3.3 数据分布
分布式系统区别于传统单机系统在于能够将数据分布到多个节点,并在多个节点之间实现负载均衡。数据分布的方式主要有两种,一种是哈希分布,如一致性哈希,代表系统为Amazon的Dynamo系统;另外一种方法是顺序分布,即每张表格上的数据按照主键整体有序,代表系统为Google的Bigtable系统。Bigtable将一张大表根据主键切分为有序的范围,每个有序范围是一个子表。
将数据分散到多台机器后,需要尽量保证多台机器之间的负载是比较均衡的。衡量机器负载涉及的因素很多,如机器Load值,CPU,内存,磁盘以及网络等资源使用情况,读写请求数及请求量,等等,分布式存储系统需要能够自动识别负载高的节点,当某台机器的负载较高时,将它服务的部分数据迁移到其他机器,实现自动负载均衡。
分布式存储系统的一个基本要求就是透明性,包括数据分布透明性,数据迁移透明性,数据复制透明性,故障处理透明性。本节介绍数据分布以及数据迁移相关的基础知识。
3.3.1 哈希分布
哈希取模的方法很常见,其方法是根据数据的某一种特征计算哈希值,并将哈希值与集群中的服务器建立映射关系,从而将不同哈希值的数据分布到不同的服务器上。所谓数据特征可以是key-value系统中的主键(key),也可以是其他与业务逻辑相关的值。例如,将集群中的服务器按0到N-1编号(N为服务器的数量),根据数据的主键(hash(key)%N)或者数据所属的用户id(hash(user_id)%N)计算哈希值,来决定将数据映射到哪一台服务器。
如果哈希函数的散列特性很好,哈希方式可以将数据比较均匀地分布到集群中去。而且,哈希方式需要记录的元信息也非常简单,每个节点只需要知道哈希函数的计算方式以及模的服务器的个数就可以计算出处理的数据应该属于哪台机器。然而,找出一个散列特性很好的哈希函数是很难的。这是因为,如果按照主键散列,那么同一个用户id下的数据可能被分散到多台服务器,这会使得一次操作同一个用户id下的多条记录变得困难;如果按照用户id散列,容易出现“数据倾斜”(data skew)问题,即某些大用户的数据量很大,无论集群的规模有多大,这些用户始终由一台服务器处理。
处理大用户问题一般有两种方式,一种方式是手动拆分,即线下标记系统中的大用户(例如运行一次MapReduce作业),并根据这些大用户的数据量将其拆分到多台服务器上。这就相当于在哈希分布的基础上针对这些大用户特殊处理;另一种方式是自动拆分,即数据分布算法能够动态调整,自动将大用户的数据拆分到多台服务器上。
传统的哈希分布算法还有一个问题:当服务器上线或者下线时,N值发生变化,数据映射完全被打乱,几乎所有的数据都需要重新分布,这将带来大量的数据迁移。
一种思路是不再简单地将哈希值和服务器个数做除法取模映射,而是将哈希值与服务器的对应关系作为元数据,交给专门的元数据服务器来管理。访问数据时,首先计算哈希值,再查询元数据服务器,获得该哈希值对应的服务器。这样,集群扩容时,可以将部分哈希值分配给新加入的机器并迁移对应的数据。
另一种思路就是采用一致性哈希(Distributed Hash Table,DHT)算法。算法思想如下:给系统中每个节点分配一个随机token,这些token构成一个哈希环。执行数据存放操作时,先计算Key(主键)的哈希值,然后存放到顺时针方向第一个大于或者等于该哈希值的token所在的节点。一致性哈希的优点在于节点加入/删除时只会影响到在哈希环中相邻的节点,而对其他节点没影响。
如图3-2所示,假设哈希空间为0~2n,一致性哈希算法如下:
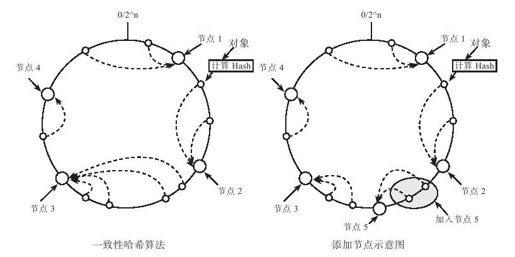
图 3-2 一致性哈希算法
●首先求出每个服务器的hash值,将其配置到一个0~2n的圆环区间上;
●其次使用同样的方法求出待存储对象的主键哈希值,也将其配置到这个圆环上;
●然后从数据映射的位置开始顺时针查找,将数据分布到找到的第一个服务器节点。
增加服务节点5以后,某些原来分布到节点3的数据需要迁移到节点5,其他数据分布均保持不变。可以看出,一致性哈希算法在很大程度上避免了数据迁移。
为了查找集群中的服务器,需要维护每台机器在哈希环中位置信息,常见的做法如下。
(1)O(1)位置信息
每台服务器记录它的前一个以及后一个节点的位置信息。这种做法的维护的节点位置信息的空间复杂度为O(1),然而每一次查找都可能遍历整个哈希环中的所有服务器,即时间复杂度为O(N),其中,N为服务器数量。
(2)O(logN)位置信息
假设哈希空间为0~2n(即N=2n),以Chord系统为例,为了加速查找,它在每台服务器维护了一个大小为n的路由表(finger table),FTP[i]=succ(p+2i-1),其中p为服务器在哈希环中的编号,路由表中的第i个元素记录了编号为p+2i-1的后继节点。通过维护O(logN)的位置信息,查找的时间复杂度改进为O(logN)。
(3)O(N)位置信息
Dynamo系统通过牺牲空间换时间,在每台服务器维护整个集群中所有服务器的位置信息,将查找服务器的时间复杂度降为O(1)。工程上一般都采用这种做法,Dynamo这样的P2P系统在每个服务器节点上都维护了所有服务器的位置信息,而带有总控节点的存储系统往往由总控节点统一维护。
一致性哈希还需要考虑负载均衡,增加服务节点node5后,虽然只影响到node5的后继,即node3的数据分布,但node3节点需要迁移的数据过多,整个集群的负载不均衡。一种自然的想法是将需要迁移的数据分散到整个集群,每台服务器只需要迁移1/N的数据量。为此,Dynamo中引入虚拟节点的概念,5.1节会详细讨论。
