第 15 章 方便好用的 Python 模块
各位在开发应用的过程中有没有想过“这个处理是不是有人实现过”“这个东西该怎么实现”之类的问题呢?这种时候最好先去 Google 上看看是否有现成的模块可用。如果只需要 Python 模块,可以到 PyPI 上去找。发现有能拿来就用的模块绝对是一大好事。确认一下许可证,只要没问题就放心去用吧。
如果能顺利缩短开发时间自然是好事一桩,但现实中往往不那么顺利,比如找不到好用的模块,或是找到模块却不知道怎么用,查询用法又花掉许多时间等。最理想的情况是事先知道这些好用模块的适用场合及使用方法,以便有需要时直接拿来用。因此我们要从平时就注意积累,多通过书籍、网络博客、RSS 订阅等途径收集相关信息。
本章的目的就是充当各位的信息源,为各位介绍一些方便好用的 Python 模块。
15.1 轻松计算日期
日期是大部分系统都要用到的,但是它的计算比较复杂,因此很容易出现 Bug。开发高品质软件时要尽量避免复杂的操作。使用 dateutil 模块可以让我们用简单的描述来完成复杂的日期计算。
dateutil
15.1.1 日期计算的复杂性
首先我们了解一下日期计算中容易出 Bug 的地方。
◉ “1 个月后”是哪一天
遇到“1 月 1 日的 1 个月后是哪一天”的问题时,大部分人都会回答“2 月 1 日”。那么,换成“1 月 31 日的 1 个月后是哪一天”,答案又是怎样呢?恐怕我们会得到“2 月 28 日或 29 日”“3 月 3 日”“2 月 31 日”等多种回答。在开发系统的过程中,如果用了“1 个月后”这种模糊不清的表述,开发者之间很可能产生认识上的分歧,最终开发结果就会出现 Bug。在这个例子中,“30 天之后”“下个月的最后一天”等表述都比“1 个月后”清楚得多,它们能准确指定一个日期,极大地避免歧义。
◉ 求下个月的最后一天
首先我们用 Python 标准模块 datetime 的 timedelta 来编写一个计算“下个月最后一天”的程序(LIST 15.1)。
LIST 15.1 datetime_dateutil_1.py
# coding: utf-8from datetime import datetime, timedeltadef main():# 下个月最后一天= 下下个月的前一天now_time = datetime.now()# 获取下下个月第一天的日期对象first_day_of_after_two_month = datetime(now_time.year,now_time.month + 2,1)# 获取下个月最后一天的日期对象last_day_of_next_month = \first_day_of_after_two_month - timedelta(days=1)# 输出结果print last_day_of_next_month.date()if __name__ == '__main__':main()
执行上述代码会得到如 LIST 15.2 所示的结果。
LIST 15.2 执行结果
$ python datetime_dateutil_1.py2012-02-29
这里我们通过“下下个月第一天的前一天”算出了“下个月的最后一天”。虽然这乍看上去没有什么问题,但实际上,在求“下下个月的第一天”时,我们忘记考虑年份的更迭了。now_time.month 可以取 1 ~ 12 的值,而这个值加上 2 有可能达到 13、14。因此,这个程序在遇到 11 月和 12 月时会发生例外。我们想要的运行情况是 now_time.month 为 11 和 12 时增算一年。问题修正后的代码如 LIST 15.3 所示。
LIST 15.3 datetime_dateutil_2.py
# coding: utf-8from datetime import datetime, timedeltadef main():# 下个月最后一天= 下下个月的前一天now_time = datetime.now()# 获取下下个月第一天的日期对象(考虑跨年问题)if now_time.month in [11, 12]:first_day_of_after_two_month = datetime(now_time.year + 1,now_time.month + 2 - 12,1)else:first_day_of_after_two_month = datetime(now_time.year,now_time.month + 2,1)# 输出下个月最后一天last_day_of_next_month = \first_day_of_after_two_month - timedelta(days=1)# 输出结果print last_day_of_next_month.date()if __name__ == '__main__':main()
可见,日期计算常常会遇到复杂的边界问题,很容易出现 Bug。下面我们用 dateutil 模块来简化这段代码。
15.1.2 导入 dateutil
用 pip 命令安装 dateutil 模块,代码如 LIST 15.4 所示。2014 年 12 月初的 dateutil 最新版本为 2.3。
LIST 15.4 用 pip 命令安装 dateutil 模块
$ pip install python-dateutil==2.3
使用 dateutil 模块的 relativedelta 函数时,我们可以使用如 LIST 15.5 所示的代码获取前面提到的“下个月最后一天”。
LIST 15.5 datetime_dateutil_3.py
# coding: utf-8from dateutil.relativedelta import relativedeltafrom datetime import datetime, timedeltadef main():# 下个月最后一天= 下下个月的前一天now_time = datetime.now()# 输出下个月最后一天last_day_of_next_month = \now_time + relativedelta(months=2, day=1, days=-1)# 输出结果print last_day_of_next_month.date()if __name__ == '__main__':main()
relativedelta 与 timedelta 一样,可以对 datetime 对象进行加减运算。关键字传值参数方面有 day、second、hour 等单数型和 days、seconds、hours 等复数型可供选择。单数型的传值参数为指定数值,复数型的传值参数为指定增减幅度。
◉ rrule
接下来要介绍的是 rrule,它可以获取符合指定规则的日期对象。比如 LIST 15.6,这段代码的作用是获取 2012 年 1 月 1 日到 2012 年 2 月 1 日的周一和周三的日期对象并输出。
LIST 15.6 dateutil_rrule.py
# coding: utf-8from datetime import datetimefrom dateutil.rrule import rrule, DAILY, MO, WEdef main():# 生成rrule 对象rrule_obj = rrule(DAILY, # 每天byweekday=(MO, WE), # 周一、周三dtstart=datetime(2012, 1, 1), # 2012 年1 月1 日起until=datetime(2012, 2, 1)) # 2012 年2 月1 日止# 逐个取出符合条件的日期对象并显示在屏幕上for dt in rrule_obj:print dtif __name__ == '__main__':main()
rrule 函数的第一个传值参数为获取间隔,可以指定 YEARLY(每年)、MONTHLY(每月)、WEEKLY(每周)、DAILY(每天)、HOURLY(每小时)、MINUTELY(每分钟)、SECONDLY(每秒)。其他条件通过选项指定。以 LIST 15.6 中的代码为例,byweekday 指定了星期几,dtstart 指定了开始日期,until 指定了终止日期。实际执行结果如 LIST 15.7 所示。
LIST 15.7 执行结果
$ python dateutil_rrule.py2012-01-02 00:00:002012-01-04 00:00:002012-01-09 00:00:002012-01-11 00:00:002012-01-16 00:00:002012-01-18 00:00:002012-01-23 00:00:002012-01-25 00:00:002012-01-30 00:00:002012-02-01 00:00:00
15.2 简化模型的映射
近年来,Web 系统为保证服务器与客户端、服务器与服务器之间的协作,越来越多地开始提供 JSON、XML 等格式的 API。在这类 API 的内部处理中,O/R 映射工具生成的对象要序列化成 JSON 或 XML 格式。
开发 API 时,API 提供的 JSON 数据的结构必须与 O/R 映射工具生成的模型对象的结构一致,否则就会出现问题。这种问题称为阻抗失配(Impedance Missmatch)。这种时候,如果模型层级结构比较复杂,那么模型的重复利用、代码的可读性、维护成本等方面都会遇到困难。
这里我们学习一个能有效解决阻抗失配的模块——bpmappers。
bpmappers
15.2.1 模型映射的必要性
在实际开发系统的过程中,API 规定的键名与值的对应关系很少能与数据模型的结构一致。接下来,我们以使用 JSON 格式返回响应的 API 为例进行学习。现在假设系统中使用了如 LIST 15.8 所示的 User 类的数据模型。
LIST 15.8 User 类
class User(object):def _init_(self, id, password, nickname, age):self.id = id # 用户IDself.password = password # 密码self.nickname = nickname # 昵称self.age = age # 年龄
这个数据模型拥有“用户 ID”“密码”“昵称”“年龄”这 4 个值。而在我们生成的 API 中,只将“用户 ID”和“昵称”两个值包含到响应之中。该 API 通过如下 JSON 格式的响应公开了 User 类的数据。
{"user_id": " 用户ID", "user_nickname": " 昵称"}
接下来写一个函数,使用该函数可以获取一个 User 类的对象,并将其转换为 JSON 格式(LIST 15.9)。
LIST 15.9 将 User 类对象转换为 JSON 格式的函数
import jsondef convert_user_to_json(user):""" 获取一个User 对象并返回JSON"""# 生成用于转换格式的字典对象user_dict = {'user_id': user.id, # 使用名为user_id 的键'user_nickname': user.nickname, # 使用名为user_nickname 的键}return json.dumps(user_dict) # 转换为JSON
这个函数通过 user_dict 变量生成字典对象,它实质上是给模型类的值与字典对象做了映射。像上面这样,我们用 API 提供数据模型的值时,必须给键和值做好映射。
数据模型与 API 响应数据的结构一致时,可以通过给数据模型添加元信息的方式简化映射的描述。使用 O/R 映射工具的数据模型大多含有元信息,因此映射更加简单一些。但正如例子所示,我们很少能遇到数据结构一致的模型,所以描述映射操作是必不可少的一步。
15.2.2 映射规则的结构化与重复利用
在需要返回多种响应的 API 时,意义相同部分的映射代码要保持一致,以便重复利用。
