13.4.3 Twitter Storm
Twitter Storm是目前广泛使用的流式计算系统,它创造性地引入了一种记录级容错的方法。如图13-7所示,Storm系统中包含如下几种角色:
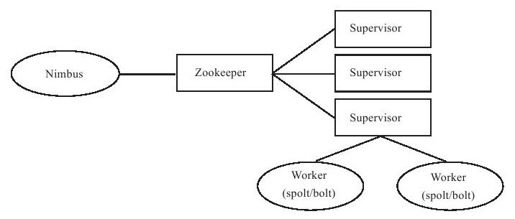
图 13-7 Storm集群的基本组件
●Nimbus:负责资源分配、任务调度、监控状态。Nimbus和supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。
●Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的Worker进程。
●Worker:运行spout/bolt组件的进程。
●Spout:产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为内部的数据格式。Spout是一个主动的角色,其接口中有个nextTuple()函数,Storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
●Bolt:接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
每个worker上运行着spolt或者bolt组件,数据从spolt组件流入,经过一系列bolt组件的处理直到生成用户想要的结果。
Storm中的一个记录称为tuple,用户在spout中生成一个新的源tuple时可以为其指定一个消息编号(message id),多个源tuple可以共用一个消息编号,表示这多个源tuple对用户来说是同一个消息单元。Storm的记录级容错机制会告知用户由Spolt发出的每个消息单元是否在指定时间内被完全处理了,从而允许Splot重新发送出错的消息。如图13-8,message1绑定的源tuple1和tuple2经过了bolt1和bolt2的处理后生成两个新的tuple(tuple3和tuple4),并最终都流向bolt3。当这个过程全部完成时,message1被完全处理了。Storm中有一个系统级组件,叫做acker。这个acker的任务就是追踪从spout中流出来的每一个message绑定的若干tuple的处理路径。Bolt1、bolt2、bolt3每次处理完成一个tuple都会通知acker,acker会判断message1是否被完全处理了,等到完全处理时通知生成message1的spolt。这里存在两个问题:
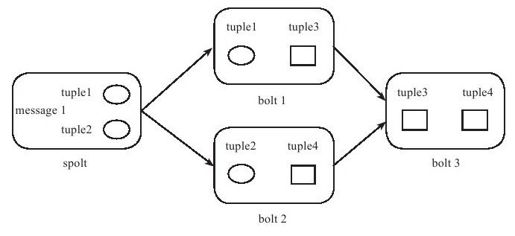
图 13-8 Storm数据流示例
1)如何判断message1是否被完全处理了?
Acker中保存了message1对应的校验值(64位整数),初始为0。每次发送或者接收一个message1绑定的tuple时都会将tuple的编号与校验值进行异或(XOR)运行,如果每个发送出去的tuple都被接受了,那么,message1对应校验值一定是0,从而认为message1被完全处理了。当然,这种方式有一定的误判率,然而考虑到每个tuple的编号为64位整数,这种概率很低。
2)系统中有很多acker实例,如何选择将message1发给哪个实例?
Storm中采用一致性哈希算法来计算message1对应的acker实例。如果acker出现性能瓶颈,只需要往系统中加入新的acker实例即可。
