附录A Python语言精要
知识是一座宝库,而实践就是开启这座宝库的钥匙。
——Thomas Fuller
人们常常问我要有关学习Python数据处理方面的优质资源。虽然市面上有许多非常不错的讲解Python语言的图书,但我在推荐的时候经常还是会犹豫不决,因为它们都是针对普通读者的,没有为那些只想“加载点儿数据,做点计算,再画点儿图”的读者做专门的裁剪。其实有几本书确实是关于Python科学计算编程的,但它们是专为数值计算和工程应用而设计的:解微分方程、计算积分、做蒙特卡罗模拟,以及其他各种数学方面的主题,但就是没有数据分析和统计方面的。由于本书的目的是让大家成为Python数据处理方面的熟手,所以我认为有必要花点时间从结构化和非结构化数据处理的角度重点介绍一些有关Python内置数据结构和库的最重要的功能。我将只介绍一些大致的信息,只要对本书的学习够用就行。
本附录并没有打算成为Python语言的详尽指南,只会对书中反复用到的那些功能做一个基本的概述。对于Python新手而言,我建议在读完本附录后再看看Python的官方教程(http://docs.python.org),最好能再读一两本有关Python通用编程方面的优质图书。以我的观点来看,如果只需要用Python进行高效的数据分析工作,根本就没必要非得成为通用软件编程方面的专家不可。我强烈建议你用IPython实验所有的代码示例,并查看各种类型、函数以及方法的文档。注意,这些例子中所用到的一些代码暂时还没必要解释得那么详细。
本书主要关注的是能够处理大数据集的高性能数组计算工具。为了使用这些工具,你常常得先把那些乱七八糟的数据处理成漂亮点的结构化形式。好在Python是一种最易上手的数据整形语言。你的Python语言能力越强,数据分析的准备工作就越简单。
Python解释器
Python是一种解释型语言。Python解释器是通过“一次执行一条语句”的方式运行程序的。标准的交互式Python解释器可以在命令行上通过python命令启动:
- $ python
- Python 2.7.2 (default, Oct 4 2011, 20:06:09)
- [GCC 4.6.1] on linux2
- Type "help", "copyright", "credits" or "license" for more information.
- >>> a = 5
- >>> print a
- 5
上面的">>>"是提示符,你可以在那里输入表达式。要退出Python解释器并返回命令提示符,输入exit()或按下Ctrl-D即可。
运行Python程序的方式很简单,只需调用python并将一个.py文件作为其第一个参数即可。假设我们已经创建了一个hello_world.py,其内容如下:
- print 'Hello world'
只需在终端上输入如下命令即可运行:
- $ python hello_world.py
- Hello world
虽然许多Python程序员用这种方式执行他们的所有Python代码,但Python科学计算程序员则更趋向于使用IPython(一种加强的交互式Python解释器)。第3章专门介绍了IPython系统。通过使用%run命令,IPython会在同一个进程中执行指定文件中的代码。因此,在这些代码执行完毕之后,你就可以通过交互的方式研究其结果了。
- $ ipython
- Python 2.7.2 |EPD 7.1-2 (64-bit)| (default, Jul 3 2011, 15:17:51)
- Type "copyright", "credits" or "license" for more information.
- IPython 0.12 -- An enhanced Interactive Python.
- ? -> Introduction and overview of IPython's features.
- %quickref -> Quick reference.
- help -> Python's own help system.
- object? -> Details about 'object', use 'object??' for extra details.
