示例:2012联邦选举委员会数据库
美国联邦选举委员会发布了有关政治竞选赞助方面的数据。其中包括赞助者的姓名、职业、雇主、地址以及出资额等信息。我们对2012年美国总统大选的数据集比较感兴趣(http://www.fec.gov/disclosurep/PDownload.do)。到编写本书时为止(2012年6月),涵盖全美各州的完整数据集是一个150MB的CSV文件(P00000001-ALL.csv),我们先用pandas.read_csv将其加载进来:
- In [13]: fec = pd.read_csv('ch09/P00000001-ALL.csv')
- In [14]: fec
- Out[14]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 1001731 entries, 0 to 1001730
- Data columns:
- cmte_id 1001731 non-null values
- cand_id 1001731 non-null values
- cand_nm 1001731 non-null values
- contbr_nm 1001731 non-null values
- contbr_city 1001716 non-null values
- contbr_st 1001727 non-null values
- contbr_zip 1001620 non-null values
- contbr_employer 994314 non-null values
- contbr_occupation 994433 non-null values
- contb_receipt_amt 1001731 non-null values
- contb_receipt_dt 1001731 non-null values
- receipt_desc 14166 non-null values
- memo_cd 92482 non-null values
- memo_text 97770 non-null values
- form_tp 1001731 non-null values
- file_num 1001731 non-null values
- dtypes: float64(1), int64(1), object(14)
该DataFrame中的记录如下所示:
- In [15]: fec.ix[123456]
- Out[15]:
- cmte_id C00431445
- cand_id P80003338
- cand_nm Obama, Barack
- contbr_nm ELLMAN, IRA
- contbr_city TEMPE
- contbr_st AZ
- contbr_zip 852816719
- contbr_employer ARIZONA STATE UNIVERSITY
- contbr_occupation PROFESSOR
- contb_receipt_amt 50
- contb_receipt_dt 01-DEC-11
- receipt_desc NaN
- memo_cd NaN
- memo_text NaN
- form_tp SA17A
- file_num 772372
- Name: 123456
你可能已经想出了许多办法从这些竞选赞助数据中抽取有关赞助人和赞助模式的统计信息。我将在接下来的内容中介绍几种不同的分析工作(运用到目前为止已经学到的技术)。
不难看出,该数据中没有党派信息,因此最好把它加进去。通过unique,你可以获取全部的候选人名单(注意,NumPy不会输出信息中字符串两侧的引号):
- In [16]: unique_cands = fec.cand_nm.unique()
- In [17]: unique_cands
- Out[17]:
- array([Bachmann, Michelle, Romney, Mitt, Obama, Barack,
- Roemer, Charles E. 'Buddy' III, Pawlenty, Timothy,
- Johnson, Gary Earl, Paul, Ron, Santorum, Rick, Cain, Herman,
- Gingrich, Newt, McCotter, Thaddeus G, Huntsman, Jon, Perry, Rick],
- dtype=object)
- In [18]: unique_cands[2]
- Out[18]: 'Obama, Barack'
最简单的办法是利用字典说明党派关系注1:
- parties = {'Bachmann, Michelle': 'Republican',
- 'Cain, Herman': 'Republican',
- 'Gingrich, Newt': 'Republican',
- 'Huntsman, Jon': 'Republican',
- 'Johnson, Gary Earl': 'Republican',
- 'McCotter, Thaddeus G': 'Republican',
- 'Obama, Barack': 'Democrat',
- 'Paul, Ron': 'Republican',
- 'Pawlenty, Timothy': 'Republican',
- 'Perry, Rick': 'Republican',
- "Roemer, Charles E. 'Buddy' III": 'Republican',
