9.1.2 基础数据结构
1.哈希表
为了提高随机读取性能,UpdateServer支持创建哈希索引,这个哈希索引结构就是LightyHashMap,代码如下:
template<typename Key,typename Value>
class LightyHashMap
{
public:
//插入一个<key,value>对到哈希表
inline int insert(const Key&key,const Value&value);
//根据key查找value
inline int get(const Key&key,Value&value);
//根据key删除一个<key,value>对,如果value不为空,那么,保存删除的值到value中
inline int erase(const Key&key,Value*value=NULL);
private:
struct Node
{
Key key;
Value value;
union
{
Node*next;
int64_t flag;
};
};
Node*buckets_;//哈希桶指针
BitLock bitlock;//位锁,用于保护哈希桶
};
LightyHashMap采用链式冲突处理方法,即将所有哈希值相同的<key,value>对链到同一个哈希桶中,它包含如下三个方法:
●insert:往哈希表中插入一个<key,value>对。这个函数首先根据key的哈希值得到桶号,接着,往哈希桶中插入一个包含key和value值的Node节点。
●get:根据key查找value。这个函数首先根据key的哈希值得到桶号,接着,遍历对应的链表,找到与传入key相同的Node节点,返回其中的value值。
●erase:根据key删除一个<key,value>对。这个函数首先根据key的哈希值得到桶号,接着,遍历对应的链表,找到并删除与传入key相同的Node节点。
LightyHashMap设计用来存储几千万甚至几亿个元素,它与普通哈希表的不同点在于以下两点:
1)位锁(BitLock):LightyHashMap通过BitLock实现哈希桶的锁结构,每个哈希桶的锁结构只需要占用一个位(Bit)。如果哈希桶对应的位锁值为0,表示没有锁冲突;否则,表示出现锁冲突。需要注意的是,LightyHashMap没有区分读锁和写锁,多个get请求也是冲突的。可以对LightyHashMap的BitLock做一些改进,例如用两个位(Bit)表示哈希桶对应的锁,其中一个位表示是否有读冲突,另外一个位表示是否有写冲突。
2)延迟初始化(Lazy Initialization):LightyHashMap的哈希桶个数往往特别多(默认为1000万个),即使仅仅对所有哈希桶执行一次memset操作,消耗的时间也是相当可观的。因此,LightyHashMap采用延迟初始化策略,即将哈希桶划分为多个单元,默认情况下每个单元包含65536个哈希桶。每次执行insert、get或者erase操作时都会判断哈希桶所属的单元是否已经初始化,如果未初始化,则对该单元内的所有哈希桶执行初始化操作。
2.B树
UpdateServer的MemTable结构底层采用B树结构索引其中的数据行,代码如下:
template<class K,class V,class Alloc>
class BTreeBase
{
public:
//把<key,value>对加到B树中,overwrite参数表示是否覆盖原有值
int put(const K&key,const V&value,const bool overwrite=false);
//获取key对应的value
int get(const K&key,V&value);
//获取扫描操作描述符
int get_scan_handle(TScanHandle&handle);
//设置扫描的数据范围
int set_key_range(TScanHandle&handle,const K&start_key,int32_t start_exclude,const K&end_key,int32_t end_exclude);
//读取下一行数据
int get_next(TScanHandle&handle,K&key,V&value);
};
支持的功能如下:
1)Put:插入一个<key,value>对。
2)Get:根据key获取对应的value。
3)Scan:扫描一段范围内的数据行。首先,调用get_scan_handle获取扫描操作描述符,其次,调用set_key_range设置扫描的数据范围,最后,不断地调用get_next读取下一行数据直到全部读完。
B树支持多线程并发修改。如图9-1所示,往MemTable插入数据行(Data)时,将修改其B树索引结构(Index),分为两种情况:
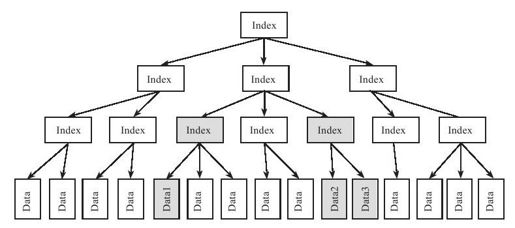
图 9-1 并发修改B树
●两个线程分别插入Data1和Data2:由于Data1和Data2属于不同的索引节点,插入Data1和Data2将影响B树的不同部分,两个线程可以并发执行,不会产生冲突。
●两个线程分别插入Data2和Data3:由于Data2和Data3属于相同的索引节点,因此,插入操作将产生冲突。其中一个线程会执行成功,另外一个线程失败后将重试。
每个索引节点满了以后将分裂为两个节点,并触发对该索引节点的父亲节点的修改操作。分裂操作将增加插入线程冲突的概率,在图9-1中,如果Data1和Data2的父亲节点都需要分裂,那么,两个插入线程都需要修改Data1和Data2的祖父节点,从而产生冲突。
另外,为了提高读写并发能力,B树实现时采用了写时复制(Copy-on-write)技术,修改每个索引节点时首先将该节点拷贝出来,接着在拷贝出来的节点上执行修改操作,最后再原子地修改其父亲节点的指针使其指向拷贝出来的节点。这种实现方式的好处在于修改操作不影响读取,读取操作永远不会被阻塞。
细心的读者可能会发现,这里的B树不支持更新(Update)以及删除操作,这是由OceanBase MVCC存储引擎的实现机制决定的。对于更新操作,MVCC存储引擎会在行的末尾追加一个单元记录更新的内容,而不会影响索引结构;对于删除操作,MVCC存储引擎内部实现为标记删除,即在行的末尾追加一个单元记录行的删除时间,而不会物理删除某行数据。