LIST 15.10 是一个返回简单的用户数据以及留言数据(包含用户和文本的数据)的 API。为便于理解,这里不采用 Web API 的形式,而是直接在控制台调用并显示结果。另外,本例中没有使用数据库。
LIST 15.10 mapping_model.py
# coding: utf-8import jsonclass User(object):def _init_(self, id, password, nickname, age):self.id = id # 用户IDself.password = password # 密码self.nickname = nickname # 昵称self.age = age # 年龄class Comment(object):def _init_(self, id, user, text):self.id = id # 留言IDself.user = user # 用户IDself.text = text # 留言内容def get_user(user_id):""" 返回用户对象的函数"""# 实际开发时应该访问数据库user = User(id=user_id,password='hoge',nickname='tokibito',age=26)return userdef get_comment(comment_id):""" 返回留言对象的函数"""# 实际开发时应该访问数据库comment = Comment(id=comment_id,user=get_user('bp12345'),text=u'Hello, world!')return commentdef mapping_user(user):"""User 模型与API 的映射"""return {'user_id': user.id, 'user_nickname': user.nickname}def mapping_user_2(user):"""User 模型与API 的映射2"""return {'user_id': user.id,'user_nickname': user.nickname,'user_age': user.age}def mapping_comment(comment):"""Comment 模型与API 的映射"""return {'user': mapping_user(comment.user), 'text': comment.text}def api_user_json(user_id):""" 以JSON 格式返回用户数据的API"""user = get_user(user_id) # 获取User 对象user_dict = mapping_user(user) # 映射到字典return json.dumps(user_dict, indent=2) # 以JSON 格式返回def api_user_detail_json(user_id):""" 以JSON 格式返回用户详细数据的API"""user = get_user(user_id) # 获取User 对象user_dict = mapping_user_2(user) # 映射到字典return json.dumps(user_dict, indent=2) # 以JSON 格式返回def api_comment_json(comment_id):""" 以JSON 格式返回留言数据的API"""comment = get_comment(comment_id) # 获取Comment 对象comment_dict = mapping_comment(comment) # 映射到字典return json.dumps(comment_dict, indent=2) # 以JSON 格式返回def main():# 获取用户数据的JSON 并显示print "--- api_user_json ---"print api_user_json('bp12345')# 获取用户数据(详细)的JSON 并显示print "--- api_user_detail_json ---"print api_user_detail_json('bp12345')# 获取留言数据的JSON 并显示print "--- api_comment_json ---"print api_comment_json('cm54321')if __name__ == '__main__':main()
在这段代码中,实现 API 功能的函数有 api_user_json、api_user_detail_json、api_comment_json。其执行结果如 LIST 15.11 所示。
LIST 15.11 执行结果
$ python mapping_model.py--- api_user_json ---{"user_id": "bp12345","user_nickname": "tokibito"}--- api_user_detail_json ---{"user_id": "bp12345","user_nickname": "tokibito","user_age": 26}--- api_comment_json ---{"text": "Hello, world!","user": {"user_id": "bp12345","user_nickname": "tokibito"}}
在 api_comment_json 的响应中,user 部分的数据结构要与 api_user_json 保持一致,因此使用了相同的映射函数。相对地,虽然 api_user_detail_json 与 api_user_json 的结构大致相同,但它们具有差异的部分使得它们用了不同的映射函数。
像上面这样,由于每个 API 之间都只存在细微的差异,使得映射函数成了一个俄罗斯套娃般的结构。随着这种函数增多,代码的可读性会越来越差。另外,因 API 的需求变更而导致函数传值参数增加时,需要一次性修正多个地方。
这些问题可以通过导入 bpmappers 来解决。
15.2.3 导入bpmappers
bpmappers 能帮助我们将对象或字典的数据映射到其他字典上。bpmappers 通过 pip 命令进行安装,代码如 LIST 15.12 所示。本书使用的 bpmappers 版本是 0.8。
LIST 15.12 用 pip 命令安装 bpmappers
$ pip install bpmappers
bpmappers 主要由 Mapper 类和 Field 类构成。Mapper 类相当于映射函数,Field 类相当于映射字典的键值对。我们通过 Python shell 执行 bpmappers,做一个简单的映射(LIST 15.13)。
LIST 15.13 用 bpmappers 做映射
>>> from bpmappers import Mapper, RawField>>> class SpamMapper(Mapper):... spam = RawField('foo')... egg = RawField('bar')...>>>>>> SpamMapper(dict(foo=123, bar='abc')).as_dict(){'egg': 'abc', 'spam': 123}
例子中定义了继承 Mapper 类的 SpamMapper 类,其属性包含 spam 和 egg 两个 RawField 对象。生成 SpamMapper 类的实例时,传值参数中指定了用做映射对象的字典。映射后的字典可以通过执行 Mapper 类的 as_dict 方法来获取。SpamMapper 类将 foo 键(或属性)的值映射到了 spam 键,将 bar 键(或属性)的值映射到了 egg 键。
接下来我们对前面那个返回用户数据和留言数据的 API(mapping_model.py)的源码作一下修改,对其导入 bpmappers。类和函数的重复部分在此省略。
LIST 15.14 bpmappers_mapping_model.py
# coding: utf-8import jsonfrom bpmappers import Mapper, RawField, DelegateFieldclass User(object):" 省略"class Comment(object):" 省略"def get_user(user_id):" 省略"def get_comment(comment_id):" 省略"class UserMapper(Mapper):"""User 模型与API 的映射"""user_id = RawField('id')user_nickname = RawField('nickname')class UserMapper2(UserMapper):"""User 模型与API 的映射2"""user_age = RawField('age')class CommentMapper(Mapper):"""Comment 模型与API 的映射"""user = DelegateField(UserMapper)text = RawField()def api_user_json(user_id):""" 以JSON 格式返回用户数据的API"""user = get_user(user_id) # 获取User 对象user_dict = UserMapper(user).as_dict() # 映射到字典return json.dumps(user_dict, indent=2) # 以JSON 格式返回def api_user_detail_json(user_id):""" 以JSON 格式返回用户详细数据的API"""user = get_user(user_id) # 获取User 对象user_dict = UserMapper2(user).as_dict() # 映射到字典return json.dumps(user_dict, indent=2) # 以JSON 格式返回def api_comment_json(comment_id):""" 以JSON 格式返回留言数据的API"""comment = get_comment(comment_id) # 获取Comment 对象comment_dict = CommentMapper(comment).as_dict() # 映射到字典return json.dumps(comment_dict, indent=2) # 以JSON 格式返回def main():" 省略"if __name__ == '__main__':main()
LIST 15.14 的执行结果没有变化。api_user_json 使用了 UserMapper。api_user_detail_json 使用的是继承 UserMapper 且添加了 age 映射的 UserMapper2 类。可以看到,bpmappers 的 Mapper 类能够利用继承的结构来添加不同的映射。另外,api_comment_json 的 user 部分与 UserMapper 的数据结构相同,所以我们直接通过 DelegateField 指定了 UserMapper。这种俄罗斯套娃式的映射结构同样可以用其他类来实现。
另外,列表内元素的套娃式映射可以用 ListDelegateField 来完成。LIST 15.15 中,我们通过 Python shell 执行了一个用 ListDelegateField 实现的映射。
LIST 15.15 用 ListDelegateField 实现的映射
- >>> from bpmappers import Mapper, RawField, ListDelegateField
- >>> class SpamMapper(Mapper):
- ... spam = RawField('foo')
- ...
- >>> class ListSpamMapper(Mapper):
- ... spam_list = ListDelegateField(SpamMapper)
- ...
