2.2.2 B树存储引擎
相比哈希存储引擎,B树存储引擎不仅支持随机读取,还支持范围扫描。关系数据库中通过索引访问数据,在Mysql InnoDB中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成B+树(B树的一种)数据结构。
1.数据结构
如图2-7所示,MySQL InnoDB按照页面(Page)来组织数据,每个页面对应B+树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B+树的根节点是常驻内存的,因此,B+树一次检索最多需要h-1次磁盘IO,复杂度为O(h)=O(logdN)(N为元素个数,d为每个节点的出度,h为B+树高度)。修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。当然,InnoDB实现时做了大量的优化,这部分内容已经超出了本书的范围。
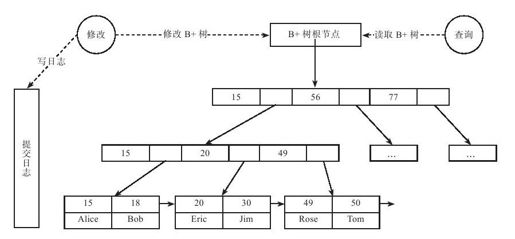
图 2-7 B+树存储引擎
2.缓冲区管理
缓冲区管理器负责将可用的内存划分成缓冲区,缓冲区是与页面同等大小的区域,磁盘块的内容可以传送到缓冲区中。缓冲区管理器的关键在于替换策略,即选择将哪些页面淘汰出缓冲池。常见的算法有以下两种。
(1)LRU
LRU算法淘汰最长时间没有读或者写过的块。这种方法要求缓冲区管理器按照页面最后一次被访问的时间组成一个链表,每次淘汰链表尾部的页面。直觉上,长时间没有读写的页面比那些最近访问过的页面有更小的最近访问的可能性。
(2)LIRS
LRU算法在大多数情况下表现是不错的,但有一个问题:假如某一个查询做了一次全表扫描,将导致缓冲池中的大量页面(可能包含很多很快被访问的热点页面)被替换,从而污染缓冲池。现代数据库一般采用LIRS算法,将缓冲池分为两级,数据首先进入第一级,如果数据在较短的时间内被访问两次或者以上,则成为热点数据进入第二级,每一级内部还是采用LRU替换算法。Oracle数据库中的Touch Count算法和MySQL InnoDB中的替换算法都采用了类似的分级思想。以MySQL InnoDB为例,InnoDB内部的LRU链表分为两部分:新子链表(new sublist)和老子链表(old sublist),默认情况下,前者占5/8,后者占3/8。页面首先插入到老子链表,InnoDB要求页面在老子链表停留时间超过一定值,比如1秒,才有可能被转移到新子链表。当出现全表扫描时,InnoDB将数据页面载入到老子链表,由于数据页面在老子链表中的停留时间不够,不会被转移到新子链表中,这就避免了新子链表中的页面被替换出去的情况。
