消息)。然而,我们无法确定之后能再次获取到所有消息(例如,上次采集后,有些消息被设置为隐私),因此类别和消息可能就无法对应。
为了举例说明,我在采集数据后的第一天尝试重建数据集,却发现有两条消息已经从线上消失(可能被用户删除或设置为隐私)。因此,只输出我们实际能用到的类别就显得尤为重要。具体做法是,首先,创建actual_labels列表存储我们能够再次从Twitter网站获取到的消息的类别。然后,创建字典,为消息的编号和类别建立起映射关系。
代码如下:
actual_labels = []label_mapping = dict(tweet_ids)
接下来,用twitter库根据消息编号采集消息。这可能要花点时间。导入前面用过的twitter库,创建授权令牌,用它来初始化twitter对象。
import twitterconsumer_key = "<Your Consumer Key Here>"consumer_secret = "<Your Consumer Secret Here>"access_token = "<Your Access Token Here>"access_token_secret = "<Your Access Token Secret Here>"authorization = twitter.OAuth(access_token, access_token_secret,consumer_key, consumer_secret)t = twitter.Twitter(auth=authorization)
遍历并抽取所有的消息编号。
all_ids = [tweet_id for tweet_id, label in tweet_ids]
然后,打开输出文件,保存消息。
with open(tweets_filename, 'a') as output_file:
Twitter API允许我们一次只能获取100条消息。因此,每次遍历100条消息。
for start_index in range(0, len(tweet_ids), 100):
把这一批次的100个编号用逗号连接起来,便于下面使用Twitter的API根据编号查找消息。
id_string = ",".join(str(i) for i inall_ids[start_index:start_index+100])
接着,调用Twitter定义的statuses/lookup方法,传入一批消息编号(已转换为字符串),以采集这些消息。
search_results = t.statuses.lookup(_id=id_string)
我们把返回结果中的每一条消息,按照之前采集数据集的做法,将它们依次保存到文件中。
for tweet in search_results:if 'text' in tweet:output_file.write(json.dumps(tweet))output_file.write("\n\n")
最后一步(仍然属于if模块),还需要保存当前遍历到的消息的类别。获取消息类别要用到之前创建的label_mapping字典,根据消息编号查找即可。代码如下:
actual_labels.append(label_mapping[tweet['id']])
运行上述代码,采集所有消息。如果你的数据集很大,花费时间相应较多——Twitter会限制请求的频次。最后一步,保存actual_labels到类别文件4里。
4再次提醒下它里面存放的是能够再次抓取到的消息的类别。——译者注
with open(labels_filename, 'w') as outf:json.dump(actual_labels, outf)
6.2 文本转换器
数据集创建好后,怎样在它上面施展数据挖掘的威力呢?
文本数据集包括图书、文章、网站、手稿、代码以及其他形式的文本。我们目前所见过的所有算法不是用来处理数值型就是类别型特征,怎样才能把文本转换成算法可以处理的形式?
多种测量方法能够帮上忙。比如,平均词长和平均句长可用来预测文本的可读性。除此之外,还有很多其他类型的特征,比如我们接下来要用到的单词是否出现(word occurrence)。
6.2.1 词袋
一种最简单却非常高效的模型就是只统计数据集中每个单词的出现次数。我们来创建一个矩阵,每一行表示数据集中的一篇文档,每一列代表一个词。矩阵中的每一项为某个词在文档中的出现次数。
下面这段文字节选自托尔金(J. R. R. Tolkien)的《指环王》。
Three Rings for the Elven-kings under the sky,
Seven for the Dwarf-lords in halls of stone,
Nine for Mortal Men, doomed to die,
One for the Dark Lord on his dark throne
In the Land of Mordor where the Shadows lie.
One Ring to rule them all, One Ring to find them,
One Ring to bring them all and in the darkness bind them.
In the Land of Mordor where the Shadows lie.