- >>> ListSpamMapper({'spam_list': [{'foo': 123}, {'foo': 456}]}).as_dict()
- {'spam_list': [{'spam': 123}, {'spam': 456}]}
ListDelegateField 中指定了继承 Mapper 类的 SpamMapper 类。ListDelegateField 可以以指定的类映射列表中的各个元素。通过上述例子我们可以看到,用 bpmappers 能够简化映射定义,同时方便映射的重复利用。
15.2.4 与 Django 联动
bpmappers 的一些功能可以为 Django 框架的模型对象映射提供辅助。使用 bpmappers.djangomodel.ModelMapper 可以轻松地根据 Django 的模型类生成用于映射的类。
下面我们用 ModelMapper 类来给简单的 Django 模型类作一个映射。请注意,这里我们不创建 Django 工程,所以需要在源码内初始化 Django(LIST 15.16)。
LIST 15.16 django_and_bpmappers.py
# coding: utf-8# 初始化Djangofrom django.conf import settingssettings.configure()from django.db import modelsfrom bpmappers.djangomodel import ModelMapperclass Person(models.Model):""" 表示人的数据模型"""name = models.CharField(u' 名字', max_length=20)age = models.IntegerField(u' 年龄')class Meta:# 指定app_label,防止应用名解析时出错app_label = ''class PersonMapper(ModelMapper):""" 让Person 模型映射到字典时需要用到的类"""class Meta:model = Persondef main():# 生成Person 对象person = Person(id=123, name=u'okano', age=26)# 映射到字典person_dict = PersonMapper(person).as_dict()# 输出到屏幕上print person_dictif __name__ == '__main__':main()
为了让 Person 模型映射到字典,我们定义了一个继承 ModelMapper 类的 PersonMapper 类。ModelMapper 类内部定义了内部类 Meta,model 指定了 Person 模型。这样描述之后,ModelMapper 就会自动地根据 Person 模型拥有的字段生成映射。
在安装了 bpmappers 和 Django 的计算机上运行上述代码将得到如 LIST 15.17 所示的结果。
LIST 15.17 执行结果
$ python django_and_bpmappers.py{'id': 123, 'name': u'okano', 'age': 26}
15.2.5 编写JSON API
接下来我们在导入 bpmappers 的前提下实际编写一个返回 JSON 格式响应的 API。首先,我们以第 2 章中开发的留言板应用为例编写代码,实现在用户提交信息时以 JSON 格式返回响应。具体代码如下。
from flask import jsonifyfrom bpmappers import Mapper, RawField, ListDelegateFieldclass GreetingMapper(Mapper):name = RawField()comment = RawField()class GreetingListMapper(Mapper):greeting_list = ListDelegateField(GreetingMapper)@application.route('api')def api_index():""" 留言"""# 读取提交的数据greeting_list = load_data()result_dict = GreetingListMapper({'greeting_list': greeting_list}).as_dict()# 以JSON 格式返回响应return jsonify(**result_dict)
将这段代码添加到 guestbook.py 的 if __name__ …之前。JSON 的响应会以 greeting_list 为键,通过数组的形式返回各次提交的姓名以及留言内容。要返回的数据通过已有的 load_data 函数获取,然后以 GreetingListMapper 类进行映射。GreetingListMapper 类使用了 ListDelegateField 类,从而实现以 GreetingMapper 类对列表内的值进行映射。
接下来保存修改,执行源码并启动服务器。在添加几条数据之后访问 http://127.0.0.1:5000api,我们会得到 JSON 格式的响应。下面是用 urllib 访问时的例子。
$ python -m urllib http://127.0.0.1:5000api{"greeting_list": [{"comment": "\u65e5\u672c\u8a9e\u306e\u6587\u5b57\u5217","name": "tokibito"},{"comment": "Hello, world!","name": "tokibito"}]}
导入 bpmappers 能提高映射的重复利用率,还能让我们在需求变更时更灵活地加以应对,因此即便是很简单的 API,也建议用 bpmappers 来实现。
15.3 图像处理
Python 的图像处理通常用 Pillow(Python Imaging Library(Fork))来进行。Pillow 由 PIL(Python Imaging Library)的分支工程开发而来。由于 PIL 已经停止开发及维护,所以如今 Pillow 成为了主流。它支持 JPEG、PNG、GIF、BMP 等多种图像格式。本书使用的是 Pillow 的 2.6.1 版本。
Pillow
15.3.1 安装Pillow
Pillow 与多种处理图像数据的程序库存在依赖关系,因此安装时需要多加注意。目前 Pillow 在 PyPI 上提供了面向 Windows 和 OS X 的 wheel 包。在 Windows、OS X 上安装(包括用 pip 命令安装)时不需要进行编译。如果使用的是其他平台,那么由于需要从 sdist 进行 C 扩展的编译,所以必须准备编译器和各种图像处理库。
◉ 有 wheel 可用的平台
如果是 OS X 和 Windows,只需像 LIST 15.18 这样使用 pip install 安装 wheel 包即可。
LIST 15.18 在OS X 上安装Pillow
$ pip install pillow==2.6.1Downloading/unpacking pillow==2.6.1Downloading Pillow-2.6.1-cp27-none-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.whl (2.8MB): 2.8MB downloadedInstalling collected packages: pillowSuccessfully installed pillowCleaning up...
◉ 从源码构建
接下来准备进行 Pillow 编译时所需的库。下面以 Ubuntu 14.04 为例进行学习。
首先,因为需要编译 C 扩展,所以需要一些基本的开发工具。我们先来确认一下 1.1 节中的安装(LIST 15.19)。
LIST 15.19 检查设置以便进行 python 的 C 扩展编译
$ pkg-config python2.7 --libs --cflags-Iusrinclude/python2.7 -Iusrinclude/x86_64-linux-gnu/python2.7 -lpython2.7
另外,图像格式和字体等的支持需要用到下述程序库。
| 支持对象 | 库 |
|---|---|
| JPEG | libjpeg-dev |
| OpenJPEG | libopenjpeg-dev |
| PNG | zlib1g-dev |
| TIFF | libtiff5-dev |
| webp | libwebp-dev |
| 字体 | libfreetype6-dev |
| 色彩管理 | liblcms2-dev |
执行 LIST 15.20 中的命令,统一安装 Pillow 需要的程序包。
LIST 15.20 安装 Pillow 需要的程序包
$ sudo apt-get install libjpeg-dev libopenjpeg-dev zlib1g-dev libtiff5-dev libfreetype6-dev libwebp-dev liblcms2-dev
现在所需工具和库已经齐全,可以用 pip 进行安装了(LIST 15.21)。
LIST 15.21 用 pip 命令安装 Pillow
$ pip install pillow==2.6.1
安装时会显示支持的图像格式等,我们可以借此查看想要的功能是否已经生效。LIST 15.22 是除 TKINTER 以外的所有功能均生效的例子。
LIST 15.22 查看支持的功能
running build_ext
running build_ext
PIL SETUP SUMMARY
version Pillow 2.6.1
platform linux2 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2]
* TKINTER support not available
—- JPEG support available
—- OPENJPEG (JPEG2000) support available (2.1.3)
—- ZLIB (PNG/ZIP) support available
—- LIBTIFF support available
—- FREETYPE2 support available
—- LITTLECMS2 support available
—- WEBP support available
—- WEBPMUX support available
To check the build, run the selftest.py script.