- 'Romney, Mitt': 'Republican',
- 'Santorum, Rick': 'Republican'}
现在,通过这个映射以及Series对象的map方法,你可以根据候选人姓名得到一组党派信息:
- In [20]: fec.cand_nm[123456:123461]
- Out[20]:
- 123456 Obama, Barack
- 123457 Obama, Barack
- 123458 Obama, Barack
- 123459 Obama, Barack
- 123460 Obama, Barack
- Name: cand_nm
- In [21]: fec.cand_nm[123456:123461].map(parties)
- Out[21]:
- 123456 Democrat
- 123457 Democrat
- 123458 Democrat
- 123459 Democrat
- 123460 Democrat
- Name: cand_nm
- # 将其添加为一个新列
- In [22]: fec['party'] = fec.cand_nm.map(parties)
- In [23]: fec['party'].value_counts()
- Out[23]:
- Democrat 593746
- Republican 407985
这里有两个需要注意的地方。第一,该数据既包括赞助也包括退款(负的出资额):
- In [24]: (fec.contb_receipt_amt > 0).value_counts()
- Out[24]:
- True 991475
- False 10256
为了简化分析过程,我限定该数据集只能有正的出资额:
- In [25]: fec = fec[fec.contb_receipt_amt > 0]
由于Barack Obama和Mitt Romney是最主要的两名候选人,所以我还专门准备了一个子集,只包含针对他们两人的竞选活动的赞助信息:
- In [26]: fec_mrbo = fec[fec.cand_nm.isin(['Obama, Barack', 'Romney, Mitt'])]
根据职业和雇主统计赞助信息
基于职业的赞助信息统计是另一种经常被研究的统计任务。例如,律师们更倾向于资助民主党,而企业主则更倾向于资助共和党。你可以不相信我,自己看那些数据就知道了。首先,根据职业计算出资总额,这很简单:
- In [27]: fec.contbr_occupation.value_counts()[:10]
- Out[27]:
- RETIRED 233990
- INFORMATION REQUESTED 35107
- ATTORNEY 34286
- HOMEMAKER 29931
- PHYSICIAN 23432
- INFORMATION REQUESTED PER BEST EFFORTS 21138
- ENGINEER 14334
- TEACHER 13990
- CONSULTANT 13273
- PROFESSOR 12555
不难看出,许多职业都涉及相同的基本工作类型,或者同一样东西有多种变体。下面的代码片段可以清理一些这样的数据(将一个职业信息映射到另一个)。注意,这里巧妙地利用了dict.get,它允许没有映射关系的职业也能“通过”:
- occ_mapping = {
- 'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
- 'INFORMATION REQUESTED' : 'NOT PROVIDED',
- 'INFORMATION REQUESTED (BEST EFFORTS)' : 'NOT PROVIDED',
- 'C.E.O.': 'CEO'
- }
- # 如果没有提供相关映射,则返回x
- f = lambda x: occ_mapping.get(x, x)
- fec.contbr_occupation = fec.contbr_occupation.map(f)
我对雇主信息也进行了同样的处理:
- emp_mapping = {
- 'INFORMATION REQUESTED PER BEST EFFORTS' : 'NOT PROVIDED',
- 'INFORMATION REQUESTED' : 'NOT PROVIDED',
- 'SELF' : 'SELF-EMPLOYED',
- 'SELF EMPLOYED' : 'SELF-EMPLOYED',
- }
- # 如果没有提供相关映射,则返回x
- f = lambda x: emp_mapping.get(x, x)
- fec.contbr_employer = fec.contbr_employer.map(f)
现在,你可以通过pivot_table根据党派和职业对数据进行聚合,然后过滤掉总出资额不足200万美元的数据:
- In [34]: by_occupation = fec.pivot_table('contb_receipt_amt',
- ...: rows='contbr_occupation',
- ...: cols='party', aggfunc='sum')
- In [35]: over_2mm = by_occupation[by_occupation.sum(1) > 2000000]
- In [36]: over_2mm
- Out[36]:
- party Democrat Republican
