数据结构和序列
Python的数据结构简单而强大。精通其用法是成为专家级Python程序员的关键环节。
元组
元组(tuple)是一种一维的、定长的、不可变的Python对象序列。最简单的创建方式是一组以逗号隔开的值:
- In [356]: tup = 4, 5, 6
- In [357]: tup
- Out[357]: (4, 5, 6)
在更复杂的表达式中定义元组时,常常需要用圆括号将值围起来,比如下面这个例子,它创建了一个由元组组成的元组:
- In [358]: nested_tup = (4, 5, 6), (7, 8)
- In [359]: nested_tup
- Out[359]: ((4, 5, 6), (7, 8))
通过调用tuple,任何序列或迭代器都可以被转换为元组:
- In [360]: tuple([4, 0, 2])
- Out[360]: (4, 0, 2)
- In [361]: tup = tuple('string')
- In [362]: tup
- Out[362]: ('s', 't', 'r', 'i', 'n', 'g')
跟大部分其他序列类型一样,元组的元素也可以通过方括号([])进行访问。跟C、C++、Java之类的语言一样,Python中的序列也是从0开始索引的:
- In [363]: tup[0]
- Out[363]: 's'
虽然存储在元组中的对象本身可能是可变的,但一旦创建完毕,存放在各个插槽中的对象就不能再被修改了:
- In [364]: tup = tuple(['foo', [1, 2], True])
- In [365]: tup[2] = False
- ---------------------------------------------------------------------------
- TypeError Traceback (most recent call last)
- <ipython-input-365-c7308343b841> in <module>()
- ----> 1 tup[2] = False
- TypeError: 'tuple' object does not support item assignment
- # 不过
- In [366]: tup[1].append(3)
- In [367]: tup
- Out[367]: ('foo', [1, 2, 3], True)
元组可以通过加号(+)运算符连接起来以产生更长的元组:
- In [368]: (4, None, 'foo') + (6, 0) + ('bar',)
- Out[368]: (4, None, 'foo', 6, 0, 'bar')
跟列表一样,对一个元组乘以一个整数,相当于是连接该元组的多个副本。
- In [369]: ('foo', 'bar') * 4
- Out[369]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar')
注意,对象本身是不会被复制的,这里涉及的只是它们的引用而已。
元组拆包
如果对元组型变量表达式进行赋值,Python就会尝试将等号右侧的值进行拆包(unpacking):
- In [370]: tup = (4, 5, 6)
- In [371]: a, b, c = tup
- In [372]: b
- Out[372]: 5
即使是嵌套元组也能被拆包:
- In [373]: tup = 4, 5, (6, 7)
- In [374]: a, b, (c, d) = tup
- In [375]: d
- Out[375]: 7
利用该功能可以非常轻松地交换变量名。这个任务在其他许多语言中可能是下面这个样子:
- tmp = a
- a = b
- b = tmp
- b, a = a, b
变量拆包功能常用于对由元组或列表组成的序列进行迭代:
- seq = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
- for a, b, c in seq:
- pass
另一个常见用法是处理从函数中返回的多个值。稍后将详细介绍。
元组方法
由于元组的大小和内存不能被修改,所以其实例方法很少。最有用的是count(对列表也是如此),它用于计算指定值的出现次数:
- In [376]: a = (1, 2, 2, 2, 3, 4, 2)
- In [377]: a.count(2)
- Out[377]: 4
列表
跟元组相比,列表(list)是变长的,而且其内容也是可以修改的。它可以通过方括号([])或list函数进行定义:
- In [378]: a_list = [2, 3, 7, None]
- In [379]: tup = ('foo', 'bar', 'baz')
- In [380]: b_list = list(tup) In [381]: b_list
- Out[381]: ['foo', 'bar', 'baz']
- In [382]: b_list[1] = 'peekaboo' In [383]: b_list
- Out[383]: ['foo', 'peekaboo', 'baz']
列表和元组在语义上是差不多的,都是一维序列,因此它们在许多函数中是可以互换的。
添加和移除元素
通过append方法,可以将元素添加到列表的末尾:
- In [384]: b_list.append('dwarf')
- In [385]: b_list
- Out[385]: ['foo', 'peekaboo', 'baz', 'dwarf']
利用insert可以将元素插入到列表的指定位置:
- In [386]: b_list.insert(1, 'red')
- In [387]: b_list
- Out[387]: ['foo', 'red', 'peekaboo', 'baz', 'dwarf']
警告: insert的计算量要比append大,因为后续的引用必须被移动以便为新元素腾地方。
insert的逆运算是pop,它用于移除并返回指定索引处的元素:
- In [388]: b_list.pop(2)
- Out[388]: 'peekaboo'
- In [389]: b_list
- Out[389]: ['foo', 'red', 'baz', 'dwarf']
remove用于按值删除元素,它找到第一个符合要求的值然后将其从列表中删除:
- In [390]: b_list.append('foo')
- In [391]: b_list.remove('foo')
- In [392]: b_list
- Out[392]: ['red', 'baz', 'dwarf', 'foo']
如果不考虑(使用append和remove时的)性能,Python列表可以是一种非常不错的“多重集合”数据结构。
通过in关键字,你可以判断列表中是否含有某个值:
- In [393]: 'dwarf' in b_list
- Out[393]: True
注意,判断列表是否含有某个值的操作比字典(dict)和集合(set)慢得多,因为Python会对列表中的值进行线性扫描,而另外两个(基于哈希表)则可以瞬间完成判断。
合并列表
跟元组一样,用加号(+)将两个列表加起来即可实现合并:
- In [394]: [4, None, 'foo'] + [7, 8, (2, 3)]
- Out[394]: [4, None, 'foo', 7, 8, (2, 3)]
对于一个已定义的列表,可以用extend方法一次性添加多个元素:
- In [395]: x = [4, None, 'foo']
- In [396]: x.extend([7, 8, (2, 3)])
- In [397]: x
- Out[397]: [4, None, 'foo', 7, 8, (2, 3)]
注意,列表的合并是一种相当费资源的操作,因为必须创建一个新列表并将所有对象复制过去。而用extend将元素附加到现有列表(尤其是在构建一个大列表时)就会好很多。因此,
- everything = []
- for chunk in list_of_lists:
- everything.extend(chunk)
要比等价的合并操作快得多
- everything = []
- for chunk in list_of_lists:
- everything = everything + chunk
排序
调用列表的sort方法可以实现就地排序(无需创建新对象):
- In [398]: a = [7, 2, 5, 1, 3]
- In [399]: a.sort()
- In [400]: a
- Out[400]: [1, 2, 3, 5, 7]
sort有几个很不错的选项。一个是次要排序键,即一个能够产生可用于排序的值的函数。例如,我们可以通过长度对一组字符串进行排序:
- In [401]: b = ['saw', 'small', 'He', 'foxes', 'six']
- In [402]: b.sort(key=len)
- In [403]: b
- Out[403]: ['He', 'saw', 'six', 'small', 'foxes']
二分搜索及维护有序列表
内置的bisect模块实现了二分查找以及对有序列表的插入操作。bisect.bisect可以找出新元素应该被插入到哪个位置才能保持原列表的有序性,而bisect.insort则确实地将新元素插入到那个位置上去:
- In [404]: import bisect
- In [405]: c = [1, 2, 2, 2, 3, 4, 7]
- In [406]: bisect.bisect(c, 2)
- Out[406]: 4
- In [407]: bisect.bisect(c, 5)
- Out[407]: 6
- In [408]: bisect.insort(c, 6)
- In [409]: c
- Out[409]: [1, 2, 2, 2, 3, 4, 6, 7]
警告: bisect模块的函数不会判断原列表是否是有序的,因为这样做的开销太大了。因此,将它们用于无序列表虽然不会报错,但可能会导致不正确的结果。
切片
通过切片标记法,你可以选取序列类型(数组、元组、NumPy数组等)的子集,其基本形式由索引运算符([])以及传入其中的start:stop构成:
- In [410]: seq = [7, 2, 3, 7, 5, 6, 0, 1]
- In [411]: seq[1:5]
- Out[411]: [2, 3, 7, 5]
切片还可以被赋值为一段序列:
- In [412]: seq[3:4] = [6, 3]
- In [413]: seq