NOTE
Pillow 2.6.1 无法识别 Ubuntu 14.04 上安装的 libopenjpeg-dev。今后的版本中应该会修复这个问题。
如果应用不涉及 Tkinter 模块的图像,可以不用管 TKINTER 的支持问题。另外,安装 Python 时,如果 Tkinter 模块并未生效,同样无法支持 TKINTER。
15.3.2 图像格式转换
图像文件的格式转换通过在 Image 类的 save 方法的传值参数中指定格式并保存来完成。下面,我们打开当前目录下名为 python.gif 的图像文件,将其转换为 JPEG 格式,并保存在 python_convert.jpg 文件中。具体代码如下。
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.gif')# 模式转换为RGBimage_rgb = image.convert('RGB')# 图像保存至文件image_rgb.save('python_convert.jpg', 'jpeg')if __name__ == '__main__':main()
可以看到,程序在读取完文件之后将图像模式转为了 RGB。
在 GIF 以及不足 256 色的 PNG、BMP 等格式中,颜色信息都保存在调色板数据块里。这类文件用 Pillow 打开时分为 P 模式(调色板模式)和 1 模式(单色模式)。另外,JPEG 文件有时还会是 CMYK 模式。当模式不支持 save 方法指定的格式时,程序会报错,所以要先用 convert 方法进行模式转换。
15.3.3 改变图像尺寸
如果想改变图像尺寸,可以使用 Image 类的 thumbnail 方法或 resize 方法。下面,我们打开当前目录下名为 python.jpg 的图像文件,将其长宽缩小一半后保存为 python_thumbnail.jpg,代码如 LIST 15.23 所示。
LIST 15.23 pil_thumbnail.py
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.jpg')# 计算图像长宽的一半half_size = (image.size[0] 2, image.size[1] 2)# 图像大小降为一半image.thumbnail(half_size, Image.ANTIALIAS)# 图像保存至文件image.save('python_thumbnail.jpg')if __name__ == '__main__':main()
Image 类的对象能够通过 size 属性以元组的形式获取图像的长和宽。
thumbanil 方法的第一个传值参数指定了图像长和宽的元组,第二个传值参数指定了滤镜 Image.ANTIALIAS。滤镜有 NEAREST、BILINER、BICUBIC、ANTIALIAS4 种可供选择,其中使用 ANTIALIAS 修改尺寸后的图像品质最高(损失最小)。
在执行 thumbnail 方法之后,会直接修改对象自身的图像大小。但是,这个方法只能用于长宽比例不变的修改。变更长宽比例时需要使用 resize 方法。下面,我们打开当前目录下名为 python.jpg 的图像文件,将其长度放大为 2 倍后保存为 python_resize.jpg,具体代码如 LIST 15.24 所示。
LIST 15.24 pil_resize.py
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.jpg')# 计算图像长度的2 倍double_size = (image.size[0], image.size[1] * 2)# 图像大小增加至2 倍image_resized = image.resize(double_size, Image.ANTIALIAS)# 图像保存至文件image_resized.save('python_resize.jpg')if __name__ == '__main__':main()
与 thumbnail 方法不同,resize 方法的返回值是修改尺寸后的 Image 类的对象。它同 thumbnail 一样,可以指定滤镜。图 15.1 和图 15.2 分别是修改尺寸之前的图像与执行完 LIST 15.24 所示的代码之后的图像。

图 15.1 修改尺寸之前的图像(python.jpg)

图 15.2 修改尺寸之后的图像(python_resize.jpg)
15.3.4 剪裁图像
Image 类的 crop 方法能够以长方形剪裁图像。下面,我们打开当前目录下名为 python.jpg 的图像文件,按照图像的宽度从正中间剪裁一个正方形并保存为 python_crop.jpg。
LIST 15.25 pil_crop.py
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.jpg')# 根据短边长度求中央正方形的坐标if image.size[0] < image.size[1]:# 横边较短时(瘦高的图像)crop_rect = (0,(image.size[1] - image.size[0]) 2,image.size[0],(image.size[1] - image.size[0]) 2 + image.size[0])else:# 竖边较短时(矮胖的图像)crop_rect = ((image.size[0] - image.size[1]) 2,0,(image.size[0] - image.size[1]) 2 + image.size[1],image.size[1])# 剪裁image_croped = image.crop(crop_rect)# 图像保存至文件image_croped.save('python_crop.jpg')if __name__ == '__main__':main()
crop 方法的传值参数是包含 4 个值的元组(Tuple),这 4 个值代表长方形剪裁区域的左上角坐标和右下角坐标。crop 的返回值为存有剪裁后图像的 Image 类对象。执行 LIST 15.25 中的代码后会得到如图 15.3 所示的结果。

图 15.3 剪裁后的图像(python_crop.jpg)
15.3.5 对图像进行滤镜处理
进行滤镜处理必须获取像素值。像素值可以用 Image 类的 getdata 方法或 getpixel 方法来获取。获取的像素值为包含 R(红)、G(绿)、B(蓝)3 个值的元组,3 个值的范围均为 0 ~ 255。下面,我们打开当前目录下名为 python.jpg 的图像文件,将所有像素反色并保存为 python_filter.jpg。
LIST 15.26 pil_filter.py
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.jpg')buffer = []# 循环逐一获取图像的像素for pixel in image.getdata():# 将像素反色并存入缓冲区buffer.append((255 - pixel[0],255 - pixel[1],255 - pixel[2]))# 用缓冲区内的像素覆盖原有数据image.putdata(buffer)# 图像保存至文件image.save('python_filter.jpg')if __name__ == '__main__':main()
getdata 方法能够返回一个迭代器,用于逐一访问图像的每一组像素值。在上例中,我们逐一取出了每个像素的像素值并进行反色(255 减去色值)。等所有像素值处理完毕之后,用 putdata 方法替换了 Image 类的对象的像素。LIST 15.26 的执行结果如图 15.4。

图 15.4 反色后的图像(python_filter.jpg)
如果要获取指定坐标的像素值,可以用 Image 类的 getpixel 方法。下面,我们打开当前目录下名为 python.jpg 的图像文件,将右上角的像素反色并保存为 python_pixel.jpg,具体代码如 LIST 15.27 所示。
LIST 15.27 pil_pixel.py
# coding: utf-8from PIL import Imagedef main():# 打开文件获取Image 对象image = Image.open('python.jpg')# 右上角的位置point = (image.size[0] - 1, 0)# 获取像素值pixel = image.getpixel(point)# 改写为反色的像素值image.putpixel(point, (255 - pixel[0],255 - pixel[1],255 - pixel[2]))# 图像保存至文件image.save('python_pixel.jpg')if __name__ == '__main__':main()
getpixel 方法的传值参数为含有横纵坐标(起点为 0)两个值的元组。改写指定位置像素值时使用了 putpixel 方法。这些方法的方便之处在于能够指定坐标,但是速度太慢,因此一旦需要大量使用,它们的效率并不见得比 getdata、putdata 等方法更高。
15.4 数据加密
在数据传输过程中,为防止数据被第三方获取或篡改,需要对数据进行加密。这里我们学习一下如何通过 PyCrypto 进行通用加密系统和公钥加密系统的加密及解密。
PyCrypto
15.4.1 安装 PyCrypto
如 LIST 15.28 所示,PyCrypto 的安装可以通过 pip 命令进行。由于它包含 C 语言编写的模块,所以安装时与 Pillow 一样需要 gcc 等编译器。各位可以事先用 apt 安装 python-dev 包和 build-essential 包。本书使用的是 PyCrypto 的 2.6.1 版本。
LIST 15.28 用 pip 命令安装 PyCrypto
$ pip install pycrypto==2.6.1
15.4.2 通用加密系统的加密及解密
通用加密系统在加密和解密时使用同一套密钥。AES、DES 等都属于通用加密算法。AES 的密码长度和块长都高于 DES,因此安全性较高。本书使用的就是 AES。
NOTE
DES(Data Encryption Standard)是1977 年被美国标准化的加密系统。
AES(Advanced Encryption Standard)是2011 年被美国标准化的加密系统。
以 AES 加密、解密时需要用到 PyCrypto 的 Crypto.Cipher.AES 类。下面我们用 PyCrypto 实现 AES 加密及解密,并将结果输出到屏幕上(LIST 15.29)。
LIST 15.29 aes_encrypt.py
# coding: utf-8from Crypto.Cipher import AESKEY = 'testtesttesttest' # 加密和解密时使用的通用密钥DATA = '0123456789123456' # 数据长度为16 的倍数def main():aes = AES.new(KEY) # 生成AES 类的实例encrypt_data = aes.encrypt(DATA) # 加密print repr(encrypt_data) # 输出至屏幕decrypt_data = aes.decrypt(encrypt_data) # 解密print repr(decrypt_data) # 输出至屏幕if __name__ == '__main__':main()
给 AES.new 函数指定用作密钥的字符串,生成 AES 对象。密钥可以是长度为 16、24、32 字符的任意字符串。数据通过 AES 对象的 encrypt 方法加密,通过 decrypt 方法解密。上述代码段的执行结果如 LIST 15.30 所示。
LIST 15.30 执行结果
$ python aes.py'\xf7\xf1\x0ccS\xef\x02\xe10\xf2\xe1\xd2\x80{\xcf\xfa''0123456789123456'
执行结果的第一条输出是加密状态的数据,第二条是将加密的二进制串解密后还原的数据。
15.4.3 公钥加密系统(RSA)的加密与解密