- contbr_occupation
- ATTORNEY 11141982.97 7477194.430000
- CEO 2074974.79 4211040.520000
- CONSULTANT 2459912.71 2544725.450000
- ENGINEER 951525.55 1818373.700000
- EXECUTIVE 1355161.05 4138850.090000
- HOMEMAKER 4248875.80 13634275.780000
- INVESTOR 884133.00 2431768.920000
- LAWYER 3160478.87 391224.320000
- MANAGER 762883.22 1444532.370000
- NOT PROVIDED 4866973.96 20565473.010000
- OWNER 1001567.36 2408286.920000
- PHYSICIAN 3735124.94 3594320.240000
- PRESIDENT 1878509.95 4720923.760000
- PROFESSOR 2165071.08 296702.730000
- REAL ESTATE 528902.09 1625902.250000
- RETIRED 25305116.38 23561244.489999
- SELF-EMPLOYED 672393.40 1640252.540000
把这些数据做成柱状图看起来会更加清楚('barh'表示水平柱状图,如图9-2所示):
- In [38]: over_2mm.plot(kind='barh')
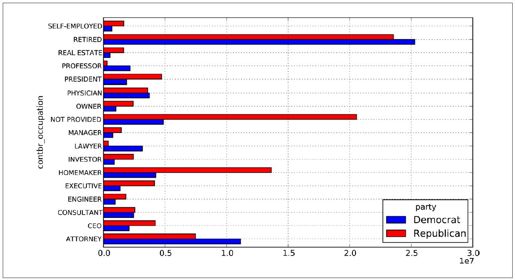
图9-2:对各党派总出资额最高的职业
你可能还想了解一下对Obama和Romney总出资额最高的职业和企业。为此,我们先对候选人进行分组,然后使用本章前面介绍的那种求取最大值的方法:
- def get_top_amounts(group, key, n=5):
- totals = group.groupby(key)['contb_receipt_amt'].sum()
- # 根据key对totals进行降序排列
- return totals.order(ascending=False)[n:]
然后根据职业和雇主进行聚合:
- In [40]: grouped = fec_mrbo.groupby('cand_nm')
- In [41]: grouped.apply(get_top_amounts, 'contbr_occupation', n=7)
- Out[41]:
- cand_nm contbr_occupation
- Obama, Barack RETIRED 25305116.38
- ATTORNEY 11141982.97
- INFORMATION REQUESTED 4866973.96
- HOMEMAKER 4248875.80
- PHYSICIAN 3735124.94
- LAWYER 3160478.87
- CONSULTANT 2459912.71
- Romney, Mitt RETIRED 11508473.59
- INFORMATION REQUESTED PER BEST EFFORTS 11396894.84
- HOMEMAKER 8147446.22
- ATTORNEY 5364718.82
- PRESIDENT 2491244.89
- EXECUTIVE 2300947.03
- C.E.O. 1968386.11
- Name: contb_receipt_amt
- In [42]: grouped.apply(get_top_amounts, 'contbr_employer', n=10)
- Out[42]:
- cand_nm contbr_employer
- Obama, Barack RETIRED 22694358.85
- SELF-EMPLOYED 17080985.96
- NOT EMPLOYED 8586308.70
- INFORMATION REQUESTED 5053480.37
- HOMEMAKER 2605408.54
- SELF 1076531.20
- SELF EMPLOYED 469290.00
- STUDENT 318831.45
- VOLUNTEER 257104.00
- MICROSOFT 215585.36
- Romney, Mitt INFORMATION REQUESTED PER BEST EFFORTS 12059527.24
- RETIRED 11506225.71
- HOMEMAKER 8147196.22
- SELF-EMPLOYED 7409860.98
- STUDENT 496490.94
- CREDIT SUISSE 281150.00
- MORGAN STANLEY 267266.00
- GOLDMAN SACH & CO. 238250.00
- BARCLAYS CAPITAL 162750.00
- H.I.G. CAPITAL 139500.00
- Name: contb_receipt_amt
对出资额分组
还可以对该数据做另一种非常实用的分析:利用cut函数根据出资额的大小将数据离散化到多个面元中:
- In [43]: bins = np.array([0, 1, 10, 100, 1000, 10000, 100000, 1000000, 10000000])
