9.3 UpdateServer实现机制
UpdateServer用于存储增量数据,它是一个单机存储系统,由如下几个部分组成:
●内存存储引擎,在内存中存储修改增量,支持冻结以及转储操作;
●任务处理模型,包括网络框架、任务队列、工作线程等,针对小数据包做了专门的优化;
●主备同步模块,将更新事务以操作日志的形式同步到备UpdateServer。
UpdateServer是OceanBase性能瓶颈点,核心是高效,实现时对锁(例如,无锁数据结构)、索引结构、内存占用、任务处理模型以及主备同步都需要做专门的优化。
9.3.1 存储引擎
UpdateServer存储引擎如图9-3所示。
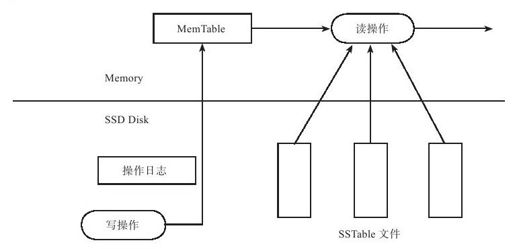
图 9-3 UpdateServer存储引擎
UpdateServer存储引擎与6.1节中提到的Bigtable存储引擎看起来很相似,不同点在于:
●UpdateServer只存储了增量修改数据,基线数据以SSTable的形式存储在 ChunkServer上,而Bigtable存储引擎同时包含某个子表的基线数据和增量数据;
●UpdateServer内部所有表格共用MemTable以及SSTable,而Bigtable中每个子表的MemTable和SSTable分开存放;
●UpdateServer的SSTable存储在SSD磁盘中,而Bigtable的SSTable存储在 GFS中。
UpdateServer存储引擎包含几个部分:操作日志、MemTable以及SSTable。更新操作首先记录到操作日志中,接着更新内存中活跃的MemTable(Active MemTable),活跃的MemTable到达一定大小后将被冻结,称为Frozen MemTable,同时创建新的Active MemTable。Frozen MemTable将以SSTable文件的形式转储到SSD磁盘中。
1.操作日志
OceanBase中有一个专门的提交线程负责确定多个写事务的顺序(即事务id),将这些写事务的操作追加到日志缓冲区,并将日志缓冲区的内容写入日志文件。为了防止写操作日志污染操作系统的缓存,写操作日志文件采用Direct IO的方式实现:
class ObLogWriter
{
public:
//write_log函数将操作日志存入日志缓冲区
int write_log(const LogCommand cmd,const char*log_data,const int64_t data_len);
//将日志缓冲区中的日志先同步到备机再写入主机磁盘
int flush_log(LogBuffer&tlog_buffer,const bool sync_to_slave=true,const bool is_master=true);
};
每条日志项由四部分组成:日志头+日志序号+日志类型(LogCommand)+日志内容,其中,日志头中记录了每条日志的校验和(checksum)。ObLogWriter中的write_log函数负责将操作日志拷贝到日志缓冲区中,如果日志缓冲区已满,则向调用者返回缓冲区不足(OB_BUF_NOT_ENOUGH)错误码。接着,调用者会通过flush_log将缓冲区中已有的日志内容同步到备机并写入主机磁盘。如果主机磁盘的最后一个日志文件超过指定大小(默认为64MB),还会调用switch_log函数切换日志文件。为了提高写性能,UpdateServer实现了成组提交(Group Commit)技术,即首先多次调用write_log函数将多个写操作的日志拷贝到相同的日志缓冲区,接着再调用flush_log函数将日志缓冲区中的内容一次性写入到日志文件中。
2.MemTable
MemTable底层是一个高性能内存B树。MemTable封装了B树,对外提供统一的读写接口。
B树中的每个叶子节点对应MemTable中的一行数据,key为行主键,value为行操作链表的指针。每行的操作按照时间顺序构成一个行操作链表。
如图9-4所示,MemTable的内存结构包含两部分:索引结构以及行操作链表,索引结构为9.1.2节中提到的B树,支持插入、删除、更新、随机读取以及范围查询操作。行操作链表保存的是对某一行各个列(每个行和列确定一个单元,称为Cell)的修改操作。
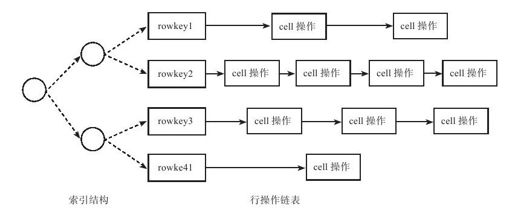
图 9-4 MemTable的内存结构