- Out[413]: [7, 2, 3, 6, 3, 5, 6, 0, 1]
由于start索引处的元素是被包括在内的,而stop索引处的元素是未被包括在内的,所以结果中的元素数量是stop start。
start或stop都是可以省略的,此时它们分别默认为序列的起始处和结尾处:
- In [414]: seq[:5] In [415]: seq[3:]
- Out[414]: [7, 2, 3, 6, 3] Out[415]: [6, 3, 5, 6, 0, 1]
负数索引从序列的末尾开始切片:
- In [416]: seq[-4:] In [417]: seq[-6:-2]
- Out[416]: [5, 6, 0, 1] Out[417]: [6, 3, 5, 6]
切片的语法需要花点时间去适应,尤其是当你原来用的是R或MATLAB时。图A-2形象地说明了正整数和负整数的切片过程。
还可以在第二个冒号后面加上步长(step)。比如每隔一位取出一个元素:
- In [418]: seq[::2]
- Out[418]: [7, 3, 3, 6, 1]
在这里使用-1是一个很巧妙的办法,它可以实现列表或元组的反序:
- In [419]: seq[::-1]
- Out[419]: [1, 0, 6, 5, 3, 6, 3, 2, 7]
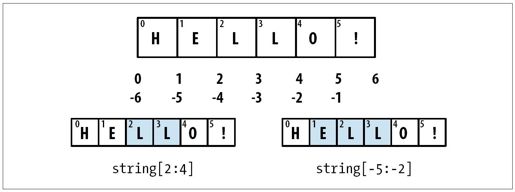
图A-2:Python的切片方式
内置的序列函数
Python有一些很不错的序列函数,你应该熟悉它们,只要有机会就用。
enumerate
在对一个序列进行迭代时,常常需要跟踪当前项的索引。下面是一种DIY的办法:
- i = 0
- for value in collection:
- # 用value做一些事情
- i += 1
由于这种事情很常见,所以Python就内置了一个enumerate函数,它可以逐个返回序列的(i,value)元组:
- for i, value in enumerate(collection):
- # 用value做一些事情
在对数据进行索引时,enumerate还有一种不错的使用模式,即求取一个将序列值(假定是唯一的)映射到其所在位置的字典。
- In [420]: some_list = ['foo', 'bar', 'baz']
- In [421]: mapping = dict((v, i) for i, v in enumerate(some_list))
- In [422]: mapping
- Out[422]: {'bar': 1, 'baz': 2, 'foo': 0}
sorted
sorted函数可以将任何序列返回为一个新的有序列表:
- In [423]: sorted([7, 1, 2, 6, 0, 3, 2])
- Out[423]: [0, 1, 2, 2, 3, 6, 7]
- In [424]: sorted('horse race')
- Out[424]: [' ', 'a', 'c', 'e', 'e', 'h', 'o', 'r', 'r', 's']
常常将sorted和set结合起来使用以得到一个由序列中的唯一元素组成的有序列表:
- In [425]: sorted(set('this is just some string'))
- Out[425]: [' ', 'e', 'g', 'h', 'i', 'j', 'm', 'n', 'o', 'r', 's', 't', 'u']
zip
zip用于将多个序列(列表、元组等)中的元素“配对”,从而产生一个新的元组列表:
- In [426]: seq1 = ['foo', 'bar', 'baz']
- In [427]: seq2 = ['one', 'two', 'three']
- In [428]: zip(seq1, seq2)
- Out[428]: [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
zip可以接受任意数量的序列,最终得到的元组数量由最短的序列决定:
- In [429]: seq3 = [False, True]
- In [430]: zip(seq1, seq2, seq3)
- Out[430]: [('foo', 'one', False), ('bar', 'two', True)]
zip最常见的用法是同时迭代多个序列,还可以结合enumerate一起使用:
- In [431]: for i, (a, b) in enumerate(zip(seq1, seq2)):
- ...: print('%d: %s, %s' % (i, a, b))
- ...:
- 0: foo, one
- 1: bar, two
- 2: baz, three
对于“已压缩的”(zipped)序列,zip还有一个很巧妙的用法,即对该序列进行“解压”(unzip)。其实就是将一组行转换为一组列。其语法看起来有点神秘:
- In [432]: pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'),
- ...: ('Schilling', 'Curt')]
- In [433]: first_names, last_names = zip(*pitchers)
- In [434]: first_names