公钥加密系统在加密和解密时分别使用不同的密钥。RSA 等就是公钥加密算法。
NOTE
RSA 是 Ron Rivest、Adi Shamir、Len Adleman 于 1977 年发明的加密算法。
◉ RSA 私钥和公钥的生成
在公钥加密系统中,加密使用公钥(Public key),解密使用私钥(Private key)。这两种密钥都需要通过算法生成。公钥和私钥的密钥对可以通过 ssh-keygen 命令或 openssl 命令来创建,不过我们这里要学习的是用 PyCrypto 生成密钥的方法。下面,我们用 PyCrypto 生成 RSA 的密钥对,以 PEM 格式(RFC1421)输出到屏幕上,具体代码如下。
LIST 15.31 rsa_generate_keypair.py
# coding: utf-8from Crypto.PublicKey import RSAfrom Crypto import RandomINPUT_SIZE = 1024def main():random_func = Random.new().read # 产生随机数的函数key_pair = RSA.generate(INPUT_SIZE, random_func) # 生成密钥对private_pem = key_pair.exportKey() # 获取PEM 格式的私钥public_pem = key_pair.publickey().exportKey() # 获取PEM 格式的公钥print private_pem # 输出至屏幕print public_pem # 输出至屏幕if __name__ == '__main__':main()
LIST 15.31 用 RSA.generate 函数生成了 RSA 密钥对的对象,用 exportKey 方法获取了用作私钥的 PEM 格式的字符串。公钥则是先通过 publickey 方法获取对象,然后再用 exportKey 方法获取的。上述代码的执行结果如 LIST 15.32 所示。
LIST 15.32 执行结果
$ python rsa_generate_keypair.py-----BEGIN RSA PRIVATE KEY-----MIICXgIBAAKBgQDMYS234o1C1Z2fbeZazcUnEfspBcs06hSmvDji+Jm5Gk6tvIHlIFFu1aCD8kBbjf2ivzmG8Dgtcn6jnLjXe3EB0H1vh70TUsvi0ZjxZsmbv6fJmJrQzJvW1Wi3wnoBeVYQk6ha8rbfY35wErxxdTWeWm1nSBwaFfnRFYnrkqVGlQIDAQABAoGBAKJZ39Ne6A/bWOa4inA/XQl4QyeHLrDN8bGxew7xpEtiFnX0dMrqLUX59RRbb7xKwtxxQuVqFXYkqWyWpk6mBFGcRH1yH888Cgu+mSbsKvMAGOW/oTl7XLV8hc4Tm0iT/gEUsCHFcE6mstkUIEMlZCWmnuoijprDbehh1OSEZPQBAkEA1IFgXqMGIC/xCYwrizFgJVAa/o4IF183CocfqPaYlotKCeNovnPXeSCmAX1d0GhCHKBIQmkmL7YUTZ1DxiWL1QJBAPY2CWyA26GKGu1WzURJa7guizaqGJpghF30U5VdvdKmetYU2gXArhHQ9LxdjG09L9BWSxg5Y1Zl02b8f2Qf78ECQQCNr3VBpBCBhXWAmCSwOcuRFUfqUWizrJhWPKGvVjuGpHhI/4bm9PXFnS8R7zSNr/XkgDmtjc4YIZ6H4UM+6enBAkBiyC9jvxdfan9/NdJJUYPMc7AbEIeqeIri/0IBrYiZWX3zIo6OvE2ajFGEuau7sE7csaKTZ4L5iQUWTrv1ufKBAkEAis4KsI4Inxz01ZPRcmPlUVKULvVqyquqsfKP+NFGPTurYiXOc2kXPbBNxyhTDQ6Dw3OB0GhARHSGiuhQQicA2w==-----END RSA PRIVATE KEY----------BEGIN PUBLIC KEY-----MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDMYS234o1C1Z2fbeZazcUnEfspBcs06hSmvDji+Jm5Gk6tvIHlIFFu1aCD8kBbjf2ivzmG8Dgtcn6jnLjXe3EB0H1vh70TUsvi0ZjxZsmbv6fJmJrQzJvW1Wi3wnoBeVYQk6ha8rbfY35wErxxdTWeWm1nSBwaFfnRFYnrkqVGlQIDAQAB-----END PUBLIC KEY-----
在输出的字符串中,从 -----BEGIN RSA PRIVATE KEY----- 到 -----END RSA PRIVATE KEY----- 的部分为私钥,从 -----BEGIN PUBLIC KEY----- 到 -----END PUBLIC KEY----- 的部分为公钥。加密解密时就是使用这一对密钥。
◉ 用公钥加密
加密需要使用公钥。PyCrypto 可以使用我们输入的 PEM 格式的公钥字符串。下面,我们将字符串 Hello, world! 加密并输出到屏幕上(LIST 15.33)。
LIST 15.33 rsa_encrypt.py
# coding: utf-8from Crypto.PublicKey import RSAfrom Crypto import RandomDATA = 'Hello, world!'PUBLIC_KEY_PEM = """-----BEGIN PUBLIC KEY-----MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDMYS234o1C1Z2fbeZazcUnEfspBcs06hSmvDji+Jm5Gk6tvIHlIFFu1aCD8kBbjf2ivzmG8Dgtcn6jnLjXe3EB0H1vh70TUsvi0ZjxZsmbv6fJmJrQzJvW1Wi3wnoBeVYQk6ha8rbfY35wErxxdTWeWm1nSBwaFfnRFYnrkqVGlQIDAQAB-----END PUBLIC KEY-----"""def main():random_func = Random.new().read # 产生随机数的函数public_key = RSA.importKey(PUBLIC_KEY_PEM) # 输入PEM 格式的公钥encrypted = public_key.encrypt(DATA, random_func) # 加密数据print encrypted # 输出至屏幕if __name__ == '__main__':main()
这段代码用 RSA.importKey 函数输入公钥并获取了 RSA 对象,然后用 encrypt 方法进行加密。encrypt 方法的传值参数处指定了需要加密的数据以及产生随机数的函数。上述代码的执行结果如 LIST 15.34 所示。
LIST 15.34 执行结果
$ python rsa_encrypt.py('\x05 a\\\xb9U\x88/El\x1a\x02\xe6\xb4\xede\xf2\xe6\xe3\xa6&~\x9e\x180[K%i\x02k\xdd\xd5%\xfd\x1a\xc6\xd7\xc4\xa8\xcf\x86\x07\xdck\x7f\xb4\xb5_,I\x80\xe9\x83\x00*q\xce\xacA\x9a\xe3$]\xe5*\x9e\x91F\xd2\xe3P\xb8+\xa6\xc1R\xde\xf2G\xf1\x185\xcd\x8f\x82\x1a\xa4c\xf5\x9c\xd8\xe0\xd1g \xfdw\xa0\xe6\xca\xf7\x9f\xde\xbf(\xa2\xd5\xdb\xd5}\xe5\xaf\x99\xf9\x90\x1cx\n\xe8\xda\x14\x9cJ\xd7\xe4\x96S',)
◉ 用私钥解密
解密需要使用私钥。与加密时一样,这里也要输入 PEM 格式的字符串。下面,我们把前面加密的数据解密并显示在屏幕上,代码如 LIST 15.35 所示。
LIST 15.35 rsa_decrypt.py
# coding: utf-8from Crypto.PublicKey import RSADATA = ('\x05 a\\\xb9U\x88/El\x1a\x02\xe6\xb4\xede\xf2\xe6\xe3\xa6&~\x9e\x180[K%i\ x02k\xdd\xd5%\xfd\x1a\xc6\xd7\xc4\xa8\xcf\x86\x07\xdck\x7f\xb4\xb5_,I\x80\xe9\x83\x00*q\xce\xacA\x9a\xe3$]\xe5*\x9e\x91F\xd2\xe3P\xb8+\xa6\xc1R\xde\xf2G\xf1\x185\xcd\x8f\x82\x1a\xa4c\xf5\x9c\xd8\xe0\xd1g \xfdw\xa0\xe6\xca\xf7\x9f\xdexbf(\xa2\xd5\xdb\xd5}\xe5\xaf\x99\xf9\x90\x1cx\n\xe8\xda\x14\x9cJ\xd7\xe4\x96S',)PRIVATE_KEY_PEM = """-----BEGIN RSA PRIVATE KEY-----MIICXgIBAAKBgQDMYS234o1C1Z2fbeZazcUnEfspBcs06hSmvDji+Jm5Gk6tvIHlIFFu1aCD8kBbjf2ivzmG8Dgtcn6jnLjXe3EB0H1vh70TUsvi0ZjxZsmbv6fJmJrQzJvW1Wi3wnoBeVYQk6ha8rbfY35wErxxdTWeWm1nSBwaFfnRFYnrkqVGlQIDAQABAoGBAKJZ39Ne6A/bWOa4inA/XQl4QyeHLrDN8bGxew7xpEtiFnX0dMrqLUX59RRbb7xKwtxxQuVqFXYkqWyWpk6mBFGcRH1yH888Cgu+mSbsKvMAGOW/oTl7XLV8hc4Tm0iT/gEUsCHFcE6mstkUIEMlZCWmnuoijprDbehh1OSEZPQBAkEA1IFgXqMGIC/xCYwrizFgJVAa/o4IF183CocfqPaYlotKCeNovnPXeSCmAX1d0GhCHKBIQmkmL7YUTZ1DxiWL1QJBAPY2CWyA26GKGu1WzURJa7guizaqGJpghF30U5VdvdKmetYU2gXArhHQ9LxdjG09L9BWSxg5Y1Zl02b8f2Qf78ECQQCNr3VBpBCBhXWAmCSwOcuRFUfqUWizrJhWPKGvVjuGpHhI/4bm9PXFnS8R7zSNr/XkgDmtjc4YIZ6H4UM+6enBAkBiyC9jvxdfan9/NdJJUYPMc7AbEIeqeIri/0IBrYiZWX3zIo6OvE2ajFGEuau7sE7csaKTZ4L5iQUWTrv1ufKBAkEAis4KsI4Inxz01ZPRcmPlUVKULvVqyquqsfKP+NFGPTurYiXOc2kXPbBNxyhTDQ6Dw3OB0GhARHSGiuhQQicA2w==-----END RSA PRIVATE KEY-----"""def main():# 输入PEM 格式的私钥private_key = RSA.importKey(PRIVATE_KEY_PEM)# 解密数据decrypted = private_key.decrypt(DATA)# 输出至屏幕print decryptedif __name__ == '__main__':main()
与加密时一样,解密也是通过 RSA.importKey 函数输入私钥并获取 RSA 对象。接下来,我们在 decrypt 方法的传值参数中指定已加密的数据进行解密。上述代码的执行结果如 LIST 15.36 所示。
LIST 15.36 执行结果
$ python rsa_decrypt.pyHello, world!
