3.6 可扩展性
通过数据分布,复制以及容错等机制,能够将分布式存储系统部署到成千上万台服务器。可扩展性的实现手段很多,如通过增加副本个数或者缓存提高读取能力,将数据分片使得每个分片可以被分配到不同的工作节点以实现分布式处理,把数据复制到多个数据中心,等等。
分布式存储系统大多都带有总控节点,很多人会自然地联想到总控节点的瓶颈问题,认为P2P架构更有优势。然而,事实却并非如此,主流的分布式存储系统大多带有总控节点,且能够支持成千上万台的集群规模。
另外,传统的数据库也能够通过分库分表等方式对系统进行水平扩展,当系统处理能力不足时,可以通过增加存储节点来扩容。
那么,如何衡量分布式存储系统的可扩展性,它与传统数据库的可扩展性又有什么区别?可扩展性不能简单地通过系统是否为P2P架构或者是否能够将数据分布到多个存储节点来衡量,而应该综合考虑节点故障后的恢复时间,扩容的自动化程度,扩容的灵活性等。
本节首先讨论总控节点是否会成为性能瓶颈,接着介绍传统数据库的可扩展性,最后讨论同构系统与异构系统增加节点时的差别。
3.6.1 总控节点
分布式存储系统中往往有一个总控节点用于维护数据分布信息,执行工作机管理,数据定位,故障检测和恢复,负载均衡等全局调度工作。通过引入总控节点,可以使得系统的设计更加简单,并且更加容易做到强一致性,对用户友好。那么,总控节点是否会成为性能瓶颈呢?
分为两种情况:分布式文件系统的总控节点除了执行全局调度,还需要维护文件系统目录树,内存容量可能会率先成为性能瓶颈;而其他分布式存储系统的总控节点只需要维护数据分片的位置信息,一般不会成为瓶颈。另外,即使是分布式文件系统,只要设计合理,也能够扩展到几千台服务器。例如,Google的分布式文件系统能够扩展到8000台以上的集群,开源的Hadoop也能够扩展到3000台以上的集群。当然,设计时需要减少总控节点的负载,比如Google的GFS舍弃了对小文件的支持,并且把对数据的读写控制权下放到工作机ChunkServer,通过客户端缓存元数据减少对总控节点的访问等。
如果总控节点成为瓶颈,例如需要支持超过一万台的集群规模,或者需要支持海量的小文件,那么,可以采用两级结构,如图3-6所示。在总控机与工作机之间增加一层元数据节点,每个元数据节点只维护一部分而不是整个分布式文件系统的元数据。这样,总控机也只需要维护元数据节点的元数据,不可能成为性能瓶颈。假设分布式文件系统(Distributed File System,DFS)中有100个元数据节点,每个元数据节点服务1亿个文件,系统总共可以服务100亿个文件。图3-6中的DFS客户端定位DFS工作机时,需要首先访问DFS总控机找到DFS元数据服务器,再通过元数据服务器找到DFS工作机。虽然看似增加了一次网络请求,但是客户端总是能够缓存DFS总控机上的元数据,因此并不会带来额外的开销。
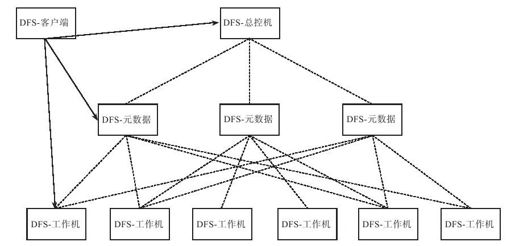
图 3-6 两级元数据架构
