日期的范围、频率以及移动
pandas中的时间序列一般被认为是不规则的,也就是说,它们没有固定的频率。对于大部分应用程序而言,这是无所谓的。但是,它常常需要以某种相对固定的频率进行分析,比如每日、每月、每15分钟等(这样自然会在时间序列中引入缺失值)。幸运的是,pandas有一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具。例如,我们可以将之前那个时间序列转换为一个具有固定频率(每日)的时间序列,只需调用resample即可:
- In [380]: ts In [381]: ts.resample('D')
- Out[380]: Out[381]:
- 2011-01-02 0.690002 2011-01-02 0.690002
- 2011-01-05 1.001543 2011-01-03 NaN
- 2011-01-07 -0.503087 2011-01-04 NaN
- 2011-01-08 -0.622274 2011-01-05 1.001543
- 2011-01-10 -0.921169 2011-01-06 NaN
- 2011-01-12 -0.726213 2011-01-07 -0.503087
- 2011-01-08 -0.622274
- 2011-01-09 NaN
- 2011-01-10 -0.921169
- 2011-01-11 NaN
- 2011-01-12 -0.726213
- Freq: D
频率的转换(或重采样)是一个比较大的主题,稍后将专门用一节来进行讨论。这里我将告诉你如何使用基本的频率。
生成日期范围
虽然我之前用的时候没有明说,但你可能已经猜到pandas.date_range可用于生成指定长度的DatetimeIndex:
- In [382]: index = pd.date_range('4/1/2012', '6/1/2012')
- In [383]: index
- Out[383]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2012-04-01 00:00:00, ..., 2012-06-01 00:00:00]
- Length: 62, Freq: D, Timezone: None
默认情况下,date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字:
- In [384]: pd.date_range(start='4/1/2012', periods=20)
- Out[384]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2012-04-01 00:00:00, ..., 2012-04-20 00:00:00]
- Length: 20, Freq: D, Timezone: None
- In [385]: pd.date_range(end='6/1/2012', periods=20)
- Out[385]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2012-05-13 00:00:00, ..., 2012-06-01 00:00:00]
- Length: 20, Freq: D, Timezone: None
起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率(表示business end of month),这样就只会包含时间间隔内(或刚好在边界上的)符合频率要求的日期:
- In [386]: pd.date_range('1/1/2000', '12/1/2000', freq='BM')
- Out[386]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2000-01-31 00:00:00, ..., 2000-11-30 00:00:00]
- Length: 11, Freq: BM, Timezone: None
date_range默认会保留起始和结束时间戳的时间信息(如果有的话):
- In [387]: pd.date_range('5/2/2012 12:56:31', periods=5)
- Out[387]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2012-05-02 12:56:31, ..., 2012-05-06 12:56:31]
- Length: 5, Freq: D, Timezone: None
有时,虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能:
- In [388]: pd.date_range('5/2/2012 12:56:31', periods=5, normalize=True)
- Out[388]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2012-05-02 00:00:00, ..., 2012-05-06 00:00:00]
- Length: 5, Freq: D, Timezone: None
频率和日期偏移量
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应。例如,按小时计算的频率可以用Hour类表示:
- In [389]: from pandas.tseries.offsets import Hour, Minute
- In [390]: hour = Hour()
- In [391]: hour
- Out[391]: <1 Hour>
传入一个整数即可定义偏移量的倍数:
- In [392]: four_hours = Hour(4)
- In [393]: four_hours
- Out[393]: <4 Hours>
一般来说,无需显式创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数:
- In [394]: pd.date_range('1/1/2000', '1/3/2000 23:59', freq='4h')
- Out[394]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2000-01-01 00:00:00, ..., 2000-01-03 20:00:00]
- Length: 18, Freq: 4H, Timezone: None
大部分偏移量对象都可通过加法进行连接:
- In [395]: Hour(2) + Minute(30)
- Out[395]: <150 Minutes>
同理,你也可以传入频率字符串(如"2h30min"),这种字符串可以被高效地解析为等效的表达式:
- In [396]: pd.date_range('1/1/2000', periods=10, freq='1h30min')
- Out[396]:
- <class 'pandas.tseries.index.DatetimeIndex'>
- [2000-01-01 00:00:00, ..., 2000-01-01 13:30:00]
- Length: 10, Freq: 90T, Timezone: None