NOTE
为了便于理解,上述例子都是直接在代码中描述公钥和私钥。实际使用时可以从密钥文件中读取密钥数据,从而提高效率。
15.5 使用 Twitter 的 API
随着 Twitter 在全世界推广,系统与 Twitter 联动的需求越来越常见。现在有不少封装了 Twitter API 的 Python 模块,这里我们以 tweepy 为例学习如何使用 tweepy 模块。tweepy 几乎涵盖了所有 Twitter API,而且能相对灵活地应对 Twitter API 自身的规格变更。下面我们用 Flask 和 tweepy 来简单做一个基于 Web 的时间轴视图。
tweepy
15.5.1 导入 tweepy
如 LIST 15.37 所示,通过 pip 命令安装 tweepy。本书使用了 tweepy 的 3.1.0 版本。
LIST 15.37 用 pip 命令安装 tweepy
$ pip install tweepy
15.5.2 添加应用与获取用户密钥
开发使用 Tiwtter 的 API 的应用时,需要将应用添加到 Twitter Application Management。下面我们来实际操作一下。如图 15.5 所示,Twitter Application Management 可以用 Twitter 账户登录。没有账户时需要新注册一个。登录后会进入 Twitter Apps 页面,该页上显示了所有已添加的应用。
Twitter Application Management
图 15.5 已添加应用的一览页面
添加新应用时,需要点击 Create New App 按钮进入添加页面,然后在该页面输入必填事项,如图 15.6 所示。
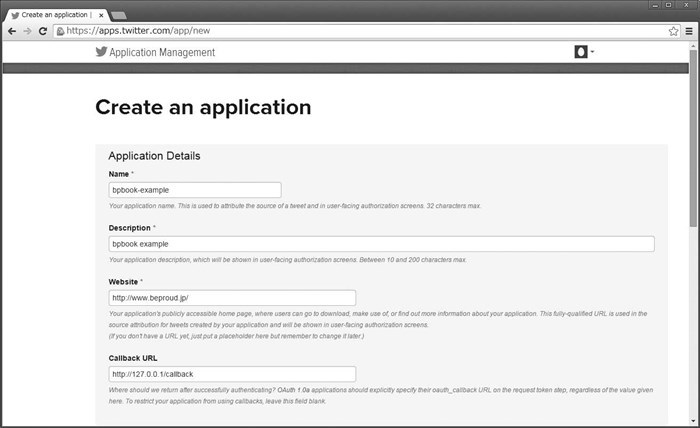
图 15.6 用于添加应用的页面
本书所用例子的输入如下。
| Name(应用名) | bpbook-example |
| Description(应用的说明) | bpbook example |
| WebSite(应用的 Web 站点) | http://www.beproud.jp/ |
| Callback URL(OAuth 认证后的回调 URL) | http://127.0.0.1:5000/callback |
| Yes, I agree(同意使用条款) | 勾选后同意使用条款 |
系统上比较重要的只有 Callback URL 的值。这里指定的是通过 Twitter 站点认证后重定向访问的应用的 URL。我们需要在之后开发的应用中实现这个 URL 的处理。输入所有项目后点击 Create your Twitter application,如果没有问题,系统会提示添加完成,并显示已添加应用的详细信息,如图 15.7 所示。
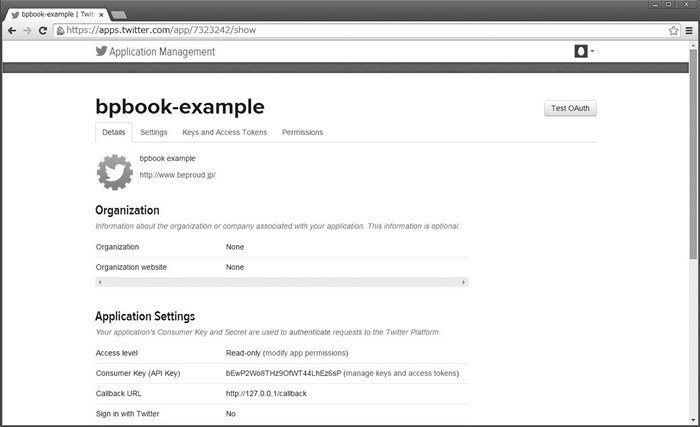
图 15.7 已添加应用的详细信息(添加完成时)
详细信息页面的 Keys and Access Tokens 标签页的 Application Settings 部分显示了 Consumer Key(用户密钥)和 Consumer Secret(用户机密)字符串。使用 Twitter 的 API 时需要用到这两个字符串以及下面即将学习的访问令牌和访问令牌机密。
Access Level 表示应用可以对用户数据做哪些操作,有 Read-only(只读)、Read and Write(可读写)、Read,Write and Access direct messages(可读写及访问私信)3 种操作可供选择。我们这里开发的时间轴视图只有读取操作,因此用 Read-only 就足够了。
15.5.3 获取访问令牌
OAuth 的访问令牌是为每一个使用应用的用户分别配发的值。可以通过已添加应用的详细信息页面为已添加应用的用户手动配发访问令牌。点击 Keys and Access Tokens 标签页下部的 Create my Access token 即可完成访问令牌的配发。点击 Regenerate My Access Token and Token Secret 可以作废已有令牌并重新配发新的。访问令牌以图 15.8 所示的字符串形式给出。我们将在应用中用到 Access Token(访问令牌)和 Access Token Secret(访问令牌机密)。
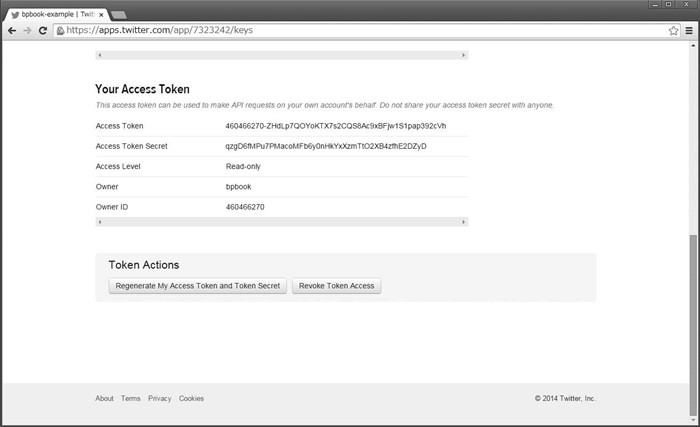
图 15.8 获取自己的访问令牌
如果应用只使用自己的 Twitter 账户,那么我们开发应用时只考虑上面获取的访问令牌即可。如果应用需要任意多个用户使用不同的 Twitter 账户,则需要使用基于 Web 的 Authorize URL 方式认证,从应用端获取访问令牌。我们即将开发的时间轴视图属于后者。
15.5.4 调用 Twitter API
用 tweepy 调用 Twitter API 时,需要用到 OAuthHandler 类和 API 类。下面,我们使用前面获取的用户密钥和访问令牌,获取 Twitter 主页上显示的时间轴,代码如 LIST 15.38 所示。
LIST 15.38 tweepy_hello.py
# coding: utf-8from tweepy import OAuthHandler, API# 用户密钥(本应用的)CONSUMER_KEY = 'Consumer key'CONSUMER_SECRET = 'Consumer secret'# 访问令牌(bpbook 用户的)ACCESS_TOKEN = 'Access token'ACCESS_TOKEN_SECRET = 'Access token secret'def main():# 生成OAuth 的handlerhandler = OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)# 给handler 设置访问令牌handler.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)# 生成API 实例api = API(handler)# 用API 获取时间轴statuses = api.home_timeline()for status in statuses:# 将获取的状态的前15 个字符输出到页面上print "%s: %s" % (status.user.screen_name, status.text[:15])if __name__ == '__main__':main()
请各位自行将上述代码中的 CONSUMER_KEY、CONSUMER_SECRET、ACCESS_TOKEN、ACCESS_TOKEN_SECRET 部分替换为前面获取的值。先在 OAuthHandler 类的构造函数中指定用户密钥和用户机密,然后用 OAuthHandler 的 set_access_token 方法给 handler 设置对应的访问令牌。在 API 类的构造函数中指定 handler 对象,让我们能够使用 API 调用。没有设置访问令牌的 handler 无法使用绝大多数的 API 调用。home_timeline 方法最多可以返回 20 条首页的时间轴信息。
上述代码的执行结果如 LIST 15.39 所示。
LIST 15.39 执行结果
$ python tweepy_hello.pybpbook: 测试liblar_jp: 【有关添加功能的通知】书籍相关connpass_jp: 【有关功能修改的通知】多天以来liblar_jp:【有关维护工作已全面结束的通知】beproud_jp: BePROUD 公司现在就Web(以下省略)
发生 TweepError: HTTP Error 401: Unauthorized 错误时,需要查看用户密钥和访问令牌是否有误。另外,执行环境的系统时间与实际时间不一致也会导致这个错误。
除 home_timeline 之外,还有许多方法封装了 API。详细内容可以查看 tweepy 文档的 API Reference 来了解。
tweepy API Reference
在这个例子中,我们是直接在代码中描述访问令牌(ACCESS_TOKEN、ACCESS_TOKEN_SECRET)的。对于只通过单一用户获取时间轴信息或进行发言的应用(比如 TwitterBot 等)而言,由于不需要用于认证的 UI,所以使用这种方法不会有问题。
15.5.5 编写用 Twitter 认证的系统
下面我们编写一个用 Twitter 账户登录(认证)并根据各 Twitter 账户的权限使用 API 的系统。编写这个系统中需要用到 Twitter 的认证页面,还要获取各个账户的访问令牌。从登录的起始处理到使用 API 的处理流程如下所示。
① 用户通过 Web 浏览器访问应用的登录 URL
② 应用从 Twitter 获取请求令牌
③ 应用将获取到的请求令牌保存在会话中
④ 应用向 Twitter 的认证 URL 返回带有令牌属性的重定向响应
⑤ 用户通过 Web 浏览器在 Twitter 的认证页面对应用授权
⑥ 用户根据 Twitter 端的重定向响应,通过 Web 浏览器访问应用的回调 URL(带有令牌属性)
⑦ 应用从会话中还原请求令牌
⑧ 应用从 Twitter 获取用户的访问令牌
⑨ 应用依据访问令牌使用 Twitter 的 API
使用 tweepy 可以轻松完成①的生成带属性的 URL、②的获取令牌、⑨的依据访问令牌使用 Twitter API。下面我们看一下 web 应用,它使用 Flask 和 tweepy 对 Twitter 账户进行认证,然后获取时间轴信息并使之显示在页面上,代码如 LIST 15.40 所示。
LIST 15.40 tweepy_auth.py
