读写文本格式的数据
因为其简单的文件交互语法、直观的数据结构,以及诸如元组打包解包之类的便利功能,Python在文本和文件处理方面已经成为一门招人喜欢的语言。
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。表6-1对它们进行了总结,其中read_csv和read_table可能会是你今后用得最多的。
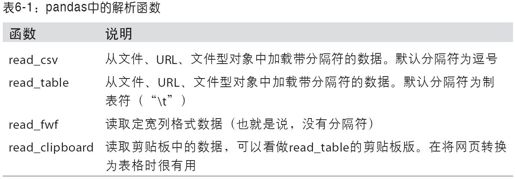
我将大致介绍一下这些函数在将文本数据转换为DataFrame时所用到的一些技术。这些函数的选项可以划分为以下几个大类:
·索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
·类型推断和数据转换:包括用户定义值的转换、缺失值标记列表等。
·日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
·迭代:支持对大文件进行逐块迭代。
·不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
类型推断(type inference)是这些函数中最重要的功能之一,也就是说,你不需要指定列的类型到底是数值、整数、布尔值,还是字符串。日期和其他自定义类型的处理需要多花点工夫才行。首先我们来看一个以逗号分隔的(CSV)文本文件:
- In [846]: !cat ch06/ex1.csv译注1
- a,b,c,d,message
- 1,2,3,4,hello
- 5,6,7,8,world
- 9,10,11,12,foo
由于该文件以逗号分隔,所以我们可以使用read_csv将其读入一个DataFrame:
- In [847]: df = pd.read_csv('ch06/ex1.csv')
- In [848]: df
- Out[848]:
- a b c d message
- 0 1 2 3 4 hello
- 1 5 6 7 8 world
- 2 9 10 11 12 foo
我们也可以用read_table,只不过需要指定分隔符而已:
- In [849]: pd.read_table('ch06/ex1.csv', sep=',')
- Out[849]:
- a b c d message
- 0 1 2 3 4 hello
- 1 5 6 7 8 world
- 2 9 10 11 12 foo
注意:这里我用的是cat这个UNIX shell命令将文本的原始内容打印到屏幕上。如果你用的是Windows,则可以使用type来达到同样的目的。
并不是所有文件都有标题行。看看下面这个文件:
- In [850]: !cat ch06/ex2.csv
- 1,2,3,4,hello
- 5,6,7,8,world
- 9,10,11,12,foo
读入该文件的办法有两个。你可以让pandas为其分配默认的列名,也可以自己定义列名:
- In [851]: pd.read_csv('ch06/ex2.csv', header=None)
- Out[851]:
- X.1 X.2 X.3 X.4 X.5
- 0 1 2 3 4 hello
- 1 5 6 7 8 world
- 2 9 10 11 12 foo
- In [852]: pd.read_csv('ch06/ex2.csv', names=['a', 'b', 'c', 'd', 'message'])
- Out[852]:
- a b c d message
- 0 1 2 3 4 hello
- 1 5 6 7 8 world
- 2 9 10 11 12 foo
假设你希望将message列做成DataFrame的索引。你可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定"message":
- In [853]: names = ['a', 'b', 'c', 'd', 'message']
- In [854]: pd.read_csv('ch06/ex2.csv', names=names, index_col='message')
- Out[854]:
- a b c d
- message
- hello 1 2 3 4
- world 5 6 7 8
- foo 9 10 11 12
如果希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的列表即可:
- In [855]: !cat ch06/csv_mindex.csv
- key1,key2,value1,value2
- one,a,1,2
- one,b,3,4
- one,c,5,6
- one,d,7,8
- two,a,9,10
- two,b,11,12
- two,c,13,14
- two,d,15,16
- In [856]: parsed = pd.read_csv('ch06/csv_mindex.csv', index_col=['key1', 'key2'])
- In [857]: parsed
- Out[857]:
- value1 value2
- key1 key2
- one a 1 2
- b 3 4
- c 5 6
- d 7 8
- two a 9 10
- b 11 12
- c 13 14
- d 15 16
有些表格可能不是用固定的分隔符去分隔字段的(比如空白符或其他模式译注2)。对于这种情况,可以编写一个正则表达式来作为read_table的分隔符。看看下面这个文本文件:
- In [858]: list(open('ch06/ex3.txt'))
- Out[858]:
- [' A B C\n',
- 'aaa -0.264438 -1.026059 -0.619500\n',
- 'bbb 0.927272 0.302904 -0.032399\n',
- 'ccc -0.264273 -0.386314 -0.217601\n',
- 'ddd -0.871858 -0.348382 1.100491\n']
该文件各个字段由数量不定的空白符分隔,虽然你可以对其做一些手工调整,但这个情况还是处理比较好。本例的这个情况可以用正则表达式\s+表示,于是我们就有了:
- In [859]: result = pd.read_table('ch06/ex3.txt', sep='\s+')
- In [860]: result
- Out[860]:
- A B C
- aaa -0.264438 -1.026059 -0.619500
- bbb 0.927272 0.302904 -0.032399
- ccc -0.264273 -0.386314 -0.217601
- ddd -0.871858 -0.348382 1.100491
这里,由于列名比数据行的数量少译注3,所以read_table推断第一列应该是DataFrame的索引。
这些解析器函数还有许多参数可以帮助你处理各种各样的异形文件格式(参见表6-2)。比如说,你可以用skiprows跳过文件的第一行、第三行和第四行:
- In [861]: !cat ch06/ex4.csv
- # hey!
- a,b,c,d,message
- # just wanted to make things more difficult for you
- # who reads CSV files with computers, anyway?
- 1,2,3,4,hello
- 5,6,7,8,world
- 9,10,11,12,foo
- In [862]: pd.read_csv('ch06/ex4.csv', skiprows=[0, 2, 3])
- Out[862]:
- a b c d message
- 0 1 2 3 4 hello
- 1 5 6 7 8 world
- 2 9 10 11 12 foo
缺失值处理是文件解析任务中的一个重要组成部分。缺失数据经常是要么没有(空字符串),要么用某个标记值表示。默认情况下,pandas会用一组经常出现的标记值进行识别,如NA、-1.#IND以及NULL等:
- In [863]: !cat ch06/ex5.csv
- something,a,b,c,d,message
- one,1,2,3,4,NA
- two,5,6,,8,world
- three,9,10,11,12,foo
- In [864]: result = pd.read_csv('ch06/ex5.csv')
- In [865]: result
- Out[865]:
- something a b c d message
- 0 one 1 2 3 4 NaN
- 1 two 5 6 NaN 8 world
- 2 three 9 10 11 12 foo
- In [866]: pd.isnull(result)
- Out[866]:
- something a b c d message
- 0 False False False False False True
- 1 False False False True False False
- 2 False False False False False False
na_values可以接受一组用于表示缺失值的字符串:
- In [867]: result = pd.read_csv('ch06/ex5.csv', na_values=['NULL'])
- In [868]: result
- Out[868]:
- something a b c d message
- 0 one 1 2 3 4 NaN
- 1 two 5 6 NaN 8 world
- 2 three 9 10 11 12 foo
可以用一个字典为各列指定不同的NA标记值:
- In [869]: sentinels = {'message': ['foo', 'NA'], 'something': ['two']}
- In [870]: pd.read_csv('ch06/ex5.csv', na_values=sentinels)
- Out[870]:
- something a b c d message
- 0 one 1 2 3 4 NaN
- 1 NaN 5 6 NaN 8 world
- 2 three 9 10 11 12 NaN



逐块读取文本文件
在处理很大的文件时,或找出大文件中的参数集以便于后续处理时,你可能只想读取文件的一小部分或逐块对文件进行迭代。
- In [871]: result = pd.read_csv('ch06/ex6.csv')
- In [872]: result
- Out[872]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 10000 entries, 0 to 9999
- Data columns:
- one 10000 non-null values
- two 10000 non-null values
- three 10000 non-null values
- four 10000 non-null values
- key 10000 non-null values
- dtypes: float64(4), object(1)
如果只想读取几行(避免读取整个文件),通过nrows进行指定即可:
- In [873]: pd.read_csv('ch06/ex6.csv', nrows=5)
- Out[873]:
- one two three four key
- 0 0.467976 -0.038649 -0.295344 -1.824726 L
- 1 -0.358893 1.404453 0.704965 -0.200638 B
- 2 -0.501840 0.659254 -0.421691 -0.057688 G
- 3 0.204886 1.074134 1.388361 -0.982404 R
- 4 0.354628 -0.133116 0.283763 -0.837063 Q
要逐块读取文件,需要设置chunksize(行数):
- In [874]: chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
- In [875]: chunker
- Out[875]: <pandas.io.parsers.TextParser at 0x8398150>
read_csv所返回的这个TextParser对象使你可以根据chunksize对文件进行逐块迭代。比如说,我们可以迭代处理ex6.csv,将值计数聚合到"key"列中,如下所示:
- chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)
- tot = Series([])
- for piece in chunker:
- tot = tot.add(piece['key'].value_counts(), fill_value=0)
- tot = tot.order(ascending=False)
于是我们就有了:
- In [877]: tot[:10]
- Out[877]:
- E 368
- X 364
- L 346
- O 343
- Q 340
- M 338
- J 337
- F 335
- K 334
- H 330
TextParser还有一个get_chunk方法,它使你可以读取任意大小的块。
将数据写出到文本格式
数据也可以被输出为分隔符格式的文本。我们再来看看之前读过的一个CSV文件:
- In [878]: data = pd.read_csv('ch06/ex5.csv')
- In [879]: data
- Out[879]:
- something a b c d message
- 0 one 1 2 3 4 NaN
- 1 two 5 6 NaN 8 world
- 2 three 9 10 11 12 foo
利用DataFrame的to_csv方法,我们可以将数据写到一个以逗号分隔的文件中:
- In [880]: data.to_csv('ch06/out.csv')
- In [881]: !cat ch06/out.csv
- ,something,a,b,c,d,message
- 0,one,1,2,3.0,4,
- 1,two,5,6,,8,world
- 2,three,9,10,11.0,12,foo
当然,还可以使用其他分隔符(由于这里直接写出到sys.stdout,所以仅仅是打印出文本结果而已):
- In [882]: data.to_csv(sys.stdout, sep='|')
- |something|a|b|c|d|message
- 0|one|1|2|3.0|4|
- 1|two|5|6||8|world
- 2|three|9|10|11.0|12|foo
缺失值在输出结果中会被表示为空字符串。你可能希望将其表示为别的标记值:
- In [883]: data.to_csv(sys.stdout, na_rep='NULL')
- ,something,a,b,c,d,message
- 0,one,1,2,3.0,4,NULL
- 1,two,5,6,NULL,8,world
- 2,three,9,10,11.0,12,foo
如果没有设置其他选项,则会写出行和列的标签。当然,它们也都可以被禁用:
- In [884]: data.to_csv(sys.stdout, index=False, header=False)
- one,1,2,3.0,4,
- two,5,6,,8,world
- three,9,10,11.0,12,foo
此外,你还可以只写出一部分的列,并以你指定的顺序排列:
- In [885]: data.to_csv(sys.stdout, index=False, cols=['a', 'b', 'c'])
- a,b,c
- 1,2,3.0
- 5,6,
- 9,10,11.0
Series也有一个to_csv方法:
- In [886]: dates = pd.date_range('1/1/2000', periods=7)
- In [887]: ts = Series(np.arange(7), index=dates)
- In [888]: ts.to_csv('ch06/tseries.csv')
- In [889]: !cat ch06/tseries.csv
- 2000-01-01 00:00:00,0
- 2000-01-02 00:00:00,1
- 2000-01-03 00:00:00,2
- 2000-01-04 00:00:00,3
- 2000-01-05 00:00:00,4
- 2000-01-06 00:00:00,5
- 2000-01-07 00:00:00,6
虽然只需一点整理工作(无header行,第一列作索引)就能用read_csv将CSV文件读取为Series,但还有一个更为方便的from_csv方法:
- In [890]: Series.from_csv('ch06/tseries.csv', parse_dates=True)
- Out[890]:
- 2000-01-01 0
- 2000-01-02 1
- 2000-01-03 2
- 2000-01-04 3
- 2000-01-05 4
- 2000-01-06 5
- 2000-01-07 6
更多信息请在IPython中查看to_csv和from_csv的文档。
手工处理分隔符格式
大部分存储在磁盘上的表格型数据都能用pandas.read_table进行加载。然而,有时还是需要做一些手工处理。由于接收到含有畸形行的文件而使read_table出毛病的情况并不少见。为了说明这些基本工具,看看下面这个简单的CSV文件:
- In [891]: !cat ch06/ex7.csv
- "a","b","c"
- "1","2","3"
- "1","2","3","4"
对于任何单字符分隔符文件,可以直接使用Python内置的csv模块。将任意已打开的文件或文件型的对象传给csv.reader:
- import csv
- f = open('ch06/ex7.csv')
- reader = csv.reader(f)
对这个reader进行迭代将会为每行产生一个元组译注4(并移除了所有的引号):
- In [893]: for line in reader:
- ....: print line
- ['a', 'b', 'c']
- ['1', '2', '3']
- ['1', '2', '3', '4']
现在,为了使数据格式合乎要求,你需要对其做一些整理工作:
- In [894]: lines = list(csv.reader(open('ch06/ex7.csv')))
- In [895]: header, values = lines[0], lines[1:]
- In [896]: data_dict = {h: v for h, v in zip(header, zip(*values))}
- In [897]: data_dict
- Out[897]: {'a': ('1', '1'), 'b': ('2', '2'), 'c': ('3', '3')}
CSV文件的形式有很多。只需定义csv.Dialect的一个子类即可定义出新格式(如专门的分隔符、字符串引用约定、行结束符等):
- class my_dialect(csv.Dialect):
- lineterminator = '\n'
- delimiter = ';'
- quotechar = '"'
- reader = csv.reader(f, diaect=my_dialect)
各个CSV语支的参数也可以关键字的形式提供给csv.reader,而无需定义子类:
- reader = csv.reader(f, delimiter='|')
可用的选项(csv.Dialect的属性)及其功能如表6-3所示。

注意:对于那些使用复杂分隔符或多字符分隔符的文件,csv模块就无能为力了。这种情况下,你就只能使用字符串的split方法或正则表达式方法re.split进行行拆分和其他整理工作了。
要手工输出分隔符文件,你可以使用csv.writer。它接受一个已打开且可写的文件对象以及跟csv.reader相同的那些语支和格式化选项:
- with open('mydata.csv', 'w') as f:
- writer = csv.writer(f, dialect=my_dialect)
- writer.writerow(('one', 'two', 'three'))
- writer.writerow(('1', '2', '3'))
- writer.writerow(('4', '5', '6'))
- writer.writerow(('7', '8', '9'))
JSON数据
JSON(JavaScript Object Notation的简称)已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。它是一种比表格型文本格式(如CSV)灵活得多的数据格式。下面是一个例子:
- obj = """
- {"name": "Wes",
- "places_lived": ["United States", "Spain", "Germany"],
- "pet": null,
- "siblings": [{"name": "Scott", "age": 25, "pet": "Zuko"},
- {"name": "Katie", "age": 33, "pet": "Cisco"}]
- }
- """
除其空值null和一些其他的细微差别(如列表末尾不允许存在多余的逗号)之外,JSON非常接近于有效的Python代码。基本类型有对象(字典)、数组(列表)、字符串、数值、布尔值以及null。对象中所有的键都必须是字符串。许多Python库都可以读写JSON数据。我将使用json,因为它是构建于Python标准库中的。通过json.loads即可将JSON字符串转换成Python形式:
- In [899]: import json
- In [900]: result = json.loads(obj)
- In [901]: result
- Out[901]:
- {u'name': u'Wes',
- u'pet': None,
- u'places_lived': [u'United States', u'Spain', u'Germany'],
- u'siblings': [{u'age': 25, u'name': u'Scott', u'pet': u'Zuko'},
