6.2 Google Megastore
Google Bigtable架构把可扩展性基本做到了极致,Megastore则是在Bigtable系统之上提供友好的数据库功能支持,增强易用性。Megastore是介于传统的关系型数据库和NoSQL之间的存储技术,它在Google内部使用广泛,如Google App Engine、社交类应用等。
互联网应用往往可以根据用户进行拆分,比如Email系统、相册系统、广告投放效果报表系统、购物网站商品存储系统等。同一个用户内部的操作需要保证强一致性,比如要求支持事务,多个用户之间的操作往往只需要最终一致性,比如用户之间发Email不要求立即收到。因此,可以根据用户将数据拆分为不同的子集分布到不同的机器上。Google进一步从互联网应用特性中抽取实体组(Entity Group)概念,从而实现可扩展性和数据库语义之间的一种权衡,同时获得NoSQL和RDBMS的优点。
如图6-5所示,用户定义了User和Photo两张表,主键分别为<user_id>和<user_id,photo_id>,每一个用户的所有数据构成一个实体组。其中,User表是实体组根表,Photo表是实体组子表。实体组根表中的一行称为根实体(Root Entity),对应Bigtable存储系统中的一行。根实体除了存放用户数据,还需要存放Megastore事务及复制操作所需的元数据,包括操作日志。

图 6-5 实体组语法
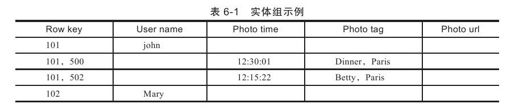
表6-1中有两个实体组,其中第一个实体组包含前三行数据,第二个实体组包含最后一行数据。第一行数据来自User表,是第一个实体组的Root Entity,存放编号为101的用户数据以及这个实体组的事务及复制操作元数据;第二行和第三行数据来自Photo表,存放用户的照片数据。
Bigtable通过单行事务保证根实体操作的原子性,也就是说,同一个实体组的元数据操作是原子的。另外,同一个实体组在Bigtable中连续存放,因此,多数情况下同一个用户的所有数据属于同一个Bigtable子表,分布在同一台Bigtable Tablet Server机器上,从而提供较高的扫描性能和事务性能。当然,如果某一个实体组过大,比如超过一个子表的大小,这样的实体组跨多个子表,可以分布到多台机器。
6.2.1 系统架构
如图6-6所示,Megastore系统由三个部分组成:
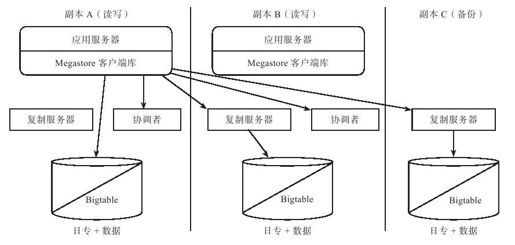
图 6-6 Megastore整体架构
●客户端库:提供Megastore到应用程序的接口,应用程序通过客户端操作 Megastore的实体组。Megastore系统大部分功能集中在客户端,包括映射Megastore操作到Bigtable,事务及并发控制,基于Paxos的复制,将请求分送给复制服务器,通过协调者实现快速读等。
●复制服务器:接受客户端的用户请求并转发到所在机房的Bigtable实例,用于解决跨机房连接数过多的问题。
●协调者:存储每个机房本地的实体组是否处于最新状态的信息,用于实现快速读。
Megastore的功能主要分为三个部分:映射Megastore数据模型到Bigtable,事务及并发控制,跨机房数据复制及读写优化。Megastore首先解析用户通过客户端传入的SQL请求,接着根据用户定义的Megastore数据模型将SQL请求转化为对底层Bigtable的操作。
在表6-1中,假设用户(user_id为101)往Photo表格中插入photo_id分别为500和502的两行数据。这就意味着,需要向Bigtable写入主键(rowkey)分别为<101,500>和<101,502>的两行数据。为了保证写事务的原子性,Megastore首先会往该用户的根实体(Bigtable中主键为<101>的数据行)写入操作日志,通过Bigtable的单行事务实现操作日志的原子性。接着,回放操作日志,并写入<101,500>和<101,502>这两行数据。这两行数据在Bigtable属于同一个版本,客户端要么读到全部行,要么一行也读不到。接下来分别介绍事务与并发控制、Paxos数据复制以及读写流程。