- In [1]: %run hello_world.py
- Hello world
- In [2]:
默认的IPython提示符采用的是一种编号的风格(如In [2]:),而不是标准的">>>"提示符。
基础知识
语言语义
Python语言的设计特点是重视可读性、简洁性以及明确性。有些人甚至将它看做“可执行的伪码”。
缩进,而不是大括号
Python是通过空白符(制表符或空格)来组织代码的,不像其他语言(如R、C++、Java、Perl等)用的是大括号。以for循环为例,要实现前面说的那个快速排序算法:
- for x in array:
- if x < pivot:
- less.append(x)
- else:
- greater.append(x)
冒号表示一段缩进代码块的开始,其后的所有代码都必须缩进相同的量,直到代码块结束为止。在别的语言中,你可能会看到下面这样的东西:
- for x in array {
- if x < pivot {
- less.append(x)
- } else {
- greater.append(x)
- }
- }
使用空白符的主要好处是,它能使大部分Python代码在外观上看起来差不多。也就是说,当你阅读某段不是自己编写的(或一年前匆忙编写的)代码时不怎么容易出现“认知失调”。在那些空白符无实际意义的语言中,你可能会发现一些格式不统一的代码,比如:
- for x in array
- {
- if x < pivot
- {
- less.append(x)
- }
- else
- {
- greater.append(x)
- }
- }
无论对它是爱是恨,反正有意义的空白符就是Python程序员的生活现实。再说了,以我的经验来看,它能使Python代码具有更高的可读性(至少比我用过其他语言要高)。虽然第一眼看上去会觉得比较火星,但我相信不用多久你就会喜欢上它的。
注意: 我强烈建议用4个空格作为默认缩进量,这样,你的编辑器就会将制表符替换为4个空格。许多文本编辑器都有一个这样的设置项。有些人喜欢用制表符或其他数量的空格,但用2个空格的情况非常少见。4个空格其实就是一种标准,绝大部分Python程序员都这么用。所以我建议:除非有特殊的原因,否则就用4个空格吧。
到目前为止,你可以看到,Python语句还能不以分号结束。不过分号还是可以用的,比如在一行上分隔多条语句:
- a = 5; b = 6; c = 7
在一行上放置多条语句的做法在Python中一般是不推荐的,因为这往往会使代码的可读性变差。
万物皆对象
Python语言的一个重要特点就是其对象模型的一致性。Python解释器中的任何数值、字符串、数据结构、函数、类、模块等都待在它们自己的“盒子”里,而这个“盒子”也就是Python对象。每个对象都有一个与之相关的类型(比如字符串或函数)以及内部数据。在实际工作当中,这使得Python语言变得非常灵活,因为即使是函数也能被当做其他对象那样处理。
注释
任何前缀为井号(#)的文本都会被Python解释器忽略掉。这通常用于在代码中添加注释。有时你可能只是想排除不运行某些代码块而不想删除它们。最简单的办法就是注释掉那些代码:
- results = []
- for line in file_handle:
- # 暂时保留空行
- # if len(line) == 0:
- # continue
- results.append(line.replace('foo', 'bar'))
函数调用和对象方法调用
函数的调用需要用到圆括号以及0个或多个参数,此外还可以将返回值赋值给一个变量:
- result = f(x, y, z)
- g()
几乎所有的Python对象都有一些附属函数(也就是方法),它们可以访问该对象的内部数据。方法的调用是这样写的:
- obj.some_method(x, y, z)
函数既可以接受位置参数,也可以接受关键字参数:
- result = f(a, b, c, d=5, e='foo')
稍后将详细介绍这个内容。
变量和按引用传递
在Python中对变量赋值时,你其实是在创建等号右侧对象的一个引用。用实际的例子来说吧,看看下面这个整数列表:
- In [241]: a = [1, 2, 3]
假如我们将a赋值给一个新变量b:
- In [242]: b = a
在某些语言中,该赋值过程将会导致数据[1,2,3]被复制。而在Python中,a和b现在都指向同一个对象,即原始列表[1,2,3](如图A-1所示)。你可以自己验证一下:对a添加一个元素,然后看看b的情况。
- In [243]: a.append(4)
- In [244]: b
- Out[244]: [1, 2, 3, 4]
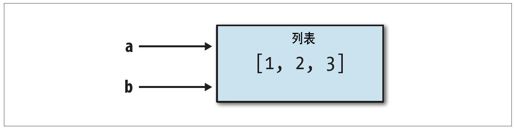
图A-1:指向同一个对象的两个引用
理解Python引用的语义以及数据复制的条件、方式、原因等知识对于在Python中处理大数据集非常重要。
注意: 赋值(assignment)操作也叫做绑定(binding),因为我们其实是将一个名称和一个对象绑定到一起。已经赋过值的变量名有时也被称为已绑定变量(bound variable)。
当你将对象以参数的形式传入函数时,其实只是传入了一个引用而已,不会发生任何复制。因此,Python被称为是按引用传递的,而某些其他的语言则既支持按值传递(创建副本)又支持按引用传递。也就是说,Python函数可以修改其参数的内容。假设我们有下面这样的一个函数:
- def append_element(some_list, element):
- some_list.append(element)
根据刚才所说的,下面这样的结果应该是在意料之中的:
- In [2]: data = [1, 2, 3]
- In [3]: append_element(data, 4)
- In [4]: data
- Out[4]: [1, 2, 3, 4]
动态引用,强类型
跟许多编译型语言(如Java和C++)相反,Python中的对象引用没有与之关联的类型信息。下面这些代码不会有什么问题:
- In [245]: a = 5
- In [246]: type(a)
- Out[246]: int
- In [247]: a = 'foo'
- In [248]: type(a)
- Out[248]: str
变量其实就是对象在特定命名空间中的名称而已。对象的类型信息是保存在它自己内部的。有些人可能会轻率地认为Python不是一种“类型化语言”。其实不是这样的。看看下面这个例子:
- In [249]: '5' + 5
- In [249]: '5' + 5
TypeError Traceback (most recent call last) <ipython-input-249-f9dbf5f0b234> in <module>() ——> 1 '5' + 5 TypeError: cannot concatenate 'str' and 'int' objects
在有些语言中(比如Visual Basic),字符串'5'可能会被隐式地转换为整数,于是就会得到10。而在另一些语言中(比如JavaScript),整数5可能会被转换为字符串,于是就会得到'55'。而在这一点上,Python可以被认为是一种强类型语言,也就是说,所有对象都有一个特定的类型(或类),隐式转换只在很明显的情况下才会发生,比如下面这样:
- In [250]: a = 4.5
- In [251]: b = 2
- # 这个操作是字符串格式化,稍后介绍
- In [252]: print 'a is %s, b is %s' % (type(a), type(b))
- a is <type 'float'>, b is <type 'int'>
- In [253]: a / b
- Out[253]: 2.25
了解对象的类型是很重要的。要想编写能够处理多个不同类型输入的函数就必须了解有关类型的知识。通过isinstance函数,你可以检查一个对象是否是某个特定类型的实例:
- In [254]: a = 5
- In [255]: isinstance(a, int)
- Out[255]: True
isinstance可以接受由类型组成的元组。如果想检查某个对象的类型是否属于元组中所指定的那些:
- In [256]: a = 5; b = 4.5
- In [257]: isinstance(a, (int, float))
- Out[257]: True
- In [258]: isinstance(b, (int, float))
- Out[258]: True
属性和方法
Python中的对象通常都既有属性(attribute,即存储在该对象“内部”的其他Python对象)又有方法(method,与该对象有关的能够访问其内部数据的函数)。它们都能通过obj.attribute_name这样的语法进行访问:
- In [1]: a = 'foo'
- In [2]: a.<Tab>
- a.capitalize a.format a.isupper a.rindex a.strip
- a.center a.index a.join a.rjust a.swapcase
- a.count a.isalnum a.ljust a.rpartition a.title
- a.decode a.isalpha a.lower a.rsplit a.translate
- a.encode a.isdigit a.lstrip a.rstrip a.upper
- a.endswith a.islower a.partiti a.split a.zfill
- a.expandtabs a.isspace a.replace a.splitlines
- a.find a.istitle a.rfind a.startswith
属性和方法还可以利用getattr函数通过名称进行访问:
- >>> getattr(a, 'split')
- <function split>
虽然本书没怎么用到getattr函数以及与之相关的hasattr和setattr函数,但是它们还是很实用的,尤其是在编写通用的、可复用的代码时。
“鸭子”类型译注1
一般来说,你可能不会关心对象的类型,而只是想知道它到底有没有某些方法或行为。比如说,只要一个对象实现了迭代器协议(iterator protocol),你就可以确认它是可迭代的。对于大部分对象而言,这就意味着它拥有一个iter魔术方法。当然,还有一个更好一些的验证办法,即尝试使用iter函数:
- def isiterable(obj):
- try:
- iter(obj)
- return True
- except TypeError: # 不可迭代
- return False