- {u'age': 33, u'name': u'Katie', u'pet': u'Cisco'}]}
相反,json.dumps则将Python对象转换成JSON格式:
- In [902]: asjson = json.dumps(result)
如何将(一个或一组)JSON对象转换为DataFrame或其他便于分析的数据结构就由你决定了。最简单方便的方式是:向DataFrame构造器传入一组JSON对象,并选取数据字段的子集译注5。
- In [903]: siblings = DataFrame(result['siblings'], columns=['name', 'age'])
- In [904]: siblings
- Out[904]:
- name age
- 0 Scott 25
- 1 Katie 33
第7章中关于USDA Food Database的那个例子进一步讲解了JSON数据的读取和处理(包括嵌套记录)。
注意:pandas团队正致力于为pandas添加原生的高效JSON导出(to_json)和解码(from_json)功能。不过目前还没开发完成。
XML和HTML:Web信息收集
Python有许多可以读写HTML和XML格式数据的库。lxml(http://lxml.de)就是其中之一,它能够高效且可靠地解析大文件。lxml有多个编程接口。首先我要用lxml.html处理HTML,然后再用lxml.objectify做一些XML处理。
许多网站都将数据放到HTML表格中以便在浏览器中查看,但不能以一种更易于机器阅读的格式(如JSON、HTML或XML)进行下载。我发现Yahoo!Finance的股票期权数据就是这样。可能你对这种数据不熟悉:期权是指使你有权从现在开始到未来某个时间(到期日)内以某个特定价格(执行价)买进(看涨期权)或卖出(看跌期权)某公司股票的衍生合约。人们的看涨和看跌期权交易有多种执行价和到期日,这些数据都可以在Yahoo!Finance的各种表格中找到。
首先,找到你希望获取数据的URL,利用urllib2将其打开,然后用lxml解析得到的数据流,如下所示:
- from lxml.html import parse
- from urllib2 import urlopen
- parsed = parse(urlopen('http://finance.yahoo.com/q/op?s=AAPL+Options'))
- doc = parsed.getroot()
通过这个对象,你可以获取特定类型的所有HTML标签(tag),比如含有所需数据的table标签。给这个简单的例子加点启发性,假设你想得到该文档中所有的URL链接。HTML中的链接是a标签。使用文档根节点的findall方法以及一个XPath(对文档的“查询”的一种表示手段):
- In [906]: links = doc.findall('.//a')
- In [907]: links[15:20]
- Out[907]:
- [<Element a at 0x6c488f0>,
- <Element a at 0x6c48950>,
- <Element a at 0x6c489b0>,
- <Element a at 0x6c48a10>,
- <Element a at 0x6c48a70>]
但这些是表示HTML元素的对象。要得到URL和链接文本,你必须使用各对象的get方法(针对URL)和text_content方法(针对显示文本):
- In [908]: lnk = links[28]
- In [909]: lnk
- Out[909]: <Element a at 0x6c48dd0>
- In [910]: lnk.get('href')
- Out[910]: 'http://biz.yahoo.com/special.html'
- In [911]: lnk.text_content()
- Out[911]: 'Special Editions'
因此,编写下面这条列表推导式(list comprehension)即可获取文档中的全部URL:
- In [912]: urls = [lnk.get('href') for lnk in doc.findall('.//a')]
- In [913]: urls[-10:]
- Out[913]:
- ['http://info.yahoo.com/privacy/us/yahoo/finance/details.html',
- 'http://info.yahoo.com/relevantads/',
- 'http://docs.yahoo.com/info/terms/',
- 'http://docs.yahoo.com/info/copyright/copyright.html',
- 'http://help.yahoo.com/l/us/yahoo/finance/forms_index.html',
- 'http://help.yahoo.com/l/us/yahoo/finance/quotes/fitadelay.html',
- 'http://help.yahoo.com/l/us/yahoo/finance/quotes/fitadelay.html',
- 'http://www.capitaliq.com',
- 'http://www.csidata.com',
- 'http://www.morningstar.com/']
现在,从文档中找出正确表格的办法就是反复试验了。有些网站会给目标表格加上一个id属性。我确定有两个分别放置看涨数据和看跌数据的表格:
- tables = doc.findall('.//table')