—J.R.R. Tolkien's epigraph to The Lord of The Rings
单词the在引文中出现了9次,单词in、for、to和one各出现了4次。单词ring和of各出现3次。
从中选取几组数据,创建一个简单的数据集。
| 单词 | the | one | ring | to |
|---|---|---|---|---|
| 频次 | 9 | 4 | 3 | 4 |
可以用counter方法统计列表中各字符串出现次数。统计单词时,通常将所有字母转换为小写,因此定义字符串时顺便把它转换为小写形式。代码如下:
s = """Three Rings for the Elven-kings under the sky,Seven for the Dwarf-lords in halls of stone,Nine for Mortal Men, doomed to die,One for the Dark Lord on his dark throneIn the Land of Mordor where the Shadows lie.One Ring to rule them all, One Ring to find them,One Ring to bring them all and in the darkness bind them.In the Land of Mordor where the Shadows lie. """.lower()words = s.split()from collections import Counterc = Counter(words)
c.most_common(5)输出出现次数最多的前5个词,竟然有4个词并列第二,多输出几个就能看出词频的差异了。
词袋模型主要分为以下三种:第一种像上面这样使用词语实际出现次数作为词频。缺点是当文档长度差异明显时,词频差距会非常大。第二种是使用归一化后的词频,每篇文档中所有词语的词频之和为1。这种做法优势明显,它规避了文档长度对词频的影响。第三种,直接使用二值特征来表示——单词在文档中出现值为1,不出现值为0。本章使用第三种。
另外一种(更)通用的规范化方法叫作词频—逆文档频率法(term frequency-inverse document frequency,简写为tf-idf),该加权方法用词频来代替词的出现次数,然后再用词频除以包含该词的文档的数量。第10章将会用到词频—逆文档频率法。
Python有很多用于处理文本的库。我们将使用主流的NLTK库(Natural Language ToolKit,自然语言处理工具集)抽取特征。scikitlearn提供进行类似处理的CountVectorizer类,建议你花点时间了解下(第9章将会用到)。然而在分词方面,NLTK提供更多选择。如果你打算用Python做自然语言处理,NLTK是个不错的选择。
6.2.2 N元语法
比起用单个词作特征,使用N元语法能更好地描述文档,具体优势稍后会讲。N元语法是指由几个连续的词组成的子序列。拿我们的数据集来讲,N元语法指的是每条消息里一组连续的词。
N元语法的计算方法跟计算单个词语方法相同,我们把构成N元语法的几个词看成是词袋中的一个词。数据集5中每一项就变成了N元语法在给定文档中的词频。
5指用N元语法作为特征的数据集。——译者注
举个例子吧,当 n 取3时,我们从下面引文中抽取前几个N元语法。
Always look on the bright side of life.
第一个N元语法(三元)是Always look on,第二个是look on the,第三个是on the bright。你可能已经发现,几个N元语法有重合,其中三个词有不同程度的重复。
N元语法比起单个词有很多优点。这个简单的概念不用通过大量的计算,就提供了有助于理解词语用法的上下文信息。它的缺点是特征矩阵变得更为稀疏——一个N元语法不太可能出现两次(尤其是在Twitter消息及其他短文本中!)。
对于社会媒体所产生的内容以及其他短文档,N元语法不可能出现在多篇不同的文档中,除非是转发。然而,在长文档中,N元语法就很有效。
文档的另外一种N元语法关注的不是一组词而是一组字符(虽然字符N元语法6有多种计算方法!)。字符N元语法有助于发现拼写错误,除此之外,还有其他好处。本章及第9章都将测试这种N元语法的效果。
6英文为Character N-gram。 ——译者注
6.2.3 其他特征
