第5章 分布式键值系统
分布式键值模型可以看成是分布式表格模型的一种特例。然而,由于它只支持针对单个key-value的增、删、查、改操作,因此,适用3.3.1节提到的哈希分布算法。
Amazon Dynamo是分布式键值系统,最初用于支持购物车应用。Dynamo将很多分布式技术融合到一个系统内,学习Dynamo的设计对理解分布式系统的理论很有帮助。当然,这个系统的主要价值在于学术层面,从工程的角度看,Dynamo牺牲了一致性,却没有换来什么好处,不适合直接模仿。
Tair是淘宝网开发的分布式键值系统,它借鉴了Dynamo系统的一些设计思路并做了一些创新,其中最大的变化就是从P2P架构修改为带有中心节点的架构,笔者认为,这种思路在大方向上是正确的。
本章首先详细介绍Amazon Dynamo的设计思路,接着介绍淘宝网的Tair系统。
5.1 Amazon Dynamo
Dynamo以很简单的键值方式存储数据,不支持复杂的查询。Dynamo中存储的是数据值的原始形式,不解析数据的具体内容。Dynamo主要用于Amazon的购物车及S3云存储服务。
Dynamo通过组合P2P的各种技术打造了线上可运行的分布式键值系统,表5-1中列出了Dynamo设计时面临的问题及最终采取的解决方案。

5.1.1 数据分布
Dynamo系统采用3.3.1节(见图3-2)中介绍的一致性哈希算法将数据分布到多个存储节点中。一致性哈希算法思想如下:给系统中每个节点分配一个随机token,这些token构成一个哈希环。执行数据存放操作时,先计算主键的哈希值,然后存放到顺时针方向第一个大于或者等于该哈希值的token所在的节点。一致性哈希的优点在于节点加入/删除时只会影响到在哈希环中相邻的节点,而对其他节点没影响。
考虑到节点的异构性,不同节点的处理能力差别可能很大,Dynamo使用了改进的一致性哈希算法:每个物理节点根据其性能的差异分配多个token,每个token对应一个“虚拟节点”。每个虚拟节点的处理能力基本相当,并随机分布在哈希空间中。存储时,数据按照哈希值落到某个虚拟节点负责的区域,然后被存储在该虚拟节点所对应的物理节点中。
如图5-1所示,某Dynamo集群中原来有3个节点,每个节点分配了3个token:节点1(1,4,7),节点2(2,3,8),节点3(0,5,6)。存放数据时,首先计算主键的哈希值,并根据哈希值将数据存放到对应token所在的节点。假设增加节点4,Dynamo集群可能会分别将节点1和节点3的token 1和token 5迁移到节点4,节点token分配情况变为:节点1(4,7),节点2(2,3,8),节点3(0,6)以及节点4(1,5)。这样就实现了自动负载均衡。
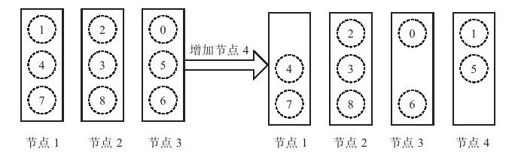
图 5-1 Dynamo虚拟节点
为了找到数据所属的节点,要求每个节点维护一定的集群信息用于定位。Dynamo系统中每个节点维护整个集群的信息,客户端也缓存整个集群的信息,因此,绝大部分请求能够一次定位到目标节点。
由于机器或者人为的因素,系统中的节点成员加入或者删除经常发生,为了保证每个节点缓存的都是Dynamo集群中最新的成员信息,所有节点每隔固定时间(比如1s)通过Gossip协议的方式从其他节点中任意选择一个与之通信的节点。如果连接成功,双方交换各自保存的集群信息。
Gossip协议用于P2P系统中自治的节点协调对整个集群的认识,比如集群的节点状态、负载情况。我们先看看两个节点A和B是如何交换对世界的认识的:
1)A告诉B其管理的所有节点的版本(包括Down状态和Up状态的节点);
2)B告诉A哪些版本它比较旧了,哪些版本它有最新的,然后把最新的那些节点发给A(处于Down状态的节点由于版本没有发生更新所以不会被关注);
3)A将B中比较旧的节点发送给B,同时将B发送来的最新节点信息做本地更新;
4)B收到A发来的最新节点信息后,对本地缓存的比较旧的节点做更新。
由于种子节点的存在,新节点加入可以做得比较简单。新节点加入时首先与种子节点交换集群信息,从而对集群有了认识。DHT(Distributed Hash Table,也称为一致性哈希表)环中原有的其他节点也会定期和种子节点交换集群信息,从而发现新节点的加入。
集群不断变化,可能随时有机器下线,因此,每个节点还需要定期通过Gossip协议同其他节点交换集群信息。如果发现某个节点很长时间状态都没有更新,比如距离上次更新的时间间隔超过一定的阈值,则认为该节点已经下线了。