对于字符串以及大部分Python集合类型,该函数会返回True:
- In [260]: isiterable('a string') In [261]: isiterable([1, 2, 3])
- Out[260]: True Out[261]: True
- In [262]: isiterable(5)
- Out[262]: False
我常常在编写需要处理多类型输入的函数时用到这个功能。还有一种常见的应用场景:编写可以接受任何序列(列表、元组、ndarray)或迭代器的函数。你可以先检查对象是不是列表(或NumPy数组),如果不是,就将其转换成是:
- if not isinstance(x, list) and isiterable(x):
- x = list(x)
引入(import)
在Python中,模块(module)就是一个含有函数和变量定义以及从其他.py文件引入的此类东西的.py文件。假设我们有下面这样一个模块:
- # some_module.py
- PI = 3.14159
- def f(x):
- return x + 2
- def g(a, b):
- return a + b
如果想要引入some_module.py中定义的变量和函数,我们可以在同一个目录下创建另一个文件:
- import some_module
- result = some_module.f(5)
- pi = some_module.PI
还可以写成这样:
- from some_module import f, g, PI
- result = g(5, PI)
通过as关键字,你可以引入不同的变量名译注2:
- import some_module as sm
- from some_module import PI as pi, g as gf
- r1 = sm.f(pi)
- r2 = gf(6, pi)
二元运算符和比较运算符
大部分二元数学运算和比较运算都跟我们想象中的一样:
- In [263]: 5 - 7 In [264]: 12 + 21.5
- Out[263]: -2 Out[264]: 33.5
- In [265]: 5 <= 2
- Out[265]: False
表A-1中列出了所有可用的二元运算符。
要判断两个引用是否指向同一个对象,可以使用is关键字。如果想判断两个引用是否不是指向同一个对象,则可以使用is not:
- In [266]: a = [1, 2, 3]
- In [267]: b = a
- # 注意,list函数始终会创建新列表
- In [268]: c = list(a)
- In [269]: a is b
- Out[269]: True
- In [270]: a is not c
- Out[270]: True
注意,这跟比较运算"=="不是一回事,因为对于上面这个情况,我们将会得到:
- In [271]: a == c
- Out[271]: True
is和is not常常用于判断变量是否为None,因为None的实例只有一个:
- In [272]: a = None
- In [273]: a is None
- Out[273]: True


严格与懒惰
无论使用什么编程语言,都必须了解表达式是何时被求值的。看看下面这两个简单的表达式:
- a = b = c = 5
- d = a + b * c
在Python中,只要这些语句被求值,相关计算就会立即(也就是严格)发生,d的值会被设置为30。而在另一种编程范式中(比如Haskell这样的纯函数编程语言),d的值在被使用之前是不会被计算出来的。这种将计算推迟的思想通常称为延迟计算(lazy evaluation译注3)。而Python是一种非常严格的(急性子)语言。几乎在任何时候,计算过程和表达式都是立即求值的。即使是在上面那个简单的例子中,也是先计算b *c的结果然后再将其与a加起来的。
有一些Python技术(尤其是用到迭代器和生成器的那些)可以用于实现延迟计算。在数据密集型应用中,当执行一些负荷非常高的计算时(这种情况不太多),这些技术就能派上用场了。
可变和不可变的对象
大部分Python对象是可变的(mutable),比如列表、字典、NumPy数组以及大部分用户自定义类型(类)。也就是说,它们所包含的对象或值是可以被修改的。
- In [274]: a_list = ['foo', 2, [4, 5]]
- In [275]: a_list[2] = (3, 4)
- In [276]: a_list
- Out[276]: ['foo', 2, (3, 4)]
而其他的(如字符串和元组等)则是不可变的(immutable)译注4:
- In [277]: a_tuple = (3, 5, (4, 5))
- In [278]: a_tuple[1] = 'four'
- ---------------------------------------------------------------------------
- TypeError Traceback (most recent call last)
- <ipython-input-278-b7966a9ae0f1> in <module>()
- ----> 1 a_tuple[1] = 'four'
- TypeError: 'tuple' object does not support item assignment