除了N元语法外,还可以抽取很多其他特征,其中就包括句法特征,比如特定词语在句子中的用法。对于需要理解文本含义的数据挖掘应用,往往会用到词性。本书限于篇幅将不涉及这些特征。如果你对此感兴趣,推荐你看由Packt出版的Python 3 Text Processing with NLTK 3 Cookbook,作者为Jacob Perkins。
6.3 朴素贝叶斯
毫无疑问,朴素贝叶斯概率模型是以对贝叶斯统计方法的朴素解释为基础。尽管存在朴素的一面,这种方法应用面很广且都取得了不错的效果。特征类型和形式多样的数据集也可以用它进行分类,本章重点讲解如何用二值化后的特征组成的词袋模型来分类。
6.3.1 贝叶斯定理
大多数人在开始学习统计学时,都会被灌输从频率论者角度出发看问题的思想,即假定数据遵从某种分布,我们的目标是确定该种分布的几个参数。我们假定参数是固定的(也可能不正确),然后用自己的模型来套这些数据,甚至通过测试来证明数据与我们的模型相吻合。
相反,贝叶斯统计实际上是根据普通人(非统计学家)实际的推理方式来建模。我们用拿到的数据,来更新模型对某事件即将发生的可能性的预测结果。在贝叶斯统计学中,我们使用数据来描述模型,而不是使用模型来描述数据,用数据证实拍脑瓜得出的模型是典型的频率论者的做法。
贝叶斯定理旨在计算P(A | B)的值,也就是在已知B发生的条件下,A发生的概率是多少。大多数情况下,B是被观察事件,比如“昨天下雨了”,A为预测结果“今天会下雨”。对数据挖掘来说,B通常是观察样本个体,A为被预测个体所属类别。下一节将学习如何在数据挖掘领域使用贝叶斯定理。
贝叶斯定理公式如下:
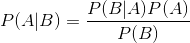
举例说明,我们想计算含有单词drugs的邮件为垃圾邮件的概率(正如我们认为含有该词的Twitter消息可能是兜售药品的垃圾广告)。
在这里,A为“这是封垃圾邮件”。7我们先来计算P(A),它也被称为先验信念(prior belief)。计算方法是,统计训练集中垃圾邮件的比例。如果我们的数据集每100封邮件有30封垃圾邮件,P(A)为30/100或0.3。
7原文直译为“A为这是封垃圾邮件的概率”,其实此处A表示的是事件,而不是概率。——译者注
B表示“该封邮件含有单词drugs”。类似地,我们可以通过计算数据集中含有单词drugs的邮件数量得到P(B)。如果每100封邮件中有10封邮件包含单词drugs,那么P(B)就为10/100或0.1。计算P(B)时,我们不关注邮件是不是垃圾邮件。
P(B|A)指的是垃圾邮件中含有单词drugs的概率,计算起来也很容易,统计训练集中所有垃圾邮件的数量以及其中含有单词drugs的数量。30封垃圾邮件中,如果有6封含有单词drugs,那么P(B|A)就为6/30或0.2。
现在,我们根据贝叶斯定理就能计算出P(A|B),得到含有drugs的邮件为垃圾邮件的概率。把上面求出来的各项代入前面的贝叶斯公式,得到结果0.6。这表明如果邮件中含有drugs这个词,那么该邮件为垃圾邮件的概率为60%。
请注意上述例子的实证性特点——我们使用的经验或证据直接来自于数据集,而不是事先假定好的某种分布。相比之下,频率论方法会要求我们首先为训练集中的单词出现概率创建某种分布形式。
6.3.2 朴素贝叶斯算法
回过头看下贝叶斯公式,我们可以用它计算个体从属于给定类别的概率。因此,它可以用来分类。
我们用C表示某种类别,用D表示数据集中一篇文档,来计算贝叶斯公式所要用到的各种统计量,对于不好计算的,做出朴素假设,简化计算。朴素贝叶斯分类算法使用贝叶斯定理计算个体从属于某一类别的概率。
P(C)为某一类别的概率,可以从训练集中计算得到(方法跟上文检测垃圾邮件例子所用到的一致)。统计训练集所有文档从属于给定类别的百分比。
P(D)为某一文档的概率,它牵扯到各种特征,计算起来很困难,但是在计算文档属于哪个类别时,对于所有类别来说,P(D)相同,因此根本就不用计算它。稍后我们来看下怎么处理。
P(D|C)为C类含有文档D的概率。由于D包含多个特征,计算起来可能很困难,这时朴素贝叶斯算法就派上用场了。我们朴素地假定各个特征之间是相互独立的,分别计算每个特征(D1、D2、D3等)在给定类别出现的概率,再求它们的积。
P(D|C) = P(D1|C) x P(D2|C).... x P(Dn|C)
上式右侧对于二值特征相对比较容易计算。直接在数据集中进行统计,就能得到所有特征的概率值。
