汇总和计算描述统计
pandas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series。跟对应的NumPy数组方法相比,它们都是基于没有缺失数据的假设而构建的。接下来看一个简单的DataFrame:
- In [198]: df = DataFrame([[1.4, np.nan], [7.1, -4.5],
- ...: [np.nan, np.nan], [0.75, -1.3]],
- ...: index=['a', 'b', 'c', 'd'],
- ...: columns=['one', 'two'])
- In [199]: df
- Out[199]:
- one two
- a 1.40 NaN
- b 7.10 -4.5
- c NaN NaN
- d 0.75 -1.3
调用DataFrame的sum方法将会返回一个含有列小计的Series:
- In [200]: df.sum()
- Out[200]:
- one 9.25
- two -5.80
传入axis=1将会按行进行求和运算:
- In [201]: df.sum(axis=1)
- Out[201]:
- a 1.40
- b 2.60
- c NaN
- d -0.55
NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能:
- In [202]: df.mean(axis=1, skipna=False)
- Out[202]:
- a NaN
- b 1.300
- c NaN
- d -0.275
表5-9列出了这些约简方法的常用选项。

有些方法(如idxmin和idxmax)返回的是间接统计(比如达到最小值或最大值的索引):
- In [203]: df.idxmax()
- Out[203]:
- one b
- two d
另一些方法则是累计型的:
- In [204]: df.cumsum()
- Out[204]:
- one two
- a 1.40 NaN
- b 8.50 -4.5
- c NaN NaN
- d 9.25 -5.8
还有一种方法,它既不是约简型也不是累计型。describe就是一个例子,它用于一次性产生多个汇总统计:
- In [205]: df.describe()
- Out[205]:
- one two
- count 3.000000 2.000000
- mean 3.083333 -2.900000
- std 3.493685 2.262742
- min 0.750000 -4.500000
- 25% 1.075000 -3.700000
- 50% 1.400000 -2.900000
- 75% 4.250000 -2.100000
- max 7.100000 -1.300000
对于非数值型数据,describe会产生另外一种汇总统计:
- In [206]: obj = Series(['a', 'a', 'b', 'c'] * 4)
- In [207]: obj.describe()
- Out[207]:
- count 16
- unique 3
- top a
- freq 8
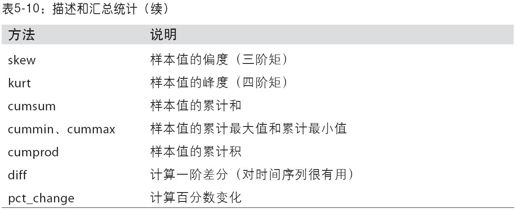
表5-10列出了所有与描述统计相关的方法。