有些频率所描述的时间点并不是均匀分隔的。例如,"M"(日历月末)和"BM"(每月最后一个工作日)就取决于每月的天数,对于后者,还要考虑月末是不是周末。由于没有更好的术语,我将这些称为锚点偏移量(anchored offset)。
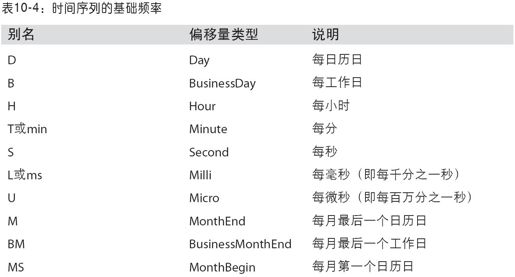
表10-4列出了pandas中的频率代码和日期偏移量类。
注意: 用户可以根据实际需求自定义一些频率类以便提供pandas所没有的日期逻辑,但具体的细节超出了本书的范围。


WOM日期
WOM(Week Of Month)是一种非常实用的频率类,它以WOM开头。它使你能获得诸如“每月第3个星期五”之类的日期:
- In [397]: rng = pd.date_range('1/1/2012', '9/1/2012', freq='WOM-3FRI')
- In [398]: list(rng)
- Out[398]:
- [<Timestamp: 2012-01-20 00:00:00>,
- <Timestamp: 2012-02-17 00:00:00>,
- <Timestamp: 2012-03-16 00:00:00>,
- <Timestamp: 2012-04-20 00:00:00>,
- <Timestamp: 2012-05-18 00:00:00>,
- <Timestamp: 2012-06-15 00:00:00>,
- <Timestamp: 2012-07-20 00:00:00>,
- <Timestamp: 2012-08-17 00:00:00>]
美国的股票期权交易人会意识到这些日子就是标准的月度到期日。
移动(超前和滞后)数据
移动(shifting)指的是沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变:
- In [399]: ts = Series(np.random.randn(4),
- ...: index=pd.date_range('1/1/2000', periods=4, freq='M'))
- In [400]: ts In [401]: ts.shift(2) In [402]: ts.shift(-2)
- Out[400]: Out[401]: Out[402]:
- 2000-01-31 0.575283 2000-01-31 NaN 2000-01-31 1.814582
- 2000-02-29 0.304205 2000-02-29 NaN 2000-02-29 1.634858
- 2000-03-31 1.814582 2000-03-31 0.575283 2000-03-31 NaN
- 2000-04-30 1.634858 2000-04-30 0.304205 2000-04-30 NaN
- Freq: M Freq: M Freq: M
shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达:
- ts / ts.shift(1) - 1
由于单纯的移位操作不会修改索引,所以部分数据会被丢弃。因此,如果频率已知,则可以将其传给shift以便实现对时间戳进行位移而不是对数据进行简单位移:
- In [403]: ts.shift(2, freq='M')
- Out[403]:
- 2000-03-31 0.575283
- 2000-04-30 0.304205
- 2000-05-31 1.814582
- 2000-06-30 1.634858
- Freq: M
这里还可以使用其他频率,于是你就能非常灵活地对数据进行超前和滞后处理了:
- In [404]: ts.shift(3, freq='D') In [405]: ts.shift(1, freq='3D')
- Out[404]: Out[405]:
- 2000-02-03 0.575283 2000-02-03 0.575283
- 2000-03-03 0.304205 2000-03-03 0.304205
- 2000-04-03 1.814582 2000-04-03 1.814582
- 2000-05-03 1.634858 2000-05-03 1.634858
- In [406]: ts.shift(1, freq='90T')
- Out[406]:
- 2000-01-31 01:30:00 0.575283
- 2000-02-29 01:30:00 0.304205
- 2000-03-31 01:30:00 1.814582
- 2000-04-30 01:30:00 1.634858
通过偏移量对日期进行位移
pandas的日期偏移量还可以用在datetime或Timestamp对象上:
- In [407]: from pandas.tseries.offsets import Day, MonthEnd
- In [408]: now = datetime(2011, 11, 17)
- In [409]: now + 3 * Day()
- Out[409]: datetime.datetime(2011, 11, 20, 0, 0)
如果加的是锚点偏移量(比如MonthEnd),第一次增量会将原日期向前滚动到符合频率规则的下一个日期译注5:
- In [410]: now + MonthEnd()
- Out[410]: datetime.datetime(2011, 11, 30, 0, 0)
- In [411]: now + MonthEnd(2)
- Out[411]: datetime.datetime(2011, 12, 31, 0, 0)
通过锚点偏移量的rollforward和rollback方法,可显式地将日期向前或向后“滚动”:
- In [412]: offset = MonthEnd()
- In [413]: offset.rollforward(now)
- Out[413]: datetime.datetime(2011, 11, 30, 0, 0)
- In [414]: offset.rollback(now)
- Out[414]: datetime.datetime(2011, 10, 31, 0, 0)
日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法:
- In [415]: ts = Series(np.random.randn(20),
- ...: index=pd.date_range('1/15/2000', periods=20, freq='4d'))
- In [416]: ts.groupby(offset.rollforward).mean()
- Out[416]:
- 2000-01-31 -0.448874
- 2000-02-29 -0.683663
- 2000-03-31 0.251920
当然,更简单、更快速地实现该功能的办法是使用resample(稍后将对此进行详细介绍):
- In [417]: ts.resample('M', how='mean')
- Out[417]:
- 2000-01-31 -0.448874
- 2000-02-29 -0.683663
- 2000-03-31 0.251920
- Freq: M
译注5:拿本例来说,就是第一次位移的量可能没有一个月那么长,就在当月。
