第 10 章 新闻语料分类
前面大部分章节在对数据进行挖掘前,新数据所属的目标类别范围是已知的。在训练过程中,我们能够了解到变量跟类别之间存在怎样的关系。这种已知目标类别的学习任务,叫作有监督学习。本章研究的是在不知道类别的情况下如何进行数据挖掘。这叫作无监督学习,它偏重于探索、发现隐藏在数据里的信息,而不是用模型来分类,其探索性更强。
本章将介绍如何对新闻语料进行聚类,以发现其中的趋势和主题。本章还将讨论怎样从链接聚合网站抽取新闻语料。
本章主要介绍如下几个概念。
从任意新闻网站获取文本内容
使用reddit网站API采集有趣的新闻报道
使用聚类分析进行无监督的数据挖掘
抽取文档主题
用线上学习方法无需再次训练即可更新模型
组合不同的模型进行聚类
10.1 获取新闻文章
本章将构建一个按照主题为最新的新闻报道分组的系统。你可以运行几周(或更长时间)以了解这段时间新闻趋势的变化。
系统首先从流行的链接聚合网站reddit1寻找新闻报道的链接。reddit存储了大量其他网站的链接,还提供讨论区。网站收集的链接按照类别进行分类,这些类别被统称为subreddit,比如有电视节目、趣味图片等类别。本章关注的是新闻这一类链接。本章使用/r/worldnews类别的链接,但是我们所编写的代码也可以用来抓取其他类别的语料。
1Y Combinator孵化的项目。最初使用Lisp语言开发,后改用Python,网站开放源代码,可以从Github上找到。创始人Steve Huffman在Udacity上开设了一门讲解Web开发的课程,课程编号为CS253。Steve卖掉reddit后,创立了专注于旅游搜索的Hipmunk网站。2015年再度回到reddit,出任CEO。web.py的作者Aaron Swartz也是reddit的联合创始人。——译者注
本章的目标是下载大家所关注的新闻报道,对其进行聚类分析,寻找其中的主题或主要概念,无需人工分析成百上千篇新闻报道,就能洞察人们关注的焦点。
10.1.1 使用Web API获取数据
前面有几章都是使用Web API从网站抽取数据。例如,第7章就用到Twitter网站的API。采集数据是数据挖掘流水线至关重要的一个环节。Web API是采集多个主题数据的绝佳工具。
使用Web API采集数据,有三个注意事项:授权方法、请求频率限制和API端点(endpoints)。
授权方法是数据提供方用来管理数据采集方的。数据提供方以此了解谁正在采集数据,确保采集方抓取数据的频率没有超出上限,同时对采集方都采集了哪些数据也做到心中有数。对于大多数网站,普通的个人用户账号就能用来采集数据,但也有部分网站要求采集方使用正式的开发者账号。
采集频率限制规定了采集方在约定时间内的最大请求次数,尤其是针对免费提供的服务。在使用数据获取接口时,一定要了解清楚,不同的网站很可能有着不同的规定。Twitter的API要求每15分钟(视调用的API而定)之内最多请求180次数据。reddit规定每分钟至多发起30次请求,下面我们还会讲到。其他有些网站会限制每天的请求次数,当然也有限制到秒级别的。即使同一个网站,不同的API调用,也有着截然不同的采集频率限制。例如,谷歌地图对每种资源API的调用限制,与按小时请求就有着不同规定,对前者限制更为严格。
如果你的应用或实验需要发起更多的请求和更快的响应,超出了免费API所能提供的,你可以寻求与API提供商进行商业合作。
API端点指的是用来抽取信息的实际网址。不同网站提供不同的接口,大部分Web API提供RESTful接口(Representational State Transfer,表述性状态转移)。RESTful接口通常与HTTP协议使用相同的操作:GET、POST、DELETE是最常用的。例如,使用下述API端点检索某一资源的相关信息:www.dataprovider.com/api/resource_type/resource_id/。
获取信息,只需要发送HTTP GET请求到指定的网址。服务器返回资源信息、信息类型和ID。大多数API都是按照这种结构进行封装的,虽然在具体实现上会有所差异。大多数提供API的网站,都会给出详细的文档,列出所有开放使用的API的具体参数。
我们来看下获取信息的具体步骤。首先,设置连接reddit网站所用到的参数,这里需要用到reddit开发者密钥。从https://www.reddit.com/login登录reddit网站,打开https://www.reddit.com/prefs/apps。点击“are you a developer? create an app…”,填写表单,选择script类型。你就能得到用户ID和密钥,新建一个笔记本文件,输入以下代码。
CLIENT_ID = "<Enter your Client ID here>"CLIENT_SECRET = "<Enter your Client Secret here>"
reddit还要求你在使用他们的API时,设置唯一的用户代理(user agent)字符串。在设置用户代理时,注意把自己的reddit用户名也写上,以创建唯一标识你应用的用户代理字符串。我的用户代理字符串中包含本书的英文名、章节编号“chapter 10”及版本号“0.1”,你可以使用其他内容。如果你的用户代理跟别人重复,你的请求频率将受到很大限制。
USER_AGENT = "python:<your unique user agent> (by u<your reddit username>)"
此外,你需要使用自己的用户名和密码登录reddit。如果你还没有账号,请注册一个(免费且无需验证个人信息)。
下一步会用到你的密码,把代码分享给别人之前,记得删除它。如果你不打算在代码中写入密码,把密码设置为none,这样每次运行时输入密码即可。但是,你需要在启动笔记本文件的终端输入,而不是在笔记本文件里输入,这是由笔记本文件的工作方式决定的。如果你无法在终端输入,请直接在代码里设置好密码。IPython的开发人员正在编写修复这个问题的插件,但是写作本书时,插件还没写好。
指定用户名和密码,代码如下:
USERNAME = "<your reddit username>"PASSWORD = "<your reddit password>"
接着,创建登录函数,使用以上信息进行登录。reddit的登录接口将会返回进一步连接所需要的令牌,这也就是登录函数的返回结果。函数声明如下:
def login(username, password):
首先,如果你不想把密码写到代码里,把它设置为none,但是你需要在命令行输入,前面已经说过。代码如下:
if password is None:password = getpass.getpass("Enter reddit password for user {}:".format(username))
使用独一无二的用户代理很重要,否则你的连接将严重受限。代码如下:
headers = {"User-Agent": USER_AGENT}
接着,创建HTTP授权对象,以登录reddit服务器。
client_auth = requests.auth.HTTPBasicAuth(CLIENT_ID, CLIENT_SECRET)
发起POST请求到access_token端点以实现登录,POST的数据有用户名、密码、授权类型。本例中授权类型为使用密码进行登录。
post_data = {"grant_type": "password", "username": username, "password": password}
最后,函数使用requests库发起登录请求(通过HTTP POST请求实现),POST请求返回的结果为字典类型。其中有一项就是进一步请求所需的令牌。代码如下:
response = requests.post("https://www.reddit.com/api/v1/access_token", auth=client_auth, data=post_data, headers=headers)return response.json()
调用上述登录函数,获取令牌。
token = login(USERNAME, PASSWORD)
令牌对象为一字典结构,其中的access_token键对应的值就是进一步请求所需的令牌。该对象还包含令牌的使用范围(全局)和过期时间。例如:
{'access_token': '<semi-random string>', 'expires_in': 3600,'scope': '*', 'token_type': 'bearer'}
10.1.2 数据资源宝库reddit
链接聚合网站reddit(www.reddit.com)拥有几亿用户,虽然英文版主要面向美国。每个用户都可以发布他们感兴趣的网站的链接,同时为该链接指定标题。其他用户对其点赞,表示他们喜欢这个链接的内容,也可以投反对票,表示不喜欢。点赞最高的链接将被移到网页的最上面,没有多少人喜欢的将不会显示。随着时间的推移,先前发表的链接也将不再显示(根据喜欢数来定)。分享的链接被点赞后,用户将会获得叫作karma2的积分,这也是为了激励用户只分享好故事。
2karma,指因果报应。reddit网站使用该词,应是取其善有善报之意。——译者注
reddit用户也可以发表链接之外的其他内容,这些内容叫作自己的广播3,它由用户输入的标题和正文组成,通常是为了提问或是引发讨论,不在积分赚取范围之内。本章仅关注链接类广播,不关注评论类的。
3广播对应英文单词post,指的是用户发表的一条内容。——译者注
网站的所有广播被分到叫作subreddit的不同栏目,每个栏目包含一系列与之相关的广播。用户发布广播时,需要选择广播所属的栏目。每个栏目都有自己的管理员和内容管理规则,用户不能发表与栏目无关的内容。
广播默认根据热度(Hot)进行排序,一条广播的热度由其存在的时间、喜欢数、不喜欢的次数来决定。除了热度外,还有最新发表的(New)和一定时间内最受欢迎的(Top)两种排序方法,最新广播可能包含大量的垃圾信息。本章将按照热度来选取广播,这些广播比较新,内容质量也比较高(单纯根据时间排序,得到的链接有很多是垃圾链接)。
使用我们前面获取到的令牌,就可以获取一个栏目的一系列链接。/r/端点默认返回所指定栏目的热门文章。我们把栏目指定为世界新闻/r/worldnews。
subreddit = "worldnews"
我们使用字符串格式化方法,用刚指定的栏目来创建完整的URL。
url = "https://oauth.reddit.com/r/{}".format(subreddit)
接下来,需要设置头部,这样才能指定授权令牌,设置独一无二的用户代理,争取不会被过分限制请求次数。代码如下:
headers = {"Authorization": "bearer {}".format(token['access_token']),"User-Agent": USER_AGENT}
然后,跟之前一样,使用requests库发起请求,别忘了指定头部。
response = requests.get(url, headers=headers)
调用response的json方法,将会得到包含reddit返回信息的一个Python字典。它包含给定栏目的25条广播,对它们进行遍历,输出每条广播的标题。广播的相关内容存储在字典键为data的那一项中。代码如下:
for story in result['data']['children']:print(story['data']['title'])
10.1.3 获取数据
我们数据集的每条广播都来自/r/worldnews栏目的热度列表。上节讲解了连接reddit网站和抽取广播内容的方法。我们来创建一个函数,把这两个步骤整合起来,抽取指定栏目每条广播的标题、链接和喜欢数。
我们遍历世界新闻栏目,最多一次获取100篇新闻报道。我们还可以使用分页,reddit最多允许我们读多少页,我们就读多少页。但是我们这里最多读5页。
因为我们代码会重复调用同一个API,为了防止超出网站所规定的采集频率限制,我们可以使用sleep函数,先来导入它。
from time import sleep
接下来要定义的这个函数接收三个参数,分别为栏目名称、授权令牌和读取的页数,默认值为5。
def get_links(subreddit, token, n_pages=5):
创建列表,存储新闻报道。
stories = []
我们在第7章见过如何在Twitter的API中使用分页功能。Twitter在返回结果时,同时返回一个游标,调用接口时,再一并传递游标,Twitter再利用此游标获取当前结果的下一页。reddit的API游标用法几乎和Twitter一致,只不过它使用after参数。获取第一页数据时用不到这个参数,将其置为none,获取到第一页后,再给它传一个有意义的值。代码如下:
after = None
遍历我们想得到的那些页。
for page_number in range(n_pages):
在上述循环中,设置好头部和URL,方法跟之前一样。
headers = {"Authorization": "bearer{}".format(token['access_token']),"User-Agent": USER_AGENT}url = "https://oauth.reddit.com/r/{}?limit=100".format(subreddit)
从第二次循环开始,我们需要设置after参数(否则返回结果都一样)。下一次循环所用到的after的值在前一次循环中设置。如果after值不为none,把它添加到URL的末尾,告诉reddit我们接下来要获取哪页的数据。代码如下:
if after:url += "&after={}".format(after)
