9.4.2 SSTable
如图9-8所示,SSTable中的数据按主键排序后存放在连续的数据块(Block)中,Block之间也有序。接着,存放数据块索引(Block Index),由每个Block最后一行的主键(End Key)组成,用于数据查询中的Block定位。接着,存放布隆过滤器(Bloom Filter)和表格的Schema信息。最后,存放固定大小的Trailer以及Trailer的偏移位置。
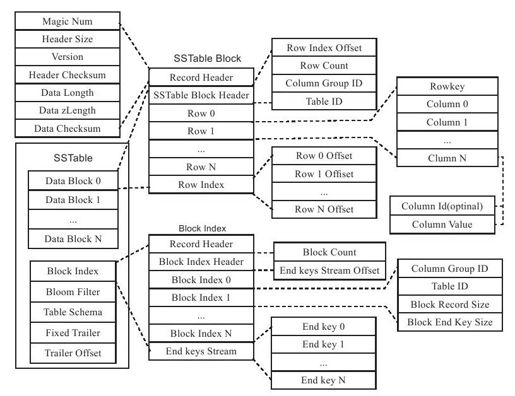
图 9-8 SSTable格式
查找SSTable时,首先从子表的索引信息中读取SSTable Trailer的偏移位置,接着获取Trailer信息。根据Trailer中记录的信息,可以获取块索引的大小和偏移,从而将整个块索引加载到内存中。根据块索引记录的每个Block的最后一行的主键,可以通过二分查找定位到查找的Block。最后将Block加载到内存中,通过二分查找Block中记录的行索引(Row Index)查找到具体某一行。本质上看,SSTable是一个两级索引结构:块索引以及行索引;而整个ChunkServer是一个三级索引结构:子表索引、块索引以及行索引。
SSTable分为两种格式:稀疏格式以及稠密格式。对于稀疏格式,某些列可能存在,也可能不存在,因此,每一行只存储包含实际值的列,每一列存储的内容为:<列ID,列值>(<Column ID,Column Value>);而稠密格式中每一行都需要存储所有列,每一列只需要存储列值,不需要存储列ID,这是因为列ID可以从表格Schema中获取。
例9-4 假设有一张表格包含10列,列ID为1~10,表格中有一行的数据内容为:

那么,如果采用稀疏格式存储,内容为:<2,20>,<3,30>,<5,50>,<7,70>,<8,80>;如果采用稠密格式存储,内容为:null,20,30,null,50,null,70,80,null,null。
ChunkServer中的SSTable为稠密格式,而UpdateServer中的SSTable为稀疏格式,且存储了多张表格的数据。另外,SSTable支持列组(Column Group),将同一个列组下的多个列的内容存储在一块。列组是一种行列混合存储模式,将每一行的所有列分成多个组(称为列组),每个列组内部按行存储。
如图9-9所示,当一个SSTable中包含多个表格/列组时,数据按照[表格ID,列组ID,行主键]([table_id,column group id,row_key])的形式有序存储。

图 9-9 SSTable包含多个表格/列组
另外,SSTable支持压缩功能,压缩以Block为单位。每个Block写入磁盘之前调用压缩算法执行压缩,读取时需要解压缩。用户可以自定义SSTable的压缩算法,目前支持的算法包括LZO以及Snappy。
SSTable的操作接口分为写入和读取两个部分,其中,写入类为ObSSTableWriter,读取类为ObSSTableGetter(随机读取)和ObSSTableScanner(范围查询)。代码如下:
class ObSSTableWriter
{
public:
//创建SSTable
//@param[in]schema表格schema信息
//@param[in]path SSTable在磁盘中的路径名
//@param[in]compressor_name压缩算法名
//@param[in]store_type SSTable格式,稀疏格式或者稠密格式
//@param[in]block_size块大小,默认64KB
int create_sstable(const ObSSTableSchema&schema,const ObString&path,const ObString&compressor_name,const int store_type,const int64_t block_size);
//往SSTable中追加一行数据
//@param[in]row一行SSTable数据
//@param[out]space_usage追加完这一行后SSTable大致占用的磁盘空间
int append_row(const ObSSTableRow&row,int64_t&space_usage);
//关闭SSTable,将往磁盘中写入Block Index,Bloom Filter,Schema,Trailer等信息
//@param[out]trailer_offset返回SSTable的Trailer偏移量
int close_sstable(int64_t&trailer_offset);
};
定期合并&数据分发过程将产生新的SSTable,步骤如下:
1)调用create_sstable函数创建一个新的SSTable;
2)不断调用append_row函数往SSTable中追加一行行数据;
3)调用close_sstable完成SSTable写入。
与9.2.1节中的MemTableIterator一样,ObSSTableGetter和ObSSTableScanner实现了迭代器接口,通过它可以不断地获取SSTable的下一个cell。
class ObIterator
{
public:
//迭代器移动到下一个cell
int next_cell();
//获取当前cell的内容
//@param[out]cell_info当前cell的内容,包括表名(table_id),行主键(row_key),列编号(column_id)以及列值(column_value)
int get_cell(ObCellInfo**cell_info);
//获取当前cell的内容
//@param[out]cell_info当前cell的内容
//@param is_row_changed是否迭代到下一行
int get_cell(ObCellInfo*cell_info,boolis_row_changed);
};
OceanBase读取的数据可能来源于MemTable,也可能来源于SSTable,或者是合并多个MemTable和多个SSTable生成的结果。无论底层数据来源如何变化,上层的读取接口总是ObIterator。
