6.3.3 分区层
分区层构建在文件流层之上,用于提供Table、Blob、Queue等数据服务。分区层的一个重要特性是提供强一致性并保证事务操作顺序。
分区层内部支持一种称为对象表(Object Table,OT)的数据架构,每个OT是一张最大可达若干PB的大表。对象表被动态地划分为连续的范围分区(RangePartition,对应Bigtable中的子表),并分散到WAS存储区的多个分区服务器(Partition Server)上。范围分区之间互相不重叠,每一行都确保只在一个范围分区上。
WAS存储区包含的对象表包括账户表,Blob数据表,Entity数据表,Message数据表。其中,账户表存储每个用户账户的元数据及配置信息;Blob、Entity、Message数据表分别对应WAS中的Blob、Table、Message服务。
另外,分层区中还有一张全局的Schema表格(Schema Table),保证所有的对象表格的schema信息,即每个对象表包含的每个列的名字,数据类型及其他属性。对象表划分为很多行,每个行通过一个主键(Primary Key)来定位,每个对象表的行主键包括用户账户名,分区名以及对象名三个部分。系统内部还维护了一张分区映射表(Partition Map),用于记录每个范围分区当前所在的分区服务器。
WAS支持的数据类型包括bool、binary string、DateTime、double、GUID、int32、int64、DictionaryType以及BlobType。DictionaryType允许每个行的某一列的值为一系列<name,type,value>的元组。BlobType被Blob表格使用,用于表示图片、图像等Blob数据。
1.架构
如图6-13所示,分区层包含如下四个部分:
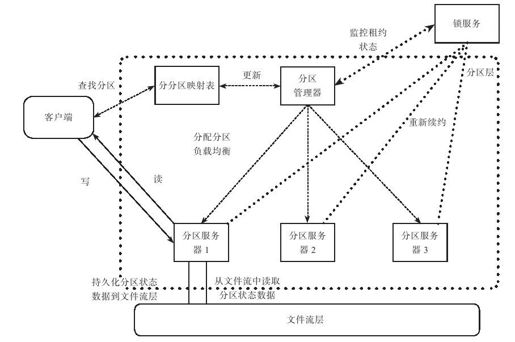
图 6-13 Azure分区层架构
●客户端程序库(Client)
提供分区层到WAS前端的接口,前端通过客户端以对不同对象表的数据单元进行增、删、查、改等操作。客户端通过分区映射表(Partition Map)获取分区映射信息,但所有表格的数据内容都在客户端与分区服务器之间直接传送;
●分区服务器(Partition Server,PS)
PS实现分区的装载/卸出、分区内容的读和写,分区的合并和分裂。一般来说,每个PS平均服务10个分区。
●分区管理器(Partition Manager,PM)
管理所有的PS,包括分配分区给PS,指导PS实现分区的分裂及合并,监控PS,在PS之间进行负载均衡并实现PS的故障恢复等。每个WAS存储区有多个PM,他们之间通过Lock Service进行选主,持有租约的PM是主PM。
●锁服务(Lock Service)
Paxos锁服务用于WAS存储区内选举主PM。另外,每个PS与锁服务之间都维持了租约。锁服务监控租约状态,PS的租约快到期时,会向锁服务重新续约。如果PS出现故障,PM需要首先等待PS上的租约过期才可以将它原来服务的分区分配出去,PS租约如果过期也需要主动停止读写服务。否则,可能出现多个PS同时读写同一个分区的情况。
2.分区数据结构
WAS分区层中的操作与Bigtable基本类似。如图6-14,用户写操作首先追加到操作日志文件流(Commit Log Stream),接着修改内存表(Memory Table),等到内存表到达一定大小后,需要执行快照(Checkpoint,对应Bigtable中的Minor Compaction)操作。分区服务器会定期将多个小快照文件合并成更大的快照文件(对应Bigtable中的Merge/Major Compaction)以减少读操作需要访问的文件数。分区服务器会对每个快照文件维护热点行数据的缓存(Row Page Cache,对应Bigtable中的Block Cache和Key Value Cache),另外,通过布隆过滤器过滤对快照文件不存在行的随机读请求。
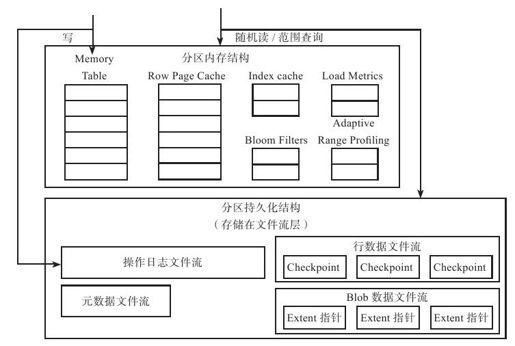
图 6-14 分区数据结构