下面跟之前一样,使用requests库发起请求,在返回结果上调用json()方法,得到Python字典。
response = requests.get(url, headers=headers)result = response.json()
返回结果中包含下一轮迭代所需的after值,用它来更新after参数。
after = result['data']['after']
暂停两秒钟,防止超出API使用频率限制。
sleep(2)
在循环体的最后,从reddit的返回结果中获取到每篇报道,把它们添加到stories列表中。我们仅需要标题、URL和喜欢数这三项数据。代码如下:
stories.extend([(story['data']['title'], story['data']['url'],story['data']['score'])for story in result['data']['children']])
最后(循环体外面),返回找到的所有新闻报道。
return stories
调用get_links函数时传入栏目名称和授权令牌即可。
stories = get_links("worldnews", token)
返回结果包含500篇新闻报道的标题、URL等,我们接下来就可以获取到这些URL所指向页面的文本内容。
10.2 从任意网站抽取文本
我们从reddit收集到的网址所指向的网站分属不同的网站组织。这些网站的目标用户是普罗大众而不是计算机程序。当我们尝试用程序获取里面的实际内容时,可能会遇到种种困难,因为如今的网站,有很多逻辑是在后台运行:调用JavaScript库,应用样式表,用AJAX加载广告,在侧边栏增加很多内容等,这些功能增加了网站的复杂程度。这些技术的应用使得当今的Web看起来鲜活、生动、丰富多彩,却增加了自动采集信息的难度。
10.2.1 寻找任意网站网页中的主要内容
我们首先需要访问每个链接,下载各个网页,将它们保存到Data文件夹中事先建好的用于存放原始网页的文件夹raw。后面,我们就要从这些原始网页中获取有用的信息。先把全部网页都保存下来,比起后面时不时地下载网页方便多了。首先,指定存放原始网页的目录。
import osdata_folder = os.path.join(os.path.expanduser("~"), "Data","websites", "raw")
后面我们要用MD5散列算法为每篇报道创建一个唯一的文件名,所以先导入hashlib。散列函数将输入(包含新闻报道名称的字符串)转换为一个看上去像是随机产生的字符串。对于相同的输入,散列函数返回相同的结果,但是不同输入之间的微小差别将会导致截然不同的输出结果。并且,散列函数为单向函数,根据散列值无法得到原来的值。导入hashlib,代码如下:
import hashlib
对于网页下载失败的网站,我们直接跳过。为了避免错过太多网页,我们维护一个计数器,统计下载失败的次数。如果是系统本身的问题阻止下载,那我们就要解决这些问题。如果失败次数过多,我们就要找出到底是什么东西在作怪,尝试去解决问题。例如,如果计算机没有联网,所有的500次下载都会失败,你得先解决联网问题,才能再开展下面的工作!
如果所有网页都能成功下载,计数器输出值应该为0。
number_errors = 0
接下来,遍历每一篇新闻报道。
for title, url, score in stories:
对报道的标题进行散列操作,作为输出文件名,以保证唯一性。因为reddit网站不要求文章标题具有唯一性,因此两篇报道可能使用相同的标题,这就会导致数据集中两条数据之间的冲突。我们使用MD5算法对报道的URL进行散列操作。现在人们发现MD5也不是绝对可靠的,但是就我们这么小的数据规模来说不太可能出问题(出现碰撞情况),即使出现这样的问题,也不用太担心。
output_filename = hashlib.md5(url.encode()).hexdigest()fullpath = os.path.join(data_folder, output_filename + ".txt")
接下来下载网页,保存到输出文件夹中。
try:response = requests.get(url)data = response.textwith open(fullpath, 'w') as outf:outf.write(data)
如果下载网页时出现问题,跳过问题网站,继续下载下一个网站的网页。上述代码能够完成我们收集到的95%的网站下载任务,对本章的应用来说足够了,因为我们寻找的是大体趋势而不是做精准研究。有时我们必须下载到所有网站的内容,这时就得调整代码,以处理各种可能的错误。抓取失败的5%~10%的网站,需要编写更为复杂的代码才能进行处理。我们来捕获出现的错误(这可是因特网,会有很多意想不到的错误),增加计数器计数,继续下载下个网站的网页。
except Exception as e:number_errors += 1print(e)
如果错误很多,把上面print(e)那一行改为raise,调用异常中断机制,以便修改问题。
现在,我们原始网页文件夹raw中有很多网页,查看这些网页(用文本编辑器打开),你会发现新闻报道的内容湮没在HTML、JavaScript、CSS以及其他内容之中。因为我们只对报道本身感兴趣,就需要一种从不同网站的网页中抽取内容的方法。
10.2.2 组装起来
获得原始网页后,我们需要找出每个网页中的新闻报道内容。有一些在线资源使用数据挖掘方法来解决这个问题,资源列表请见附录。一般来说,很少需要用到这些复杂的算法,当然使用它们能得到更为精确的结果。这也是数据挖掘艺术的一部分——知道什么时候用,什么时候不用。
首先,获取到raw文件夹中的所有文件名。
filenames = [os.path.join(data_folder, filename)for filename in os.listdir(data_folder)]
接着,创建输出文件夹,新闻报道内容抽取出来后,将保存到该文件夹下。
text_output_folder = os.path.join(os.path.expanduser("~"), "Data","websites", "textonly")
接着,编写从网页中抽取文本的代码。我们将使用lxml包解析HTML文件,lxml的HTML解析器容错能力强,可以处理不规范的HTML代码。导入语句如下所示:
from lxml import etree
文本抽取分为以下三步:首先,遍历HTML文件的每一个节点,抽取其中的文本内容。其次,跳过JavaScript、样式和注释节点,这些节点不太可能包含对我们有价值的信息。最后,确保文本内容长度至少为100个字符。分析文章主题,100个字符就够用,但是要想得到更准确的结果,文章长度有待增加。