相关系数与协方差
有些汇总统计(如相关系数和协方差)是通过参数对计算出来的。我们来看几个DataFrame,它们的数据来自Yahoo!Finance的股票价格和成交量:
- import pandas.io.data as web
- all_data = {}
- for ticker in ['AAPL', 'IBM', 'MSFT', 'GOOG']:
- all_data[ticker] = web.get_data_yahoo(ticker, '1/1/2000', '1/1/2010')
- price = DataFrame({tic: data['Adj Close']
- for tic, data in all_data.iteritems()})
- volume = DataFrame({tic: data['Volume']
- for tic, data in all_data.iteritems()})
接下来计算价格的百分数变化:
- In [209]: returns = price.pct_change()
- In [210]: returns.tail()
- Out[210]:
- AAPL GOOG IBM MSFT
- Date
- 2009-12-24 0.034339 0.011117 0.004420 0.002747
- 2009-12-28 0.012294 0.007098 0.013282 0.005479
- 2009-12-29 -0.011861 -0.005571 -0.003474 0.006812
- 2009-12-30 0.012147 0.005376 0.005468 -0.013532
- 2009-12-31 -0.004300 -0.004416 -0.012609 -0.015432
Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差:
- In [211]: returns.MSFT.corr(returns.IBM)
- Out[211]: 0.49609291822168838
- In [212]: returns.MSFT.cov(returns.IBM)
- Out[212]: 0.00021600332437329015
DataFrame的corr和cov方法将以DataFrame的形式返回完整的相关系数或协方差矩阵:
- In [213]: returns.corr()
- Out[213]:
- AAPL GOOG IBM MSFT
- AAPL 1.000000 0.470660 0.410648 0.424550
- GOOG 0.470660 1.000000 0.390692 0.443334
- IBM 0.410648 0.390692 1.000000 0.496093
- MSFT 0.424550 0.443334 0.496093 1.000000
- In [214]: returns.cov()
- Out[214]:
- AAPL GOOG IBM MSFT
- AAPL 0.001028 0.000303 0.000252 0.000309
- GOOG 0.000303 0.000580 0.000142 0.000205
- IBM 0.000252 0.000142 0.000367 0.000216
- MSFT 0.000309 0.000205 0.000216 0.000516
利用DataFrame的corrwith方法,你可以计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算):
- In [215]: returns.corrwith(returns.IBM)
- Out[215]:
- AAPL 0.410648
- GOOG 0.390692
- IBM 1.000000
- MSFT 0.496093
传入一个DataFrame则会计算按列名配对的相关系数。这里,我计算百分比变化与成交量的相关系数:
- In [216]: returns.corrwith(volume)
- Out[216]:
- AAPL -0.057461
- GOOG 0.062644
- IBM -0.007900
- MSFT -0.014175
传入axis=1即可按行进行计算。无论如何,在计算相关系数之前,所有的数据项都会按标签对齐。
唯一值、值计数以及成员资格
还有一类方法可以从一维Series的值中抽取信息。以下面这个Series为例:
- In [217]: obj = Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
第一个函数是unique,它可以得到Series中的唯一值数组:
- In [218]: uniques = obj.unique()
- In [219]: uniques
- Out[219]: array([c, a, d, b], dtype=object)
返回的唯一值是未排序的,如果需要的话,可以对结果再次进行排序(uniques.sort())。value_counts用于计算一个Series中各值出现的频率:
- In [220]: obj.value_counts()
- Out[220]:
- c 3
- a 3
- b 2
- d 1
为了便于查看,结果Series是按值频率降序排列的。value_counts还是一个顶级pandas方法,可用于任何数组或序列:
- In [221]: pd.value_counts(obj.values, sort=False)
- Out[221]:
- a 3
- b 2
- c 3
- d 1
最后是isin,它用于判断矢量化集合的成员资格,可用于选取Series中或DataFrame列中数据的子集:
- In [222]: mask = obj.isin(['b', 'c'])
- In [223]: mask In [224]: obj[mask]
- Out[223]: Out[224]:
- 0 True 0 c
- 1 False 5 b
- 2 False 6 b
- 3 False 7 c
- 4 False 8 c
- 5 True
- 6 True
- 7 True
- 8 True
表5-11给出了这几个方法的一些参考信息。

有时,你可能希望得到DataFrame中多个相关列的一张柱状图。例如:
- In [225]: data = DataFrame({'Qu1': [1, 3, 4, 3, 4],
- ...: 'Qu2': [2, 3, 1, 2, 3],
- ...: 'Qu3': [1, 5, 2, 4, 4]})
- In [226]: data
- Out[226]:
- Qu1 Qu2 Qu3
- 0 1 2 1
- 1 3 3 5
- 2 4 1 2
- 3 3 2 4
- 4 4 3 4
将pandas.value_counts传给该DataFrame的apply函数,就会出现:
- In [227]: result = data.apply(pd.value_counts).fillna(0)
- In [228]: result
- Out[228]:
- Qu1 Qu2 Qu3
- 1 1 1 1
- 2 0 2 1
- 3 2 2 0
- 4 2 0 2
- 5 0 0 1