与Bigtable的不同点如下:a)WAS中每个分区拥有一个专门的操作日志文件,而Bigtable中同一个Tablet Server的所有子表共享同一个操作日志文件;b)WAS中每个分区维护各自的元数据(例如分区包含哪些快照文件,持久化成元数据文件流),分区管理器只管理每个分区与所在的分区服务器之间的映射关系;而Bigtable专门维护了两级元数据表:元数据表(Meta Table)及根表(Root Table),每个分区的元数据保存在上一级元数据表中;c)WAS专门引入了Blob数据文件流用于支持Blob数据类型。
由于Blob数据一般比较大,如果行数据流中包含Blob数据,只记录每个Blob数据块在操作日志文件流(Commit Log Stream)中的索引信息,即所在的操作日志文件名及文件内的偏移。执行快照操作时,需要回收操作日志。如果操作日志的某些extent包含Blob数据,需要将这些extent连接到Blob数据流的末尾。这个操作只是简单地往Blob数据流文件追加extent指针,文件流层对此专门提供了快速操作接口。
3.负载均衡
PM记录每个PS及它服务的每个分区的负载。影响负载的因素包括:1)每秒事务数;2)平均等待事务个数;3)节流率;4)CPU使用率;5)网络使用率;6)请求延时;7)每个分区的数据大小。PM与PS之间维持了心跳,PS定期将负载信息通过心跳包回复PM。如果PM检测到某个分区的负载过高,发送指令给PS执行分裂操作;如果PS负载过高,而它服务的分区集合中没有过载的分区,PM从中选择一个或者多个分区迁移到其他负载较轻的PS。
对某个分区负载均衡两个阶段:
●卸载:PM首先发送一个卸载指令给PS,PS会执行一次快照操作。一旦完成后,PS停止待迁移分区的读写服务并告知PM卸载成功。如果卸载过程中PS出现异常,PM需要查询锁服务,直到PS的服务租约过期才可以执行下一步操作。
●加载:PM发送加载指令给新的PS并且更新PM维护的分区映射表结构,将分区指向新的PS。新的PS加载分区并且开始提供服务。由于卸载时执行了一次快照操作,加载时需要回放的操作日志很少,保证了加载的快速。
4.分裂与合并
有两种可能导致WAS对某个分区执行分裂操作,一种可能是分区太大,另外一种可能是分区的负载过高。PM发起分裂操作,并由PS确定分裂点。如果是基于分区大小的分裂操作,PS维护了每个分区的大小以及大致的中间位置,并将这个中间位置作为分裂点;如果是基于负载的分裂操作,PS自适应地计算分区中哪个主键范围的负载最高并通过它来确定分裂点。
假设需要把分区B分裂为两个新的分区C和D,操作步骤如下:
1)PM告知PS将分区B分裂为C和D。
2)PS对B执行快照操作,接着停止分区B的读写服务;
3)PS发起一个"MultiModify"[1]操作将分区B的元数据,操作日志及行数据流复制到C和D。这一步只需要拷贝每个文件的extent指针列表,不需要拷贝extent的内容。接着PS分别往C和D的元数据流写入新的分区范围。
4)PS开始对C和D这两个分区提供读写服务。
5)PS通知PM分裂成功,PM相应地更新分区映射表及元数据信息。接着PM会把C或者D中的其中一个分区迁移到另外一个不同的PS。
合并操作需要选择两个连续的负载较低的分区。假设需要把分区C和D合并成为新的分区E。操作步骤如下:
1)PM迁移C或者D,使得这两个分区被同一个PS服务。接着PM通知PS将分区C和D合并成为E。
2)PS分别对分区C和D执行快照操作,接着停止分区C和D的读写服务;
3)PS发起一个"MultiModify"操作合并分区C和D的操作日志及行数据流,生成E的操作日志和行数据流。假设分区C的操作日志文件包含<C1,C2>两个extent,分区D的操作日志文件包含<D1,D2,D3>三个extent,则分区E的操作日志文件包含<C1,C2,D1,D2,D3>这五个extent。行数据流及Blob数据流也是类似的。与分裂操作类似,这里只需要修改文件的extent指针列表,不需要拷贝extent的实际内容。
4)PS对E构造新的元数据流,包含新的操作日志文件,行数据文件,C和D合并后的新的分区范围以及操作日志回放点和行数据文件索引信息。
5)PS加载新分区E并提供读写服务。
6)PS通知PM合并成功,接着PM相应地更新分区映射表及元数据信息。
[1]MultiModify指在一次调用中实现多步修改操作。
