6.3.2 文件流层
文件流层提供内部接口供服务分区层使用。它提供类似文件系统的命名空间和API,但所有的写操作只能是追加,支持的接口包括:打开&关闭文件、改名、读取以及追加到文件。文件流层中的文件称为流,每个流包含一系列的extent。每个extent由一连串的block组成。
如图6-11所示,文件流"//foo"包含四个extent(E1、E2、E3、E4)。每个extent包含一连串追加到它的block。其中,E1、E2和E3是已经加封的(sealed),这就意味着不允许再对它们追加数据;E4是未加封的(unsealed),允许对它执行追加操作。
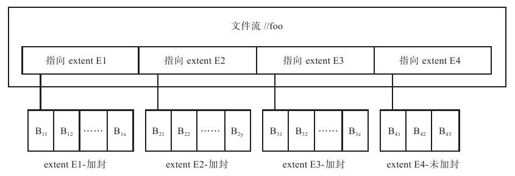
图 6-11 某文件流示例
block是数据读写的最小单位,每个block最大不超过4MB。文件流层对每个block计算检验和(checksum)。读取操作总是给定某个block的边界,然后一次性连续读取一个或者多个完整的block数据;写入操作凑成一个或者多个block写入到系统。WAS中的block与GFS中的记录(record)概念是一致的。
extent是文件流层数据复制,负载均衡的基本单位,每个存储区默认对每个extent保留三个副本,每个extent的默认大小为1GB。如果存储小对象,多个小对象可能共享同一个extent;如果存储大对象,比如几GB甚至TB,对象被切分为多个extent。WAS中的extent与GFS中的chunk概念是一致的。
stream用于文件流层对外接口,每个stream在层级命名空间中有一个名字。WAS中的stream与GFS中的file概念是一致的。
1.架构
如图6-12所示,文件流层由三个部分组成:
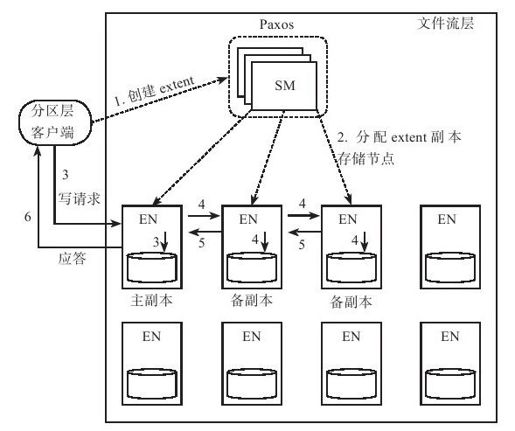
图 6-12 Azure文件流层的架构
●流管理器(Stream Manager,SM)
流管理器维护了文件流层的元数据,包括文件流的命名空间,文件流到extent之间的映射关系,extent所在的存储节点信息。另外,它还需要监控extent存储节点,负责整个系统的全局控制,如extent复制,负载均衡,垃圾回收无用的extent,等等。流管理器会定期通过心跳的方式轮询extent存储节点。流管理器自身通过Paxos协议实现高可用性。
●extent存储节点(Extent Node,EN)
extent存储节点实际存储每个extent的副本数据。每个extent单独存储成一个磁盘文件,这个文件中包含extent中所有block的数据及checksum,以及针对每个block的索引信息。extent存储节点之间互相通信拷贝客户端追加的数据,另外,extent存储节点还需要接受流管理器的命令,如创建extent副本,垃圾回收指定extent,等等。
●客户端库(Partition Layer Client)
客户端库是文件流层提供给上层应用(即分区层)的访问接口,它是一组专用接口,不遵守POSIX规范,以库文件的形式提供。分区层访问文件流层时,首先访问流管理器节点,获取与之进行交互的extent存储节点信息,然后直接访问这些存储节点,完成数据存取工作。
2.复制及一致性
WAS中的流文件只允许追加,不允许更改。追加操作是原子的,数据追加以数据块(block)为单位,多个数据块可以由客户端凑成一个缓冲区一次性提交到文件流层的服务端,保证原子性。与GFS一样,客户端追加数据块可能失败需要重试,从而产生重复记录,分区层需要处理这种情况。
分区层通过两种方式处理重复记录:对于元数据(metadata)和操作日志流(commit log streams),所有的数据都有一个唯一的事务编号(transaction sequence),顺序读取时忽略编号相同的事务;对于每个表格中的行数据流(row data streams),只有最后一个追加成功的数据块才会被索引,因此先前追加失败的数据块不会被分区层读取到,将来也会被系统的垃圾回收机制删除。
如图6-12,WAS追加流程如下:
1)如果分区层客户端没有缓存当前extent信息,例如追加到新的流文件或者上一个extent已经缝合(sealed),客户端请求SM创建一个新的extent;