前面说过,我们对脚本、样式或注释不感兴趣。因此,创建列表,存放这些不可能包含新闻报道内容的节点。代码如下:
skip_node_types = ["script", "head", "style", etree.Comment]
我们创建一个函数,把HTML文件解析成lxml etree对象,然后创建另外一个函数,解析前面得到的树,寻找文本。第一个函数简单易懂:打开网页文件,用lxml库的parse方法解析HTML文件。代码如下:
def get_text_from_file(filename):with open(filename) as inf:html_tree = lxml.html.parse(inf)return get_text_from_node(html_tree.getroot())
上述函数的最后一行,调用getroot()函数,获取到树的根节点,而不是整棵树etree,这样文本抽取函数get_text_from_node以节点作为参数,它能处理包括根节点在内的所有节点,便于递归调用。
文本抽取函数将在任何子节点上调用自己,以抽取子节点中的文本内容,最后返回拼接在一起的所有子节点的文本。
如果一个节点没有任何子节点,文本抽取函数返回该节点的文本内容。如果该节点不包含任何内容,就返回空字符串。请注意,还需要执行上面提到的文本抽取的第三步——检查文本长度是否达到100个字符。代码如下:
def get_text_from_node(node):if len(node) == 0:# No children, just return text from this itemif node.text and len(node.text) > 100:return node.textelse:return ""
明确节点有子节点之后,就对每一个子节点递归调用文本抽取函数,把返回的文本内容拼接在一起。代码如下:
results = (get_text_from_node(child) for child in nodeif child.tag not in skip_node_types)return "\n".join(r for r in results if len(r) > 1)
上面return语句中的if语句是为了防止返回空行(例如,有的节点没有子节点和文本内容)。
遍历所有的原始网页,从文件里抽取文本,把结果保存到纯文本文件4夹中。
4指去除掉网页代码后剩下的文本内容。——译者注
for filename in os.listdir(data_folder):text = get_text_from_file(os.path.join(data_folder, filename))with open(os.path.join(text_output_folder, filename), 'w')as outf:outf.write(text)
打开纯文本文件夹中的文件,查看它们是否有内容。如果很多都不包含新闻报道内容,提升最少字符限制,我们刚才用的是100。如果设置为更高的值,仍不起作用,或者你的应用对抽取文本内容有更高的要求,请尝试使用附录介绍的更为复杂的方法。
10.3 新闻语料聚类
本章的目的是通过聚类发现新闻语料中潜藏的趋势。我们将使用诞生于1957年的经典机器学习算法k-means(k均值)。
聚类属于无监督学习,我们使用聚类算法探索隐藏在数据里的奥秘。我们的数据集由大约500篇新闻报道组成,人工查看这些文章的主题费时费力。即使使用概括统计方法也不容易,对这种方法而言数据还是相当多。而聚类分析则可以按照主题把它们分成不同的簇,然后就可以按簇研究它们的主题。
我们在没有明确的类别的情况下会使用聚类方法。从这个意义上来讲,聚类算法学习时没有明确的方向性,它们根据目标函数而不是数据潜在的含义来学习。因此,选择聚类效果好的特征就很有必要。对于有监督学习,即使你选用了效果较差的特征,学习算法可以选择不用这些特征。例如,支持向量机为对分类用处不大的特征分配很小的权重。然而,聚类算法会综合所有特征给出最后结果——即使那些不会提供给我们答案的特征。
在对真实的数据进行聚类分析前,最好了解哪些特征适用于当前任务。本章使用词袋模型。我们寻找的是主题相关的簇,因此使用主题相关的特征为数据建模。我们之所以知道这些特征可用来聚类,是因为别人用有监督方法解决类似问题时用过这些特征。对比来说,如果要按照作者把作品分组,我们就要使用类似第9章用到的特征。
10.3.1 k-means算法
k-means聚类算法迭代寻找最能够代表数据的聚类质心点。算法开始时使用从训练数据中随机选取的几个数据点作为质心点。k-means中的k表示寻找多少个质心点,同时也是算法将会找到的簇的数量。例如,把k设置为3,数据集所有数据将会被分成3个簇。
k-means算法分为两个步骤:为每一个数据点5分配簇标签,更新各簇的质心点。
5一个数据点对应数据集中一条数据,把数据集看成样本,一条数据即可被称作是一个个体。——译者注
分簇这一步中,我们为数据集的每个个体设置一个标签,把它和最近的质心点联系起来。对于距离质心点1最近的个体,我们为它们分配标签1,距离质心点2最近的个体,分配标签2,以此类推。标签相同的个体属于同一个簇,所有带有标签1的数据点属于簇1(只是暂时的,数据点所属的簇会随着算法的运行发生变化)。
更新环节,计算各簇内所有数据点的均值,更新质心点。
k-means算法会重复上述两个步骤;每次更新质心点时,所有质心点将会小范围移动。这会轻微改变每个数据点在簇内的位置,从而引发下一次迭代时质心点的变动。这个过程会重复执行直到条件不再满足时为止。通常是在迭代一定次数后,或者当质心点的整体移动量很小时,就可以终止算法的运行。有时可以等算法自行终止运行,这表明簇已经相当稳定——数据点所属的簇不再变动,质心点也不再改变时。
下图表示的是对随机创建的数据集执行k-means算法,数据集包含三个簇。图中的三颗五角星表示最初随机从数据集中选取的三个质心点。k-means算法经过5轮迭代后,质心点发生了改变,具体位置用三角形来表示。
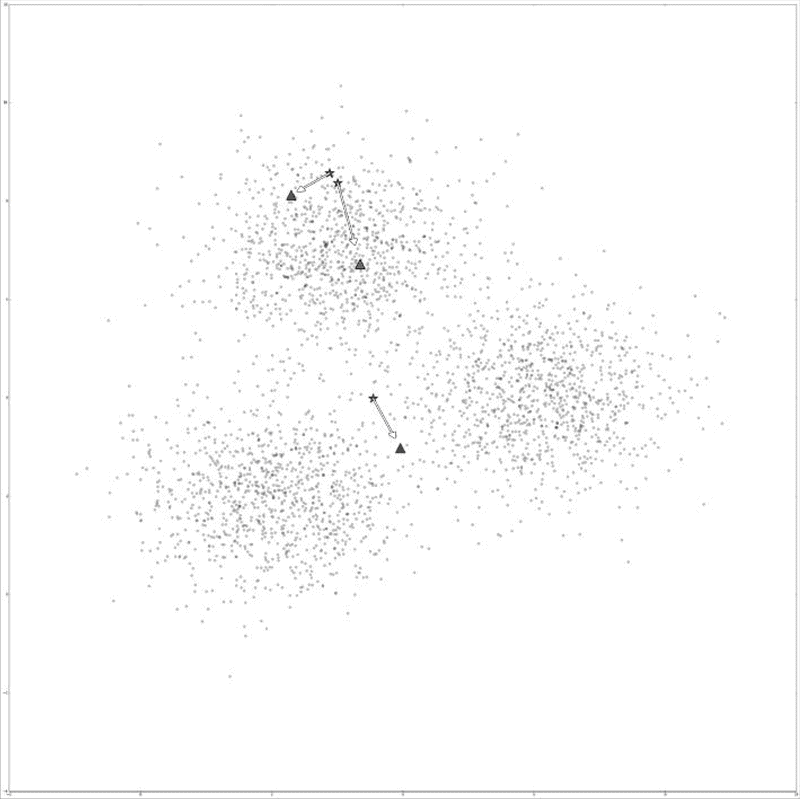
k-means算法因它所使用的数学方法和久经考验而充满魅力。该算法只有(大体上可以这么说)一个参数,虽然距它提出至今已过了半个多世纪,但由于它在很多数据挖掘问题上效果很好,仍被频繁使用。
scikitlearn实现了k-means算法,直接从cluster模块导入即可。
from sklearn.cluster import KMeans
我们顺便把CountVectorizer类的好兄弟TfidfVectorizer导进来。这个向量化工具根据词语出现在多少篇文档中,对词语计数进行加权。出现在较多文档中的词语权重较低(用文档集数量除以词语出现在的文档的数量,然后取对数)。对于很多文本挖掘应用,使用该种权重计算方法,能够有效提升效果。代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
