绘制地图:图形化显示海地地震危机数据
Ushahidi是一家非营利软件公司,人们可以通过短信向其提供有关自然灾害和地缘政治事件的信息。这些数据集会被发布在他们的网站(http://community.ushahidi.com/research/datasets/)上以供分析和图形化。我下载了2010年海地地震及其余震期间搜集的数据。在本节中,我将告诉你如何利用pandas以及其他目前已经学过的工具处理这些数据,以便为分析和图形化工作做准备。从上面的链接下载好这个CSV文件之后,就可以用read_csv将其加载到DataFrame中了:
- In [94]: data = pd.read_csv('ch08/Haiti.csv')
- In [95]: data
- Out[95]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 3593 entries, 0 to 3592
- Data columns:
- Serial 3593 non-null values
- INCIDENT TITLE 3593 non-null values
- INCIDENT DATE 3593 non-null values
- LOCATION 3593 non-null values
- DESCRIPTION 3593 non-null values
- CATEGORY 3587 non-null values
- LATITUDE 3593 non-null values
- LONGITUDE 3593 non-null values
- APPROVED 3593 non-null values
- VERIFIED 3593 non-null values
- dtypes: float64(2), int64(1), object(7)
现在来处理一下这些数据,看看哪些是我们想要的。每一行表示一条从某人的手机上发送的紧急或其他问题的报告。每条报告都有一个时间戳和位置(经度和纬度):
- In [96]: data[['INCIDENT DATE', 'LATITUDE', 'LONGITUDE']][:10]
- Out[96]:
- INCIDENT DATE LATITUDE LONGITUDE
- 0 05/07/2010 17:26 18.233333 -72.533333
- 1 28/06/2010 23:06 50.226029 5.729886
- 2 24/06/2010 16:21 22.278381 114.174287
- 3 20/06/2010 21:59 44.407062 8.933989
- 4 18/05/2010 16:26 18.571084 -72.334671
- 5 26/04/2010 13:14 18.593707 -72.310079
- 6 26/04/2010 14:19 18.482800 -73.638800
- 7 26/04/2010 14:27 18.415000 -73.195000
- 8 15/03/2010 10:58 18.517443 -72.236841
- 9 15/03/2010 11:00 18.547790 -72.410010
CATEGORY字段含有一组以逗号分隔的代码,这些代码表示消息的类型:
- In [97]: data['CATEGORY'][:6]
- Out[97]:
- 0 1. Urgences | Emergency, 3. Public Health,
- 1 1. Urgences | Emergency, 2. Urgences logistiques
- 2 2. Urgences logistiques | Vital Lines, 8. Autre |
- 3 1. Urgences | Emergency,
- 4 1. Urgences | Emergency,
- 5 5e. Communication lines down,
- Name: CATEGORY
只要仔细观察一下上面这个数据摘要,就能发现有些分类信息缺失了,因此我们需要丢弃这些数据点。此外,调用describe还能发现数据中存在一些异常的地理位置:
- In [98]: data.describe()
- Out[98]:
- Serial LATITUDE LONGITUDE
- count 3593.000000 3593.000000 3593.000000
- mean 2080.277484 18.611495 -72.322680
- std 1171.100360 0.738572 3.650776
- min 4.000000 18.041313 -74.452757
- 25% 1074.000000 18.524070 -72.417500
- 50% 2163.000000 18.539269 -72.335000
- 75% 3088.000000 18.561820 -72.293570
- max 4052.000000 50.226029 114.174287
清除错误位置信息并移除缺失分类信息是一件很简单的事情:
- In [99]: data = data[(data.LATITUDE > 18) & (data.LATITUDE < 20) &
- ...: (data.LONGITUDE > -75) & (data.LONGITUDE < -70)
- ...: & data.CATEGORY.notnull()]
现在,我们想根据分类对数据做一些分析或图形化工作,但是各个分类字段中可能含有多个分类。此外,各个分类信息不仅有一个编码,还有一个英文名称(可能还有一个法语名称)。因此需要对数据做一些规整化处理。首先,我编写了两个函数译注5,一个用于获取所有分类的列表,另一个用于将各个分类信息拆分为编码和英语名称:
- def to_cat_list(catstr):
- stripped = (x.strip() for x in catstr.split(','))
- return [x for x in stripped if x]
- def get_all_categories(cat_series):
- cat_sets = (set(to_cat_list(x)) for x in cat_series)
- return sorted(set.union(*cat_sets))
- def get_english(cat):
- code, names = cat.split('.')