- Out[434]: ('Nolan', 'Roger', 'Schilling')
- In [435]: last_names
- Out[435]: ('Ryan', 'Clemens', 'Curt')
稍后我将详细讨论函数调用中星号(*)的用法。其实它相当于:
- zip(seq[0], seq[1], ..., seq[len(seq) - 1])
reversed
reversed用于按逆序迭代序列中的元素:
- In [436]: list(reversed(range(10)))
- Out[436]: [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
字典
字典(dict)可算是Python中最重要的内置数据结构。它更常见的名字是哈希映射(hash map)或相联数组(associative array)。它是一种大小可变的键值对集,其中的键(key)和值(value)都是Python对象。创建字典的方式之一是:使用大括号({})并用冒号分隔键和值。
- In [437]: empty_dict = {}
- In [438]: d1 = {'a' : 'some value', 'b' : [1, 2, 3, 4]}
- In [439]: d1
- Out[439]: {'a': 'some value', 'b': [1, 2, 3, 4]}
访问(以及插入、设置)元素的语法跟列表和元组是一样的:
- In [440]: d1[7] = 'an integer'
- In [441]: d1
- Out[441]: {7: 'an integer', 'a': 'some value', 'b': [1, 2, 3, 4]}
- In [442]: d1['b']
- Out[442]: [1, 2, 3, 4]
你可以判断字典中是否存在某个键,其语法跟在列表和元组中判断是否存在某个值是一样的:
- In [443]: 'b' in d1
- Out[443]: True
使用del关键字或pop方法(删除指定值之后将其返回)可以删除值:
- In [444]: d1[5] = 'some value'
- In [445]: d1['dummy'] = 'another value'
- In [446]: del d1[5]
- In [447]: ret = d1.pop('dummy')
- In [448]: ret
- Out[448]: 'another value'
keys和values方法分别用于获取键和值的列表。虽然键值对没有特定的顺序,但这两个函数会以相同的顺序输出键和值:
- In [449]: d1.keys() In [450]: d1.values()
- Out[449]: ['a', 'b', 7] Out[450]: ['some value', [1, 2, 3, 4], 'an integer']
警告: 如果你正在使用Python 3,则dict.keys()和dict.values()会返回迭代器而不是列表。
利用update方法,一个字典可以被合并到另一个字典中去:
- In [451]: d1.update({'b' : 'foo', 'c' : 12})
- In [452]: d1
- Out[452]: {7: 'an integer', 'a': 'some value', 'b': 'foo', 'c': 12}
从序列类型创建字典
有时你可能会想将两个序列中的元素两两配对地组成一个字典。粗略分析一下之后,你可能会写出这样的代码:
- mapping = {}
- for key, value in zip(key_list, value_list):
- mapping[key] = value
由于字典本质上就是一个二元元组集,所以我们完全可以用dict类型函数直接处理二元元组列表:
- In [453]: mapping = dict(zip(range(5), reversed(range(5))))
- In [454]: mapping
- Out[454]: {0: 4, 1: 3, 2: 2, 3: 1, 4: 0}
稍后我们将讨论有关字典推导式的知识,这是构造字典的另一种优雅的方式。
默认值
下面这样的逻辑很常见:
- if key in some_dict:
- value = some_dict[key]
- else:
- value = default_value
其实dict的get和pop方法可以接受一个可供返回的默认值,于是,上面的if-else块就可以被简单地写成:
- value = some_dict.get(key, default_value)
如果key不存在,则get默认返回None,而pop则会引发一个异常。在设置值的时候,常常会将字典中的值处理成别的集类型(比如列表)。例如,根据首字母对一组单词进行分类并最终产生一个由列表组成的字典:
- In [455]: words = ['apple', 'bat', 'bar', 'atom', 'book']
- In [456]: by_letter = {}
- In [457]: for word in words:
- ...: letter = word[0]
- ...: if letter not in by_letter:
- ...: by_letter[letter] = [word]
- ...: else:
- ...: by_letter[letter].append(word)
- ...:
- In [458]: by_letter
- Out[458]: {'a': ['apple', 'atom'], 'b': ['bat', 'bar', 'book']}
字典的setdefault方法刚好能达到这个目的。上面的if-else块可以写成:
- by_letter.setdefault(letter, []).append(word)
内置的collections模块有一个叫做defaultdict的类,它可以使该过程更简单。传入一个类型或函数(用于生成字典各插槽所使用的默认值)即可创建出一个defaultdict:
- from collections import defaultdict
- by_letter = defaultdict(list)
- for word in words:
- by_letter[word[0]].append(word)
defaultdict的初始化器只需要一个可调用对象(例如各种函数),并不需要明确的类型。因此,如果你想要将默认值设置为4,只需传入一个能够返回4的函数即可:
- counts = defaultdict(lambda: 4)
字典键的有效类型
虽然字典的值可以是任何Python对象,但键必须是不可变对象,如标量类型(整数、浮点数、字符串)或元组(元组中的所有对象也必须是不可变的)。这里的术语是可哈希性(hashability)译注7。通过hash函数,你可以判断某个对象是否是可哈希的(即可以用作字典的键):
- In [459]: hash('string')
- Out[459]: -9167918882415130555
- In [460]: hash((1, 2, (2, 3)))
- Out[460]: 1097636502276347782
- In [461]: hash((1, 2, [2, 3])) # 这里会失败,因为列表是可变的
- ---------------------------------------------------------------------------
- TypeError Traceback (most recent call last)
- <ipython-input-461-800cd14ba8be> in <module>()
- ----> 1 hash((1, 2, [2, 3])) # 这里会失败,因为列表是可变的
- TypeError: unhashable type: 'list'
如果要将列表当做键,最简单的办法就是将其转换成元组:
- In [462]: d = {}
- In [463]: d[tuple([1, 2, 3])] = 5
- In [464]: d
- Out[464]: {(1, 2, 3): 5}
集合
集合(set)是由唯一元素组成的无序集。你可以将其看成是只有键而没有值的字典。集合的创建方式有二:set函数或用大括号包起来的集合字面量:
- In [465]: set([2, 2, 2, 1, 3, 3])
- Out[465]: set([1, 2, 3])
- In [466]: {2, 2, 2, 1, 3, 3}
- Out[466]: set([1, 2, 3])
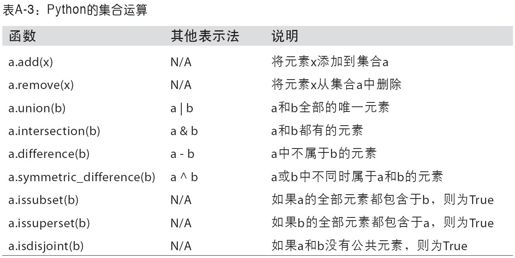
集合支持各种数学集合运算,如并、交、差以及对称差等。表A-3列出了常用的集合方法:
- In [467]: a = {1, 2, 3, 4, 5}
- In [468]: b = {3, 4, 5, 6, 7, 8}
- In [469]: a | b # 并(或)
- Out[469]: set([1, 2, 3, 4, 5, 6, 7, 8])
- In [470]: a & b # 交(与)
- Out[470]: set([3, 4, 5])
- In [471]: a - b # 差
- Out[471]: set([1, 2])
- In [472]: a ^ b # 对称差(异或)
- Out[472]: set([1, 2, 6, 7, 8])
你还可以判断一个集合是否是另一个集合的子集(原集合包含于新集合)或超集(原集合包含新集合):
- In [473]: a_set = {1, 2, 3, 4, 5}
- In [474]: {1, 2, 3}.issubset(a_set)
- Out[474]: True
- In [475]: a_set.issuperset({1, 2, 3})
- Out[475]: True
不难看出,如果两个集合的内容相等,则它们就是相等的:
- In [476]: {1, 2, 3} == {3, 2, 1}
- Out[476]: True
列表、集合以及字典的推导式
列表推导式是最受欢迎的Python语言特性之一。它使你能够非常简洁地构造一个新列表:只需一条简洁的表达式,即可对一组元素进行过滤,并对得到的元素进行转换变形。其基本形式如下:
- [expr for val in collection if condition]
这相当于下面这段for循环:
- result = []
- for val in collection:
- if condition:
- result.append(expr)
过滤器条件可以省略,只留下表达式。例如,给定一个字符串列表,我们可以滤除长度小于等于2的字符串,并将剩下的字符串转换成大写字母形式:
- In [477]: strings = ['a', 'as', 'bat', 'car', 'dove', 'python']
- In [478]: [x.upper() for x in strings if len(x) > 2]
- Out[478]: ['BAT', 'CAR', 'DOVE', 'PYTHON']
集合和字典的推导式是该思想的一种自然延伸,它们的语法差不多,只不过产生的是集合和字典而已。字典推导式的基本形式如下:
- dict_comp = {key-expr : value-expr for value in collection if condition}
集合推导式跟列表推导式非常相似,唯一的区别就是它用的是花括号而不是方括号:
- set_comp = {expr for value in collection if condition}
跟列表推导式一样,集合和字典的推导式也都只是语法糖而已,但它们确实能使代码变得更容易读写。再以上面那个字符串列表为例,假设我们想要构造一个集合,其内容为原列表字符串的各种长度。使用集合推导式即可轻松实现此功能:
- In [479]: unique_lengths = {len(x) for x in strings}
- In [480]: unique_lengths
- Out[480]: set([1, 2, 3, 4, 6])
再来看一个简单的字典推导式范例。我们可以为这些字符串创建一个指向其列表位置的映射关系:
- In [481]: loc_mapping = {val : index for index, val in enumerate(strings)}
- In [482]: loc_mapping
- Out[482]: {'a': 0, 'as': 1, 'bat': 2, 'car': 3, 'dove': 4, 'python': 5}
实际上,该字典还可以这样构造:
- loc_mapping = dict((val, idx) for idx, val in enumerate(strings))
依我看,字典推导式版的代码要更短也更清晰。
注意: 字典和集合的推导式是最近才加入到Python的(Python 2.7和Python 3.1+)。
嵌套列表推导式
假设我们有一个由男孩名列表和女孩名列表组成的列表(即列表的列表):
- In [483]: all_data = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
- ...: ['Susie', 'Casey', 'Jill', 'Ana', 'Eva', 'Jennifer', 'Stephanie']]
这些名字可能是从多个文件中读取出来的,而且专门将男孩女孩的名字分开。现在,假设我们想要找出带有两个以上(含)字母e的名字,并将它们放入一个新列表中。我们当然可以用一个简单的for循环来实现:
- names_of_interest = []
- for names in all_data:
- enough_es = [name for name in names if name.count('e') > 2]译注8
- names_of_interest.extend(enough_es)
实际上,整个运算过程完全可以写成一条嵌套列表推导式,如下所示:
- In [484]: result = [name for names in all_data for name in names
- ...: if name.count('e') >= 2]
- In [485]: result
- Out[485]: ['Jefferson', 'Wesley', 'Steven', 'Jennifer', 'Stephanie']
乍看起来,嵌套列表推导式确实不太好理解。推导式中for的部分是按嵌套顺序排列的,而过滤条件则还是跟之前一样是放在后面的。下面是另外一个例子,将一个由整数元组构成的列表“扁平化”为一个简单的整数列表:
- In [486]: some_tuples = [(1, 2, 3), (4, 5, 6), (7, 8, 9)]
- In [487]: flattened = [x for tup in some_tuples for x in tup]
- In [488]: flattened
- Out[488]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
其实你可以这样来记:嵌套for循环中各个for的顺序是怎样的,嵌套推导式中各个for表达式的顺序就是怎样的。
- flattened = []
- for tup in some_tuples:
- for x in tup:
- flattened.append(x)
你可以编写任意多层的嵌套,但是如果嵌套超过两三层的话,可能你就得思考一下数据结构设计有没有问题了。一定要注意上面那种语法跟“列表推导式中的列表推导式”之间的区别。比如下面这条语句也是正确的,但结果不同:
- In [229]: [[x for x in tup] for tup in some_tuples]