相反,如果我们不做朴素的假设,就要计算每个类别不同特征之间的相关性。这些计算很难完成,如果没有大量的数据或足够的语言分析模型也不可能完成。
到这里,算法就很明确了。对于每个类别,我们都要计算P(C|D),忽略P(D)项。概率较高的那个类别即为分类结果。由于P(D)对每个类别来说都是相等,去掉它对最终预测结果没有多大影响。
6.3.3 算法应用示例
举例说明下计算过程,假如数据集中有以下一条用二值特征表示的数据:[1, 0, 0, 1]。
训练集中有75%的数据属于类别0,25%属于类别1,且每个特征属于每个类别的似然度如下。
类别0:[0.3, 0.4, 0.4, 0.7]
类别1:[0.7, 0.3, 0.4, 0.9]
拿类别0中特征1的似然度举例子,上面这两行数据可以这样理解:类别0中有30%的数据,特征1的值为1。
我们来计算一下这条数据属于类别0的概率。类别为0时,P(C=0) = 0.75。
朴素贝叶斯算法用不到P(D),因此我们不用计算它。我们来看下计算过程。
P(D|C=0) = P(D1|C=0) x P(D2|C=0) x P(D3|C=0) x P(D4|C=0)= 0.3 x 0.6 x 0.6 x 0.7= 0.0756
现在,我们就可以计算该条数据从属于每个类别的概率。需要提醒的是,我们没有计算P(D),因此,计算结果不是实际的概率。由于两次都不计算P(D),结果具有可比较性,能够区分出大小就足够了。来看下计算结果。
P(C=0|D) = P(C=0) P(D|C=0)= 0.75 * 0.0756= 0.0567
接着,计算类别1的概率。
P(C=1) = 0.25
朴素贝叶斯公式不需要计算P(D)。我们来看下计算过程。
P(D|C=1) = P(D1|C=1) x P(D2|C=1) x P(D3|C=1) x P(D4|C=1)= 0.7 x 0.7 x 0.6 x 0.9= 0.2646P(C=1|D) = P(C=1)P(D|C=1)= 0.25 * 0.2646= 0.06615
该条数据应该被分到类别1中。计算过程中,你可能已经猜到结果了。看到最终结果两个类别的概率如此接近,你可能还是会有点惊讶。毕竟,类别为0时,P(D|C)的概率比类别为1时高很多。这是因为我们给出的先验概率很高,即大部分数据都属于类别0。
如果训练集中两类数据数量相同,结果就会大为不同。假设P(C=0) 、P(C=1) 各为0.5,再计算下结果看看。
6.4 应用
接下来,创建流水线,接收一条消息,仅根据消息内容,判断它是否与编程语言Python相关。
我们使用NLTK抽取特征。NLTK提供了大量用于自然语言处理的工具。后续章节还会继续使用它。
用
pip安装NLTK:pip3 install nltk如果安装失败,请参考NLTK安装指南:www.nltk.org/install.html。
接下来,创建流水线抽取词语特征,并使用朴素贝叶斯算法对消息进行分类。流水线包括以下步骤。
(1) 用NLTK的word_tokenize函数,将原始文档转换为由单词及其是否出现组成的字典。
(2) 用scikitlearn中的DictVectorizer转换器将字典转换为向量矩阵,这样朴素贝叶斯分类器就能使用第一步中抽取的特征。
(3) 正如前几章做过的那样,训练朴素贝叶斯分类器。
(4) 还需要新建一个笔记本文件ch6_classify_twitter(本章最后一个),用于分类。
6.4.1 抽取特征
我们使用NLTK抽取单词是否出现作为特征。我们想在流水线中使用NLTK,但是它的接口与转换器接口不一致。因此,需要创建一个包含fit和transform方法的基础转换器,只有这样才能在流水线中使用。
首先,创建转换器类。这个类不需要进行预处理,只需要抽取特征。因此,fit函数不做任何操作,只返回它自身(self)即可,转换器对象要用到它。
转换器函数就有点复杂。我们要用它从每篇文档中抽取单词,如果单词出现,记为True。注意这里使用二值特征,单词在文档中出现,值为True,反之,值为False。如果我们想使用词频,就要创建用来统计单词频率的字典,前几章讲过。
来看下代码。
from sklearn.base import TransformerMixinfrom nltk import word_tokenizeclass NLTKBOW(TransformerMixin):def fit(self, X, y=None):return selfdef transform(self, X):return [{word: True for word in word_tokenize(document)}for document in X]