- In [44]: labels = pd.cut(fec_mrbo.contb_receipt_amt, bins)
- In [45]: labels
- Out[45]:
- Categorical: contb_receipt_amt
- array([(10, 100], (100, 1000], (100, 1000], ..., (1, 10], (10, 100],
- (100, 1000]], dtype=object)
- Levels (8): Index([(0, 1], (1, 10], (10, 100], (100, 1000], (1000, 10000],
- (10000, 100000], (100000, 1000000], (1000000, 10000000]], dtype=object)
然后根据候选人姓名以及面元标签对数据进行分组:
- In [46]: grouped = fec_mrbo.groupby(['cand_nm', labels])
- In [47]: grouped.size().unstack(0)
- Out[47]:
- cand_nm Obama, Barack Romney, Mitt
- contb_receipt_amt
- (0, 1] 493 77
- (1, 10] 40070 3681
- (10, 100] 372280 31853
- (100, 1000] 153991 43357
- (1000, 10000] 22284 26186
- (10000, 100000] 2 1
- (100000, 1000000] 3 NaN
- (1000000, 10000000] 4 NaN
从这个数据中可以看出,在小额赞助方面,Obama获得的数量比Romney多得多。你还可以对出资额求和并在面元内规格化,以便图形化显示两位候选人各种赞助额度的比例:
- In [48]: bucket_sums = grouped.contb_receipt_amt.sum().unstack(0)
- In [49]: bucket_sums
- Out[49]:
- cand_nm Obama, Barack Romney, Mitt
- contb_receipt_amt
- (0, 1] 318.24 77.00
- (1, 10] 337267.62 29819.66
- (10, 100] 20288981.41 1987783.76
- (100, 1000] 54798531.46 22363381.69
- (1000, 10000] 51753705.67 63942145.42
- (10000, 100000] 59100.00 12700.00
- (100000, 1000000] 1490683.08 NaN
- (1000000, 10000000] 7148839.76 NaN
- In [50]: normed_sums = bucket_sums.div(bucket_sums.sum(axis=1), axis=0)
- In [51]: normed_sums
- Out[51]:
- cand_nm Obama, Barack Romney, Mitt
- contb_receipt_amt
- (0, 1] 0.805182 0.194818
- (1, 10] 0.918767 0.081233
- (10, 100] 0.910769 0.089231
- (100, 1000] 0.710176 0.289824
- (1000, 10000] 0.447326 0.552674
- (10000, 100000] 0.823120 0.176880
- (100000, 1000000] 1.000000 NaN
- (1000000, 10000000] 1.000000 NaN
- In [52]: normed_sums[:-2].plot(kind='barh', stacked=True)
我排除了两个最大的面元,因为这些不是由个人捐赠的。最终的结果如图9-3所示。
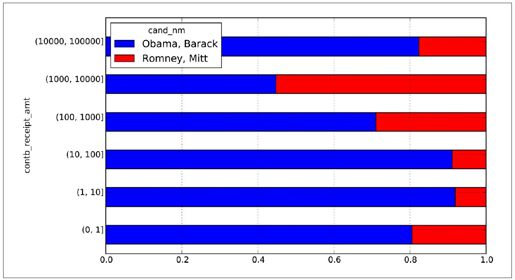
图9-3:两位候选人收到的各种捐赠额度的总额比例
当然,还可以对该分析过程做许多的提炼和改进。比如说,可以根据赞助人的姓名和邮编对数据进行聚合,以便找出哪些人进行了多次小额捐款,哪些人又进行了一次或多次大额捐款。我强烈建议你下载这些数据并自己摸索一下。
根据州统计赞助信息
首先自然是根据候选人和州对数据进行聚合:
- In [53]: grouped = fec_mrbo.groupby(['cand_nm', 'contbr_st'])
- In [54]: totals = grouped.contb_receipt_amt.sum().unstack(0).fillna(0)
- In [55]: totals = totals[totals.sum(1) > 100000]
- In [56]: totals[:10]
- Out[56]:
- cand_nm Obama, Barack Romney, Mitt
- contbr_st
- AK 281840.15 86204.24
- AL 543123.48 527303.51
- AR 359247.28 105556.00
- AZ 1506476.98 1888436.23
- CA 23824984.24 11237636.60
- CO 2132429.49 1506714.12