# coding: utf-8from flask import Flask, render_template, session, request, redirectfrom tweepy import OAuthHandler, APIapplication = Flask(__name__)# 设置用于会话的密钥application.secret_key = 'my secret key'# 用户密钥CONSUMER_KEY = 'Consumer key'CONSUMER_SECRET = 'Consumer secret'def get_access_token():""" 从会话获取访问令牌的函数"""return session.get('access_token')def set_access_token(access_token):""" 在会话中保存访问令牌的函数"""session['access_token'] = access_tokendef get_request_token(key):""" 从会话获取请求令牌的函数"""return session.get(key)def set_request_token(key, token):""" 在会话中保存请求令牌的函数"""session[key] = tokendef get_oauth_handler():""" 返回Tweepy 的OAuth handler 的函数"""return OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)def get_api(access_token):""" 指定访问令牌返回API 实例的函数"""handler = get_oauth_handler()handler.set_access_token(access_token[0], access_token[1])api = API(handler)return apidef set_user(user):""" 在会话中保存用户信息的函数"""# 以可JSON 序列化的字典对象格式保存在会话中session['user'] = {'screen_name': user.screen_name}def get_user():""" 从会话获取用户信息的函数"""return session.get('user')def is_login():""" 返回是否为登录状态"""return not not get_access_token()def clear_session():""" 删除会话的值"""session.clear()@application.route('')def index():""" 首页使用模板显示页面"""# 根据模板显示页面return render_template('index.html', is_login=is_login(), user=get_user())@application.route('login')def login():""" 登录URL开始Twitter 认证"""handler = get_oauth_handler()# 获取认证URLauth_url = handler.get_authorization_url()# 请求令牌保存在会话中set_request_token(handler.request_token['oauth_token'],handler.request_token['oauth_token_secret'])# 重定向到认证URLreturn redirect(auth_url)@application.route('callback')def callback():""" 回调URLTwitter 认证后的回调URL"""# 用GET 方法获取OAuth 的回调属性oauth_token = request.args.get('oauth_token')oauth_verifier = request.args.get('oauth_verifier')# 取消时重定向到首页if not oauth_token and not oauth_verifier:return redirect('')# 获取OAuth 的handlerhandler = get_oauth_handler()# 从会话获取请求令牌并设置给handlerrequest_token = get_request_token(oauth_token)handler.request_token = {'oauth_token': oauth_token,'oauth_token_secret': request_token,}# 获取访问令牌access_token = handler.get_access_token(oauth_verifier)# 将访问令牌保存在会话中set_access_token(access_token)# 获取API 实例api = get_api(access_token)# 获取登录用户的信息并保存至会话set_user(api.me())# 重定向到首页return redirect('')@application.route('logout')def logout():""" 登出URL从会话中删除登录状态的信息"""# 删除会话中的登录信息clear_session()# 重定向到首页return redirect('')@application.route('timeline')def timeline():""" 显示时间轴信息的页面需要认证"""# 获取登录状态if not is_login():# 没有登录则重定向到首页return redirect('')# 从会话获取访问令牌access_token = get_access_token()if not access_token:# 无法获取访问令牌时# 清除会话并重新开始clear_session()return redirect('')# 获取API 实例api = get_api(access_token)# 调用Twitter API 获取时间轴信息statuses = api.home_timeline()# 通过模板显示页面return render_template('timeline.html', statuses=statuses)if __name__ == '__main__':# 通过IP 地址127.0.0.1 的5000 端口执行应用application.run('127.0.0.1', 5000, debug=True)
其中,CONSUMER_KEY、CONSUMER_SECRET 的值需要替换成之前为应用获取的值。在上面的例子中,我们用 Flask 的会话保存了请求令牌。该段代码使用了 index.html 和 timeline.html 两个模板文件,这两个文件保存在 templates 目录下,其内容如 LIST 15.41 所示。
LIST 15.41 templates/index.html
<html><head><meta http-equiv="Contenttype" content="text/html; charset=utf-8" ><title>Twitter 认证<title></head><body>{% if is_login %}<p> 登录名: {{ user.screen_name }}</p><ul><li><a href="timeline"> 获取时间轴信息<a></li><li><a href="logout"> 登出<a></li></ul>{% else %}<ul><li><a href="login"> 登录<a></li></ul>{% endif %}</body></html>
index.html 在未认证状态下显示开始认证处理的 URL 链接,在已认证状态下则显示 Twitter 的昵称(登录名)、获取时间轴信息的处理以及登出处理的链接(LIST 15.42)。
LIST 15.42 templates/timeline.html
<html><head><meta http-equiv="Contenttype" content="text/html; charset=utf-8" ><title> 时间轴信息的显示<title></head><body><dl>{% for status in statuses %}<dt>{{ status.user.screen_name }}</dt><dd>{{ status.text }}</dd>{% endfor %}</dl></body></html>
timeline.html 用来显示获取到的时间轴信息(状态)。准备好源码及模板后,用 python 命令执行 tweepy_auth.py 启动服务器,代码如 LIST 15.43 所示。
LIST 15.43 用 python 命令执行 tweepy_auth.py
$ python tweepy_auth.pyRunning on http://127.0.0.1:5000/Restarting with reloader
NOTE
本例是用 5000 端口启动开发服务器的,因此请保证 SSH 隧道的主 OS 与客 OS 的 5000 端口相连接。
启动服务器后,打开 Web 浏览器试着访问 http://127.0.0.1:5000/。刚开始时我们处于未登录状态,所以会显示有登录链接的页面。点击登录连接,随后将跳转至 Twitter 的认证页面,我们会看到如图 15.9 所示的应用授权请求信息以及按钮。
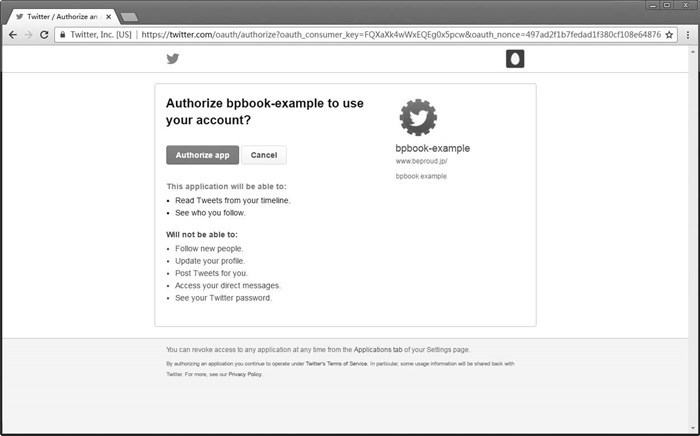
图 15.9 Twitter 的应用授权页面
点击页面中的授权按钮之后,页面将重定向到我们添加应用时填写的 Callback URL,处理也将返回到应用端。获取访问令牌和个人信息后,应用显示带有用户名、获取时间轴信息链接以及登出链接的登录状态界面。我们点击获取时间轴信息的链接之后,应用会使用用户的访问令牌获取时间轴信息并显示在页面上。至此,时间轴视图的应用开发完毕。
NOTE
这里介绍的时间轴视图是将访问令牌保存了在会话中,会话一旦过期就需要重新获取令牌。我们可以通过将访问令牌存放在数据库中来避免这一问题。
15.6 使用REST API
系统间协作及使用外部服务时,经常会用 REST API 作接口。REST API 可以用 Python 标准模块 urllib 和 json 来控制,不过本书要讲的是 Requests 的使用方法。
Requests: HTTP for Humans
15.6.1 REST 简介
REST(Representational state transfer,具象状态传输 1)是一种软件架构。它于 2000 年由 Roy Fielding 提出,是几种软件设计原则的集合。
1有时也被译为表述性状态转移或表述性状态传输等。——译者注
不过,现在人们广泛使用的 REST 和 REST API 通常指“在 HTTP 上运行的非 SOAP 非 RPC 的 API”。
REST API 的特征如下。
在 HTTP 上运行
数据被称为“资源”
REST API 可使用的资源具有唯一的 URL
GET/POST/PUT/DELETE 等 HTTP 方法分别对应资源的获取 保存 覆盖 / 删除等操作
通过 JSON、XML 等格式收发数据
请求成功、请求失败等处理结果体现在状态代码中
如果要使用 REST API,则需要用到 HTTP 客户端。在 shell 命令或 shell 脚本中使用时要用 curl,在程序中使用时则要用 HTTP 客户端程序库。
REST - Wikipedia
http://zh.wikipedia.org/wiki/REST
Fielding Dissertation CHAPTER 5 Representational State Transfer (REST)
http://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
15.6.2 导入 Requests
如 LIST 15.44 所示,用 pip 命令安装 Requests。本书使用的是 Requests 的 2.5.0 版本。
LIST 15.44 用 pip 命令安装 Requests