创建数据分析流水线,流水线分两步,第一步是特征抽取,第二步是调用k-means算法。代码如下:
from sklearn.pipeline import Pipelinen_clusters = 10pipeline = Pipeline([('feature_extraction', TfidfVectorizer(max_df=0.4)),('clusterer', KMeans(n_clusters=n_clusters))])
我们为参数max_df设置了一个很低的值0.4,表示忽略出现在40%及以上的文档中的词语。这个参数可用来剔除本身不含有主题相关含义的词语。
首先训练算法,然后再用它来做预测。前几章的分类任务都是按照这两个步骤实施,但是这里有一点不同——我们没有为fit函数指定目标类别。这也正是无监督学习任务的含义所在!代码如下:
pipeline.fit(documents)labels = pipeline.predict(documents)
变量labels包含每个数据点的簇标签。标签相同的数据点属于同一个簇。需要指出的是簇标签本身没有含义:不能说簇1和簇2比簇1和簇3更相似。
我们可以使用Counter类来查看每个簇有多少数据点。
from collections import Counterc = Counter(labels)for cluster_number in range(n_clusters):print("Cluster {} contains {} samples".format(cluster_number,c[cluster_number]))
聚类问题的结果(注意你的数据集可能跟我的不同)往往是一个簇很大,包含了大多数个体,再有几个中等规模的簇,最后还有几个只包含一两个个体的很小的簇,这种不平衡性很常见。
10.3.2 评估结果
聚类分析主要是探索性分析,因此很难有效地评估聚类算法结果的好坏。评估算法结果最直接的方式是根据它要学习的标准对其进行评价。
对于k-means算法,寻找新质心点的标准是,最小化每个数据点到最近质心点的距离。这叫作算法的惯性权重(inertia),任何经过训练的KMeans实例都有该属性。
pipeline.named_steps['clusterer'].inertia_
输出结果为343.94,不过这个值本身没有意义,但是可以用它来确定分为多少簇合适。前面的例子,n_clusters的值被设置为10,但这是最佳值吗?下面代码n_clusters依次取2到20之间的值,每取一个值,k-means算法运行10次。每次运行算法都记录惯性权重。
对于n_clusters变量的每个取值,仅训练X矩阵一次,以(极大)提升代码运行速度。
inertia_scores = []n_cluster_values = list(range(2, 20))for n_clusters in n_cluster_values:cur_inertia_scores = []X = TfidfVectorizer(max_df=0.4).fit_transform(documents)for i in range(10):km = KMeans(n_clusters=n_clusters).fit(X)cur_inertia_scores.append(km.inertia_)inertia_scores.append(cur_inertia_scores)
变量inertia_scores存储了n_clusters取2到20每个值时所对应的惯性权重。我们把惯性权重和簇的数量做成图,以便了解它们之间的关系。
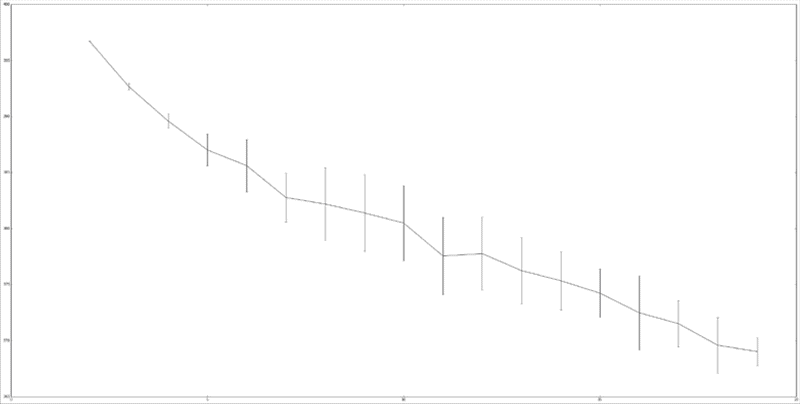
整体而言,随着簇数量的增加,质心点和其他数据点位置的调整逐渐减少,惯性权重应该逐渐降低,这是很容易就能从上图得到的结论。从6簇进一步分为7簇时,质心点是随机选取的,这将会直接影响到最终结果。尽管如此,整体的趋势(你的结果可能会有所不同)是簇数量为6时,惯性权重进行了最后一次大的调整。
随后惯性权重改变很小,虽然没有明确的标准可言。这样的时刻被称作是拐点(elbow),用图来表示就是曲线的顶点,看起来就像是肘部。有些数据集拐点很明显,但是有的数据集可能没有拐点(它们的图像看起来很平滑)。
根据上述分析,把n_clusters的值设置为6,重新运行算法。
n_clusters = 6pipeline = Pipeline([('feature_extraction',TfidfVectorizer(max_df=0.4)),('clusterer', KMeans(n_clusters=n_clusters))])pipeline.fit(documents)labels = pipeline.predict(documents)
10.3.3 从簇中抽取主题信息
现在我们把关注点放到各簇上,尝试从中找到每个簇的主题。首先,从特征提取这一步抽取词表。
terms = pipeline.named_steps['feature_extraction'].get_feature_names()
计算每簇所包含的个体数量。
c = Counter(labels)
遍历所有的簇,输出每簇所包含的个体数量。评估结果时,要把簇的大小考虑进去——有的簇可能只有一个个体,因此不能代表新闻趋势。代码如下:
for cluster_number in range(n_clusters):print("Cluster {} contains {} samples".format(cluster_number,c[cluster_number]))
接下来(在循环体内部),遍历该簇最重要的词语。首先,从质心点找出特征值最大的5个特征。代码如下:
print(" Most important terms")centroid = pipeline.named_steps['clusterer'].cluster_centers_[cluster_number]most_important = centroid.argsort()
依次输出这5个特征。
for i in range(5):
对i取反,因为most_important数组中的最小值排在最前面。
term_index = most_important[-(i+1)]
然后输出序号、词语和得分。
print(" {0}) {1} (score: {2:.4f})".format(i+1, terms[term_index], centroid[term_index]))
结果能较好地反映当时人们关注的焦点。我得到的结果(2015年3月)中,几个簇的主题为健康问题、中东紧张局势、朝鲜半岛紧张局势和俄罗斯相关问题。这些充斥着当时的新闻头条——虽然很多年以来就一直这样!