- CT 2068291.26 3499475.45
- DC 4373538.80 1025137.50
- DE 336669.14 82712.00
- FL 7318178.58 8338458.81
如果对各行除以总赞助额,就会得到各候选人在各州的总赞助额比例:
- In [57]: percent = totals.div(totals.sum(1), axis=0)
- In [58]: percent[:10]
- Out[58]:
- cand_nm Obama, Barack Romney, Mitt
- contbr_st
- AK 0.765778 0.234222
- AL 0.507390 0.492610
- AR 0.772902 0.227098
- AZ 0.443745 0.556255
- CA 0.679498 0.320502
- CO 0.585970 0.414030
- CT 0.371476 0.628524
- DC 0.810113 0.189887
- DE 0.802776 0.197224
- FL 0.467417 0.532583
我认为在地图上看这些数据会比较有意思(第8章中介绍过相关技术)。在找到有关州界的shape file(http://nationalatlas.gov/atlasftp.html?openChapters=chpbound)并稍微学习一下matplotlib及其basemap工具包(Thomas Lecocq的博客帮了我的大忙注2)之后,我终于用下面这段代码画出了刚才算出来的相对百分比:译注7
- from mpl_toolkits.basemap import Basemap, cm
- import numpy as np
- from matplotlib import rcParams
- from matplotlib.collections import LineCollection
- import matplotlib.pyplot as plt
- from shapelib import ShapeFile
- import dbflib
- obama = percent['Obama, Barack']
- fig = plt.figure(figsize=(12, 12))
- ax = fig.add_axes([0.1,0.1,0.8,0.8])
- lllat = 21; urlat = 53; lllon = -118; urlon = -62
- m = Basemap(ax=ax, projection='stere',
- lon_0=(urlon + lllon) / 2, lat_0=(urlat + lllat) / 2,
- llcrnrlat=lllat, urcrnrlat=urlat, llcrnrlon=lllon,
- urcrnrlon=urlon, resolution='l')
- m.drawcoastlines()
- m.drawcountries()
- shp = ShapeFile('../states/statesp020')
- dbf = dbflib.open('../states/statesp020')
- for npoly in range(shp.info()[0]):
- # 在地图上绘制彩色多边形
- shpsegs = []
- shp_object = shp.read_object(npoly)
- verts = shp_object.vertices()
- rings = len(verts)
- for ring in range(rings):
- lons, lats = zip(*verts[ring])
- x, y = m(lons, lats)
- shpsegs.append(zip(x,y))
- if ring == 0:
- shapedict = dbf.read_record(npoly)
- name = shapedict['STATE']
- lines = LineCollection(shpsegs,antialiaseds=(1,))
- # state_to_code字典,例如'ALASKA' -> 'AK', omitted
- try:
- per = obama[state_to_code[name.upper()]]
- except KeyError:
- continue
- lines.set_facecolors('k')
- lines.set_alpha(0.75 * per) # 把“百分比”变小一点
- lines.set_edgecolors('k')
- lines.set_linewidth(0.3)
- plt.show()
最终结果如图9-4所示。
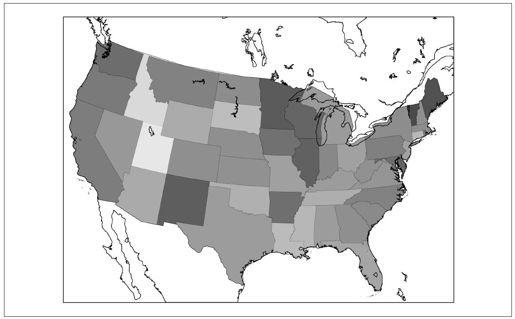
图9-4:汇集了所有赞助统计信息的美国地图(颜色越深表示越支持民主党)
注1:为了简单起见,这里假设Gary Johnson是一名共和党员,虽然他后来成为自由党的候选人。
注2:http://www.geophysique.be/2011/01/27/matplotlib-basemap-tutorial-07-shapefiles-unleached/。
译注7:惭愧,折腾了整整两天,愣是没做出来。太郁闷了,照着输入都不行。在网上找了一个比较有效的办法,不过由于时间太紧就没完成,希望读者在尝试成功之后一定在网上发布一下,以飨更多读者。
