13.5.3 HP Vertica
Vertica是Michael Stonebraker的学术研究项目C-Store的商业版本,并最终被惠普公司收购。Vertica在架构上与OceanBase有相似之处,这里介绍其中一些有趣的思想。
1.混合存储模型
Vertica的数据包含两个部分:ROS(Read-Optimized Storage)以及WOS(Write-Optimized Storage),WOS的数据在内存中且不排序和加索引,ROS的数据在磁盘中有序且压缩存储。后台的"TUPLE MOVER"会不断地将数据从WOS读出并往ROS更新(同时完成排序和索引)。Vertica的这种设计和OceanBase很相似,ROS对应OceanBase中的ChunkServer,WOS对应OceanBase中的UpdateServer。由于后台采用"BULK"的方式批量更新,性能非常好。
2.多映射(Projections)存储
Vertica没有采用传统关系数据库的B树索引,而是冗余存储一张表格的多个视图,定义为映射。
每个映射包含表格的部分列,可以分别对不同的映射定义不同的排序主键。如图13-13所示,系统中有一张表格逻辑上包含5列<A,B,C,D,E>,物理存储成三个映射,分别为:Projection1(A,B,C,主键为<A,B>),Projection2(A,B,C,主键为<B,A>)和Projection3(B,D,E,主键为<B>)。
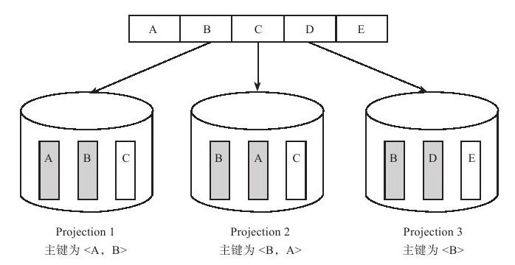
图 13-13 vertica projections示例
a)"select A,B,C from table where A=1"=>查询Projection1
b)"select A,B,C from table where B=1"=>查询Projection2
c)"select B,D from table where B=1"=>查询Projection3
Vertica通常维护多个不同排序的有重叠的映射,尽量使得每个查询的数据只来自一个映射,以提高查询性能。为了支持任意列查询,需要保证每个列至少在一个映射中出现。
3.列式存储
Vertica中的每一列数据独立存储在磁盘中的连续块上。查询数据时,Vertica只需要读取那些需要的列,而不是被选择的行的所有的列数据。
4.压缩技术
Vertica根据数据类型、基数(可能的取值个数)、排序自动对数据进行压缩,从而最小化每列占用的空间。常用的压缩算法包括:
●Run Length Encoding:列类型为整数,基数较小且有序;
●位图索引:列类型为整数,基数较小;
●按块字典压缩:列类型为字符串且基数较小;
●LZ通用压缩算法:其他列值特征不明显的场景。
基于列的压缩由于同样的数据类型和相同的取值范围,通常会大幅度提高压缩效果。另外,vertica还支持直接在压缩后的数据上做运算。