10.3.4 用聚类算法做转换器
另外提一下,k-means算法(以及其他聚类算法)还有比较有趣的一个特点,就是可以用来简化特征。特征简化的方法有很多种,比如主要成分分析(Principle Component Analysis)、潜在语义索引(Latent Semantic Indexing)等,这些方法还能用来创建新特征,但是它们通常对计算能力要求很高。
在前面的例子中,词表共有14 000个词条——这个数据集很大。我们的聚类算法把它们仅归为6个簇。我们可以使用数据点到质心点的距离作为特征创建一个特征数较之前少得多的数据集。
在k-means实例上调用转换函数。因为流水线最后一步是k-means实例,因此可以在它上面调用转换函数。
X = pipeline.transform(documents)
上面代码在流水线最后一步的k-means实例上调用转换方法。得到的矩阵有六个特征,数据量跟文档的长度相同。
你可以对得到的矩阵进行二次聚类,如果有目标类别的话,也可以用来分类。大致的流程是使用标注好的数据选取特征,用聚类方法把特征数减少到更容易操作的范围内,再用SVM等算法对前面处理过的数据集进行分类。
10.4 聚类融合
第3章研究了如何把几棵效果相对较差的决策树分类器整合在一起形成随机森林,用来处理分类任务。聚类算法也可以进行融合,这样做的主要原因是,融合后得到的算法能够平滑算法多次运行所得到的不同结果。正如我们之前所说,多次运行k-means算法得到的结果因最初选择的质心点不同而不同。多次运行算法,综合考虑所得到的多个结果,可以减少波动。
聚类融合方法还可以降低参数选择对最终结果的影响。大多数聚类算法对参数选择很敏感,参数稍有不同将带来不同的聚类结果。
10.4.1 证据累积
最基本的融合方法是对数据进行多次聚类,每次都记录各个数据点的簇标签。然后计算每两个数据点被分到同一个簇的次数。这就是证据累积算法(Evidence Accumulation Clustering,EAC)的精髓。
证据累积算法两大步骤如下:第一步,使用k-means等低水平的聚类算法对数据集进行多次聚类,记录每一次迭代两个数据点出现在同一簇的频率,将结果保存到共协矩阵(coassociation)中。第二步,使用另外一种聚类算法——分级聚类对第一步得到的共协矩阵进行聚类分析。分级聚类一个比较有趣的特性是,它等价于寻找一棵把所有节点连接到一起的树,并把权重低的边去掉。
遍历所有标签,记录具有相同标签的两个数据点的位置,创建共协矩阵。我们需要用到SciPy的稀疏矩阵csr_matrix。
from scipy.sparse import csr_matrix
注意函数声明中的参数为所有数据点的标签。
def create_coassociation_matrix(labels):
记录具有相同标签的两个数据点的行号和列号,把它们分别存储到rows和cols列表中。稀疏矩阵通常由一系列记录非零值位置的列表组成,csr_matrix就是这种类型的。
rows = []cols = []
标签去重后,再进行遍历。
unique_labels = set(labels)for label in unique_labels:
查找具有某一标签的所有数据点。
indices = np.where(labels == label)[0]
对于每组标签相同的数据点,记录它们的位置。代码如下:
for index1 in indices:for index2 in indices:rows.append(index1)cols.append(index2)
在所有循环的外面创建数据集,两个数据点标签相同时,数据集中该位置的值为1。有多少组数据点标签相同,数据集中就有多少个元素为1。代码如下:
data = np.ones((len(rows),))return csr_matrix((data, (rows, cols)), dtype='float')
调用上述函数,传入所有的数据点标签,就能得到共协矩阵。
C = create_coassociation_matrix(labels)
现在我们可以把这些矩阵的多个实例整合起来,多次运行k-means算法,把结果结合起来看。运行C(在记事本新格子里输入C,并运行),查看有多少个非零值。从得到的结果来看,矩阵中大约半数的项有值,我的聚类结果有一个大的簇(各簇的大小越均匀,非零值数量越少)。
下一步对共协矩阵进行分级聚类。我们需要找到该矩阵的最小生成树,删除权重低于阈值的边。
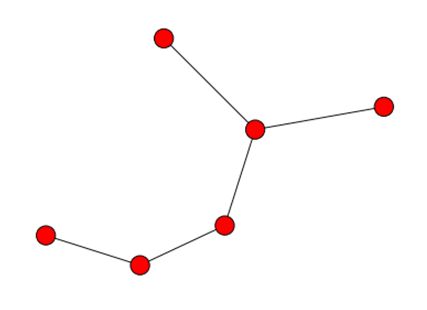
从图的理论角度看,生成树为所有节点都连接到一起的图。最小生成树(Minimum Spanning Tree,MST)即总权重最低的生成树。结合我们的应用来讲,图中的节点对应数据集中的个体,边的权重对应两个顶点被分到同一簇的次数——也就是共协矩阵所记录的值。
下图的MST有6个节点。图中的节点可以在MST中多次使用,唯一的要求是所有的节点应该连接在一起。
我们使用SciPy sparse包的minimum_spanning_tree函数计算MST。
from scipy.sparse.csgraph import minimum_spanning_tree
可以直接在coassociation函数返回的稀疏矩阵上调用mst函数。
mst = minimum_spanning_tree(C)
然而,矩阵C中,值越高表示一组数据点被分到同一簇的次数越多——这个值表示相似度。相反,minimum_spanning_tree函数的输入为距离,高的值反而表示相似度越小。因此,我们对C取反再计算最小生成树。
mst = minimum_spanning_tree(-C)
上述函数返回结果为一个矩阵,大小跟C相同(行列数分别跟数据集样本数量和特征数相同),只不过保留了最小生成树中的边,其他都被删除了。
然后我们删除其边的权重小于阈值的节点。方法是,遍历MST矩阵中的每一条边,删除低于规定值的边。仅对共协矩阵(值为1或0,没有什么可处理的)进行一次遍历无法完成上述任务。因此,我们来创建额外的标签,创建一个新共协矩阵,然后把这两个矩阵相加。代码如下:
pipeline.fit(documents)labels2 = pipeline.predict(documents)C2 = create_coassociation_matrix(labels2)C_sum = (C + C2) / 2
然后再计算MST,删除在这两个矩阵中都没有出现的边。
mst = minimum_spanning_tree(-C_sum)mst.data[mst.data > -1] = 0
