第4章 分布式文件系统
分布式文件系统的主要功能有两个:一个是存储文档、图像、视频之类的Blob类型数据;另外一个是作为分布式表格系统的持久化层。
分布式文件系统中最为著名的莫过于Google File System(GFS),它构建在廉价的普通PC服务器之上,支持自动容错。GFS内部将大文件划分为大小约为64MB的数据块(chunk),并通过主控服务器(Master)实现元数据管理、副本管理、自动负载均衡等操作。其他文件系统,例如Taobao File System(TFS)、Facebook Haystack或多或少借鉴了GFS的思路,架构上都比较相近。
本章首先重点介绍GFS的内部实现机制,接着介绍TFS和Face book Haystack的内部实现。最后,本章还会简单介绍内容分发网络(Content Delivery Network,CDN)技术,这种技术能够将图像、视频之类的数据缓存在离用户“最近”的网络节点上,从而降低访问延时,节省带宽。
4.1 Google文件系统
Google文件系统(GFS)是构建在廉价服务器之上的大型分布式系统。它将服务器故障视为正常现象,通过软件的方式自动容错,在保证系统可靠性和可用性的同时,大大降低系统的成本。
GFS是Google分布式存储的基石,其他存储系统,如Google Bigtable、Google Megastore、Google Percolator均直接或者间接地构建在GFS之上。另外,Google大规模批处理系统MapReduce也需要利用GFS作为海量数据的输入输出。
4.1.1 系统架构
如图4-1所示,GFS系统的节点可分为三种角色:GFS Master(主控服务器)、GFS ChunkServer(CS,数据块服务器)以及GFS客户端。
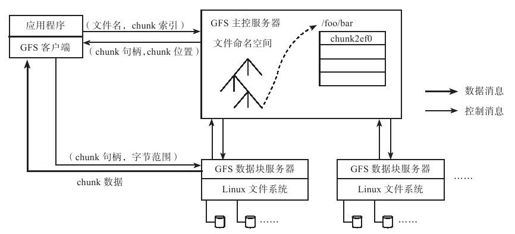
图 4-1 GFS整体架构
GFS文件被划分为固定大小的数据块(chunk),由主服务器在创建时分配一个64位全局唯一的chunk句柄。CS以普通的Linux文件的形式将chunk存储在磁盘中。为了保证可靠性,chunk在不同的机器中复制多份,默认为三份。
主控服务器中维护了系统的元数据,包括文件及chunk命名空间、文件到chunk之间的映射、chunk位置信息。它也负责整个系统的全局控制,如chunk租约管理、垃圾回收无用chunk、chunk复制等。主控服务器会定期与CS通过心跳的方式交换信息。
客户端是GFS提供给应用程序的访问接口,它是一组专用接口,不遵循POSIX规范,以库文件的形式提供。客户端访问GFS时,首先访问主控服务器节点,获取与之进行交互的CS信息,然后直接访问这些CS,完成数据存取工作。
需要注意的是,GFS中的客户端不缓存文件数据,只缓存主控服务器中获取的元数据,这是由GFS的应用特点决定的。GFS最主要的应用有两个:MapReduce与Bigtable。对于MapReduce,GFS客户端使用方式为顺序读写,没有缓存文件数据的必要;而Bigtable作为分布式表格系统,内部实现了一套缓存机制。另外,如何维护客户端缓存与实际数据之间的一致性是一个极其复杂的问题。
