3.6.3 异构系统
传统数据库扩容与大规模存储系统的可扩展性有何区别呢?为了说明这一问题,我们首先定义同构系统,如图3-8所示。
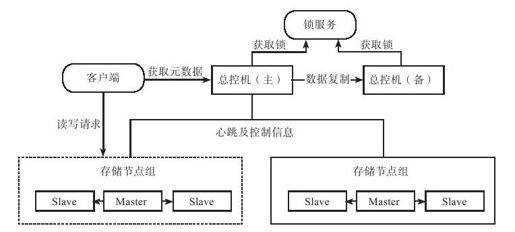
图 3-8 同构系统
将存储节点分为若干组,每个组内的节点服务完全相同的数据,其中有一个节点为主节点,其他节点为备节点。由于同一个组内的节点服务相同的数据,这样的系统称为同构系统。同构系统的问题在于增加副本需要迁移的数据量太大,假设每个存储节点服务的数据量为1TB,内部传输带宽限制为20MB/s,那么增加副本拷贝数据需要的时间为1TB/20MB/s=50000s,大约十几个小时,由于拷贝数据的过程中存储节点再次发生故障的概率很高,所以这样的架构很难做到自动化,不适用大规模分布式存储系统。
大规模分布式存储系统要求具有线性可扩展性,即随时加入或者删除一个或者多个存储节点,系统的处理能力与存储节点的个数成线性关系。为了实现线性可扩展性,存储系统的存储节点之间是异构的。否则,当集群规模达到一定程度后,增加节点将变得特别困难。异构系统将数据划分为很多大小接近的分片,每个分片的多个副本可以分布到集群中的任何一个存储节点。如果某个节点发生故障,原有的服务将由整个集群而不是某几个固定的存储节点来恢复。
如图3-9所示,系统中有五个分片(A,B,C,D,E),每个分片包含三个副本,如分片A的三个副本分别为A1,A2以及A3。假设节点1发生永久性故障,那么可以从剩余的节点中任意选择健康的节点来增加A,B以及E的副本。由于整个集群都参与到节点1的故障恢复过程,故障恢复时间很短,而且集群规模越大,优势就会越明显。

图 3-9 异构系统
