2.2 单机存储引擎
存储引擎是存储系统的发动机,直接决定了存储系统能够提供的性能和功能。存储系统的基本功能包括:增、删、读、改,其中,读取操作又分为随机读取和顺序扫描。哈希存储引擎是哈希表的持久化实现,支持增、删、改,以及随机读取操作,但不支持顺序扫描,对应的存储系统为键值(Key-Value)存储系统;B树(B-Tree)存储引擎是B树的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描,对应的存储系统是关系数据库。当然,键值系统也可以通过B树存储引擎实现;LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,支持增、删、改、随机读取以及顺序扫描。它通过批量转储技术规避磁盘随机写入问题,广泛应用于互联网的后台存储系统,例如Google Bigtable、Google LevelDB以及Facebook开源的Cassandra系统。本节分别以Bitcask、MySQL InnoDB以及Google LevelDB系统为例介绍这三种存储引擎。
2.2.1 哈希存储引擎
Bitcask是一个基于哈希表结构的键值存储系统,它仅支持追加操作(Append-only),即所有的写操作只追加而不修改老的数据。在Bitcask系统中,每个文件有一定的大小限制,当文件增加到相应的大小时,就会产生一个新的文件,老的文件只读不写。在任意时刻,只有一个文件是可写的,用于数据追加,称为活跃数据文件(active data file)。而其他已经达到大小限制的文件,称为老数据文件(older data file)。
1.数据结构
如图2-6所示,Bitcask数据文件中的数据是一条一条的写入操作,每一条记录的数据项分别为主键(key)、value内容(value)、主键长度(key_sz)、value长度(value_sz)、时间戳(timestamp)以及crc校验值。(数据删除操作也不会删除旧的条目,而是将value设定为一个特殊的值用作标识)。内存中采用基于哈希表的索引数据结构,哈希表的作用是通过主键快速地定位到value的位置。哈希表结构中的每一项包含了三个用于定位数据的信息,分别是文件编号(file id),value在文件中的位置(value_pos),value长度(value_sz),通过读取file_id对应文件的value_pos开始的value_sz个字节,这就得到了最终的value值。写入时首先将Key-Value记录追加到活跃数据文件的末尾,接着更新内存哈希表,因此,每个写操作总共需要进行一次顺序的磁盘写入和一次内存操作。
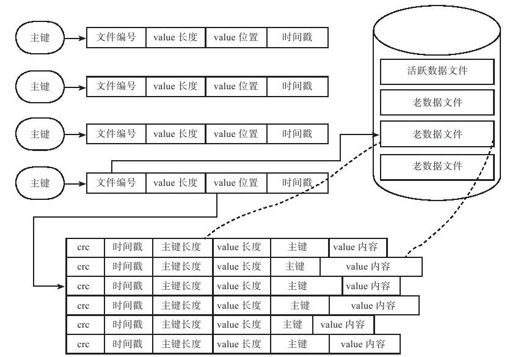
图 2-6 Bitcask数据结构
Bitcask在内存中存储了主键和value的索引信息,磁盘文件中存储了主键和value的实际内容。系统基于一个假设,value的长度远大于主键的长度。假如value的平均长度为1KB,每条记录在内存中的索引信息为32字节,那么,磁盘内存比为32:1。这样,32GB内存索引的数据量为32GB×32=1TB。
2.定期合并
Bitcask系统中的记录删除或者更新后,原来的记录成为垃圾数据。如果这些数据一直保存下去,文件会无限膨胀下去,为了解决这个问题,Bitcask需要定期执行合并(Compaction)操作以实现垃圾回收。所谓合并操作,即将所有老数据文件中的数据扫描一遍并生成新的数据文件,这里的合并其实就是对同一个key的多个操作以只保留最新一个的原则进行删除,每次合并后,新生成的数据文件就不再有冗余数据了。
3.快速恢复
Bitcask系统中的哈希索引存储在内存中,如果不做额外的工作,服务器断电重启重建哈希表需要扫描一遍数据文件,如果数据文件很大,这是一个非常耗时的过程。Bitcask通过索引文件(hint file)来提高重建哈希表的速度。
简单来说,索引文件就是将内存中的哈希索引表转储到磁盘生成的结果文件。Bitcask对老数据文件进行合并操作时,会产生新的数据文件,这个过程中还会产生一个索引文件,这个索引文件记录每一条记录的哈希索引信息。与数据文件不同的是,索引文件并不存储具体的value值,只存储value的位置(与内存哈希表一样)。这样,在重建哈希表时,就不需要扫描所有数据文件,而仅仅需要将索引文件中的数据一行行读取并重建即可,大大减少了重启后的恢复时间。
