13.5 实时分析
海量数据离线分析对于MapReduce这样的批处理系统挑战并不大,如果要求实时,又分为两种情况:如果查询模式单一,那么,可以通过MapReduce预处理后将最终结果导入到在线系统提供实时查询;如果查询模式复杂,例如涉及多个列任意组合查询,那么,只能通过实时分析系统解决。实时分析系统融合了并行数据库和云计算这两类技术,能够从海量数据中快速分析出汇总结果。
13.5.1 MPP架构
并行数据库往往采用MPP(Massively Parallel Processing,大规模并行处理)架构。MPP架构是一种不共享的结构,每个节点可以运行自己的操作系统、数据库等。每个节点内的CPU不能访问另一个节点的内存,节点之间的信息交互是通过节点互联网络实现的。
如图13-9所示,将数据分布到多个节点,每个节点扫描本地数据,并由Merge操作符执行结果汇总。
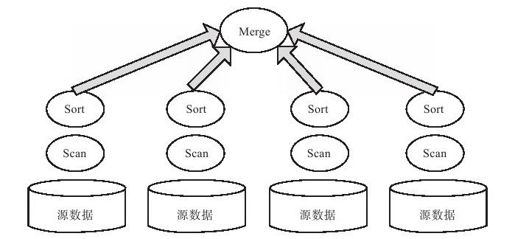
图 13-9 MPP Merge操作符
常见的数据分布算法有两种:
●范围分区(Range partitioning):按照范围划分数据。
●哈希分区(Hashing):根据哈希函数计算结果将每个元组分配给相应的节点。
Merge操作符:系统中存在一个或者多个合并节点,它会发送命令给各个数据分片请求相应的数据,每个数据分片所在的节点扫描本地数据,排序后回复合并节点,由合并节点通过merge操作符执行数据汇总。Merge操作符是一个统称,涉及的操作可能是limit、order by、group by、join等。这个过程相当于执行一个Reduce任务个数为1的MapReduce作业,不同的是,这里不需要考虑执行过程中服务器出现故障的情况。
如果Merge节点处理的数据量特别大,可以通过Split操作符将数据划分到多个节点,每个节点对一部分数据执行group by、join等操作后再合并最终结果。
如图13-10,假如需要执行"select*from A,B where A.x=B.y",可以分别根据A.x和B.x的哈希值将表A和B划分为A0、A1以及B0、B1。由两个节点分别对A0、B0以及A1、B1执行join操作后再合并join结果。
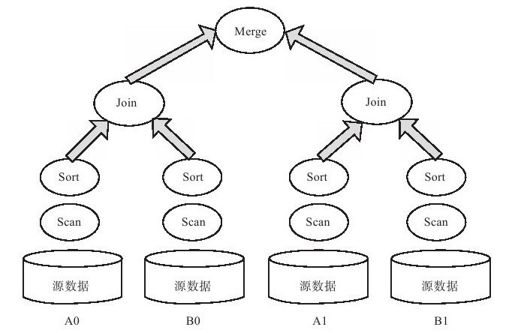
图 13-10 MPP Split操作符
并行数据库的SQL查询和MapReduce计算有些类似,可以认为MapReduce模型是一种更高层次的抽象。由于考虑问题的角度不同,并行数据库处理的SQL查询执行时间通常很短,出现异常时整个操作重做即可,不需要像MapReduce实现那样引入一个主控节点管理计算节点,监控计算节点故障,启动备份任务等。