我们需要移除在C1和C2都没有出现的边——也就是值为1的。然而我们刚才在计算时,对C_sum取反,因此,阈值也应该使用相反数。
最后,我们找到所有的连通分支,也就是寻找移除低权重的边以后仍然连接在一起的节点。返回的第一个值为连通分支的数量(也就是有多少个簇),第二个值为每个数据点的标签。代码如下:
from scipy.sparse.csgraph import connected_componentsnumber_of_clusters, labels = connected_components(mst)
我的数据集最终找到了8个簇,每个簇都跟之前差不多。这不足为奇,因为我们仅进行了两轮 k-means迭代,更多的迭代(请见下节)结果差异会更明显。
10.4.2 工作原理
k-means算法不考虑特征的权重,实际上它假定所有的特征取值范围相同。我们在第2章探讨过使用取值范围不同的特征所带来的问题。k-means算法寻找的是圆形簇(circular clusters),如下图所示。

从上图中,我们可以看到不是所有的簇都是圆形。左侧的簇呈圆形,这也是k-means算法很擅长处理的。中间为椭圆形,通过特征规范化(feature scaling),k-means算法可以处理该种聚类问题。最后一幅图甚至不是凸形的——这种形状很奇怪,用k-means算法来处理聚类结果为这种形状的数据集有难度。
证据累积算法的工作原理为重新把特征映射到新空间,上节讲到用k-means来做特征简化,本质上,证据累积算法使用与其相似的原则,每次运行k-means算法都相当于使用转换器对特征进行一次转换。但是我们这里仅使用实际的标签而不是到每个质心点的距离。我们使用存储在共协矩阵中的数据。
证据累积算法只关心数据点之间的距离而不是它们在原来特征空间的位置。对于没有规范化过的特征,仍然存在问题。因此,特征规范很重要,无论如何都要做(我们用tf-idf规范特征值,从而使特征具有相同的值域)。
我们在第9章见过使用SVM内核做类似的转换。这些转换方法很强大,在处理复杂数据集时记得使用。
10.4.3 实现
现在我们来把前面这些整合起来,创建接口跟scikitlearn对得上的简易聚类算法,实现证据累积的两个步骤。首先,使用scikitlearn的ClusterMixin创建证据累积算法类。
from sklearn.base import BaseEstimator, ClusterMixinclass EAC(BaseEstimator, ClusterMixin):
参数分别为第一步k-means算法运行次数(创建共协矩阵),用来删除边的阈值和每次运行k-means算法要找到的簇的数量。指定n_clusters的取值范围,每次运行k-means算法都能得到不同的聚类结果。一般而言,从融合的角度看,每次结果有所不同是件好事。否则,融合多次算法跟只运行一次算法效果相同(但是几个聚类结果之间差距较大也不能表明融合后效果就会好)。代码如下:
def __init__(self, n_clusterings=10, cut_threshold=0.5, n_clusters_range=(3, 10)):self.n_clusterings = n_clusteringsself.cut_threshold = cut_thresholdself.n_clusters_range = n_clusters_range
为EAC类定义fit函数。
def fit(self, X, y=None):
接着,使用k-means算法进行低水平聚类,把每一次迭代得到的共协矩阵加起来。为了节省内存,我们使用生成器,仅在需要时创建共协矩阵。生成器每迭代一次,就在数据集上跑一个新的k-means实例,然后创建一个共协矩阵。再使用sum方法把得到的多个共协矩阵加起来。代码如下:
C = sum((create_coassociation_matrix(self.singleclustering(X))for i in range(self.n_clusterings)))
跟前面一样,我们创建MST,删除低于阈值的边(注意使用相反数),找到连通分支。跟scikitlearn其他fit函数一样,我们都需要返回self,以便流水线的下一个步骤使用。代码如下:
mst = minimum_spanning_tree(-C)mst.data[mst.data > -self.cut_threshold] = 0self.n_components, self.labels_ = connected_components(mst)return self
接着,编写通过一轮迭代进行聚类的函数。具体方法是,使用numpy的randint函数随机选取几个簇,用参数n_clusters_range指定随机选取的范围。然后使用k-means算法进行聚类和预测数据集属于哪个簇。最后返回由k-means计算得到的簇标签。代码如下:
def singleclustering(self, X):n_clusters = np.random.randint(*self.n_clusters_range)km = KMeans(n_clusters=n_clusters)return km.fit_predict(X)
像之前那样创建流水线,只不过在流水线最后一步,使用证据累积算法而不是之前的k-means算法实例,运行代码。代码如下。
pipeline = Pipeline([('feature_extraction', TfidfVectorizer(max_df=0.4)),('clusterer', EAC())])
10.5 线上学习
有时,在开始学习之前,我们没有足够的数据用来进行训练。有时,数据量太大,内存装不下,或一时拿不到数据,或完成预测后,我们又拿到了新数据。以上情况就可以使用线上学习方法,在需要时及时训练模型。
10.5.1 线上学习简介
线上学习是指用新数据增量地改进模型。支持线上学习的算法可以先用一条或少量数据进行训练,随着更多新数据的添加,更新模型。相比之下,不支持线上学习的算法在开始训练之前需要一次性拿到所有数据。标准的k-means算法以及前几章的绝大部分算法都不支持线上学习。
线上学习算法在只有几条新数据的情况下就能做到部分更新已有模型。神经网络算法是支持线上学习的标准例子。随着一条新数据输入到神经网络后,网络中的权重根据学习速率进行更新,学习速率通常为一个很小的值,比如0.01。这表明一条新数据只能对模型带来很小的变动(希望是改进)。
神经网络还可以按照批模式来训练,每次只用一组数据进行训练。批模式,算法运行速度快,但是耗内存较多。
