13.5.4 Google Dremel
Google Dremel是Google的实时分析系统,可以扩展到上千台机器规模,处理PB级别的数据。Dremel还是Google Bigquery服务的底层存储和查询引擎。相比传统的并行数据库,Dremel的优势在于可扩展性,磁盘的顺序读取速度在100MB/s上下,而Dremel能够在1秒内处理1TB的数据,即使压缩率为10:1,也至少需要1000个磁盘并发读。
1.系统架构
Dremel系统融合了并行数据库和Web搜索技术。首先,它借鉴了Web搜索中的“查询树”的概念,将一个巨大复杂的查询,分割成大量较小的查询,使其能并发地在大量节点上执行。其次,和并行数据库类似,Dremel提供了一个SQL-like的接口,且支持列式存储。
如图13-14所示,Dremel采用多层并层级向上汇报的方式实现数据运算后的汇聚,即:
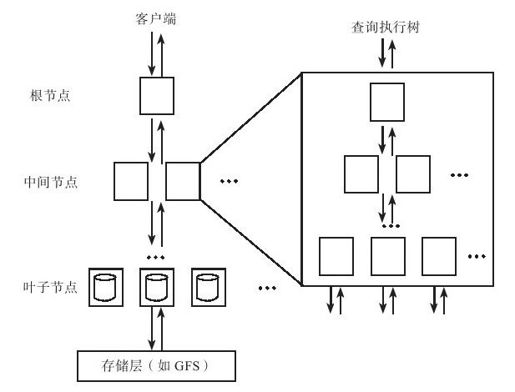
图 13-14 Dremel系统架构
●叶子节点执行查询后得到部分结果向上层中间节点汇报;
●中间节点再向上层中间节点汇报(此层可以重复几次或零次);
●中间节点向根节点汇报最终结果。
Dremel要求数据在向上层汇报中,是可以聚集的,也就是说,在逐级上报的过程中数据量不断变小,最终的结果不会很大,确保在一台机器能够承受的范围。
2.Dremel与MapReduce的比较
MapReduce的输出结果直接由reduce任务写入到分布式文件系统,因此,只要reduce任务个数足够多,输出结果可以很大;而Dremel中的最终数据汇聚到一个根节点,因此一般要求最终的结果集比较小,例如GB级别以下。
Dremel的优势在于实时性,只要服务器个数足够多,大部分情况下能够在3秒以内处理完成TB级别数据。
