3.5 容错
随着集群规模变得越来越大,故障发生的概率也越来越大,大规模集群每天都有故障发生。容错是分布式存储系统设计的重要目标,只有实现了自动化容错,才能减少人工运维成本,实现分布式存储的规模效应。
单台服务器故障的概率是不高的,然而,只要集群的规模足够大,每天都可能有机器故障发生,系统需要能够自动处理。首先,分布式存储系统需要能够检测到机器故障,在分布式系统中,故障检测往往通过租约(Lease)协议实现。接着,需要能够将服务复制或者迁移到集群中的其他正常服务的存储节点。
本节首先介绍Google某数据中心发生的故障,接着讨论分布式系统中的故障检测以及恢复方法。
3.5.1 常见故障
来自Google的Jeff Dean在LADIS 2009报告中介绍了Google某数据中心第一年运行发生的故障数据,如表3-1所示。
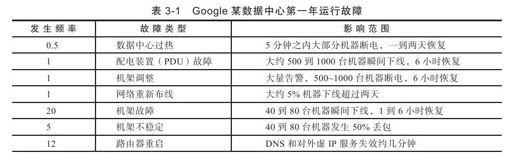
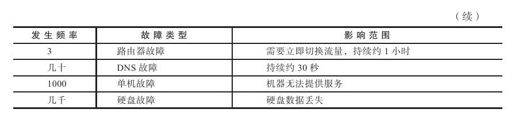
从表3-1可以看出,单机故障和磁盘故障发生概率最高,几乎每天都有多起事故,系统设计首先需要对单台服务器故障进行容错处理。一般来说,分布式存储系统会保存多份数据,当其中一份数据所在服务器发生故障时,能通过其他副本继续提供服务。另外,机架故障发生的概率相对也是比较高的,需要避免将数据的所有副本都分布在同一个机架内。最后,还可能出现磁盘响应慢,内存错误,机器配置错误,数据中心之间网路连接不稳定,等等。