返回结果为一个元素为字典的列表,第一个字典的各项为第一条消息中的所有词语。字典的每一项用单词作为键,值为True,表示该词在该条消息中出现过。字典中没有出现的词,表示这条消息里不包含该词。当然,我们也可以用值False来表示没在消息中的词,但是那样太浪费存储空间,也没有必要。
6.4.2 将字典转换为矩阵
这一步是将上面得到的字典转换为可以用分类器进行处理的矩阵。在DictVectorizer的帮助下,这一步变得非常容易。
DictVectorizer类接受元素为字典的列表,将其转换为矩阵。矩阵中的各个特征为所有字典中的每个键,特征值就是特征在文本中是否出现。用代码生成字典很容易,但是实现的很多数据挖掘算法更喜欢接收矩阵格式的数据,于是DictVectorizer显得格外有用。
数据集中,每个字典用单词作为键,单词只有在对应的消息中出现,这个单词才会出现在字典里。因此,矩阵以每个单词作为特征,如果消息中出现该单词,那么相应的特征值就为True。
导入DictVectorizer后,就可以使用它。
from sklearn.feature_extraction import DictVectorizer
6.4.3 训练朴素贝叶斯分类器
最后,我们需要组装分类器,因为本章使用朴素贝叶斯算法,数据集只包含二值特征,因此我们使用专门用于二值特征分类的BernoulliNB分类器,它用起来很简单。就像是DictVectorizer一样,我们先来导入它,把它添加到流水线中。
from sklearn.naive_bayes import BernoulliNB
6.4.4 组装起来
终于等到把所有部件组装起来的时候了。像前面做过的那样,在笔记本文件中,指定好文件名,加载数据集和类别数据。注意是消息(不是消息编号)及它们的类别所在的文件。代码如下:
import osinput_filename = os.path.join(os.path.expanduser("~"), "Data","twitter", "python_tweets.json")labels_filename = os.path.join(os.path.expanduser("~"), "Data","twitter", "python_classes.json")
加载消息。我们只对消息内容感兴趣,因此只提取和存储它们的text值。代码如下:
tweets = []with open(input_filename) as inf:for line in inf:if len(line.strip()) == 0:continuetweets.append(json.loads(line)['text'])
加载消息的类别。
with open(classes_filename) as inf:labels = json.load(inf)
创建流水线,把所有部件组合起来。流水线包含以下三个部分。
我们创建的
NLTKBOW转换器DictVectorizer转换器BernoulliNB分类器
流水线代码如下:
from sklearn.pipeline import Pipelinepipeline = Pipeline([('bag-of-words', NLTKBOW()),('vectorizer', DictVectorizer()),('naive-bayes', BernoulliNB())])
我们几乎现在就可以运行流水线,用之前多次用过的cross_val_score方法来计算正确率。但是在这之前,我们要介绍一种比正确率更好的评价指标。我们后面会看到,每个类别数据量不同的情况下,正确率不足以说明算法的优劣。
6.4.5 用F1值评估
选择评价指标时,了解它们的适用范围很重要。正确率应用范围很广,理解起来比较容易,计算起来也方便。但是,造假很容易。换句话说,你很容易就能实现一个正确率很高,但实际用处不大的算法。
我们的消息数据集(你的可能与此不同)中,50%的消息与编程语言有关,50%不相关,很多数据集不会这么均匀(balanced)。
例如,对于垃圾邮件过滤器而言,其所处理的邮件很可能80%以上都是垃圾邮件,倘若一个过滤器把所有邮件都标为垃圾邮件,它没有实际应用价值,但是正确率却高达80%!