- if '|' in names:
- names = names.split(' | ')[1]
- return code, names.strip()
你可以测试一下get_english函数是否工作正常:
- In [101]: get_english('2. Urgences logistiques | Vital Lines')
- Out[101]: ('2', 'Vital Lines')
接下来,我做了一个将编码跟名称映射起来的字典,这是因为我们等会儿要用编码进行分析。后面我们在修饰图表时也会用到这个(注意,这里用的是生成器表达式,而不是列表推导式):
- In [102]: all_cats = get_all_categories(data.CATEGORY)
- # 生成器表达式
- In [103]: english_mapping = dict(get_english(x) for x in all_cats)
- In [104]: english_mapping['2a']
- Out[104]: 'Food Shortage'
- In [105]: english_mapping['6c']
- Out[105]: 'Earthquake and aftershocks'
根据分类选取记录的方式有很多,其中之一是添加指标(或哑变量)列,每个分类一列。为此,我们首先抽取出唯一的分类编码,并构造一个全零DataFrame(列为分类编码,索引跟data的索引一样):
- def get_code(seq):
- return [x.split('.')[0] for x in seq if x]
- all_codes = get_code(all_cats)
- code_index = pd.Index(np.unique(all_codes))
- dummy_frame = DataFrame(np.zeros((len(data), len(code_index))), index=data.index,
- columns=code_index)
如果一切顺利,dummy_frame应该是这样的:
- In [107]: dummy_frame.ix[:, :6]
- Out[107]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 3569 entries, 0 to 3592
- Data columns:
- 1 3569 non-null values
- 1a 3569 non-null values
- 1b 3569 non-null values
- 1c 3569 non-null values
- 1d 3569 non-null values
- 2 3569 non-null values
- dtypes: float64(6)
你可能已经想到了,现在应该将各行中适当的项设置为1,然后再与data进行连接:
- for row, cat in zip(data.index, data.CATEGORY):
- codes = get_code(to_cat_list(cat))
- dummy_frame.ix[row, codes] = 1
- data = data.join(dummy_frame.add_prefix('category_'))
现在data有了一些新的列:
- In [109]: data.ix[:, 10:15]
- Out[109]:
- <class 'pandas.core.frame.DataFrame'>
- Int64Index: 3569 entries, 0 to 3592
- Data columns:
- category_1 3569 non-null values
- category_1a 3569 non-null values
- category_1b 3569 non-null values
- category_1c 3569 non-null values
- category_1d 3569 non-null values
- dtypes: float64(5)
接下来开始画图吧!由于这是空间坐标数据,因此我们希望把数据绘制在海地的地图上。basemap工具集(http://matplotlib.github.com/basemap,matplotlib的一个插件)使得我们能够用Python在地图上绘制2D数据。basemap提供了许多不同的地球投影以及一种将地球上的经纬度坐标投影转换为二维matplotlib图的方式。经过一遍又一遍地尝试,我编写了下面这个函数,它可以绘制出一张简单的黑白海地地图:
- from mpl_toolkits.basemap import Basemap
- import matplotlib.pyplot as plt
- def basic_haiti_map(ax=None, lllat=17.25, urlat=20.25,
- lllon=-75, urlon=-71):
- # 创建极球面投影的Basemap实例。
- m = Basemap(ax=ax, projection='stere',
- lon_0=(urlon + lllon) / 2,
- lat_0=(urlat + lllat) / 2,
- llcrnrlat=lllat, urcrnrlat=urlat,
- llcrnrlon=lllon, urcrnrlon=urlon,
- resolution='f')
- # 绘制海岸线、州界、国界以及地图边界。
- m.drawcoastlines()
- m.drawstates()
- m.drawcountries()
- return m
现在的问题是,如何让返回的这个Basemap对象知道该怎样将坐标转换到画布上。我编写了下面的代码来绘制数据。对于每一个分类,我在数据集中找到了对应的坐标,并在适当的subplot中绘制一个Basemap,转换坐标,然后通过Basemap的plot方法绘制点:
- fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
- fig.subplots_adjust(hspace=0.05, wspace=0.05)
- to_plot = ['2a', '1', '3c', '7a']
- lllat=17.25; urlat=20.25; lllon=-75; urlon=-71
- for code, ax in zip(to_plot, axes.flat):
- m = basic_haiti_map(ax, lllat=lllat, urlat=urlat,
- lllon=lllon, urlon=urlon)
- cat_data = data[data['category_%s' % code] == 1]
- # 计算地图的投影坐标。
- x, y = m(cat_data.LONGITUDE, cat_data.LATITUDE)
- m.plot(x, y, 'k.', alpha=0.5)
- ax.set_title('%s: %s' % (code, english_mapping[code]))
最终结果如图8-24所示。
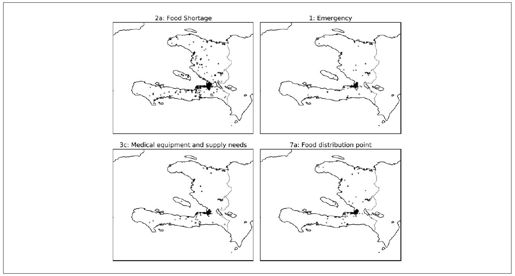
图8-24:海地地震的4类数据
从图中可以看出,大部分数据都集中在人口最稠密的城市——太子港。basemap还可以叠加来自shapefile的地图数据。我先下载了一个带有太子港道路的shapefile(参见http://cegrp.cga.harvard.edu/haiti/?q=resources_data)。Basemap对象有一个非常方便的readshapefile方法,于是在解压完道路数据文件之后,我只在代码中加以下几行就可以了:
- shapefile_path = 'ch08/PortAuPrince_Roads/PortAuPrince_Roads'
- m.readshapefile(shapefile_path, 'roads')
在对经纬度边界进行了一番尝试之后,我做了一张反映食物短缺情况的图片,如图8-25所示。
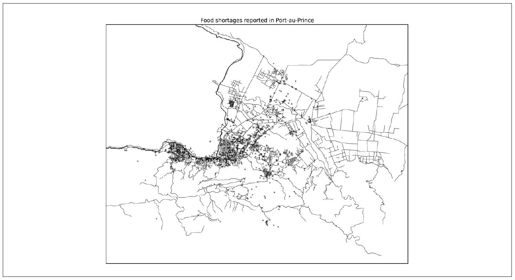
图8-25:海地大地震期间,太子港的食物短缺报告
译注5:读者就当做两个吧。
