3.5 最短摘要的生成
互联网搜索已经成为了大家工作和生活的一部分。在输入一些关键词之后,搜索引擎会返回许多结果,每个结果都包含一段概括网页内容的摘要。例如,在www.live.com中搜索“微软亚洲研究院使命”,第一个结果是微软亚洲研究院的首页,如图3-7所示。
在搜索结果中,标题和URL之间的内容就是我们所说的摘要:
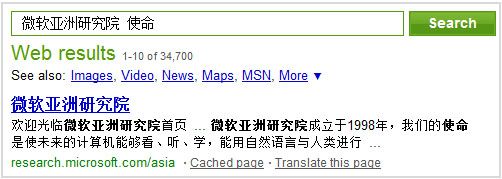
图3-7 搜索引擎中的最短摘要
这些最短摘要是怎样生成的呢?可以对问题进行如下的简化:
假设给定的已经是经过网页分词之后的结果,词语序列数组为W。其中W[0],W[1],…,W[N]为一些已经分好的词语。
假设用户输入的搜索关键词为数组Q。其中Q[0],Q[1],…,Q[m]为所有输入的搜索关键词。
这样,生成的最短摘要实际上就是一串相互联系的分词序列。比如从W[i]到W[j],其中,0<i<j<=N。例如图3-7中,“欢迎光临微软亚洲研究院首页”包含了所有的关键字——“微软亚洲研究院使命”。
分析与解法
【解法一】
在分析问题之前,先通过一个实际的例子来探讨。比如在微软亚洲研究院的主页上,有这么一段话:
“微软亚洲研究院成立于1998年,我们的使命是使未来的计算机能够看、听、学,能用自然语言与人类进行交流。在此基础上,微软亚洲研究院还将促进计算机在亚太地区的普及,改善亚太用户的计算体验。”
那么,我们可以猜想一下可能的分词结果就是:
“微软/亚洲/研究院/成立/于/1998/年/,/我们/的/使命/是/使/未来/的/计算机/能够/看/、/听/、/学/,/能/用/自然语言/与/人类/进行/交流/。/在/此/基础/上/,/微软/亚洲/研究院/还/将/促进/计算机/在/亚太/地区/的/普及/,/改善/亚太/用户/的/计算/体验/。/”
这也就是我们期望的W数组序列。
那么,我们可以看看这样的一个序列:

看了如上的序列之后,相信大家一定找到一些解题思路了吧:
1.从W数组的第一个位置开始查找出一段包含所有关键词数组Q的序列。计算当前的最短长度,并更新Seq数组。
2.对目标数组W进行遍历,从第二个位置开始,重新查找包含所有关键词数组Q的序列,同样计算出其最短长度,以及更新包含所有关键词的序列Seq,然后求出最短距离。
3.依次操作下去,一直到遍历至目标数组W的最后一个位置为止。
那么,这个算法的时间复杂度如何呢?
首先,要遍历所有其他的关键词(M),对于每个关键词,要遍历整个网页的词(N),而每个关键词在整个网页中的每一次出现,要遍历所有的Seq,以更新这个关键词与所有其他关键词的最小距离。
所以算法复杂度为:O(N2*M)。
【解法二】
前面的时间复杂度这么高,我们是否有办法降低呢?
相信你一定注意到了,进行查找的时候,总是重复地循环,效率不高。那么怎么简化呢?还是来看看这些序列:

问题在于,如何一次把所有的关键词都扫描到,并且不遗漏。扫描肯定是无法避免的,但是如何把两次扫描的结果联系起来呢?这是一个值得考虑的问题。
沿用前面的扫描方法,再来看看:
第一次扫描的时候,假设需要包含所有的关键词,将得到如下的结果:
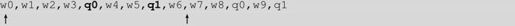
那么,下次扫描应该怎么办呢?显然,我们可以把第一个被扫描的位置挪到q0处。

如果把第一个被扫描的位置继续往后面移动一格,这样包含的序列中将减少了关键词q0。那么,如果我们把第二个扫描位置往后移,这样就可以找到下一个包含所有关键词的序列。如下:

这样,问题就和第一次扫描时碰到的情况一样了。依次扫描下去,在w中找出所有包含q的序列,并且找出其中的最小值,就可得到最终的结果。
示例代码如下所示:
代码清单3-8

小结
在上面的分析中,我们首先简化和抽象了问题,使之变成了一个容易理解的字符串匹配的问题。然后,在最简单的算法的基础之上,找出可能的简化方案,进而降低算法的复杂度。
在实际的面试中,面试者并没有期望应聘者第一次就能够给出最佳的解决方案。如果应聘者能够不断地深入分析问题,逐步找出更加可行的方案,将能够获得面试者的认可。
