3.5.3 故障恢复
当总控机检测到工作机发生故障时,需要将服务迁移到其他工作机节点。常见的分布式存储系统分为两种结构:单层结构和双层结构。大部分系统为单层结构,在系统中对每个数据分片维护多个副本;只有类Bigtable系统为双层结构,将存储和服务分为两层,存储层对每个数据分片维护多个副本,服务层只有一个副本提供服务。单层结构和双层结构的故障恢复机制有所不同。
单层结构的分布式存储系统维护了多个副本,例如副本个数为3,主备副本之间通过操作日志同步。如图3-5所示,某单层结构的分布式存储系统有3个数据分片A、B、C,每个数据分片存储了三个副本。其中,A1,B1,C1为主副本,分别存储在节点1,节点2以及节点3。假设节点1发生故障,将被总控节点检测到,总控节点选择一个最新的副本,比如A2或者A3替换A1成为新的主副本并提供写服务。节点下线分为两种情况:一种是临时故障,节点过一段时间将重新上线;另一种情况是是永久性故障,比如硬盘损坏。总控节点一般需要等待一段时间,比如1个小时,如果之前下线的节点重新上线,可以认为是临时性故障,否则,认为是永久性故障。如果发生永久性故障,需要执行增加副本操作,即选择某个节点拷贝A的数据,成为A的备副本。
两层结构的分布式存储系统会将所有的数据持久化写入底层的分布式文件系统,每个数据分片同一时刻只有一个提供服务的节点。如图3-5所示,某双层结构的分布式存储系统有3个数据分片,A、B和C。它们分别被节点1,节点2和节点3所服务。当节点1发生故障时,总控节点将选择一个工作节点,比如节点2,加载A的服务。由于A的所有数据都存储在共享的分布式文件系统中,节点2只需要从底层分布式文件系统读取A的数据并加载到内存中。
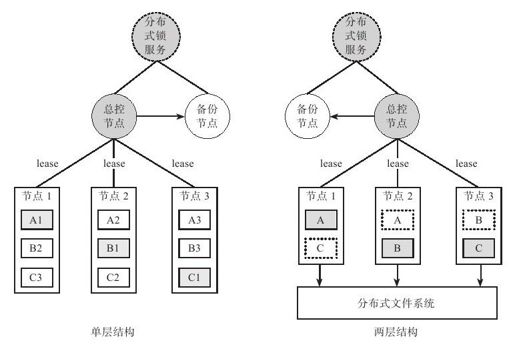
图 3-5 故障恢复
节点故障会影响系统服务,在故障检测以及故障恢复的过程中,不能提供写服务及强一致性读服务。停服务时间包含两个部分,故障检测时间以及故障恢复时间。故障检测时间一般在几秒到十几秒,和集群规模密切相关,集群规模越大,故障检测对总控节点造成的压力就越大,故障检测时间就越长。故障恢复时间一般很短,单层结构的备副本和主副本之间保持实时同步,切换为主副本的时间很短;两层结构故障恢复往往实现成只需要将数据的索引,而不是所有的数据,加载到内存中。
总控节点自身也可能出现故障,为了实现总控节点的高可用性(High Availability),总控节点的状态也将实时同步到备机,当故障发生时,可以通过外部服务选举某个备机作为新的总控节点,而这个外部服务也必须是高可用的。为了进行选主或者维护系统中重要的全局信息,可以维护一套通过Paxos协议实现的分布式锁服务,比如Google Chubby或者它的开源实现Apache Zookeeper。
