13.5.2 EMC Greenplum
Greenplum是EMC公司研发的一款采用MPP架构的OLAP产品,底层基于开源的PostgreSQL数据库。
1.整体架构
如图13-11,Greenplum系统主要包含两种角色:Master服务器(Master Server)和Segment服务器(Segment Server)。在Greenplum中每个表都是分布在所有节点上的。Master服务器首先对表的某个或多个列进行哈希运算,然后根据哈希结果将表的数据分布到Segment服务器中。整个过程中Master服务器不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
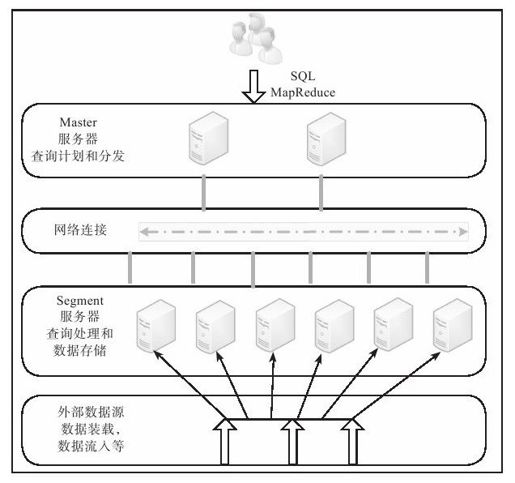
图 13-11 Greenplum整体架构
Greenplum支持两种访问方式:SQL和MapReduce。用户将SQL操作语句发送给Master服务器,由Master服务器执行词法分析、语法分析,生成查询计划,并将查询请求分发给多台Segment服务器。每个Segment服务器返回部分结果后,Master服务器会进行聚合并将最终结果返回给用户。除了高效查询,Greenplum还支持通过数据的并行装载,将外部数据并行装载到所有的Segement服务器。
2.并行查询优化器
Greenplum的并行查询优化器负责将用户的SQL或者MapReduce请求转化为物理执行计划。Greenplum采用基于代价的查询优化算法(cost-based optimization),从各种可能的查询计划中选择一个代价最小的。Greenplum优化器会考虑集群全局统计信息,例如数据分布,另外,除了考虑单机执行的CPU、内存资源消耗,还需要考虑数据的网络传输开销。
Greenplum除了生成传统关系数据库的物理运算符,包括表格扫描(Scan)、过滤(Filter)、聚集(Aggregation)、排序(Sort)、联表(Join),还会生成一些并行运算符,用来描述查询执行过程中如何在节点之间传输数据。
●广播(Broadcast,N:N):每个计算节点将目标数据发送给所有其他节点。
●重新分布(Redistribute,N:N):类似MapReduce中的shuffle过程,每个计算节点将目标数据重新哈希后分散到所有其他节点。
●汇总(Gather,N:1):所有的计算节点将目标数据发送给某个节点(一般为 Master服务器)。
图13-12中有四张表格:订单信息表(orders),订单项表(lineitem),顾客信息表(customer)以及顾客国籍表(nation)。其中,orders表记录了订单的基本信息,包括订单主键(o_orderkey)、顾客主键(o_custkey)和订单发生日期(o_orderdate);lineitem表记录了订单项信息,包括订单主键(l_orderkey)和订单金额(l_price);customer表记录了顾客的基本信息,包括顾客主键(c_custkey)和顾客国籍主键(c_nationkey);nation表记录了顾客的国籍信息,包括国籍主键(n_nationkey)和国籍名称(n_name)。Orders表和lineitem表通过订单主键关联,orders表和customer表通过顾客主键关联,customer表和nation通过国籍主键关联。左边的SQL语句查询订单发生日期在1994年8月1日开始三个月内的所有订单,按照顾客分组,计算每个分组的所有订单交易额,并按照交易额逆序排列。在右边的物理查询计划中,首先分别对lineitem和orders,custom和nation执行联表操作,联表后生成的结果分别记为Join_table1和Join_table2。接着,再对Join_table1和Join_table2执行联表操作。其中,custom和nation联表时会将nation表格的数据广播(Broadcast)到所有的计算节点(共4个);Join_table1和Join_table2联表时会将Join_table1按照Join列(o_custkey)哈希后重新分布(Redistribute)到所有的计算节点。最后,每个计算节点都有一部分Join_table1和Join_table2的数据,且Join列(o_custkey以及c_custkey)相同的数据分布在同一个计算节点,每个计算节点分别执行Hash Join、HashAggregate以及Sort操作。最后,将每个计算节点上的部分结果汇总(Gather)到Master服务器,整个SQL语句执行完成。
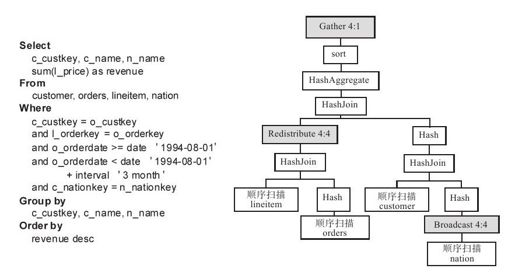
图 13-12 Greenplum查询优化示例
