3.3.2 顺序分布
哈希散列破坏了数据的有序性,只支持随机读取操作,不能够支持顺序扫描。某些系统可以在应用层做折衷,比如互联网应用经常按照用户来进行数据拆分,并通过哈希方法进行数据分布,同一个用户的数据分布到相同的存储节点,允许对同一个用户的数据执行顺序扫描,由应用层解决跨多个用户的操作问题。另外,这种方式可能出现某些用户的数据量太大的问题,由于用户的数据限定在一个存储节点,无法发挥分布式存储系统的多机并行处理能力。
顺序分布在分布式表格系统中比较常见,一般的做法是将大表顺序划分为连续的范围,每个范围称为一个子表,总控服务器负责将这些子表按照一定的策略分配到存储节点上。如图3-3所示,用户表(User表)的主键范围为1~7000,在分布式存储系统中划分为多个子表,分别对应数据范围1~1000,1001~2000,……6001~7000。Meta表是可选的,某些系统只有根表(Root表)一级索引,在Root表中维护用户表的位置信息,即每个User子表在哪个存储节点上。为了支持更大的集群规模,Bigtable这样的系统将索引分为两级:根表以及元数据表(Meta表),由Meta表维护User表的位置信息,而Root表用来维护Meta表的位置信息。读User表时,需要通过Meta表查找相应的User子表所在的存储节点,而读取Meta表又需要通过Root表查找相应的Meta子表所在的存储节点。
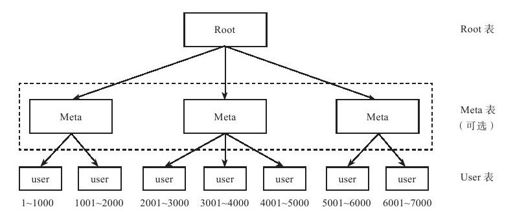
图 3-3 顺序分布
顺序分布与B+树数据结构比较类似,每个子表相当于叶子节点,随着数据的插入和删除,某些子表可能变得很大,某些变得很小,数据分布不均匀。如果采用顺序分布,系统设计时需要考虑子表的分裂与合并,这将极大地增加系统复杂度。子表分裂指当一个子表太大超过一定阀值时需要分裂为两个子表,从而有机会通过系统的负载均衡机制分散到多个存储节点。子表合并一般由数据删除引起,当相邻的两个子表都很小时,可以合并为一个子表。一般来说,单个服务节点能够服务的子表数量是有限的,比如4000~10000个,子表合并的目的是为了防止系统中出现过多太小的子表,减少系统中的元数据。