同理,我们可以用一个数据点或少量数据点来轻微更新k-means中的质心点。具体做法是,在k-means算法更新质心点这一步加入学习速率。我们假定这些新数据点是从总体中随机选取的,质心点应该朝它们在原来标准、离线的k-means算法中的位置移动。
线上学习与流式学习(streaming-based learning)有关,但有几个重要的不同点。线上学习能够重新评估先前创建模型时所用到的数据,而对于后者,所有数据都只使用一次。
10.5.2 实现
scikitlearn提供了MiniBatchKMeans算法,可以用它来实现线上学习功能。这个类实现了partial_fit函数,接收一组数据,更新模型。相反,调用fit()将会删除之前的训练结果,重新根据新数据进行训练。
因为MiniBatchKMeans聚类过程跟scikitlearn中其他聚类算法一致,所以创建和使用方法跟其他算法相同。
因此,我们可以使用TfIDFVectorizer从数据集中抽取特征,创建矩阵X。代码如下:
vec = TfidfVectorizer(max_df=0.4)X = vec.fit_transform(documents)
再来导入MiniBatchKMeans,初始化一个实例。
from sklearn.cluster import MiniBatchKMeansmbkm = MiniBatchKMeans(random_state=14, n_clusters=3)
接着,随机从X矩阵中选择数据,模拟来自外部的新数据。每次取一些数据,更新模型。
batch_size = 10for iteration in range(int(X.shape[0] / batch_size)):start = batch_size iterationend = batch_size (iteration + 1)mbkm.partial_fit(X[start:end])
在实例上调用predict()方法,获得原始数据集的聚类结果。
labels = mbkm.predict(X)
然而目前阶段,我们无法在流水线中使用TfIDFVectorizer,因为它不是在线算法。为了解决这个问题,我们使用HashingVectorizer类,它巧妙地使用散列算法极大地降低了计算词袋模型所需的内存开销。我们不是记录特征名字,比如文档中的词,而是仅记录这些名字的散列值。这样,在我们查看数据集之前,就能知道所有的特征,因为我们已经拿到了所有特征的散列值。大约有218个散列值,数据量很大,但是使用稀疏矩阵,存储和计算都很容易,因为矩阵中很多项的值都为0。
写作本书时,sickit-learn的Pipeline类无法用于线上学习。不同的应用有着细微差别,这也就表明不存在万全之策,也就无法封装一个通用的流水线类。相反,我们可以创建自己的能够支持线上学习的流水线子类。我们这个类继承自scikitlearn的Pipeline类。
class PartialFitPipeline(Pipeline):
创建partial_fit函数,接收输入矩阵、可选的类别(这里用不到)。
def partial_fit(self, X, y=None):
我们之前讲过,流水线由一系列转换步骤组成,前一步的输出为下一步的输入。我们把第一个输入设置为X矩阵,接着,用每一个转换器对输入进行转换。
Xt = Xfor name, transform in self.steps[:-1]:
然后,转换已有的数据集,继续迭代,直到达到最后一步(我们这里为聚类算法)。
Xt = transform.transform(Xt)
接着,在最后一步调用partial_fit函数,返回结果。
return self.steps[-1][1].partial_fit(Xt, y=y)
我们现在就可以创建流水线,在线上学习过程使用MiniBatchKMeans和HashingVectorizer。除了新类PartialFitPipeline和HashingVectorizer外,使用线上学习进行聚类分析,其整个过程跟本章其他部分大同小异,只不过每次使用的数据量少多了。
pipeline = PartialFitPipeline([('feature_extraction',HashingVectorizer()),('clusterer', MiniBatchKMeans(random_state=14, n_clusters=3))])batch_size = 10for iteration in range(int(len(documents) / batch_size)):start = batch_size iterationend = batch_size (iteration + 1)pipeline.partial_fit(documents[start:end])labels = pipeline.predict(documents)
当然这种方法也有不足之处。比如,我们很难知道对于每个簇来说哪些词最为重要。如果想知道的话,这就要用到另外一种特征抽取工具CountVectorizer,先取到每个词的散列值,然后通过散列值而不是词本身查找词的重要性。这样做有点麻烦,并且抵消了我们使用HashingVectorizer节省下来的内存。并且,我们也无法使用之前用过的max_df参数,因为它需要知道特征是什么并一直统计它们。
此外,我们无法在线上学习中使用tf-idf权重。虽然我们可以估计并使用权重,但是也很麻烦。HashingVectorizer算法非常有用,是散列算法的精彩应用。
10.6 小结
本章研究了一种无监督学习方法——聚类。无监督学习用来探索数据而不是分类或预测。我们从reddit网站采集到的数据没有类别,所以无法对其进行分类。我们使用k-means算法把新闻报道分成组,以找到数据中隐藏的主题和趋势。
从reddit网站采集网址数据后,我们发现它们指向不同的网站,因此,需要研制一种适用范围广的网页内容抽取方法。抽取数据时,我们只寻找大块的文本,而没有使用成熟的机器学习方法。有一些有趣的机器学习方法可以改善文本抽取效果,详见附录部分本章的补充内容。我在附录中,针对每一章都给出了后续学习方向及实验效果改善方法,还给出了参考资料,并介绍了读者可能感兴趣的难度更大的应用。
本章还探讨了一种很直观的融合算法——证据累积算法。融合算法可用来处理结果之间的差异,尤其是你不知道怎么选取好的参数时(参数选取对于聚类来说就特别难)。
最后,我们介绍了线上学习。这是通向包括大数据在内的大型机器学习算法的入口,接下来两章会讲大数据。后两章的实验规模很大,在学习模型的同时,还要求学会管理数据。
下一章将从无监督学习再度回到分类。我们将研究以复杂神经网络为基础的分类方法——深度学习。