- calls = tables[9]
- puts = tables[13]
每个表格都有一个标题行,然后才是数据行:
- In [915]: rows = calls.findall('.//tr')
对于标题行和数据行,我们希望获取每个单元格内的文本。对于标题行,就是th单元格,而对于数据行,则是td单元格:
- def _unpack(row, kind='td'):
- elts = row.findall('.//%s' % kind)
- return [val.text_content() for val in elts]
这样,我们就得到了:
- In [917]: _unpack(rows[0], kind='th')
- Out[917]: ['Strike', 'Symbol', 'Last', 'Chg', 'Bid', 'Ask', 'Vol', 'Open Int']
- In [918]: _unpack(rows[1], kind='td')
- Out[918]:
- ['295.00',
- 'AAPL120818C00295000',
- '310.40',
- ' 0.00',
- '289.80',
- '290.80',
- '1',
- '169']
现在,把所有步骤结合起来,将数据转换为一个DataFrame。由于数值型数据仍然是字符串格式,所以我们希望将部分列(可能不是全部)转换为浮点数格式。虽然你可以手工实现该功能,但是pandas恰好就有一个TextParser类可用于自动类型转换(read_csv和其他解析函数其实在内部都用到了它):
- from pandas.io.parsers import TextParser
- def parse_options_data(table):
- rows = table.findall('.//tr')
- header = _unpack(rows[0], kind='th')
- data = [_unpack(r) for r in rows[1:]]
- return TextParser(data, names=header).get_chunk()
最后,我对那两个lxml表格对象调用该解析函数并得到最终的DataFrame:
- In [920]: call_data = parse_options_data(calls)
- In [921]: put_data = parse_options_data(puts)
- In [922]: call_data[:10]
- Out[922]:
- Strike Symbol Last Chg Bid Ask Vol Open Int
- 0 295 AAPL120818C00295000 310.40 0.0 289.80 290.80 1 169
- 1 300 AAPL120818C00300000 277.10 1.7 284.80 285.60 2 478
- 2 305 AAPL120818C00305000 300.97 0.0 279.80 280.80 10 316
- 3 310 AAPL120818C00310000 267.05 0.0 274.80 275.65 6 239
- 4 315 AAPL120818C00315000 296.54 0.0 269.80 270.80 22 88
- 5 320 AAPL120818C00320000 291.63 0.0 264.80 265.80 96 173
- 6 325 AAPL120818C00325000 261.34 0.0 259.80 260.80 N/A 108
- 7 330 AAPL120818C00330000 230.25 0.0 254.80 255.80 N/A 21
- 8 335 AAPL120818C00335000 266.03 0.0 249.80 250.65 4 46
- 9 340 AAPL120818C00340000 272.58 0.0 244.80 245.80 4 30
利用lxml.objectify解析XML
XML(Extensible Markup Language)是另一种常见的支持分层、嵌套数据以及元数据的结构化数据格式。本书所使用的这些文件实际上来自于一个很大的XML文档。
之前,我介绍了lxml库及其lxml.html接口。这里我将介绍另一个用于操作XML数据的接口,即lxml.objectify。
纽约大都会运输署(Metropolitan Transportation Authority,MTA)发布了一些有关其公交和列车服务的数据资料(http://www.mta.info/developers/download.html)。这里,我们将看看包含在一组XML文件中的运行情况数据。每项列车或公交服务都有各自的文件(如Metro-North Railroad的文件是Performance_MNR.xml译注6),其中每条XML记录就是一条月度数据,如下所示:
- <INDICATOR>
- <INDICATOR_SEQ>373889</INDICATOR_SEQ>
- <PARENT_SEQ></PARENT_SEQ>
- <AGENCY_NAME>Metro-North Railroad</AGENCY_NAME>
- <INDICATOR_NAME>Escalator Availability</INDICATOR_NAME>
- <DESCRIPTION>Percent of the time that escalators are operational