注意,仅仅因为“可以修改某个对象”并不代表“就该那么做”。这种行为在编程中也叫做副作用(side effect)。例如,在编写一个函数时,任何副作用都应该通过该函数的文档或注释明确地告知用户。即使可以使用可变对象,我也建议尽量避免副作用且注重不变性(immutability)。
标量类型
Python有一些用于处理数值数据、字符串、布尔值(True或False)以及日期/时间的内置类型。表A-2列出了主要的标量类型。后面我们将单独讨论日期/时间的处理,因为它们是由标准库中的datetime模块提供的。

数值类型
用于表示数字的主要Python类型是int和float。能被保存为int的整数的大小由平台决定(是32位还是64位),但是Python会自动将非常大的整数转换为long,它可以存储任意大小的整数。
- In [279]: ival = 17239871
- In [280]: ival ** 6
- Out[280]: 26254519291092456596965462913230729701102721L
浮点数会被表示为Python的float类型。浮点数会被保存为一个双精度(64位)值。它们也可以用科学计数法表示:
- In [281]: fval = 7.243
- In [282]: fval2 = 6.78e-5
在Python 3中,整数除法除不尽时就会产生一个浮点数:
- In [284]: 3 / 2
- Out[284]: 1.5
在Python 2.7及以下版本中(某些读者现在用的可能就是译注5),只要将下面这条怪模怪样的语句添加到自定义模块的顶部即可修改这个默认行为:
- from __future__ import division
如果没加这句的话,你也可以显式地将分母转换成浮点数译注6:
- In [285]: 3 / float(2)
- Out[285]: 1.5
要得到C风格的整数除法(如果除不尽,就丢弃小数部分),使用除后圆整运算符(//)即可:
- In [286]: 3 // 2
- Out[286]: 1
复数的虚部是用j表示的:
- In [287]: cval = 1 + 2j
- In [288]: cval * (1 - 2j)
- Out[288]: (5+0j)
字符串
很多人都是因为Python强大而灵活的字符串处理能力才使用它的。编写字符串字面量时,既可以用单引号(')也可以用双引号("):
- a = 'one way of writing a string'
- b = "another way"
对于带有换行符的多行字符串,可以使用三重引号(即'''或"""):
- c = """
- This is a longer string that
- spans multiple lines
- """
Python字符串是不可变的。要修改字符串就只能创建一个新的:
- In [289]: a = 'this is a string'
- In [290]: a[10] = 'f'
- ---------------------------------------------------------------------------
- TypeError Traceback (most recent call last)
- <ipython-input-290-5ca625d1e504> in <module>()
- ----> 1 a[10] = 'f'
- TypeError: 'str' object does not support item assignment
- In [291]: b = a.replace('string', 'longer string')
- In [292]: b
- Out[292]: 'this is a longer string'
许多Python对象都可以用str函数转换为字符串:
- In [293]: a = 5.6 In [294]: s = str(a)
- In [295]: s
- Out[295]: '5.6'
由于字符串其实是一串字符序列,因此可以被当做某种序列类型(如列表、元组等)进行处理:
- In [296]: s = 'python' In [297]: list(s)
- Out[297]: ['p', 'y', 't', 'h', 'o', 'n']
- In [298]: s[:3]
- Out[298]: 'pyt'
反斜杠(\)是转义符(escape character),也就是说,它可用于指定特殊字符(比如新行\n或unicode字符)。要编写带有反斜杠的字符串字面量,也需要对其进行转义:
- In [299]: s = '12\\34'
- In [300]: print s
- 12\34
如果字符串带有很多反斜杠且没有特殊字符,你就会发现这个办法很容易让人抓狂。幸运的是,你可以在字符串最左边引号的前面加上r,它表示所有字符应该按照原本的样子进行解释:
- In [301]: s = r'this\has\no\special\characters'
- In [302]: s
- Out[302]: 'this\\has\\no\\special\\characters'
将两个字符串加起来会产生一个新字符串:
- In [303]: a = 'this is the first half '
