7.3.2 架构
Spanner构建在Google下一代分布式文件系统Colossus之上。Colossus是GFS的延续,相比GFS,Colossus的主要改进点在于实时性,并且支持海量小文件。
由于Spanner是全球性的,因此它有两个其他分布式存储系统没有的概念:
●Universe。一个Spanner部署实例称为一个Universe。目前全世界有3个,一个开发、一个测试、一个线上。Universe支持多数据中心部署,且多个业务可以共享同一个Universe。
●Zones。每个Zone属于一个数据中心,而一个数据中心可能有多个Zone。一般来说,Zone内部的网络通信代价较低,而Zone与Zone之间通信代价很高。
如图7-7所示,Spanner系统包含如下组件:
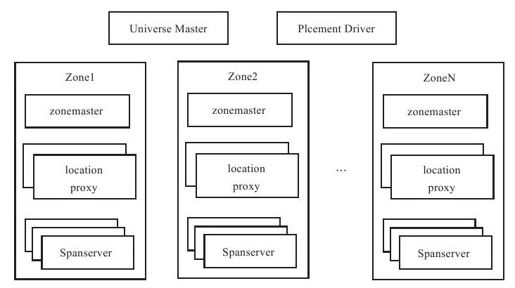
图 7-7 Spanner整体架构
●Universe Master:监控这个Universe里Zone级别的状态信息。
●Placement Driver:提供跨Zone数据迁移功能。
●Location Proxy:提供获取数据的位置信息服务。客户端需要通过它才能够知道数据由哪台Spanserver服务。
●Spanserver:提供存储服务,功能上相当于Bigtable系统中的Tablet Server。
每个Spanserver会服务多个子表,而每个子表又包含多个目录。客户端往Spanner发送读写请求时,首先查找目录所在的Spanserver,接着从Spanserver读写数据。
这里面有一个问题:如何存储目录与Spanserver之间的映射关系?假设每个用户对应一个目录,全球总共有50亿用户,那么,映射关系的数据规模为几十亿到几百亿,单台服务器无法存放。Spanner论文中没有明确说明,笔者猜测这里的做法和Bigtable类似,即将映射关系这样的元数据信息当成元数据表格,和普通用户表格采取相同的存储方式。
