10.2 只读事务
只读事务(SELECT语句),经过词法分析、语法分析,预处理后,转化为逻辑查询计划和物理查询计划。以SQL语句select c1,c2 from t1 where id=1 group by c1 order by c2为例,MergeServer收到该语句后将调用ObSql类的静态方法direct_execute,执行步骤如下:
1)调用flex、bison解析SQL语句生成一个语法树。
2)解析语法树,生成逻辑执行计划ObSelectStmt。ObSelectStmt结构中记录了SQL语句扫描的表格名(t1),投影列(c1,c2),过滤条件(id=1),分组列(c1)以及排序列(c2)。
3)根据逻辑执行计划生成物理执行计划。ObSelectStmt只是表达了一种意图,但并不知道实际如何执行,ObTransformer类的generate_physical_plan将ObSelectStmt转化为物理执行计划。
逻辑查询计划的改进以及物理查询计划的选择,即查询优化器,是关系数据库最难的部分,OceanBase目前在这一部分的工作不多。因此,本节不会涉及太多关于如何生成物理查询计划的内容,下面仅以两个例子说明OceanBase的物理查询计划。
例10-1 假设有一个单表SQL语句如图10-2所示。
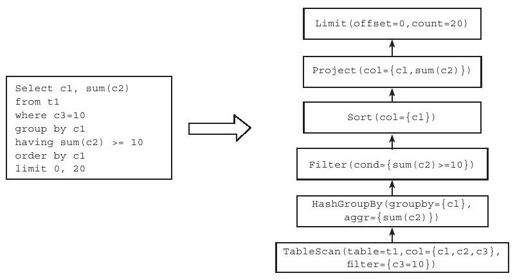
图 10-2 单表物理查询计划示例
单表SQL语句执行过程如下:
1)调用TableScan操作符,读取子表t1中的数据,该操作符还将执行投影(Project)和过滤(Filter),返回的结果只包含c3=10的数据行,且每行只包含c1、c2、c3三列。
2)调用HashGroupBy操作符(假设采用基于哈希的分组算法),按照c1对数据分组,同时计算每个分组内c2列的总和。
3)调用Filter操作符,过滤分组后生成的结果,只返回上一层sum(c2)>=10的行。
4)调用Sort操作符将结果按照c1排序。
5)调用Project操作符,只返回c1和sum(c2)这两列数据。
6)调用Limit操作符执行分页操作,只返回前20条数据。
例10-2 假设有一个需要联表的SQL语句如图10-3所示。
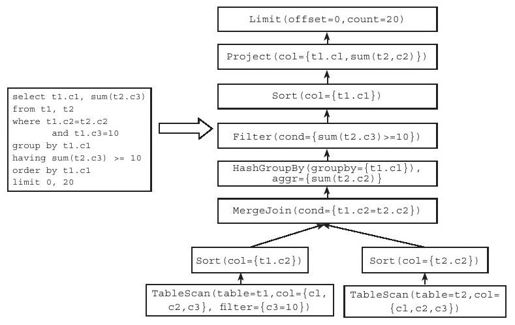
图 10-3 多表物理查询计划示例
多表SQL语句执行过程如下:
1)调用TableScan分别读取t1和t2的数据。对于t1,使用条件c3=10对结果进行过滤,t1和t2都只需要返回c1,c2,c3这三列数据。
2)假设采用基于排序的表连接算法,t1和t2分别按照t1.c2和t2.c2排序后,调用Merge Join运算符,以t1.c2=t2.c2为条件执行等值连接。
3)调用HashGroupBy运算符(假设采用基于哈希的分组算法),按照t1.c1对数据分组,同时计算每个分组内t2.c3列的总和。
4)调用Filter运算符,过滤分组后的生成的结果,只返回上一层sum(t2.c3)>=10的行。
5)调用Sort操作符将结果按照t1.c1排序。
6)调用Project操作符,只返回t1.c1和sum(t2.c3)这两列数据。
7)调用Limit操作符执行分页操作,只返回前20条数据。
10.2.1 物理操作符接口
9.4.2节介绍一期分布式存储引擎中的迭代器接口为ObIterator,通过它,可以将读到的数据以cell为单位逐个迭代出来。然而,数据库操作总是以行为单位的,因此,二期实现数据库功能层时考虑将基于cell的迭代器修改为基于行的迭代器。
行迭代器接口如下:
//ObRow表示一行数据内容
class ObRow
{
public:
//根据表ID以及列ID获得指定cell
//@param[in]table_id表格ID
//@param[in]column_id列ID
//@param[out]cell读到的cell
int get_cell(const uint64_t table_id,const uint64_t column_id,ObObj*&cell);
//获取第cell_idx个cell
int raw_get_cell(const int64_t cell_idx,const ObObj*&cell,uint64_t&table_id,
uint64_t&column_id);
//获取本行的列数
int64_t get_column_num()const;
};
每一行数据(ObRow)包括多个列,每个列的内容包括所在的表ID(table_id),列ID(column_id)以及列内容(cell)。ObRow提供两种访问方式:根据table_id和column_id随机访问某个列,以及根据列下标(cell_idx)获取某个指定列。
物理运算符接口如下:
//物理运算符接口
class ObPhyOperator
{
public:
//添加子运算符,所有非叶子节点物理运算符都需要调用该接口
virtual int set_child(int32_t child_idx,ObPhyOperator&child_operator);
//打开物理运算符。申请资源,打开子运算符等
virtual int open()=0;
//关闭物理运算符。释放资源,关闭子运算符等
virtual int close()=0;
//获得下一行数据内容
//@param[out]row下一行数据内容的引用
//@return返回码,包括成功、迭代过程中出现错误以及迭代完成
virtual int get_next_row(const ObRow*&row)=0;
};
ObPhyOperator每次获取一行数据,使用方法如下:
ObPhyOperator rootoperator=root_operator;//根运算符
root_operator->open();
ObRow*row=NULL;
while(OB_SUCCESS==root_operator->get_next_row(row))
{
Output(row);//输出本行
}
root_operator->close();
为什么ObPhyOperator类中有一个set_child接口呢?这是因为所有的物理运算符构成一个树,每个物理运算的输出结果都可以认为是一个临时的二维表,树中孩子节点的输出总是作为它的父亲节点的输入。例10-1中,叶子节点为一个TableScan类型的物理运算符(称为table_scan_op),它的父亲节点为一个HashGroupBy类型的物理运算符(称为hash_group_by_op),接下来依次为Filter类型物理运算符filter_op,Sort类型物理运算符sort_op,Project类型物理运算符project_op,Limit类型物理运算符limit_op。其中,limit_op为根运算符。那么,生成物理运算符时将执行如下语句:
limit_op->set_child(0,project_op);
project_op->set_child(0,sort_op);
sort_op->set_child(0,filter_op);
filter_op->set_child(0,hash_group_by_op);
hash_group_by_op->set_child(0,table_scan_op);
root_op=limit_op;
SQL最终执行时,只需要迭代root_op(即limit_op)就能够把需要的数据依次迭代出来。limit_op发现前一批数据迭代完成则驱动下层的project_op获取下一批数据,project_op发现前一批数据迭代完成则驱动下层的sort_op获取下一批数据。以此类推,直到最底层的table_scan_op不断地从原始表t1中读取数据。