例9-3 对主键为1的商品有3个修改操作,分别是:将商品购买人数修改为100,删除该商品,将商品名称修改为“女鞋”,那么,该商品的行操作链中将保存三个Cell,分别为:<update,购买人数,100>、<delete,*>以及<update,商品名,“女鞋”>。
MemTable中存储的是对该商品的所有修改操作,而不是最终结果。另外,MemTable删除一行也只是往行操作链表的末尾加入一个逻辑删除标记,即<delete,*>,而不是实际删除索引结构或者行操作链表中的行内容。
MemTable实现时做了很多优化,包括:
●哈希索引:针对主要操作为随机读取的应用,MemTable不仅支持B树索引,还支持哈希索引,UpdateServer内部会保证两个索引之间的一致性。
●内存优化:行操作链表中每个cell操作都需要存储操作列的编号(column_id)、操作类型(更新操作还是删除操作)、操作值以及指向下一个cell操作的指针,如果不做优化,内存膨胀会很大。为了减少内存占用,MemTable实现时会对整数值进行变长编码,并将多个cell操作编码后序列到同一块缓冲区中,共用一个指向下一批cell操作缓冲区的指针:
struct ObCellMeta
{
const static int64_t TP_INT8=1;//int8整数类型
const static int64_t TP_INT16=2;//int16整数类型
const static int64_t TP_INT32=3;//int32整数类型
const static int64_t TP_INT64=4;//int64整数类型
const static int64_t TP_VARCHAR=6;//变长字符串类型
const static int64_t TP_DOUBLE=13;//双精度浮点类型
const static int64_t TP_ESCAPE=0x1f;//扩展类型
const static int64_t ES_DEL_ROW=1;//删除行操作
};
class ObCompactCellWriter
{
public:
//写入更新操作,存储成压缩格式
int append(uint64_t column_id,const ObObj&value);
//写入删除操作,存储成压缩格式
int row_delete();
};
MemTable通过ObCompactCellWriter来将cell操作序列化到内存缓冲区中,如果为更新操作,调用append函数;如果为删除操作,调用row_delete函数。更新操作的存储格式为:数据类型+值+列ID,TP_INT8/TP_INT16/TP_INT32/TP_INT64分别表示8位/16位/32位/64位整数类型,TP_VARCHAR表示变长字符串类型,TP_DOUBLE表示双精度浮点类型。删除操作为扩展操作,其存储格式为:TP_ESCAPE+ES_DEL_ROW。例9-3中的三个Cell:<update,购买人数,100>、<delete,*>以及<update,商品名,“女鞋”>在内存缓冲区的存储格式为:

第1~3字节表示第一个Cell,即<update,购买人数,100>;第4~5字节表示第二个cell,即<delete,*>;第6~8字节表示第三个Cell,即<update,商品名,“女鞋”>。
MemTable的主要对外接口可以归结如下:
//开启一个事务
//@param[in]trans_type事务类型,可能为读事务或者写事务
//@param[out]td返回的事务描述符
int start_transaction(const TETransType trans_type,MemTableTransDescriptor&td);
//提交或者回滚一个事务
//@param[in]td事务描述符
//@param[in]rollback是否回滚,默认为false
int end_transaction(const MemTableTransDescriptor td,bool rollback=false);
//执行随机读取操作,返回一个迭代器
//@param[in]td事务描述符
//@param[in]table_id表格编号
//@param[in]row_key待查询的主键
//@param[out]iter返回的迭代器
int get(const MemTableTransDescriptor td,const uint64_t table_id,const ObRowkey&row_key,MemTableIterator&iter);
//执行范围查询操作,返回一个迭代器