- In [304]: b = 'and this is the second half'
- In [305]: a + b
- Out[305]: 'this is the first half and this is the second half'
字符串格式化是另一个重要的主题。Python 3带来了一些新的字符串格式化手段,这里我简要说明一下其主要机制。以一个%开头且后面跟着一个或多个格式字符的字符串是需要插入值的目标(这非常类似于C语言中的printf函数)。看看下面这个字符串:
- In [306]: template = '%.2f %s are worth $%d'
在这个字符串中,%s表示将参数格式化为字符串,%.2f表示一个带有2位小数的数字,%d表示一个整数。要用实参替换这些格式化形参,需要用到二元运算符%以及由值组成的元组:
- In [307]: template % (4.5560, 'Argentine Pesos', 1)
- Out[307]: '4.56 Argentine Pesos are worth $1'
字符串格式化是一个很大的主题,控制值在结果字符串中的格式化效果的方式非常多。我建议你在网上多找一些有关于此的资料来看看。
这里之所以要专门讨论通用字符串处理,是因为它有关于数据分析,更多细节请参阅第7章。
布尔值
Python中的两个布尔值分别写作True和False。比较运算和条件表达式都会产生True或False。布尔值可以用and和or关键字进行连接:
- In [308]: True and True
- Out[308]: True
- In [309]: False or True
- Out[309]: True
几乎所有内置的Python类型以及任何定义了nonzero魔术方法的类都能在if语句中被解释为True或False:
- In [310]: a = [1, 2, 3]
- ...: if a:
- ...: print 'I found something!'
- ...:
- I found something!
- In [311]: b = []
- ...: if not b:
- ...: print 'Empty!'
- ...:
- Empty!
Python中大部分对象都有真假的概念。比如说,如果空序列(列表、字典、元组等)用于控制流(就像上面的空列表b)就会被当做False处理。要想知道某个对象究竟会被强制转换成哪个布尔值,使用bool函数即可:
- In [312]: bool([]), bool([1, 2, 3])
- Out[312]: (False, True)
- In [313]: bool('Hello world!'), bool('')
- Out[313]: (True, False)
- In [314]: bool(0), bool(1)
- Out[314]: (False, True)
类型转换
str、bool、int以及float等类型也可用作将值转换成该类型的函数:
- In [315]: s = '3.14159'
- In [316]: fval = float(s) In [317]: type(fval)
- Out[317]: float
- In [318]: int(fval) In [319]: bool(fval) In [320]: bool(0)
- Out[318]: 3 Out[319]: True Out[320]: False
None
None是Python的空值类型。如果一个函数没有显式地返回值,则隐式返回None。
- In [321]: a = None
- In [322]: a is None
- Out[322]: True
- In [323]: b = 5
- In [324]: b is not None
- Out[324]: True
None还是函数可选参数的一种常见默认值:
- def add_and_maybe_multiply(a, b, c=None):
- result = a + b
- if c is not None:
- result = result * c
- return result
我们要牢记,None不是一个保留关键字,它只是NoneType的一个实例而已。
日期和时间
Python内置的datetime模块提供了datetime、date以及time等类型。datetime类型是用得最多的,它合并了保存在date和time中的信息:
- In [325]: from datetime import datetime, date, time
- In [326]: dt = datetime(2011, 10, 29, 20, 30, 21)
- In [327]: dt.day In [328]: dt.minute
- Out[327]: 29 Out[328]: 30
给定一个datetime实例,你可以通过调用其date和time方法提取相应的date和time对象:
- In [329]: dt.date() In [330]: dt.time()
- Out[329]: datetime.date(2011, 10, 29) Out[330]: datetime.time(20, 30, 21)
strftime方法用于将datetime格式化为字符串:
- In [331]: dt.strftime('%m/%d/%Y %H:%M')
- Out[331]: '10/29/2011 20:30'
字符串可以通过strptime函数转换(解析)为datetime对象:
- In [332]: datetime.strptime('20091031', '%Y%m%d')
- Out[332]: datetime.datetime(2009, 10, 31, 0, 0)
完整的格式化定义请参见表10-2。
在对时间序列数据进行聚合或分组时,可能需要替换datetime中的一些字段。例如,将分和秒字段替换为0,并产生一个新对象:
- In [333]: dt.replace(minute=0, second=0)
- Out[333]: datetime.datetime(2011, 10, 29, 20, 0)
两个datetime对象的差会产生一个datetime.timedelta类型:
- In [334]: dt2 = datetime(2011, 11, 15, 22, 30)
- In [335]: delta = dt2 - dt
- In [336]: delta In [337]: type(delta)
- Out[336]: datetime.timedelta(17, 7179) Out[337]: datetime.timedelta
将一个timedelta加到一个datetime上会产生一个新的datetime:
- In [338]: dt
- Out[338]: datetime.datetime(2011, 10, 29, 20, 30, 21)
- In [339]: dt + delta
- Out[339]: datetime.datetime(2011, 11, 15, 22, 30)
控制流
if、elif和else
if语句是一种最常见的控制流语句类型。它用于判断一个条件,如果为True,则执行紧跟其后的代码块:
- if x < 0:
- print 'It's negative'
一条if语句可以跟上一个或多个elif块以及一个“滴水不漏”的else块(如果所有条件都为False):
- if x < 0:
- print 'It's negative'
- elif x == 0:
- print 'Equal to zero'
- elif 0 < x < 5:
- print 'Positive but smaller than 5'
- else:
- print 'Positive and larger than or equal to 5'
如果任何一个条件为True,则其后的elif或else块就不会执行。对于用and或or组成的复合条件,各条件是按从左到右的顺序求值的,而且是短路型的:
- In [340]: a = 5; b = 7
- In [341]: c = 8; d = 4
- In [342]: if a < b or c > d:
- ...: print 'Made it'
- Made it
在本例中,比较运算c>d是不会被计算的,因为第一个比较运算为True。
for循环
for循环用于对集合(比如列表或元组)或迭代器进行迭代。for循环的标准语法是:
- for value in collection:
- # 对value做一些处理
continue关键字用于使for循环提前进入下一次迭代(即跳过代码块的剩余部分)。看看下面这段代码,其功能是对列表中的整数求和并跳过None值:
- sequence = [1, 2, None, 4, None, 5]
- total = 0
- for value in sequence:
- if value is None:
- continue
- total += value
break关键字用于使for循环完全退出。下面这段代码用于对列表的元素求和,遇到5就退出:
- sequence = [1, 2, 0, 4, 6, 5, 2, 1]
- total_until_5 = 0
- for value in sequence:
- if value == 5:
- break
- total_until_5 += value
后面我们还会看到,如果集合或迭代器的元素是序列类型(比如元组或列表),那么还可以非常方便地将这些元素拆散成for语句中的多个变量:
- for a, b, c in iterator:
- # 做一些处理
while循环
while循环定义了一个条件和一个代码块,只要条件不为False或循环没有被break显式终止,则代码块将一直不断地执行下去:
- x = 256
- total = 0
- while x > 0:
- if total > 500:
- break
- total += x
- x = x // 2
pass
pass是Python中的“空操作”语句。它可以被用在那些没有任何功能的代码块中。由于Python是根据空白符划分代码块的,所以它的存在是很有必要的:
- if x < 0:
- print 'negative!'
- elif x == 0:
- # TODO: 在这里放点代码
- pass
- else:
- print 'positive!'
在开发一个新功能时,常常会将pass用作代码中的占位符:
- def f(x, y, z):
- # TODO: 实现这个函数!