为了解决这个问题,我们使用另一个最为常用的评价指标F1值(也被称为F值、F-measure,或者其他变体8)。
8比如F0.5等。——译者注
F1值是以每个类别为基础进行定义的,包括两大概念:准确率(precision)和召回率(recall)。准确率是指预测结果属于某一类的个体,实际属于该类的比例。召回率是指被正确预测为某个类别的个体数量与数据集中该类别个体总量的比例。
在我们这里,可分别对两个类别(相关和不相关)的分类情况计算F1值。但是,我们只关注相关这一类数据的分类情况。因此,准确率计算变为以下问题:在所有被预测为相关的消息中,真正相关的占比多少?类似地,召回率就转化为:数据集所有相关的消息中,有多少被正确预测为相关的?
计算出准确率和召回率后,就能得到F1值,它是两者的调和平均数。

将scoring参数的值设置为F1,就能使用scikitlearn中的F1方法。默认将会返回类别为1的F1值。使用以下代码求得F1值。
scores = cross_val_score(pipeline, tweets, labels, scoring='f1')
输出平均值。
import numpy as npprint("Score: {:.3f}".format(np.mean(scores)))
结果为0.798,这表明预测含有Python的消息与编程语言有关的F1值差不多为80%。这是使用包含200条消息的数据集取得的结果。如果采集更多消息作为训练数据,你会发现结果还会提升!
6.4.6 从模型中获取更多有用的特征
你可能存在这样的疑问:“什么特征才是判断一条消息是否相关的最好的特征?”我们可以从朴素贝叶斯模型中抽取该信息,找到朴素贝叶斯算法所认为的最好的特征。
首先,训练得到一个新模型。使用cross_val_score在测试集上得到交叉检验结果不难,但是要得到模型本身就不容易了。为了得到模型,我们只好用流水线的fit函数,创建新模型。代码如下:
model = pipeline.fit(tweets, labels)
借助流水线的named_steps属性和步骤名(创建流水线对象时,我们自己定义的),就能访问流水线每一个步骤。例如,可以像下面这样访问朴素贝叶斯模型。
nb = model.named_steps['naive-bayes']
从这个模型中,可以抽取每个单词的对数概率,比如log(P(A|f)),其中f为给定特征。
之所以使用对数概率,是因为实际值非常小。例如,第一个值为-3.486,实际概率约为0.03。计算中涉及很小的概率值时,常使用对数概率来防止数值下溢,因为非常小的值往往会被约等于0。所有概率连乘,其中一个值为0,最终结果将为0!而实际上即使是很小的值,大小不同,对分类的贡献率也会有所差异,值越大的特征贡献率越大。
把得到的对数概率数组按照降序排列,找出最有用的特征。降序排列,需要在值前加个负号。代码如下:
top_features = np.argsort(-feature_probabilities[1])[:50]
上面代码只是给出特征索引值而没有给出实际的特征名称。这样看不出什么东西来,因此,需要把特征索引和特征名称对应起来。流水线的DictVectorizer这一步很关键,它是用来创建矩阵的。幸运的是,它也记录了特征名称和索引值的映射关系。因此,可以从流水线的这一部分抽取特征。
dv = model.named_steps['vectorizer']
通过在DictVectorizer的feature_names_属性中进行查找,找到最佳特征的名称,然后将其输出。输入下面代码,运行后将得到最佳特征列表。
