7.2 Microsoft SQL Azure
Microsoft SQL Azure是微软的云关系型数据库,后端存储又称为云SQL Server(Cloud SQL Server)。它构建在SQL Server之上,通过分布式技术提升传统关系型数据库的可扩展性和容错能力。
7.2.1 数据模型
1.逻辑模型
云SQL Server将数据划分为多个分区,通过限制事务只能在一个分区执行来规避分布式事务。另外,它通过主备复制(Primary-Copy)协议将数据复制到多个副本,保证高可用性。
云SQL Server中一个逻辑数据库称为一个表格组(table group),它既可以是有主键的,也可以是无主键的,本节只讨论有主键的表格组。如果一个表格组是有主键的,要求表格组中所有的表格都有一个相同的列,称为划分主键(partitioning key)。图中的表格组包含两个表格,顾客表(Customers)和订单表(Orders),划分主键为顾客ID(Customers表中的Id列)。如图7-2所示。
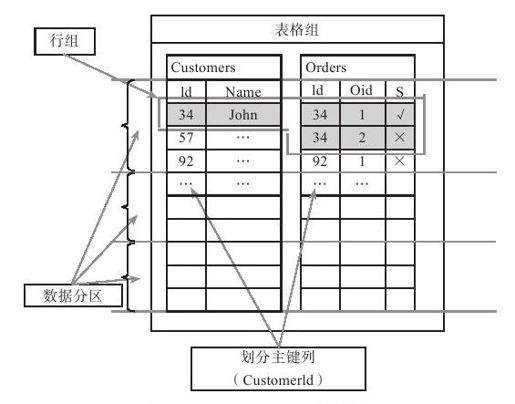
图 7-2 云SQL Server数据模型
划分主键不需要是表格组中每个表格的唯一主键。图7-2中,顾客ID是顾客表的唯一主键,但不是订单表的唯一主键。同样,划分主键也不需要是每个表格的聚集索引,订单表的聚集索引为组合主键<顾客ID,订单ID>(<Id,Oid>)。
表格组中所有划分主键相同的行集合称为行组(row group)。顾客表的第一行以及订单表的前两行的划分主键均为34,构成一个行组。云SQL Server只支持同一个行组内的事务,这就意味着,同一个行组的数据逻辑上会分布到一台服务器。
如果表格组是有主键的,云SQL Server支持自动地水平拆分表格组并分散到整个集群。同一个行组总是被一台物理的SQL Server服务,从而避免了分布式事务。这样的好处是避免了分布式事务的两个问题:阻塞及性能,当然,也限制了用户的使用模式。
只读事务可以跨多个行组,但事务隔离级别最多支持读取已提交(read-committed)。
2.物理模型
在物理层面,每个有主键的表格组根据划分主键列有序地分成多个数据分区(partition)。这些分区之间互相不重叠,并且覆盖了所有的划分主键值。这就确保了每个行组属于一个唯一的分区。
分区是云SQL Server复制、迁移、负载均衡的基本单位。每个分区包含多个副本(默认为3),每个副本存储在一台物理的SQL Server上。由于每个行组属于一个分区,这也就意味着每个行组的数据量不能超过分区允许的最大值,也就是单台SQL Server的容量上限。
一般来说,同一个交换机或者同一个机架的机器同时出现故障的概率较大,因而它们属于同一个故障域(failure domain)。云SQL Server保证每个分区的多个副本分布到不同的故障域。每个分区有一个副本为主副本(Primary),其他副本为备副本(Secondary)。主副本处理所有的查询,更新事务并以操作日志的形式将事务同步到备副本,备副本接收主副本发送的事务日志并应用到本地数据库。目前,备副本不支持读操作,当然,这是很容易实现的,只是可能读取到过期的数据。
如图7-3所示,有四个逻辑分区PA、PB、PC、PD,每个分区有一个主副本和两个备副本。例如,PA有一个主副本PAP以及两个备副本PAS1和PAS2。每台物理SQL Server数据库混合存放了主副本和备副本。如果某台机器发生故障,它上面的分区能够很快分散到其他活着的机器上。
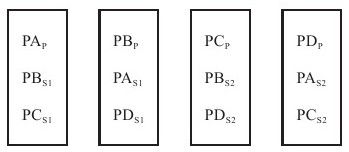
图 7-3 云SQL Server物理模型
分区划分是动态的,如果某个分区超过了允许的最大分区大小或者负载太高,这个分区将分裂为两个分区。假设分区A的主副本在机器X,它的备副本在机器Y和Z。如果分区A分裂为A1和A2,每个副本都需要相应地分裂为两段。为了更好地进行负载均衡,每个副本分裂前后的角色可能不尽相同。例如,A1的主副本仍然在机器X,备副本在机器Y和机器Z;而A2的主副本可能在机器Y,备副本在机器X和机器Z。