- pass
异常处理
优雅地处理Python错误或异常是构建健壮程序的重要环节。在数据分析应用中,许多函数只对特定类型的输入有效。例如,Python的float函数可以将字符串转换为浮点数,但是如果输入值不正确就会产生ValueError:
- In [343]: float('1.2345')
- Out[343]: 1.2345
- In [344]: float('something')
- ---------------------------------------------------------------------------
- ValueError Traceback (most recent call last)
- <ipython-input-344-439904410854> in <module>()
- ----> 1 float('something')
- ValueError: could not convert string to float: something
假设我们想要编写一个在出错时能优雅地返回输入参数的改进版float函数。我们可以编写一个新函数,并把对float函数的调用放在一个try/except块中:
- def attempt_float(x):
- try:
- return float(x)
- except:
- return x
只有当float(x)引发异常时,except块中的代码才会被执行:
- In [346]: attempt_float('1.2345')
- Out[346]: 1.2345
- In [347]: attempt_float('something')
- Out[347]: 'something'
你可能已经注意到了,float还可以引发ValueError以外的异常:
- In [348]: float((1, 2))
- In [348]: float((1, 2))
TypeError Traceback (most recent call last) <ipython-input-348-842079ebb635> in <module>() ——> 1 float((1, 2)) TypeError: float() argument must be a string or a number
你可能只希望处理ValueError,因为TypeError(输入参数不是字符串或数值)可能意味着你的程序中存在合法性bug。要达到这个目的,在except后面加上异常类型即可:
- def attempt_float(x):
- try:
- return float(x)
- except ValueError:
- return x
于是我们就有了:
- In [350]: attempt_float((1, 2))
- In [350]: attempt_float((1, 2))
TypeError Traceback (most recent call last) <ipython-input-350-9bdfd730cead> in <module>() ——> 1 attempt_float((1, 2)) <ipython-input-349-3e06b8379b6b> in attempt_float(x) 1 def attempt_float(x): 2 try: ——> 3 return float(x) 4 except ValueError: 5 return x TypeError: float() argument must be a string or a number
只需编写一个由异常类型组成的元组(圆括号是必需的)即可捕获多个异常:
- def attempt_float(x):
- try:
- return float(x)
- except (TypeError, ValueError):
- return x
有时你可能不想处理任何异常,而只是希望有一段代码不管try块代码成功与否都能被执行。使用finally即可达到这个目的:
- f = open(path, 'w')
- try:
- write_to_file(f)
- finally:
- f.close()
这里,文件句柄f始终都会被关闭。同理,你也可以让某些代码只在try块成功时执行,使用else即可:
- f = open(path, 'w')
- try:
- write_to_file(f)
- except:
- print 'Failed'
- else:
- print 'Succeeded'
- finally:
- f.close()
range和xrange
range函数用于产生一组间隔平均的整数:
- In [352]: range(10)
- Out[352]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
可以指定起始值、结束值以及步长等信息:
- In [353]: range(0, 20, 2)
- Out[353]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
如你所见,range所产生的整数不包括末端值。range常用于按索引对序列进行迭代:
- seq = [1, 2, 3, 4]
- for i in range(len(seq)):
- val = seq[i]
对于非常长的范围,建议使用xrange,其参数跟range一样,但它不会预先产生所有的值并将它们保存到列表中(可能会非常大),而是返回一个用于逐个产生整数的迭代器。下面这段代码用于对0到9999之间所有3或5的倍数的数字求和:
- sum = 0
- for i in xrange(10000):
- # %是求模运算符
- if x % 3 == 0 or x % 5 == 0:
- sum += i
注意: 在Python 3中,range始终返回迭代器,因此也就没必要使用xrange函数了。
三元表达式
Python的三元表达式(ternary expression)允许你将产生一个值的if-else块写到一行或一个表达式中。其语法如下所示:
- value = true-expr if condition else false-expr
其中的true-expr和false-expr可以是任何Python表达式。它跟下面这种冗长格式的效果一样:
- if condition:
- value = true-expr
- else:
- value = false-expr
下面是一个具体点的例子:
- In [354]: x = 5
- In [355]: 'Non-negative' if x >= 0 else 'Negative'
- Out[355]: 'Non-negative'
跟if-else块一样,只有一个表达式会被求值。虽然这可能会引诱你总是使用三元表达式去浓缩你的代码,但要意识到,如果条件以及true和false表达式非常复杂,就可能会牺牲可读性。