for i, feature_index in enumerate(top_features):print(i, dv.feature_names_[feature_index],np.exp(feature_probabilities[1][feature_index]))
前几个特征为“:” “http” “#” “@”。结合采集的数据来判断,我们认为这些很可能是噪音(虽然冒号在编程语言之外的文本中使用的相对较少)。更多的训练数据,有助于减少这些噪音对分类的影响。接着往下看,下面这些特征更像是与编程语言有关。
7 for 0.18867924528311 with 0.14150943396228 installing 0.066037735849129 Top 0.066037735849134 Developer 0.056603773584935 library 0.056603773584936 ] 0.056603773584937 [ 0.056603773584941 version 0.047169811320843 error 0.0471698113208
还有一些特征是在工作环境中提及Python,因此可能指的是编程语言Python。(虽然作为自由职业者的耍蛇人也可能使用Python这个词,但是他们较少活跃在Twitter上。)
22 jobs 0.066037735849130 looking 0.056603773584931 Job 0.056603773584934 Developer 0.056603773584938 Freelancer 0.047169811320840 projects 0.047169811320847 We're 0.0471698113208
上面最后一个特征通常出现在诸如“We're looking for a candidate for this job”(我们正在招聘符合该职位要求的员工)这样的消息中。
查看这些特征,我们收获不小,有了这些特征,我们自己经过训练也可以完成分类任务,寻找这些特征的共同点(与主题相关),或者去除讲不通的特征。例如,词“RT”虽然排名比较靠前,然而,这是Twitter网站表示转发的用语。经验丰富的工作人员就可以从特征列表中删除这个词,降低由于数据集很小而引入的噪音对分类结果的影响。
6.5 小结
本章研究的是文本挖掘——特征的抽取、应用及扩展方法,具体研究任务是根据语境消除词语的歧义——即一条消息中的Python是否指编程语言。我们使用Twitter提供的API下载消息,使用在笔记本文件中建立的表单完成语料标注。
我们还考虑了实验结果的可再现性。虽然Twitter不允许你把自己采集的数据给别人使用,但是消息编号是可以共享的。我们编写代码,保存消息编号,再用这些编号来重建先前的数据集。由于有些消息被删除或是出于其他原因,我们无法再次获取它们。
我们用朴素贝叶斯分类器对文本进行分类,该分类器是以贝叶斯定理为基础,它使用数据来更新模型,而不是像频率论者那样从模型出发。这有助于整合新数据到模型中,利用新数据来更新模型和使用先验知识。此外,基于各特征相互独立的朴素假设,便于计算各特征出现在给定类别的概率,而不用考虑各特征之间复杂的相关性。
我们用词语是否出现作为特征值——即消息是否含有某个词,这种模型9叫作词袋模型。虽然它丢掉了词语在句子中的位置等信息,但它在很多数据集上表现不凡。
9把文档看成由一个个孤立的、无前后位置关系的单词组成的。——译者注
朴素贝叶斯分类器结合词袋模型,组装成的流水线功能强大。对于大多数文本挖掘任务,它都能取得很好的效果。在尝试更高级的模型之前,用这样的分类器取得的分类结果作为参考的基准很不错。另外一个优点是,朴素贝叶斯分类器不需要调整任何参数(如果你愿意折腾的话,也确实有几个)。
下一章将介绍怎样从另外一种数据类型——图中抽取特征,尝试解决向社会媒体网站用户推荐感兴趣的人这一问题。