$ pip install requests
15.6.3 导入测试服务器
要检查 Requests 模块的运行状况就必须使用 Web 服务器。httpbin 模块是基于 Python 开发的 HTTP 测试服务器。本书将用 httpbin 模块作为测试服务器来讲解 Requests 的使用方法。
如 LIST 15.45 所示,用 pip 命令安装 httpbin。本书使用的是 httpbin 的 0.2.0 版本。
LIST 15.45 用 pip 命令安装 httpbin
$ pip install httpbin
httpbin 的测试服务器用 LIST 15.46 中的命令启动。
LIST 15.46 启动 httpbin 的测试服务器
$ python -m httpbin.core* Running on http://127.0.0.1:5000/
在导入 Requests 模块之前,先用 curl 命令检查测试服务器的运行状况。
在测试服务器已启动的状态下运行 LIST 15.47。如果运行正常,屏幕上将显示如下所示的 JSON 格式报告。
LIST 15.47 用 curl 命令检查测试服务器的运行状况
$ curl "http://127.0.0.1:5000/get?foo=bar" # 向测试服务器发送GET 请求{"args": { # args 为GET 参数"foo": "bar"},"headers": {"Accept": "/","Content-Length": "","ContentType": "","Host": "127.0.0.1:5000","User-Agent": "curl/7.35.0"},"origin": "127.0.0.1","url": "http://127.0.0.1:5000/get?foo=bar"}$ curl -X post -d foo=bar http://127.0.0.1:5000/post # 向测试服务器发送POST 请求{"args": {},"data": "", # data 为发送数据的正文(未经过编码的表单数据除外)"files": {}, # files 为被上传的文件"form": { # form 为经过编码的表单数据"foo": "bar"},"headers": {"Accept": "/","Content-Length": "7","ContentType": "application/x-www-form-urlencoded","Host": "127.0.0.1:5000","User-Agent": "curl/7.35.0"},"json": null,"origin": "127.0.0.1","url": "http://127.0.0.1:5000/post"}
可以看出,测试服务器具有将请求的内容以 JSON 格式返回的功能。
NOTE
在 Windows 上使用curl 命令时需要安装命令工具。
cURL - Download
15.6.4 发送GET 请求
用 Requests 发送 GET 请求,具体代码如 LIST 15.48 所示。
LIST 15.48 requests_get.py
# coding: utf-8import pprintimport requestsdef main():# GET 参数以字典形式通过params 传值参数指定response = requests.get('http://127.0.0.1:5000/get',params={'foo': 'bar'})# 使用响应对象的json 方法可以获取转换为Python 字典对象的JSON 数据pprint.pprint(response.json())if __name__ == '__main__':main()
在 requests.get 函数中指定对象 URL,用 params 关键字传值参数指定 GET 参数。服务器返回的响应为 JSON 格式,因此要用 json 方法将其转换为字典形式再显示到页面上。上述代码的执行结果如 LIST 15.49 所示。
LIST 15.49 执行结果
$ python requests_get.py{u'args': {u'foo': u'bar'},u'headers': {u'Accept': u'/',u'Accept-Encoding': u'gzip, deflate',u'Connection': u'keep-alive',u'Content-Length': u'',u'ContentType': u'',u'Host': u'127.0.0.1:5000',u'User-Agent': u'python-requests/2.5.0 CPython/2.7.8 Linux/3.13.0-35-generic'},u'origin': u'127.0.0.1',u'url': u'http://127.0.0.1:5000/get?foo=bar'}
15.6.5 发送 POST 请求
用 Requests 发送 POST 请求,具体代码如 LIST 15.50 所示。
LIST 15.50 requests_post.py
# coding: utf-8import pprintimport requestsdef main():# POST 参数以字典形式通过第二个传值参数指定response = requests.post('http://127.0.0.1:5000/post',{'foo': 'bar'})# 使用响应对象的json 方法可以获取转换为Python 字典对象的JSON 数据pprint.pprint(response.json())if __name__ == '__main__':main()
request.post 函数中指定了对象 URL 和 POST 参数。给 POST 参数指定的字典会被编码为 URL 发送出去。这段代码的执行结果如 LIST 15.51 所示。
LIST 15.51 执行结果
$ python requests_post.py{u'args': {},u'data': u'',u'files': {},u'form': {u'foo': u'bar'},u'headers': {u'Accept': u'/',u'Accept-Encoding': u'gzip, deflate',u'Connection': u'keep-alive',u'Content-Length': u'7',u'ContentType': u'application/x-www-form-urlencoded',u'Host': u'127.0.0.1:5000',u'User-Agent': u'python-requests/2.5.0 CPython/2.7.8 Linux/3.13.0-35-generic'},u'json': None,u'origin': u'127.0.0.1',u'url': u'http://127.0.0.1:5000/post'}
15.6.6 发送 JSON 格式的 POST 请求
有些 API 接口要求直接发送 JSON 格式的字符串,不能将数据编码为 URL。用 Requests 以 JSON 格式字符串的形式发送 POST 请求,具体代码如 LIST 15.52 所示。
LIST 15.52 requests_post_json.py
# coding: utf-8import pprintimport jsonimport requestsdef main():# 指定json.dumps 生成的字符串之后,可以直接发送数据而不进行URL 编码# 需要明确指定Content-Tpyeresponse = requests.post('http://127.0.0.1:5000/post',json.dumps({'foo': 'bar'}),headers={'ContentType': 'application/json'})pprint.pprint(response.json())if __name__ == '__main__':main()
post 函数的传值参数中指定的发送数据为字符串。传值参数指定字符串时会直接发送数据,不进行 URL 编码。这段代码的执行结果如 LIST 15.53 所示。
LIST 15.53 执行结果
$ python requests_post_json.py{u'args': {},u'data': u'{"foo": "bar"}',u'files': {},u'form': {},u'headers': {u'Accept': u'/',u'Accept-Encoding': u'gzip, deflate',u'Connection': u'keep-alive',u'Content-Length': u'14',u'ContentType': u'application/json',u'Host': u'127.0.0.1:5000',u'User-Agent': u'python-requests/2.5.0 CPython/2.7.8 Linux/3.13.0-35-generic'},u'json': {u'foo': u'bar'},u'origin': u'127.0.0.1',u'url': u'http://127.0.0.1:5000/post'}
15.6.7 使用 GET/POST 之外的 HTTP 方法
某些 API 还会用到 GET、POST 之外的 HTTP 方法(PUT、DELETE、HEAD、OPTIONS)。Requests 同样为这些方法准备了对应的函数,代码如 LIST 15.54 所示。
LIST 15.54 requests_other_methods.py
# coding: utf-8import requestsdef main():requests.put('http://127.0.0.1:5000/put', {'foo': 'bar'}) # PUTrequests.delete('http://127.0.0.1:5000/delete') # DELETErequests.head('http://127.0.0.1:5000/get') # HEADrequests.options('http://127.0.0.1:5000/options') # OPTIONSif __name__ == '__main__':main()
执行了这段代码之后,程序会向服务器发送 HTTP 的 PUT、DELETE、HEAD、OPTIONS 方法的请求,获取响应后执行结束。
可见,用 Requests 可以轻松使用以 HTTP 为接口的 REST API。
15.7 小结
在开发应用的过程中,我们多少都会遇到些难题,而方便好用的模块往往是解决难题的方法之一。本章介绍了几个开发中的难题以及解决相应难题的 Python 模块。希望各位多多利用本书以及其他各种信息来源,收集难题的解决方案以及好用模块的信息。多了解一些可以拿来就用的模块是大幅缩短开发时间的有效途径。