//@param[in]td事务描述符
//@param[in]range查询范围,包括起始行、结束行,开区间或者闭区间
//@param[out]iter返回的迭代器
int scan(const MemTableTransDescriptor td,const ObRange&range,MemTableIterator&iter);
//开始执行一次修改操作
//@param[in]td事务描述符
int start_mutation(const MemTableTransDescriptor td);
//提交或者回滚一次修改操作
//@param[in]td事务描述符
//@param[in]rollback是否回滚
int end_mutation(const MemTableTransDescriptor td,bool rollback);
//执行修改操作
//@param[in]td事务描述符
//@param[in]mutator修改操作,包含一个或者多个对多个表格的cell操作
int set(const MemTableTransDescriptor td,ObUpsMutator&mutator);
对于读事务,操作步骤如下:
1)调用start_transaction开始一个读事务,获得事务描述符;
2)执行随机读取或者扫描操作,返回一个迭代器;接着可以从迭代器不断迭代数据;
3)调用end_transaction提交或者回滚一个事务。
class MemTableIterator
{
public:
//迭代器移动到下一个cell
int next_cell();
//获取当前cell的内容
//@param[out]cellinfo当前cell的内容,包括表名(table_id),行主键(row
key),列编号(column_id)以及列值(column_value)
int get_cell(ObCellInfo**cell_info);
//获取当前cell的内容
//@param[out]cell_info当前cell的内容
//@param is_row_changed是否迭代到下一行
int get_cell(ObCellInfo*cell_info,boolis_row_changed);
};
读事务返回一个迭代器MemTableIterator,通过它可以不断地获取下一个读到的cell。在例9-3中,读取编号为1的商品可以得到一个迭代器,从这个迭代器中可以读出行操作链中保存的3个Cell,依次为:<update,购买人数,100>,<delete,*>,<update,商品名,“女鞋”>。
写事务总是批量执行,步骤如下:
1)调用start_transaction开始一批写事务,获得事务描述符;
2)调用start_mutation开始一次写操作;
3)执行写操作,将数据写入到MemTable中;
4)调用end_mutation提交或者回滚一次写操作;如果还有写事务,转到步骤2);
5)调用end_transaction提交写事务。
3.SSTable
当活跃的MemTable超过一定大小或者管理员主动发起冻结命令时,活跃的MemTable将被冻结,生成冻结的MemTable,并同时以SSTable的形式转储到SSD磁盘中。
SSTable的详细格式请参考9.4节ChunkServer实现机制,与ChunkServer中的SSTable不同的是,UpdateServer中所有的表格共用一个SSTable,且SSTable为稀疏格式,也就是说,每一行数据的每一列可能存在,也可能不存在修改操作。
另外,OceanBase设计时也尽量避免读取UpdateServer中的SSTable,只要内存足够,冻结的MemTable会保留在内存中,系统会尽快将冻结的数据通过定期合并或者数据分发的方式转移到ChunkServer中去,以后不再需要访问UpdateServer中的SSTable数据。
当然,如果内存不够需要丢弃冻结MemTable,大量请求只能读取SSD磁盘,UpdateServer性能将大幅下降。因此,希望能够在丢弃冻结MemTable之前将SSTable的缓存预热。
UpdateServer的缓存预热机制实现如下:在丢弃冻结MemTable之前的一段时间(比如10分钟),每隔一段时间(比如30秒),将一定比率(比如5%)的请求发给SSTable,而不是冻结MemTable。这样,SSTable上的读请求将从5%到10%,再到15%,依次类推,直到100%,很自然地实现了缓存预热。