- systemwide. The availability rate is based on physical observations performed the morning of regular business days only. This is a new indicator the agency began reporting in 2009.</DESCRIPTION>
- <PERIOD_YEAR>2011</PERIOD_YEAR>
- <PERIOD_MONTH>12</PERIOD_MONTH>
- <CATEGORY>Service Indicators</CATEGORY>
- <FREQUENCY>M</FREQUENCY>
- <DESIRED_CHANGE>U</DESIRED_CHANGE>
- <INDICATOR_UNIT>%</INDICATOR_UNIT>
- <DECIMAL_PLACES>1</DECIMAL_PLACES>
- <YTD_TARGET>97.00</YTD_TARGET>
- <YTD_ACTUAL></YTD_ACTUAL>
- <MONTHLY_TARGET>97.00</MONTHLY_TARGET>
- <MONTHLY_ACTUAL></MONTHLY_ACTUAL>
- </INDICATOR>
我们先用lxml.objectify解析该文件,然后通过getroot得到该XML文件的根节点的引用:
- from lxml import objectify
- path = 'Performance_MNR.xml'
- parsed = objectify.parse(open(path))
- root = parsed.getroot()
root.INDICATOR返回一个用于产生各个<INDICATOR>XML元素的生成器。对于每条记录,我们可以用标记名(如YTD_ACTUAL)和数据值填充一个字典(排除几个标记)译注7:
- data = []
- skip_fields = ['PARENT_SEQ', 'INDICATOR_SEQ', 'DESIRED_CHANGE', 'DECIMAL_PLACES']
- for elt in root.INDICATOR:
- el_data = {}
- for child in elt.getchildren():
- if child.tag in skip_fields:
- continue
- el_data[child.tag] = child.pyval
- data.append(el_data)
最后,将这组字典转换为一个DataFrame:
- In [927]: perf = DataFrame(data)
- In [928]: perf
- Out[928]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 648 entries, 0 to 647
- Data columns:
- AGENCY_NAME 648 non-null values
- CATEGORY 648 non-null values
- DESCRIPTION 648 non-null values
- FREQUENCY 648 non-null values
- INDICATOR_NAME 648 non-null values
- INDICATOR_UNIT 648 non-null values
- MONTHLY_ACTUAL 648 non-null values
- MONTHLY_TARGET 648 non-null values
- PERIOD_MONTH 648 non-null values
- PERIOD_YEAR 648 non-null values
- YTD_ACTUAL 648 non-null values
- YTD_TARGET 648 non-null values
- dtypes: int64(2), object(10)
- Empty DataFrame
- Columns: array([], dtype=int64)
- Index: array([], dtype=int64)
XML数据可以比本例复杂得多。每个标记都可以有元数据。看看下面这个HTML的链接标记(它也算是一段有效的XML):
- from StringIO import StringIO
- tag = '<a href="http://www.google.com">Google</a>'
- root = objectify.parse(StringIO(tag)).getroot()
现在就可以访问链接文本或标记中的任何字段了(如href):
- In [930]: root
- Out[930]: <Element a at 0x88bd4b0>
- In [931]: root.get('href')
- Out[931]: 'http://www.google.com'
- In [932]: root.text
- Out[932]: 'Google'
译注1:还是那句话,作者用的是UNIX,Windows下得用type。
译注2:这里的“模式”一词表示的是“字符串”。如果对此概念较模糊,建议阅读《数据结构》。
译注3:准确的说法应该是:列名的数量比列的数量少1。完整的说法应该是:列名“行”中“有内容的”字段数量比其他数据“行”中“有内容的”字段数量少1。
译注4:很明显,这里得到的结果不是元组而是列表。
译注5:意思是说可以选一部分字段。当然也可以全部选完。
译注6:该文件已经更名,但还是可以下载到相关的文件。
译注7:由于数据文件格式已经改变,所以这段代码不能直接执行了,需要按照新的数据格式稍微调整一下,不过也不麻烦,留给读者当做练习吧。
