第6章 分布式表格系统
分布式表格系统对外提供表格模型,每个表格由很多行组成,通过主键唯一标识,每一行包含很多列。整个表格在系统中全局有序,适用3.3.2节中讲的顺序分布。
Google Bigtable是分布式表格系统的始祖,它采用双层结构,底层采用GFS作为持久化存储层。GFS+Bigtable双层架构是一种里程碑式的架构,其他系统,包括Microsoft分布式存储系统Windows Azure Storage以及开源的Hadoop系统,均为其模仿者。Bigtable的问题在于对外接口不够丰富,因此,Google后续开发了两套系统,一套是Megastore,构建在Bigtable之上,提供更加丰富的使用接口;另外一套是Spanner,支持跨多个数据中心的数据库事务,下一章会专门介绍。
本章首先详细介绍Bigtable的架构及实现,接着分析Megastore的架构,最后介绍Microsoft Azure Storage的架构。
6.1 Google Bigtable
Bigtable是Google开发的基于GFS和Chubby的分布式表格系统。Google的很多数据,包括Web索引、卫星图像数据等在内的海量结构化和半结构化数据,都存储在Bigtable中。与Google的其他系统一样,Bigtable的设计理念是构建在廉价的硬件之上,通过软件层面提供自动化容错和线性可扩展性能力。
Bigtable系统由很多表格组成,每个表格包含很多行,每行通过一个主键(Row Key)唯一标识,每行又包含很多列(Column)。某一行的某一列构成一个单元(Cell),每个单元包含多个版本的数据。整体上看,Bigtable是一个分布式多维映射表,如下所示:
(row:string,column:string,timestamp:int64)->string
另外,Bigtable将多个列组织成列族(column family),这样,列名由两个部分组成:(column family,qualifier)。列族是Bigtable中访问控制的基本单元,也就是说,访问权限的设置是在列族这一级别上进行的。Bigtable中的列族在创建表格的时候需要预先定义好,个数也不允许过多;然而,每个列族包含哪些qualifier是不需要预先定义的,qualifier可以任意多个,适合表示半结构化数据。
Bigtable数据的存储格式如图6-1所示。
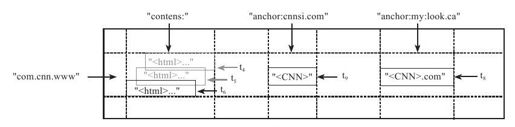
图 6-1 Bigtable数据存储格式
Bigtable中的行主键可以是任意的字符串,最大不超过64KB。Bigtable表中的数据按照行主键进行排序,排序使用的是字典序。图6-1中行主键com.cnn.www是域名www.cnn.com变换后的结果,这样做的好处是使得所有www.cnn.com下的子域名在系统中连续存放。这一行数据包含两个列族:"contents"和"anchor"。其中,列族"anchor"又包含两个列,qualifier分别为"cnnsi.com"和"my:look.ca"。
Google的很多服务,比如Web检索和用户的个性化设置,都需要保存不同时间的数据,这些不同的数据版本必须通过时间戳来区分。图6-1中的t4、t5和t6表示保存了三个时间点获取的网页。为了简化不同版本的数据管理,Bigtable提供了两种设置:一种是保留最近的N个不同版本,另一种是保留限定时间内的所有不同版本,比如可以保存最近10天的所有不同版本的数据。失效的版本将会由Bigtable的垃圾回收机制自动删除。
6.1.1 架构
Bigtable构建在GFS之上,为文件系统增加一层分布式索引层。另外,Bigtable依赖Google的Chubby(即分布式锁服务)进行服务器选举及全局信息维护。
如图6-2所示,Bigtable将大表划分为大小在100~200MB的子表(tablet),每个子表对应一个连续的数据范围。Bigtable主要由三个部分组成:客户端程序库(Client)、一个主控服务器(Master)和多个子表服务器(Tablet Server)。
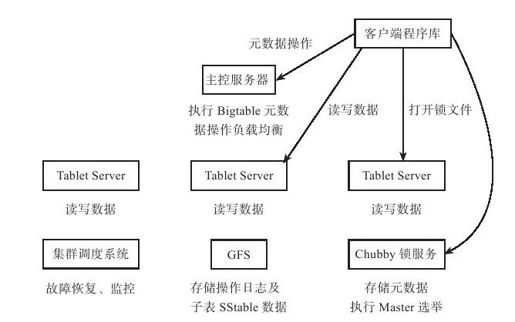
图 6-2 Bigtable的整体架构
●客户端程序库(Client):提供Bigtable到应用程序的接口,应用程序通过客户端程序库对表格的数据单元进行增、删、查、改等操作。客户端通过Chubby锁服务获取一些控制信息,但所有表格的数据内容都在客户端与子表服务器之间直接传送;
●主控服务器(Master):管理所有的子表服务器,包括分配子表给子表服务器,指导子表服务器实现子表的合并,接受来自子表服务器的子表分裂消息,监控子表服务器,在子表服务器之间进行负载均衡并实现子表服务器的故障恢复等。
●子表服务器(Tablet Server):实现子表的装载/卸出、表格内容的读和写,子表的合并和分裂。Tablet Server服务的数据包括操作日志以及每个子表上的sstable数据,这些数据存储在底层的GFS中。
Bigtable依赖于Chubby锁服务完成如下功能:
1)选取并保证同一时间内只有一个主控服务器;
2)存储Bigtable系统引导信息;
3)用于配合主控服务器发现子表服务器加入和下线;
4)获取Bigtable表格的schema信息及访问控制信息。
Chubby是一个分布式锁服务,底层的核心算法为Paxos。Paxos算法的实现过程需要一个“多数派”就某个值达成一致,进而才能得到一个分布式一致性状态。也就是说,只要一半以上的节点不发生故障,Chubby就能够正常提供服务。Chubby服务部署在多个数据中心,典型的部署为两地三数据中心五副本,同城的两个数据中心分别部署两个副本,异地的数据中心部署一个副本,任何一个数据中心整体发生故障都不影响正常服务。
Bigtable包含三种类型的表格:用户表(User Table)、元数据表(Meta Table)和根表(Root Table)。其中,用户表存储用户实际数据;元数据表存储用户表的元数据;如子表位置信息、SSTable及操作日志文件编号、日志回放点等,根表用来存储元数据表的元数据;根表的元数据,也就是根表的位置信息,又称为Bigtable引导信息,存放在Chubby系统中。客户端、主控服务器以及子表服务器执行过程中都需要依赖Chubby服务,如果Chubby发生故障,Bigtable系统整体不可用。