2)SM根据一定的策略,如存储节点负载,机架位置等,分配一定数量(默认值为3)的extent副本到EN。其中一个extent副本为主副本,允许客户端写操作,其他副本为备副本,只允许接收主副本同步的数据。Extent写入过程中主副本维持不变,因此,WAS不需要类似GFS中的租约机制,大大简化了追加流程;
3)客户端写请求发送到主副本。主副本将执行如下操作:a)决定追加的数据块在extent中的位置;b)定序:如果有多个客户端往同一个extent并发追加,主副本需要确定这些追加操作的顺序;c)将数据块写入主副本自身;
4)主副本把待追加数据发给某个备副本,备副本接着转发给其他备副本。每一个备副本会根据主副本确定的顺序执行写操作;
5)备副本副本写成功后应答主副本;
6)如果所有的副本都应答成功,主副本应答客户端追加操作成功;
追加过程中如果某个副本出现故障,客户端追加请求返回失败,接着客户端将联系SM。SM首先会缝合失败的extent,接着创建一个新的extent用来提供追加操作。SM处理副本故障的平均时间在20ms左右,新的extent创建完成后客户端追加操作可以继续,整体影响不大。
每个extent副本都维护了已经成功提交的数据长度(commit length),如果出现异常,各个副本当前的长度可能不一致。SM缝合extent时首先请求所有的副本获取当前长度,如果副本之间不一致,SM将选择最小的长度值作为缝合后的长度。如果缝合操作的过程中某个副本所在的节点出现故障,缝合操作仍然能够成功执行,等到节点重启后,SM将强制该节点从extent的其他副本同步数据。
文件流层保证如下两点:
●只要记录被追加并成功响应客户端,从任何一个副本都能够读到相同的数据;
●即使追加过程出现故障,一旦extent被缝合,从任何一个被缝合的副本都能够读到相同的内容。
3.存储优化
extent存储节点面临两个问题:如何保证磁盘调度公平性以及避免磁盘随机写操作。
很多硬盘通过牺牲公平性来最大限度地提高吞吐量,这些磁盘优先执行大块顺序读写操作。而文件流层中既有大块顺序读写操作,也有大量的随机读取操作。随机读写操作可能被大块顺序读写操作阻塞,在某些磁盘上甚至观察到随机IO被阻塞高达2300ms的情况。为此,WAS改进了IO调度策略,如果存储节点上某个磁盘当前已发出请求的期望完成时间超过100ms或者最近一段时间内某个请求的响应时间超过200ms,避免将新的IO请求调度到该磁盘。这种策略适当牺牲了磁盘的吞吐量,但是保证公平性。
文件流层客户端追加操作应答成功要求所有的副本都将数据持久化到磁盘。这种策略提高了系统的可靠性,但增加了写操作延时。每个存储节点上有很多extent,这些extent被大量分区层上的客户端并发追加,如果每次追加都需要将extent文件刷到磁盘中,将导致大量的随机写。为了减少随机写,存储节点采用单独的日志盘(journal drive)顺序保存节点上所有extent的追加数据,追加操作分为两步:a)将待追加数据写入日志盘;b)将数据写入对应的extent文件。操作a)将随机写变为针对日志盘的顺序写,一般来说,操作a)先成功,操作b)只是将数据保存到系统内存中。如果节点发生故障,需要通过日志盘中的数据恢复extent文件。通过这种策略,可以将针对同一个extent文件的连续多个写操作合并成一个针对磁盘的写操作,提高了系统的吞吐量,同时降低了延时。
文件流层还有一种抹除码(erasure coding)机制用于减少extent副本占用的空间,GFS以及开源的HDFS也采用了这个机制。每个数据中心的extent副本默认都需要存储三份,为了降低存储成本,文件流层会对已经缝合的extent进行Reed-Solomon编码[1]。具体来讲,文件流层在后台定期执行任务,将extent划分为N个长度大致相同的数据段,并通过Reed-Solomon算法计算出M个纠错码段用于纠错。只要出现问题的数据段或纠错码段总和小于或者等于M个,文件流层都能重建整个extent。推荐的配置是N=10,M=4,也就是只需要1.4倍的存储空间,就能够容忍多达4个存储节点出现故障。
[1]一种纠错码,在分布式文件系统或者RAID技术中用于容忍多个副本或者磁盘同时离线的情况。
